移动APP 演化策略研究*
2020-01-11欧阳逸於志文
孙 悦,郭 斌,欧阳逸,於志文,王 柱
西北工业大学 计算机学院,西安710072
1 引言
2018 年1 月发布的第41 次《中国互联网络发展状况统计报告》(http://www.cac.gov.cn/2018-01/31/c_1122347026.htm)显示,截至2017 年11 月,中国市场上监测到的手机应用软件(application,APP)在架数量为391 万款,规模分布依次为游戏类、生活服务类、电子商务类、办公学习类等。APP 的迅猛发展离不开用户的参与,此外用户对APP 的使用态度和偏好也是决定APP 能否占领市场的关键要素之一。实时关注用户使用APP 的情况,从反馈系统中了解用户体验反馈,从而获得更多用户积累和支持,对APP 运营和演化起到重要作用。
传统调查问卷的方法由于其成本高、周期长、实时性差等缺陷,已经不能满足APP 演化的需要。而在线问卷等网络调查手段也存在回复率低,受访用户缺乏代表性等问题,效果仍不理想。
2004 年以来,网络信息的生成方式发生了重大变革,海量用户生成上传数据替代了传统的网络平台生成数据,这些数据称为群智数据——用户群体通过不同参与模式贡献的数据[1]。近年来,人们开始越来越多地使用各种各样的在线口碑评价平台来分享他们的消费体验和对各种产品的偏好,同时用户在选择使用或者购买产品的时候也会参考其他用户对该产品的评价[2]。用户在应用商店评论自己的使用情况、态度偏好等,还可以对APP 进行评星和评分,这些信息由大量APP 使用者共同参与生成,是典型的群智数据中的一种,整理分析这些数据能够帮助APP 实现智能演化。对于APP 设计者和开发商来说,用户评价不仅会决定APP 的市场前景和流行度,甚至还会影响商业规划和决策。
近年来,以在线评论数据为代表的群智数据的研究已经成为热点,但目前针对移动APP 评论的研究却方兴未艾,最近的研究有2017 年Martin 等[3]强调挖掘应用商店评论信息具有巨大价值,对于软件开发团队在需求设计、软件发布和测试等多方面都有直接且重要的意义。有关研究都表明APP 应用商店的文本评论能够反映出用户在选择APP 使用时的需求和偏好,并且这些评论中蕴含巨大价值,对APP 开发和演化具有促进作用。
因此,本文主要基于群智数据——APP 用户评论数据进行分析建模,结合经典评价模型,从开发者的角度对APP 提出演化策略,并给出版本预测模型,指导APP 版本更新迭代。
2 相关工作
2.1 在线评论挖掘
在线评论挖掘广泛应用于电子商务中,综合文本挖掘、自然语言处理、信息提取、机器学习、信息检索、概率统计等多个知识领域的研究。对于产品的在线评论研究则主要包括:评论属性的提取和情感识别和分类等。
