带参数学习的引导信号迭代学习控制方法
2019-12-23黄静郑华义李宏李国岫邱成
黄静, 郑华义, 李宏, 李国岫, 邱成
(1.北京交通大学 机械与电子控制工程学院, 北京 100044; 2.北京精密机电控制设备研究所, 北京 100076)
0 引言
在航空航天领域中,飞行器空气舵的主要作用是控制飞行器的飞行姿态以及调整与改变飞行轨迹,其性能好坏直接影响飞行器的控制精度和稳定性。
空气舵负载模拟器是空气舵的重要地面试验设备,用于模拟空气舵在飞行过程中所承受的载荷,为空气舵地面试验提供可靠的试验保障和技术支持。随着我国航天和国防事业的大力发展,对飞行器提出了更高的要求,研究能够精确复现飞行过程中力学条件的空气舵负载模拟器势在必行。而空气舵负载模拟器在加载试验中,会经常加载一些连续性、周期性负载,例如正弦信号、三角波信号、方波信号等。在加载过程中,除了加载系统的运动以外,空气舵本身也会进行独立的运动,二者运动是通过某些连接件耦合在一起的,因此给加载端控制带来了极大的挑战和难度。
本文研究的负载模拟器结构示意图如图1所示。从图1中可以看出,加载系统和承载系统(空气舵作动器)通过摇臂连接在一起,在空气舵作动器独立运动过程中,需要加载系统加载上所要求的模拟载荷。针对空气舵负载模拟器所加载的负载具备周期性特点,期望找到一种带有学习能力的智能型控制方法,以适应空气舵地面负载试验的要求。
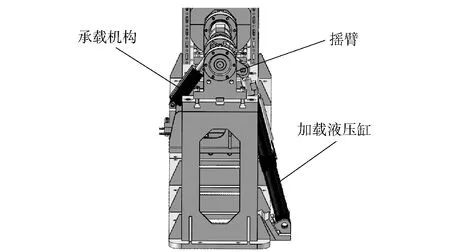
图1 系统结构示意图Fig.1 Schematic diagram of load simulator structure
在控制领域中,日本学者Uchiyama[1]最早于1978年基于迭代学习思想提出迭代学习控制(ILC)方法,随后在1984年Arimoto等[2]正式提出该方法的理论框架并发展至今,如今迭代控制方法依然是智能控制领域的一个重要研究领域[3-6]和研究热点[7-11]。
