大数据背景下大学生就业网络精准化服务模式研究
2020-01-08拜亚萌
拜亚萌
(焦作大学,河南 焦作454000)
随着高等教育普及,高校毕业生人数日益增多,高校就业工作的压力也变得越来越严峻。 国家层面和高校层面均出台相应政策,不断完善就业信息服务体系,提升就业工作效率与服务质量[1]。 大学生网络就业信息服务就是通过各类就业网站获取相应的求职信息,但目前大多数就业网站在个性化服务内容、岗位精准匹配等方面存在不足,如何解决大学生就业难和企业招聘人才难的问题,已经成为大学生就业网络服务模式研究的一项重要内容[2-3]。
运用大数据分析技术对海量就业信息数据进行挖掘处理,从而获取具有价值的就业信息,提升高校毕业生精准就业服务水平, 成为大数据背景下高校精准就业服务工作的重点之一。 本文正是基于此目的,以大数据分析技术为基础,优化构建一种多层结构的就业网络精准化服务模式。
1. 就业网络信息服务模式设计思路
在就业网络招聘领域,求职用户和招聘企业构成了供求关系, 本文将两者作为研究主体,分析得到不同主体所具备的对应属性信息[4]。其中,求职用户的简历类资源主要包括客观特征和主观意向,客观特征主要指基本信息、技能特长、教育水平、工作经历等客观属性,主观意向则包括期望职业、期望行业、期望公司类别以及期望工作地等相关属性。而招聘企业中的职位类资源需求,同样又包括岗位客观需求以及岗位主观要求[5-6]。 其中,岗位客观需求则主要对应聘者的基本信息、教育水平、工作经历以及技能水平进行客观性约束,岗位主观要求则针对职位所属行业、 公司所属行业、公司性质、职位所在地等主观因素。 图1 描述了求职用户简历类资源和招聘企业职位类资源的不同属性之间的对应关系。
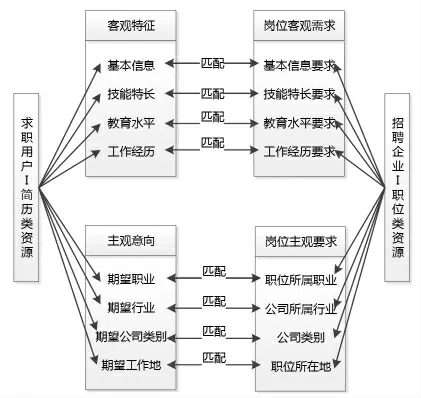
图1 简历类资源与职位类资源的对应关系
简历类资源和职位类资源中的某些属性之间存在联系。 其中,求职用户的客观特征属性与招聘职位所需的能力要求之间存在对应关系,求职者的期望属性与岗位主观要求之间也存在对应关系。 因此,本文正是基于此思路,通过采集简历类资源和职位类资源中的关键属性值,对用户与就业信息数据向量进行匹配计算,根据匹配结果,对权重推荐度进行排序,取相似度靠前的推荐结果推荐给用户,从而完成就业网络信息服务模式的精准化推荐操作。
2. 就业网络信息服务模式构建方案
针对目前就业网络信息服务中普遍存在的就业冗余信息多、就业信息不匹配、就业信息时效性差以及推荐系统不完善等问题,重点对就业网络信息服务平台、精准化就业服务推荐模型以及个性化推荐算法的设计过程进行了阐述。
2.1 就业网络信息服务平台总体设计
就业网络信息服务平台是实现大学生就业网络精准化服务模式的重要载体,该平台可为不同用户提供一站式就业信息服务。 设计思路采用分层架构思想, 自上而下分为信息服务平台层、信息服务策略层、信息数据仓库层。 每个层次又根据实际业务需求划分为不同功能模块,通过面向对象服务设计模式,使得不同功能模块之间具备低耦合、可扩展等良好的技术特性。 图2 描述了就业网络信息服务平台的体系模型结构。
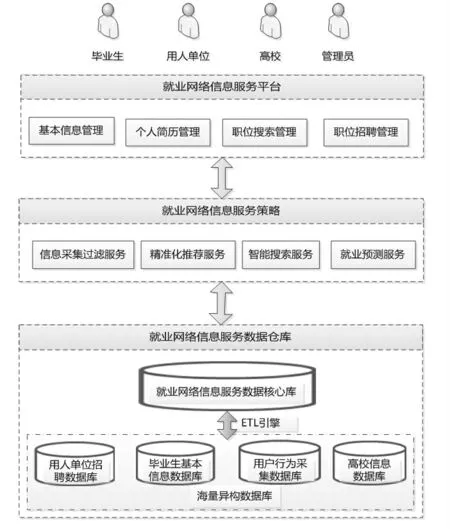
图2 大学生就业网络信息服务平台体系框架
2.1.1 服务平台层
该层以就业信息服务网站的方式为求职者和用人单位等相关主体用户提供访问各种业务的操作, 同时通过该层实现交互式的访问操作。另外, 该层还负责收集就业信息和基础数据,包括求职用户和企业用户的客观属性和主观需求所涉及的相关数据信息,并将相应数据转换为对应技能或就业需求。 该层主要向用户提供各种就业信息服务,包括个人简历管理、个性化搜索管理、职业规划管理、技能评估管理等多个核心模块和基本的服务功能。