在线评论中对于属性的识别方法有很多,如基于人工定义的方法[4]、基于词频的方法[5-6]、基于词语共现的方法[7]、基于模式或规则的方法[8-9]、基于本体论的方法[10-12]。传统的属性提取方法是基于规则的方法,根据语法规则、评论等陈述性的语句中,主语就是评论属性[8]。基于词频的方法是按照产品评论的统计规律抽取评论属性。基于共现模式的研究如Kobayashi 等[13]以车和游戏文本为例用半自动化的方式提取产品属性,Hu 等[5]以电子产品为例,采用词性标注和候选频繁项集生成、剪枝、识别等完成属性识别。Song 等[14]结合语料标注过程和支持向量机的分类原理实现了一个基于主动学习的属性元素标注工具。
情感识别和分类的主要任务是判断评论情感倾向是褒义、中性还是贬义,分类方法有基于无监督的点互信息(point-wise mutual information,PMI)的方法[15-16]、基于词语极性推测的方法[17]、基于情感词典的方法[18-19]。Turney[16]提出了应用无监督的分类方法识别产品语义倾向的方法,还采用互信息(PMI)和信息检索(information retrieval,IR)结合的算法计算短语的语义倾向[20]。Hu 等[6]提出利用词典的词汇关系判定词的极性,根据WordNet 词典的特点,设计了极性词自动分类的算法。
2.2 需求计量模型
需求计量是产品定位和营销与发展策略的基础。其中联合分析[21]是一种多元的统计分析方法,一种用于市场研究,帮助人们定量研究消费者选择偏好的方法,用于估测消费者对一些能够详细定义的产品属性的相对重要性和属性水平的效用的评价。另一种评价产品属性对顾客满意度的方式是KANO模型[22]。该模型最早源于日本学者Noriaki Kano 在20 世纪80 年代提出的产品开发和客户满意度理论,如图1 所示。

Fig.1 Diagram of KANO model图1 KANO 模型示意图
该理论将用户偏好分为五类:(1)魅力属性。用户意想不到的,如果不提供此需求,用户满意度不会降低,但当产品提供此需求,用户满意度会大幅提升。(2)期望属性。当产品提供此需求,用户满意度会提升,当不提供此需求,用户满意度会降低,或称之为一维属性。(3)必备属性。当产品优化必备属性的需求,用户满意度不会提升,当不提供此需求,用户满意度会大幅降低。(4)无差异属性。无论提供或不提供此需求,用户满意度都不会有改变,用户根本不在意。(5)反向属性。用户根本都没有此需求,提供后用户满意度反而会下降。
该模型被广泛应用于质量管理领域、产品设计领域和各种服务行业中[23-25]。
2.3 APP 评论挖掘
APP 评论是用户直接反馈使用情况和感受的途径,挖掘其中的信息有助于开发商更好地完成产品升级,更深理解用户需求和偏好,具有十分重大的研究价值。
Chandy 等[26]最早利用APP Store中爬取的用户评论数据集设计了一个简单模型识别评论中的垃圾评论。后来,Iacob 等[27]基于语言规则的方法构造了一个用于APP 评论分析的工具模型(mobile APP review analyzer,MARA),能够实现自动检索评论中所体现的APP 功能请求。Chen 等[28]创新性地提出了一个APP 评论计算框架(APP review mining,AR-Miner)识别评论中的有效信息,并对信息有效性排序。Vu等[29]提出一种基于关键字的半自动化评论分析框架(mining and analyzing reviews by keywords,MARK),实现了对于某一关键词评论的筛选、提炼和分析,并能以时间序列检测绘制关键词属性的变化曲线。