但是在ILC理论中,虽然理论上能够证明其控制误差最终收敛,但是对中间过程的误差却没有限制和要求。而在实际工程应用中,即使误差最终收敛,若是中间过程的误差过大,也是不能接受的[12]。将传统ILC方法应用于空气舵负载模拟器的液压控制系统中,尝试跟踪一个正弦信号,其系统输出如图2所示。
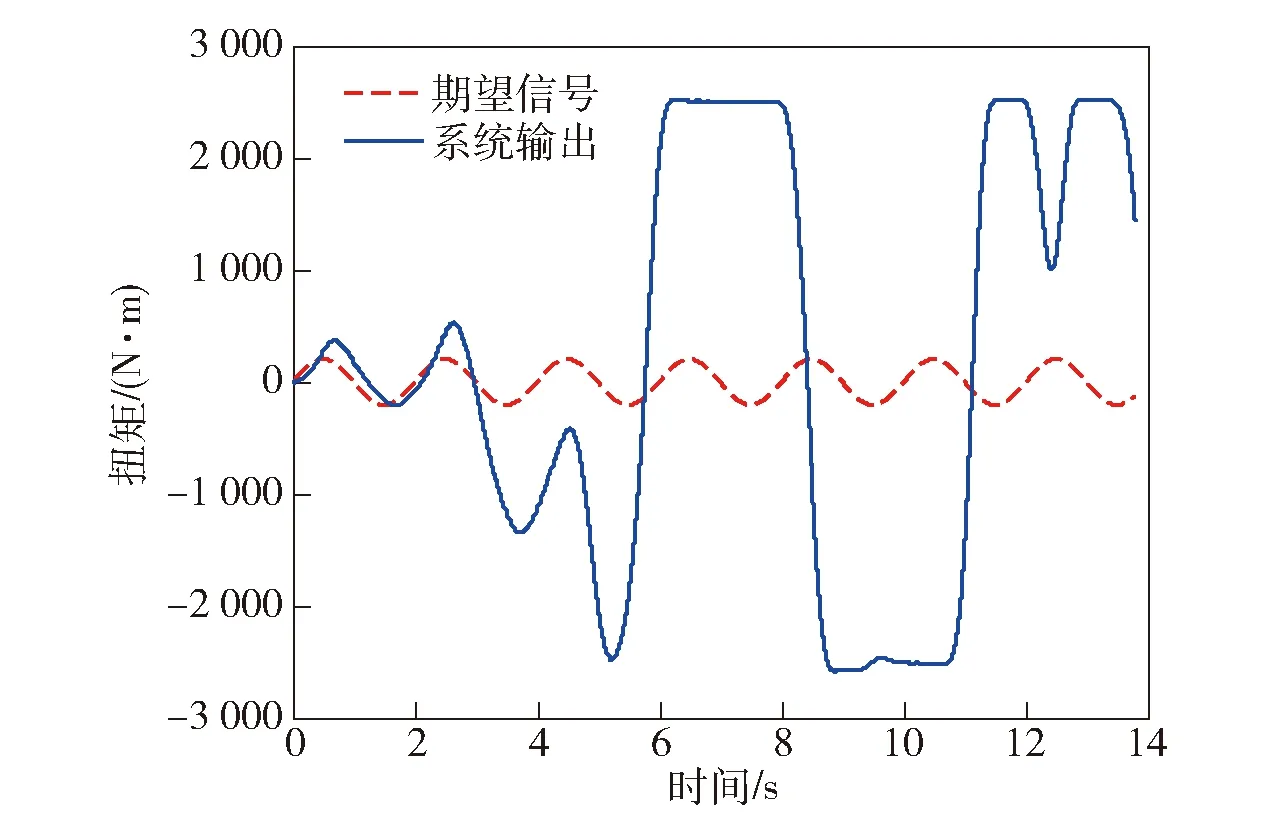
图2 传统迭代学习实际系统输出Fig.2 Traditional iterative learning output in real system
从图2中可以看出,系统在第2个周期后,误差越来越大,系统逐渐失控。究其原因,主要有两点:一是迭代学习控制理论中,一般都要求或假设每个周期的初始状态是严格一致的,但是这一点在实际系统中很难做到;二是因为实际控制系统中,输入信号和输出信号之间存在一定的相位延迟,传统ILC一般都未考虑相位因素的影响,在实际应用过程中,相位延迟也会对“经验学习”有重要影响。
针对以上问题,本文尝试保留ILC的优点,即智能性和实现简单性,提出部分改进,希望解决传统迭代控制方法中中间过程误差较大、系统不受控的问题,同时使得新的ILC方法具备更快的收敛速度和更好的控制效果。
1 引导信号ILC方法的提出
控制系统一般有多种数学表示方法,若采用状态方程表示方法,则离散的控制系统可以写为(1)式的形式:
(1)
式中:k=1,2,3,…表示迭代次数;xk(t)、uk(t)、yk(t)分别表示系统第k次的状态向量、输入向量和输出向量;xki(t)表示第k次迭代时系统的第i个状态;A、B、C为系统的系数矩阵。
传统ILC方法表达式如(2)式所示:
(2)
式中:ek(t)为系统第k次迭代的控制误差向量;yd(t)为系统的期望信号向量;f(·)函数代表某种迭代学习律。
利用误差向量ek(t)和输入向量uk(t),通过设计或构建的学习律,便可以产生第k+1次的输入向量uk+1(t)。从(2)式中可以看出,传统ILC的学习对象是系统的输入信号。为了解决系统控制过程中不受控的问题,结合传统比例、积分、微分(PID)控制方法,提出一种新的控制信号即引导信号。让系统的跟踪信号不再直接跟踪期望信号,而是跟踪引导信号,迭代学习的对象也不再是输入信号,而是引导信号。由引导信号和系统反馈输出信号形成闭环PID控制,便能解决之前系统的不受控问题。