2.1.2 服务策略层
该层负责对服务平台层所涉及的各种业务进行分析和计算,并将计算结果以策略的方式呈现给用户。 该层以大数据分析、数据挖掘技术为技术支撑,构建信息采集、过滤、精准化推荐、智能搜索、就业预测分析等不同的服务策略。
其中,信息采集过滤服务主要负责对用户求职行为(点击、申请、收藏、浏览)以及个人基本信息、简历信息等数据进行清洗、转化、过滤等操作,为数据分析提供规范化的数据集合。 精准化推荐的核心是协同过滤推荐引擎算法,根据求职用户的兴趣爱好、 期望职业等主观意愿信息,预测用户实际需求, 并检索出相应的就业服务信息,主动为用户提供各种个性化就业相关的服务信息。 智能搜索引擎服务则通过搜索引擎接收用户信息,分析就业信息需求,并通过协同过滤推荐算法,在本地数据库中进行信息匹配,将得到的匹配信息汇总,从而为用户提供所需的搜索服务。 就业预测分析则主要通过个性化推荐引擎算法, 计算与目标求职者具有相似行为的其他用户, 并获取相似用户的求职行为和职位获取信息,并将该信息作为个性化推荐信息推送给目标求职者,从而完成就业趋势预测分析等服务。
2.1.3 数据仓库层
数据仓库层主要由海量异构数据仓库、就业网络信息服务核心数据库以及数据ETL 引擎三部分组成,其主要功能是负责为服务策略层提供必要的数据信息。 其中,海量易购数据仓库则由用人单位招聘数据库、 毕业生基本信息数据库、用户行为采集数据库、高校毕业生信息数据库构成。 ETL 引擎则是该层的核心,将各种异构数据库的数据进行抽取、清洗、转换、聚合后加载到核心数据库中,为上层的数据挖掘和联机分析提供必要的基础数据。
2.2 精准化就业服务推荐模型设计
就业信息推荐模型是整个就业网络服务平台的核心,也是服务策略层的重要组件之一。 在该模型中分别针对求职用户和招聘企业进行内容属性提取,并构建各自相应的用户模型,再通过推荐引擎(内容匹配器)完成信息匹配,从而对求职者的真实求职意图进行预测和推荐。 图3 则是精准化就业服务推荐模型的工作流程,就业服务推荐模型工作步骤描述如下。
(1)采集信息:分别获取求职用户简历类资源信息以及招聘企业岗位需求类资源信息。 其中,用户资源包括个人基本信息等显式数据以及用户行为等隐式数据,岗位需求类资源则主要包括岗位客观需求和岗位主观需求等数据信息。
(2)创建模型:面向求职用户和招聘企业,分别创建求职用户基本模型、用户行为模型和职位需求模型。
(3)抽取集合:从所创建的资源模型中抽取由主观兴趣和客观特征组成的关键属性集合,并将对应的关键属性值存储到就业信息核心数据库中,生成各自属性向量集。
(4)数据处理:利用用户协同过滤推荐算法,对用户和就业信息数据向量进行匹配计算。
(5)结果推荐:根据匹配结果,对权重推荐度进行排序, 取相似度靠前的推荐结果推荐给用户,从而获取职位推荐信息。
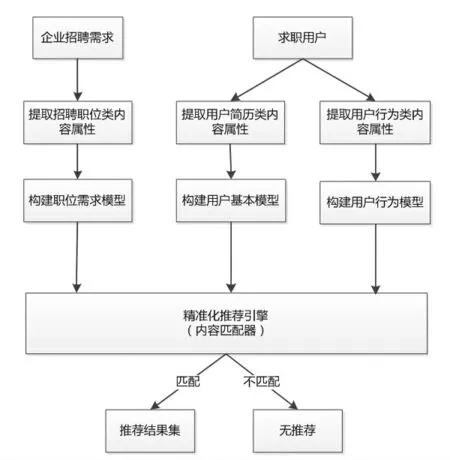
图3 精准化就业服务推荐流程
其中,用户行为数据的采集主要包括显式数据和隐式数据。 显式数据包括个人基本信息、学历专业、兴趣爱好等用户注册所提交的静态数据信息。 而隐式数据则主要指求职者通过点击、浏览、搜索、查询、收藏等行为所产生的行为数据信息。 通过对上述两类数据信息的采集,并进行数据清洗、转化、筛选等预处理,减少无效数据的参与量,降低模型计算量。 然后,根据用户行为数据,采用用户画像技术,构建用户模型。 最后,通过推荐引擎(内容匹配器)完成职位信息的推荐。