至于APP 评论的情感分析,Thelwall 等[30]首先提出一种基于非正式网络信息文本的情感检测算法,以商业目的为导向,检测在线产品评论文本中用户对产品的意见。对于后续APP 演化升级的研究,Fu等[31]提出一个可以从细节层级分析用户评论和评分的系统,给出了用户倾向的原因,为应用市场提供有价值可参考的意见,同时也能给APP 市场开发人员提供技术支持。Guzman 等[32]提出一种帮助APP 开发者自动筛选、聚合和分析评论的方法,首先使用自然语言处理识别评论中包含的应用程序的属性,然后在所有识别的属性评论中,给该属性进行一个评分,最终帮助开发者系统分析APP 单一属性的意见。后来,Guzman 等[33]又提出一个基于特征和情感为中心的检索方法,能自动为开发人员提供不同的用户评论,代表评论中涉及的不同意见和经验。
3 APP 评论数据的采集和预处理
为便于用户对比选择,APP 市场的应用商店会给出APP 的综合评级(或评分)和排行情况。同时,APP应用商店还会鼓励下载用户及时反馈问题和使用情况。APP 开发商可以通过各大应用商店获取用户评论,从反馈的信息中挖掘功能需求、用户偏好和建议等,有助于实现APP 的演化,从而不断实现功能完善、界面优化等。
国内知名移动应用商店有:安智市场、豌豆荚、腾讯应用宝、360 手机助手、百度应用商店等。除此之外,各大品牌手机都有专门的应用商店。为了保证数据可靠性,同时也能保证应用商店的评论是足量且可获取的,从数个平台上挑选出以下9 家平台进行数据采集。它们分别是:360 手机助手、百度手机助手、腾讯应用宝、豌豆荚、华为应用商店、OPPO 应用商店、VIVO 应用商店、魅族应用商店和联想开发者社区。
3.1 采集数据筛选
图2 和图3 展示了来自360 手机助手的一款应用——摩拜单车APP 的应用信息和应用评价。

Fig.2 Application information of Mobike APP of 360 mobile assistant图2 360 手机助手中摩拜单车APP 的应用信息
Fig.3 Comments on Mobike APP of 360 mobile assistant图3 360 手机助手中摩拜单车APP 的评论信息
图2 显示包含应用名称、应用综合评分、总评价数目、下载次数等在内的APP 的基本信息。综合评分、总评价数目和下载次数较为重要,可以表明应用的受欢迎程度和热度。
图3 的评论信息则包含了详细的用户使用情况和感受评价。评价的总体态度是一个离散的情感倾向值,分别是好评、中评和差评。
本文从其他应用商店中搜集整理APP 应用的总体信息界面和详细评论页面总结,最终决定采集APP应用介绍、大小、分类、标签等基本信息和更新记录、综合评分/评星、评论详细文本内容、评价时间等评论信息。由于APP 评论还在不断更新,本文采集到自2016 年8 月8 日起至2017 年10 月15 日的评论数据和版本更新数据信息,并基于此加以研究。