系统的引导信号ILC方法可以表示为如下形式:
(3)
式中:rk(t)为系统第k次迭代的引导信号;p为系统PID控制中的比例系数;L为N×N阶迭代学习增益矩阵,N为一个周期内的采样次数。
该方法应用于实际系统中,系统的输出与传统ILC的输出对比图如图3所示。从图3中可以看出,采用引导信号ILC方法以后,系统不再出现失控的情况,并且控制效果随着迭代学习过程的进行逐渐得到改善。表明在引导信号ILC方法的作用下,系统不仅具备了学习的智能特性,并且解决了中间过程不受控的问题。
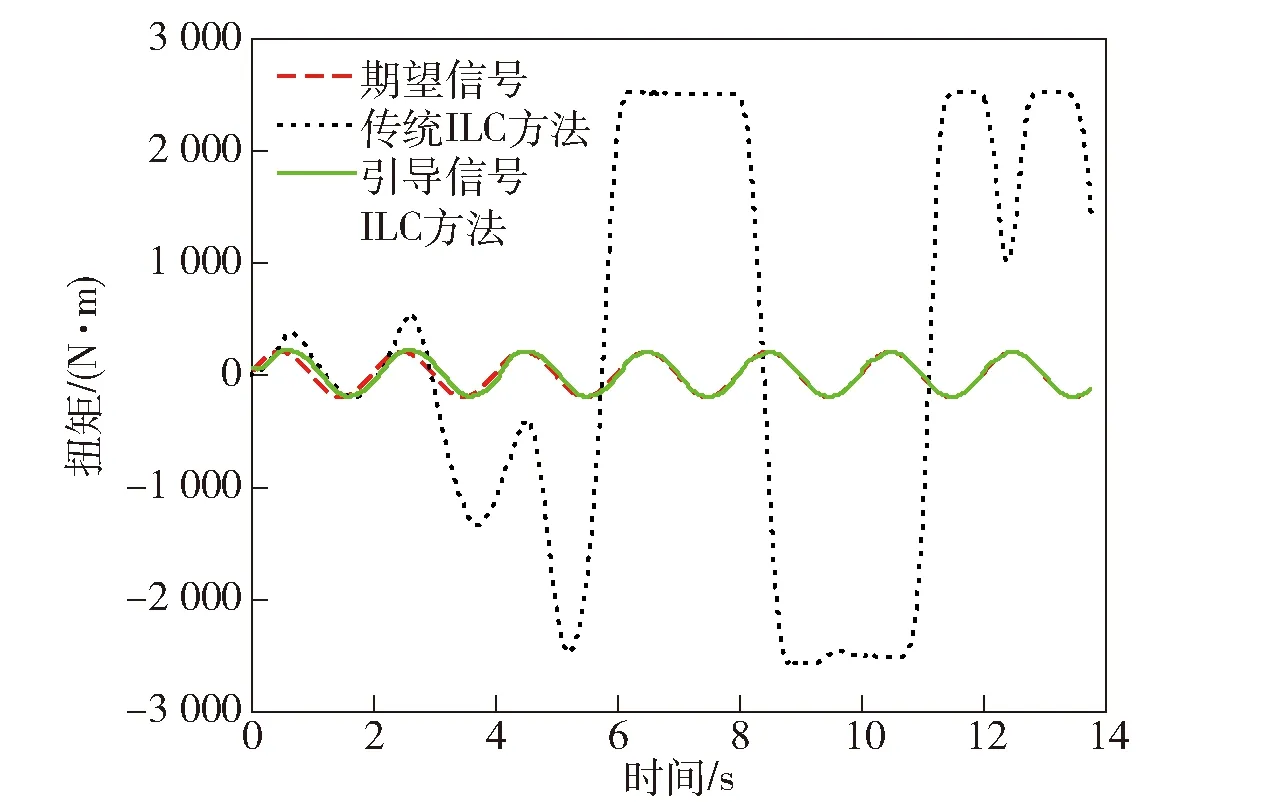
图3 引导信号ILC实际控制效果Fig.3 Actual control effect of guiding signal iterative learning control algorithm
2 引导信号双重学习控制方法的提出
(3)式中控制方法中的学习参数L为一个固定参数,为了提高学习效率,使控制系统具备更快的收敛速度,考虑针对学习参数进行一定的改进,充分利用系统的控制误差,在每个迭代周期根据系统的误差及控制效果,进行参数的自我调整,使系统具备更好的智能性和学习能力。为此针对上述控制方法,做出如下改进:即通过对比同一时刻,最近2个迭代周期的误差大小以及变化趋势对学习参数进行优化和改进。其基本思路是:通过迭代学习,如果当前误差比之前的误差有减小的趋势,则表明当前系数是有效的,并且增大下一次的学习参数,使得学习的速度变快,直至误差满足精度要求,则停止参数学习过程。具体参数学习和改进过程如(4)式:
(4)
式中:pL为学习系数;eh为设置的学习误差门限值,eh>0;当迭代误差ek(t)小于误差门限时,停止学习过程,此时引导信号rk(t)沿用前一次迭代的rk-1(t)信号;Lk(t)为第k次迭代的学习增益矩阵。