本文采用协同过滤推荐算法作为推荐引擎的核心算法,首先对用户显式数据和隐式数据进行采集,并对采集的数据进行数据建模,计算分析出与目标求职者类似的相似用户;最后,将相似用户所具有的求职行为作为目标求职者的匹配结果,输出职位推荐结果,从而实现个性化推荐。 该算法是在基于内容和规则的推荐算法基础之上进行的改进,相比传统的基于文本的推荐算法,协同过滤推荐算法在数据依赖度、数据模型创建、 数据集合采集等性能方面均有较大的提高。 同时,协同过滤推荐算法的最大优势在于对用户隐式数据的分析和处理,从而可以从更多维度提升推荐结果的精准性。
3. 就业网络信息服务模式保障体系
高校毕业生就业网络信息服务模式是一个综合性的服务系统,除了需要专业的技术支持之外,还需要从丰富就业资源、改进信息技术、完善就业指导体系、 加强就业信息服务队伍建设、扩大机构合作等五个方面提供相应的保障机制。
(1)高质量的就业信息资源。 传统就业信息服务模式已经不能满足高校毕业生的就业需求,要构建满足不同学历层次的毕业生就业信息资源库,同时对就业信息进行细化分类,形成横向和纵向布局、 专业和爱好交叉的信息分类模式。加强对异构就业资源信息库的统一化管理,对各类数据资源进行标准化、规范化处理,更好实现就业信息资源的最优化配置。
(2)改进个性化的信息服务技术。 要充分利用信息过滤技术、移动互联网、云计算技术、WEB数据挖掘技术、 大数据分析等智能信息技术,针对大学生就业网络信息服务实际需求,改进就业网络信息服务模式,优化个性化推荐引擎和推荐策略,不断提高大学生对个性化就业信息服务的满意度。
(3)完善高校毕业生就业指导体系。 各个高校要重视大学生职前培训,加强学校和学生之间的联系, 更多地获取大学生的各种就业需求,进一步了解当前大学生在就业、择业过程中面临的各种实际问题。 将专业知识与企业岗位技能需求之间的关系进行重新梳理,一方面可以通过优化高校课程体系及培养方案,更高效地为企业培养各种急需人才,另一方面,通过收集各类毕业生就业信息数据,更好地优化就业网络信息服务模式, 进而更好地完善高校毕业生的就业服务体系。
(4)加强就业信息服务队伍建设。 就业信息服务队伍建设也是确保就业信息服务模式顺利开展的重要环节,要建立不同技术水平和服务能力的就业信息服务人员梯队,围绕大学生就业信息实际需求,形成技术开发、需求调研、培训管理为一体的初级、中级、高级三类人才体系。 只有不断加强技术人才储备,定期开展技术交流和业务培训,才能不断完善技术服务水平,应对来自不同层面的竞争和压力,为高校毕业生就业信息服务提供更为满意的服务。
(5)扩大机构合作共享。 为提高推荐模型的精准度,还需要提供更多的学习样本数据,这就要求不同的就业信息服务平台、服务机构和各个高校要打破界限,加强合作交流,提供更多的就业信息数据和职位需求信息, 提高资源利用率。另外,在不断增加数据资源数量的同时,还要确保数据的质量,制订标准化的数据格式,提高数据的有效性。
4. 结束语
在本课题的研究过程中, 通过问卷调查、门户网站调研、高校走访等方式,明确高校毕业生的就业网络信息服务需求。 利用云计算架构、大数据分析等技术, 釆用自顶向下的分层设计思想, 优化高校毕业生就业网络信息服务模式,提出个性化推荐算法来弥补当前就业信息服务中求职用户与就业信息不匹配问题,为个性化推荐系统在就业信息服务领域的应用作参考,进而为就业信息实现精准化推荐服务提供解决思路。
该服务模式运用大数据分析技术挖掘就业相关数据的潜在价值,将大数据相关技术应用于高校就业工作,能够更好地分析人才市场供需不匹配的现象,为高校毕业生个性化就业指导提供更加客观、科学、准确的数据、算法和模型支撑,为毕业生提供精准化的就业推荐和就业指导服务,进而提高就业工作服务质量和效率。