3.2 数据预处理
首先对于如应用介绍、大小、标签等APP 基本信息进行表格汇总,其次,对于APP 更新记录信息,以统计表的形式展示版本、更新日期和更新日志。最后针对详细评论信息,本文构建一张数据表对评论数据进行结构化处理和存储,如图4 所示,评论数据表项为:评论日期、应用商店、评论用户名、评星、评价详细内容。
Fig.4 Display of database table entries图4 数据库表项展示
4 基于KANO 模型的用户需求分析
本章基于采集处理的APP 评论数据对用户需求进行分析。
如图5 所示,针对用户需求进行分析的基本步骤为:(1)属性识别。构建包含APP 属性的属性词典,包含无效评论的过滤。(2)情感分析。评论文本的情绪倾向识别,完成评论者对APP 属性的具体感情倾向的识别。(3)需求权重分析。基于评论整体感情倾向和属性情感倾向联合分析,确定用户需求的不同权重。
4.1 属性识别和情感分析
4.1.1 属性词典的构建
本文通过分词将评论中的属性词汇分割,然后根据TextRank 算法根据频率和术语的语义关系对术语进行排序。算法1 属性词典的建立方式描述如下:
算法1 属性词典的建立
输入:评论数据库中的数据表。
输出:候选属性、相应词频。
步骤1 连接读取数据库中的数据表,读取原始评论语句;
步骤2 使用正则匹配过滤无效字符或字符串;
步骤3 文本分词,使用结巴分词以默认模式分词并划分词性,移除停用词;
步骤4 词频统计与展示,对分词结果统计,提取APP 相关词频最高的名词,作为候选属性词云展示。
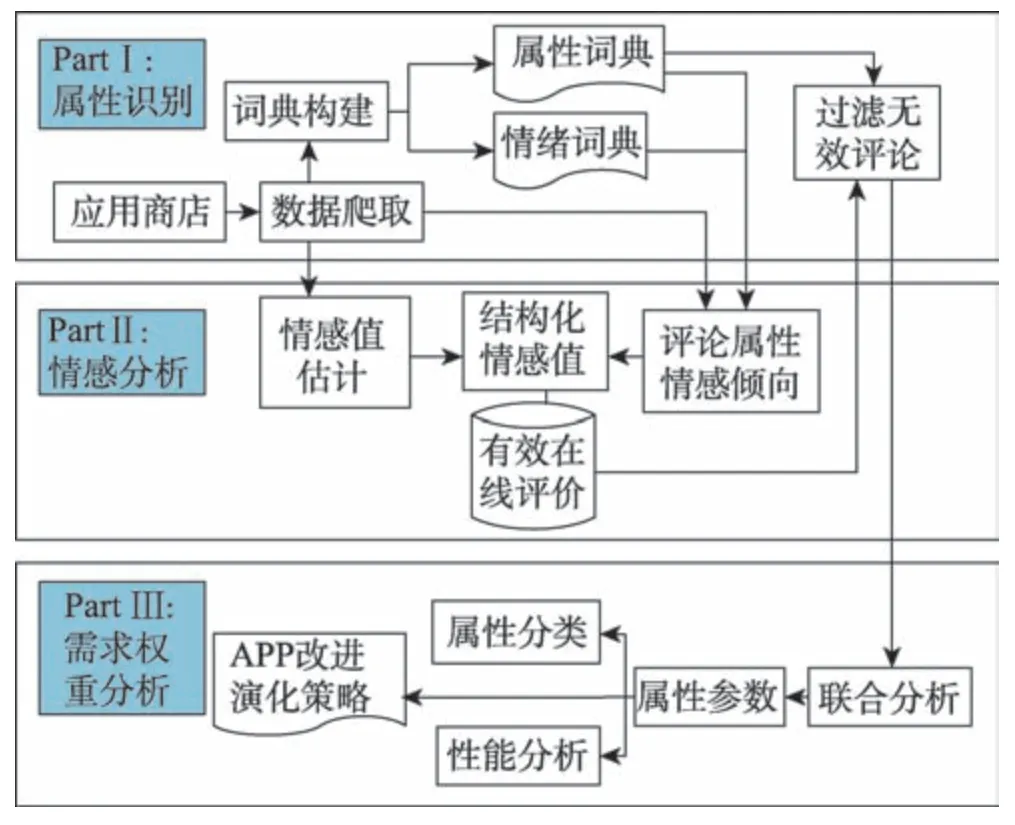
Fig.5 Analysis framework of user demand measurement图5 用户需求计量分析框架
算法1 步骤2 中提到无效字符的过滤,如标点符号等,在分词过程中不仅是无实际意义的,反而还会造成分词效果混乱。步骤3 中文本分词后创建一个列表存储分词片段和词性分类。这个过程需要注意移除停用词。停用词是指高频无效词和低频错误词,即在文本集合中出现次数较多但无实际意义的词,如“的”“等”“这”等,目前中文的停用词词库暂时还没有,通过语料查询,搜集整理了包含特殊符号在内的1 894 个中文停用词作备用。
结果共提取了500 个术语作为候选属性,经过咨询、排查和筛选,过滤与APP 相关的属性项分为15 个类别,构建了候选属性的词汇表。表1 给出筛选属性和出现频数统计情况,制作相应的词云图案如图6所示。
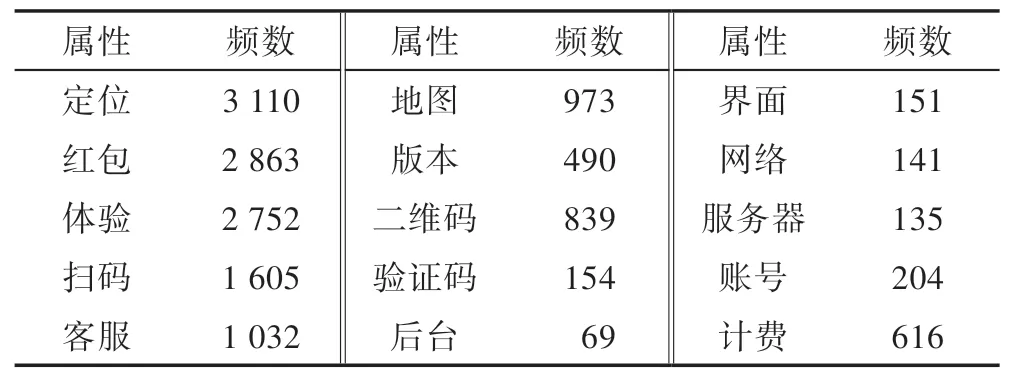
Table 1 Frequency statistics of selected attributes表1 筛选属性的频数统计
4.1.2 属性词典的构建
情感识别是一项专门且精细的任务,需要进行细粒度的情感分析处理。由于汉语语法的原因,针对评论作观点词性总结。