在迭代学习过程中,当系统输出逐渐逼近期望信号的过程中,系统误差ek(t)会越来越小,甚至可能是一个接近于0的值,因此为了防止学习参数Lk(t)突然间剧烈变化、导致系统不稳定,在学习过程中设置了误差门限eh,只有当系统误差超出ek(t)>eh时,系统才需要进行迭代学习。
3 收敛性分析及证明
收敛性分析的核心理念主要是依赖于压缩映射原理[13]和不动点原理[14-15]。因为迭代学习具有重复性的特点,所以研究人员总是要求或期望系统每次都从同一初始状态开始进行学习。初始状态对于学习方法收敛性的证明有着重要作用,因此在大部分的收敛性证明中总是假设或设定系统的初始状态都保持不变基[16-20],但是这一假设在实际过程中几乎是不可能实现的。针对这一情况,本文提出的带参数学习引导信号迭代学习方法需要在初始状态不一致的情况下进行数学证明。
针对(4)式中提出的参数学习迭代控制方法,需要进行系统的收敛性分析和证明。根据(1)式,系统第k次迭代时的输出yk(t)可以表示为(5)式:
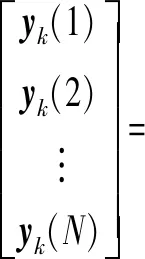
(5)
式中:xk(0)是第k次迭代时的系统初始状态。
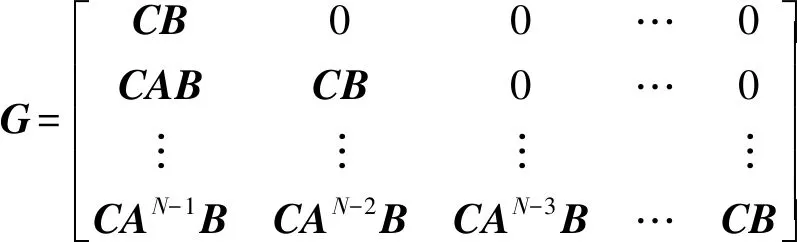
则系统第k次迭代时输出和输入之间的向量表达式(5)式可以改写为(6)式:
yk=Guk+Dxk(0).
(6)
本文研究的空气舵负载模拟器加载系统,在周期信号控制作用下具备一个基本特性:系统控制引导信号为连续的周期性信号时,当系统稳定后的输出也呈现出周期性特性,该特性如图4所示。
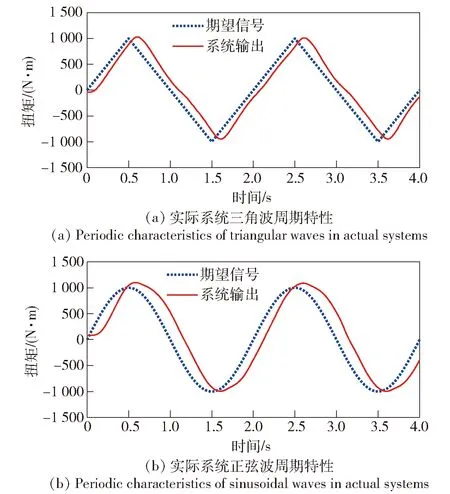
图4 系统周期特性图Fig.4 Periodic characteristics diagram
这一周期特性用数学表达式可以表示为
当rk(t)=rk-1(t)时,有
yk(t)=yk-1(t),
(7)
相应地,可以推导出如下等式:
当rk(t)=rk-1(t)时,有
uk(t)=uk-1(t).
(8)
根据系统时间上的连续性xk+1(0)=xk(N)和重复性xk+1(0)=xk(0),有
xk+1(0)=xk(0)=xk(N).