Fig.6 Word cloud display of selected attributes图6 候选属性词云展示图
一般说来,陈述性质的用户评论具有相似的固定的句式结构。表2 列举了一些常见的评论观点句式,可以发现属性观点的倾向主要与形容属性的形容词的情感倾向相关,还与一些具有否定意义的助词“不”“否”“无”等意义联系紧密。利用这样的规则可以简单有效地提取出用户评论对于具体属性的态度和情感倾向。

Table 2 Sentence structures of common APP reviews表2 一些常见的APP 评论句式
以算法1 属性词典的建立方式筛选形容词分类,结合知网Hownet 情感词典(http://www.keenage.com/html/c_bulletin_2007.htm)给出的中文情感分析用语词集,构建一个情感词典,其中包含7 425 个词的情感词汇,如表3 所示。
对于否定意义的助词的判断,本文搜集整理出一个否定意义词词库,共42 个词,如:不、不是、不可、别、没、莫、无、勿、休等。因为在汉语文法当中双重否定表示肯定,需统计否定词的个数看其奇偶性来改变情感倾向状态,所以需要统计否定意义词汇个数对情感倾向判定,最终会得到每条评论中包含的属性及其明确的感情倾向。算法2 整体思路如下:

Table 3 Classification of emotions and the number of their related terms表3 情感分类和相关术语数量
算法2 属性情感倾向的判断
输入:原始评论、筛选属性、肯定/否定情感倾向词典、否定意义词词库。
输出:评论中属性的情感倾向。
步骤1 将评论分词,以列表的形式记录;
步骤2 对分词列表进行扫描,找到属性词,并记录其位置,并在其所在的评论分句中查找情感词;
夏冰扶着栏杆轻轻爬上平台。范坚强和一杭正在对饮。范坚强抬头看到他,大吃一惊:“你怎么在这里?”夏冰见被发现,便不再躲藏,大摇大摆走到范坚强旁边坐下。“我闻到酒香,就进来了。”说完,抓起桌上的酒瓶,对着瓶口喝了一大口,又将一块牛排塞在嘴里。
步骤3 查词典得到情感词所代表的情感倾向,并存储其情感倾向状态;
步骤4 在分句中查找是否包含有否定词,如果有且是奇数个否定词,则将情感倾向状态改变;
步骤5 循环执行1~4 步,直至遍历所有的评论。
令h{pos,neg}代表属性各自的情感,使用式(1)将数据转化为二值数据:
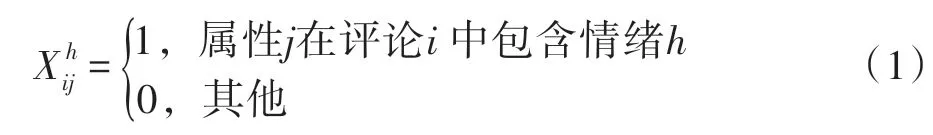
也就是说,当属性j在评论i中包含肯定情感倾向时,;当属性j在评论i中包含否定情感倾向时,;当同时为0,那么评论i不包含属性j,即其为空值。这样就将其结构化,评论情感分析结果如表4 所示。
Table 4 Results of attribute extraction and emotional analysis of every comment表4 每条评论中属性提取和情感分析的结果
于是可以得到数据集D1={x},其中x是一个顾客对不同属性的情绪倾向的30 维的行向量。
应用商店对于评论文本整体而言,文本所体现的情感与用户真实体验更为一致。因为用户在填写评论时候,会相对仔细回忆使用体验,并写下印象最为深刻的相关部分。因此,应用自然语言处理技术来推断文本的情绪,使用Snow NLP 工具包(https://pypi.org/project/snownlp/0.11.1/)可以方便地处理中文文本的情感值,工具对每条评论的情感值进行评估预测,设其预测值为ye,其取值范围为[0,1]。设置一个离散集合{-1,0,1}分别表示否定情绪、中性和肯定情绪:

这样可以得到一个新的数据集D2={y},表示评论文本整体的情感倾向。
4.2 KANO 模型分析用户需求权重
本节主要使用联合分析的方法来衡量产品属性对用户的影响[34]。上一节中,使用情感识别将评论转换为包含某些属性情感倾向的二值化数据。每个属性都有三个离散情感值:肯定倾向、否定倾向和缺失值。KANO 模型揭示了用户满意度不会随着属性水平而改变,因此在快速迭代变化的APP 中,确定理想的模式和状态是不可能的,从而本文将每一项评论作为用户需求情感值的刺激,将文本包含的情感倾向作为用户体验。

其中,y是用户体验;同式(1);是对肯定情绪的偏好值,是对否定情绪的偏好值,如果情绪为缺失值,那么默认的权值为0。由式(3)可以估计参数值。对于每个属性,有3 个观测值:。通过这3 个观测点并结合图1,可以根据KANO 模型将属性映射到不同类别上。下面给出映射规则,在此之前,首先需要建立两个基本变量:

在此基础上可以给出每个属性的权重为:
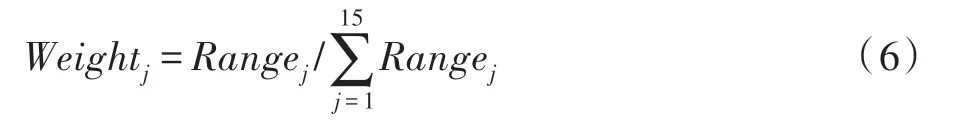
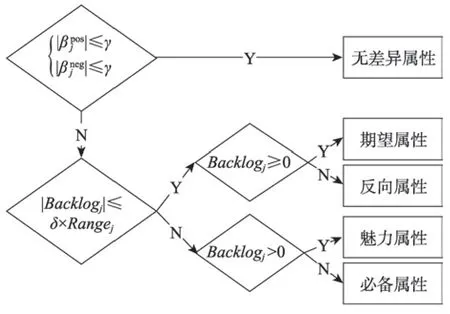
Fig.7 Mapping rules for results of KANO model图7 KANO 模型的映射规则
4.3 实验结果分析
4.3.1 模型的结果
根据属性词典和情感识别结果,使用线性回归方法,估计出各个属性在两种情感倾向下的权重,再将其利用图7 的映射规则对属性进行归类,得到对应KANO 模型的分类结果。在参数估计中选用12 719条有效评论,得到估计参数的结果如表5 所示。
4.3.2 演化策略及其有效性分析
将估计参数代入式(4)和式(5)中,映射得到KANO 模型的属性分类,如表6 所示。
大多数属性被标识为必备属性,包括:网络、服务器、后台、红包、客服、地图、计费、扫码、二维码、版本、界面和验证码。缺少这些属性,会引起用户极大的不满,因此要在APP 升级演化过程中发现用户的需要,如:快速稳定的网络连接;流畅的后台和服务器的工作;真实的红包优惠;及时的客服处理;精准的地图服务;便利的扫码过程和清晰明显的二维码;合理即关即停的计费模块;性能稳定的版本更新;快捷的验证码发送。如果能对这些必备属性先改进优化,必能大大减少负面评论的数量,有助于APP 良性发展。
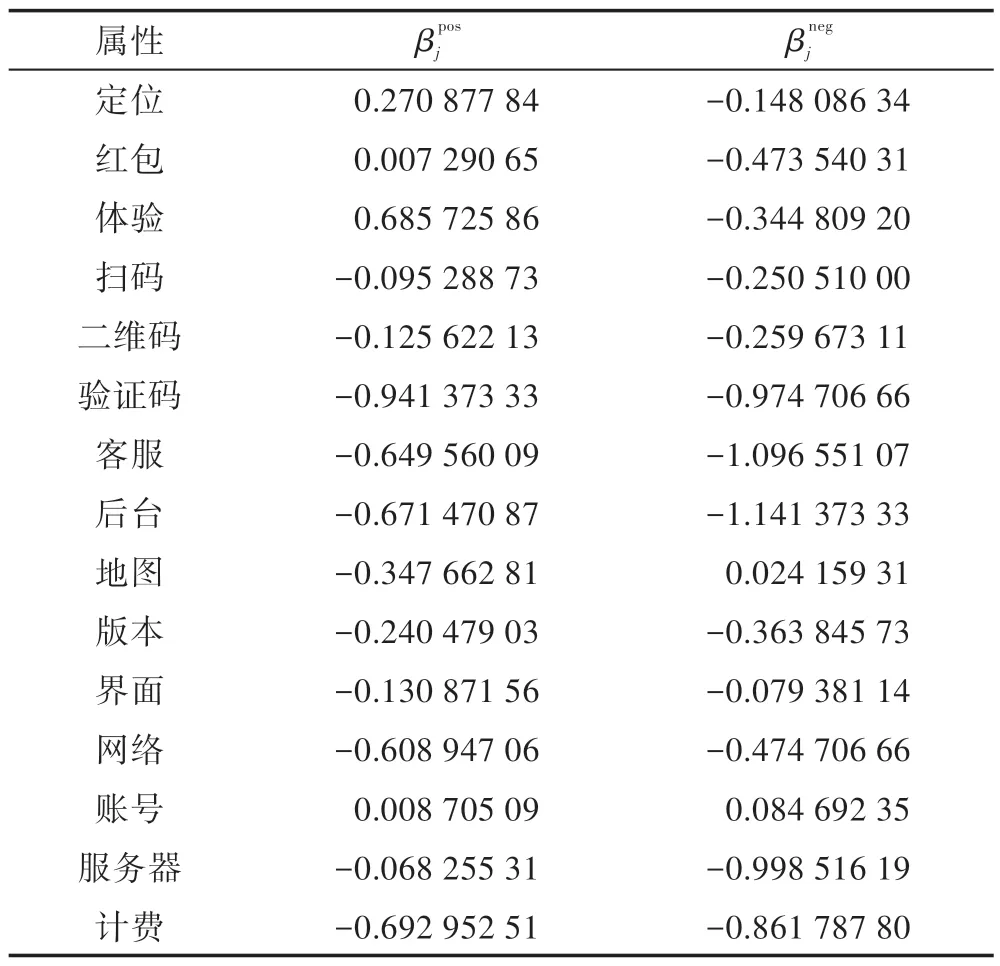
Table 5 Estimated parameters of conjoint analysis表5 联合分析估计参数
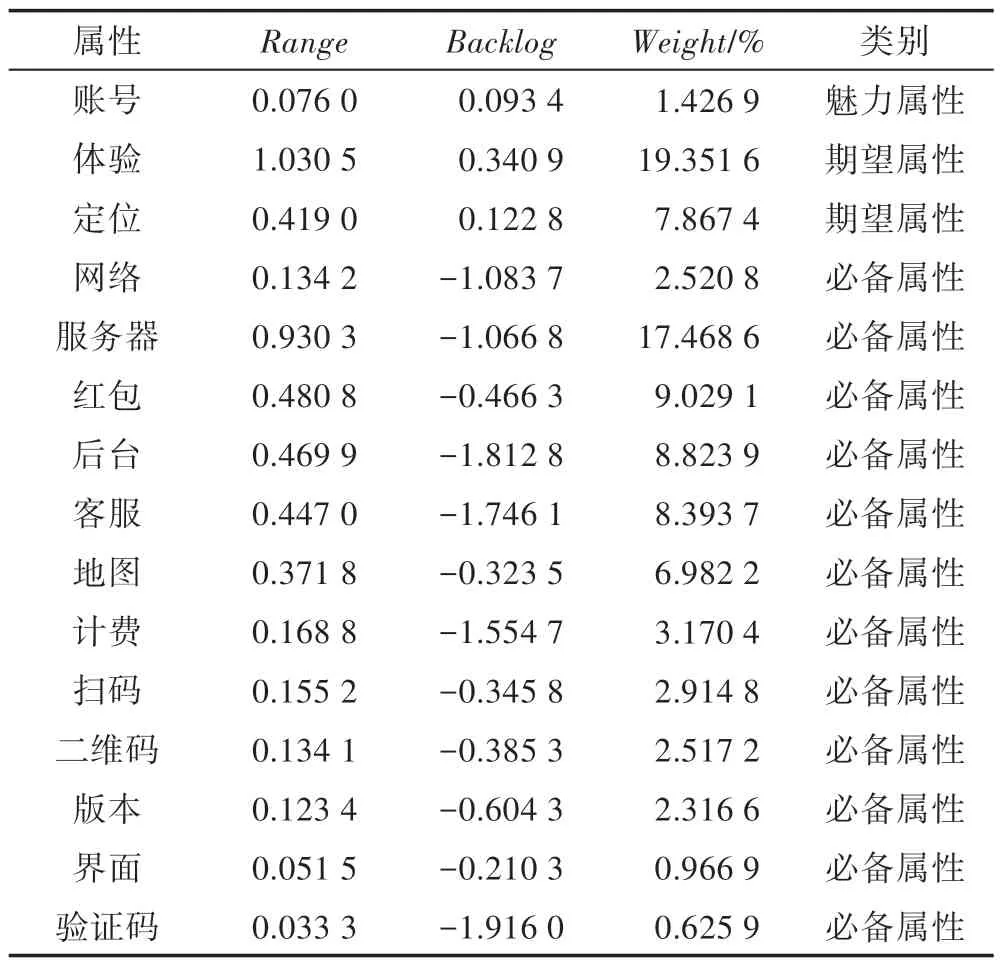
Table 6 Category of each attribute表6 每个属性的类别
体验和定位是期望属性,它们的变化与满意度呈现正线性关系。有关这些属性的评论,用户表现出多是反馈和建议,希望开发者对其进一步改进优化。这一类属性的负面评价略微多于正面评价,情感相比必备属性的评论情感缓和许多。如果能在其原有基础上适当改进,会提升APP 的用户粘度,帮助APP 平稳迭代。
魅力属性包括账号。这些属性可以极大地提高满足度,但是在不满足的时候,也不会造成严重的满意度下降。评论中大量用户提到一个账户可以支持多开几辆自行车,因此运营商应该逐步考虑实现该需求。
从总体来看,开发者应该首先满足必备属性和期望属性的需求。摩拜单车APP 于2017 年12 月15日发布6.5.0 版本的更新日志显示:“摩拜单车APP 终于等到一个很大很棒的更新啦!设计师们这一次投入了很多精力哦~更快:扫码开锁速度、地图加载更快;更轻:简单易懂的操作界面;更美:设计大改版,优化调整40 余处细节,去下载骑车体验一个。”可以发现模型分词所给出的策略与后续官方更新日志基本吻合,可以认定本文所给出的演化策略是合理或有效的。
将收集到的所有评论,按照日期取情感预测值的评论值和整体的平均值,结合APP 版本升级日期的标签,如图8 所示。
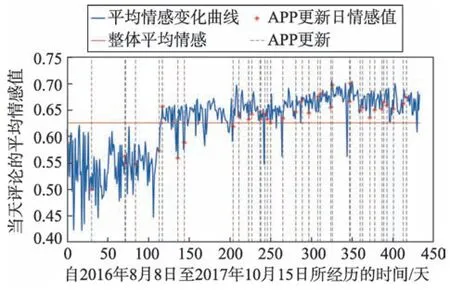
Fig.8 Average emotional value curve of comments on Mobike APP from Aug 8,2016 to Oct 15,2017图8 自2016 年8 月8 日至2017 年10 月15 日摩拜单车评论的平均情感值变化曲线
该图展示出自2016 年8 月以来,该款APP 持续稳定更新,先前平均情感值稳定在0.55 附近,随着APP 不断的版本更新升级,平均情感值大大提升,整体平均情感值为0.659,并且情感值曲线在0.65 附近波动。可见,APP 版本更新使得用户评论的平均情感值提升,用户体验有所改善。
4.3.3 模型的鲁棒性分析
为了测试模型鲁棒性,将样本随机分成5 种样本,并将其逐一加入到训练集中,计算属性的范围和权重,并比较属性排名。
由表7 可以发现随机输入模型的样本数量达到全部(5/5)时,属性的权重排序和模型原输入样本得到的结果稍有差别,原因是由于在进行参数估计的时候使用了scikit-learn 库中的Cross-validation 模型。该模型对输入的有限数据集进行打乱,分为训练集和测试集,本文的实验设置测试集的比率是20%,由于算法自身随机抽取测试集的特点,每次选取的测试数据不同,导致最终结果稍有差异。如表7所示,起初属性的排名波动差异较大,然而随着样本的不断添加,模型性能逐渐保持一致,属性的级别排名逐渐稳定,模型鲁棒性得以检验。
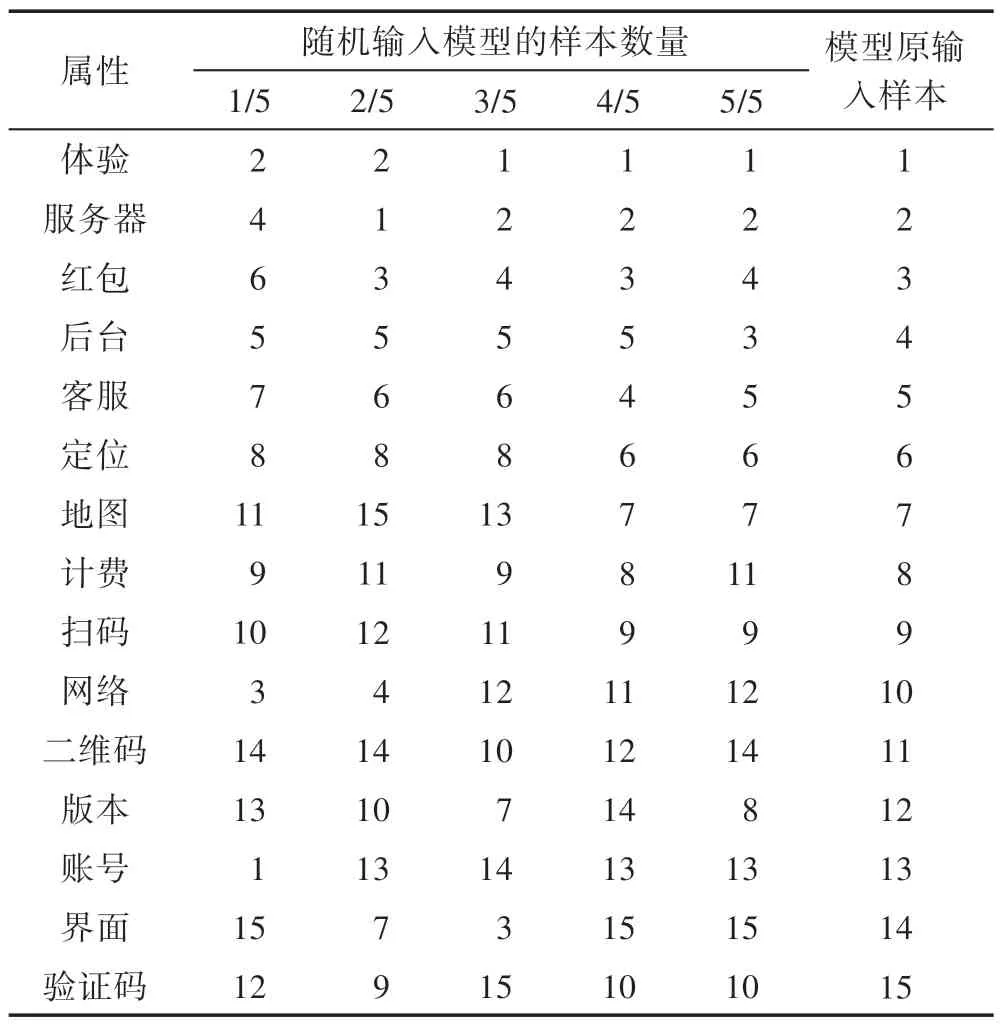
Table 7 Attribute weight ranking changes with the addition of training sample size表7 属性随加入训练样本量变化的权重排名
4.4 模型推广
本文将此模型应用到高德地图APP 的评论数据之上,得到导航类APP 的演化改进策略。
首先选取评论与该类APP 演化相关的属性,经过咨询、筛查,最终确定10 个属性为定位、路线、信号、版本、语音、离线、路况、界面、权限和体验。按照4.2 节的实验方法,对这些属性进行权重的参数估计,然后将其映射到KANO模型上,得到结果如表8所示。
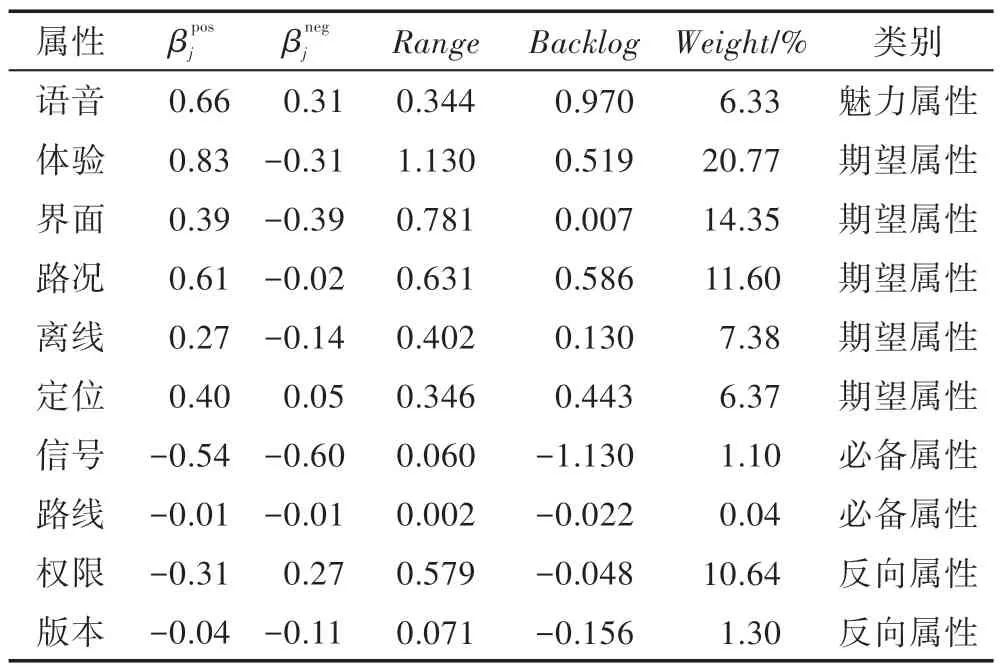
Table 8 Results of mapping attributes of navigation class APPs'comments to KANO model表8 将导航类应用评论属性映射到KANO 模型的结果
对于如高德等导航类APP 而言,魅力属性是语音,APP 开发者应该考虑颇具特色的明星代言语音播报会十分吸引用户下载使用。
划分为期望属性的是体验、界面、路况、离线和定位。这几个属性的完善情况和用户的满意度是呈线性关系的,APP 开发者应该考虑对其功能更新完善。
信号和路线被归类为必备属性,可见相对于上述属性,用户在使用过程中对GPS 信号和路线推荐十分不满意。对于开发者而言,应该重视这类问题,尽早优化推荐路线的算法和GPS 信号弱的缺陷问题。
在所有的属性中出现了两个反向属性,分别是权限和版本。用户评论普遍表现出的是拒绝该导航类APP 获取不必要的手机高级权限和对APP 频繁更新版本的行为极其反感。APP 开发者应该适当减少版本更新频率,实现稳步迭代,此外应注意保护用户隐私,在获取手机高级权限前需满足隐私协议并询问征求用户意见。
总体来看,对于如高德地图等导航类APP,应首要处理用户权限的访问问题,并降低APP 版本更新频率,其次应优化路线推荐算法和增强接收信号的强度。在此基础上,不断对界面、离线地图、路况和定位进行完善,并保持明星语音播报素材包的更新热度。高德导航APP 于2017 年9 月22 日发布8.1.8.2132 版本的更新日志显示:“【亮点】1、明星语音新选择,地图搜“高晓松语音”可下载使用;2、骑行规划支持多种方案,总有一种适合您。【优化】1、异地热门城市使用搜索首页,即获精彩推荐;2、任意地标酒店轻松搜索,为您推荐专属房型。”其中所体现的新明星语音、路线多方案规划、界面优化等与本文提出的更新策略相吻合,因此可以认为模型是有效且合理的。
5 结束语
本文主要基于群智数据——APP 用户评论数据进行分析,使用联合分析方法,引入KANO 模型评估不同属性的重要程度,从开发者的角度对APP 提出演化策略,并证明了模型的鲁棒性和策略的合理性。
不足之处是:研究过程是建立在评论者偏好一致的假设上进行总体的分析,并且模型在一定程度上受到各应用商店的评论源数据的限制。因此如果能在情感估计前使用主题聚类的方法或结合其他数据源进行多源分析,可能会提高模型的效果。