(9)
根据(1)式将xk(N)展开,可以得到如下等式:
xk(0)=ANxk(0)+Quk-1,
(10)
式中:向量Q=[AN-1B,AN-2B,AN-3B,…,AB,B],为1个参数矩阵。
(10)式就是连续性、周期性信号作用下系统状态变量所具备的特性。在此特性基础上,可以进一步分析系统在新提出迭代学习律下的收敛性。
系统第k+1次的误差ek+1可以写为如下表达式:
ek+1=yd-yk+1=yd-Guk+1-Dxk+1(0)=
rd-pG(rk+1-yk+1)-Dxk+1(0)=
yd-pG(rk+Lkek-yk+1)-Dxk+1(0)=
yd-pG(rk-yk+Lkek-yk+1+yk)-Dxk+1(0)=
yd-pG(rk-yk)-Dxk(0)-pG(Lkek+yk-yk+1)-
Dxk+1(0)+Dxk(0)=
yd-pGuk-Dxk(0)-pG(Lkek+yk-yk+1)-
Dxk+1(0)+Dxk(0)=
ek-pG(Lkek+(yd-yk+1)-(yd-yk))-
Dxk+1(0)+Dxk(0)=
ek-pG(Lkek+ek+1-ek)-D(xk+1(0)-xk(0)),
(11)
式中:ek=[ek(1),ek(2),…,ek(N)]T为系统第k次迭代时的误差向量;Lk=[Lk(1),Lk(2),…,Lk(N)]T为系统第k次迭代时的学习增益矩阵;yd为期望信号。
由(11)式可以推导出
ek+1=ek-pG(Lkek+ek+1-ek)-
D(xk+1(0)-xk(0)).
(12)
根据(1)式,将xk(t+1)=Axk(t)+Buk(t)展开,可得
xk+1(0)=xk(N)=ANxk(0)+Quk,
(13)
根据uk(t)=p(rk(t)-yk(t)),可以推导出uk和uk-1之间的关系如下:
uk=uk-1+pLkek-1+pek-pek-1.
(14)
(13)式代入(12)式中,可得
xk+1(0)=ANxk(0)+Quk-1+pQek+
pQ(L-I)ek-1.
(15)
再根据(10)式,(14)式可以进一步化简为
xk+1(0)=xk(0)+pQek+pQ(L-I)ek-1.
(16)
根据(15)式可以将(11)式进一步写为如下等式:
(I+pG)ek+1=ek+[-pG(Lk-I)-pDQ]ek-
pDQ(Lk-I)ek-1,
(17)
矩阵I+pG可逆,(17)式两端同时左乘逆矩阵(I+pG)-1可得如下表达式:
ek+1=(I+pG)-1[I-pG(Lk-I)-pDQ]ek-
p(I+pG)-1DQ(Lk-I)ek-1.
(18)
(4)式中
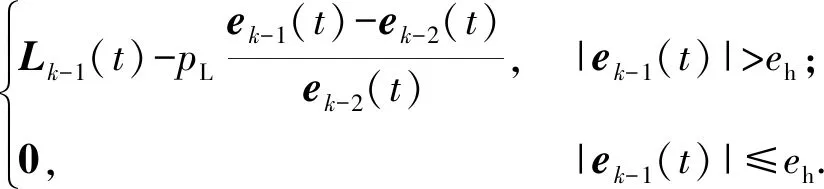
由此可得
(19)
|ek-1(t)|>eh,因此由(19)式可以推导出如下不等式:
即
(20)
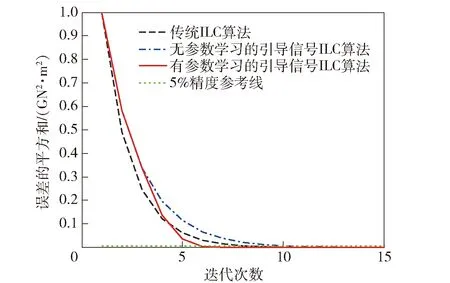
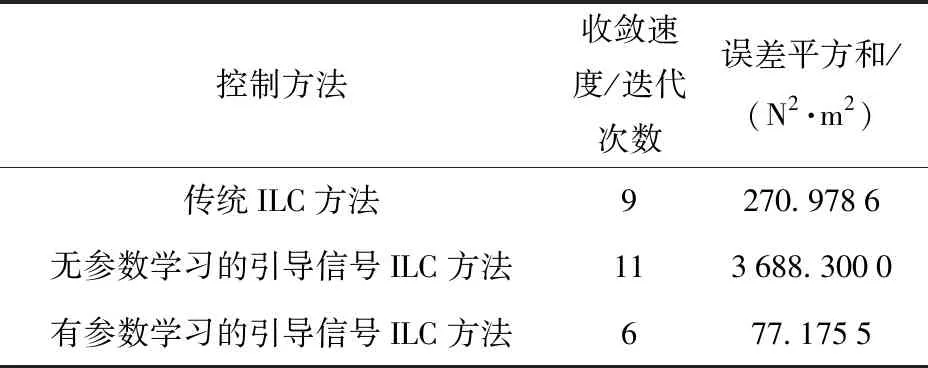
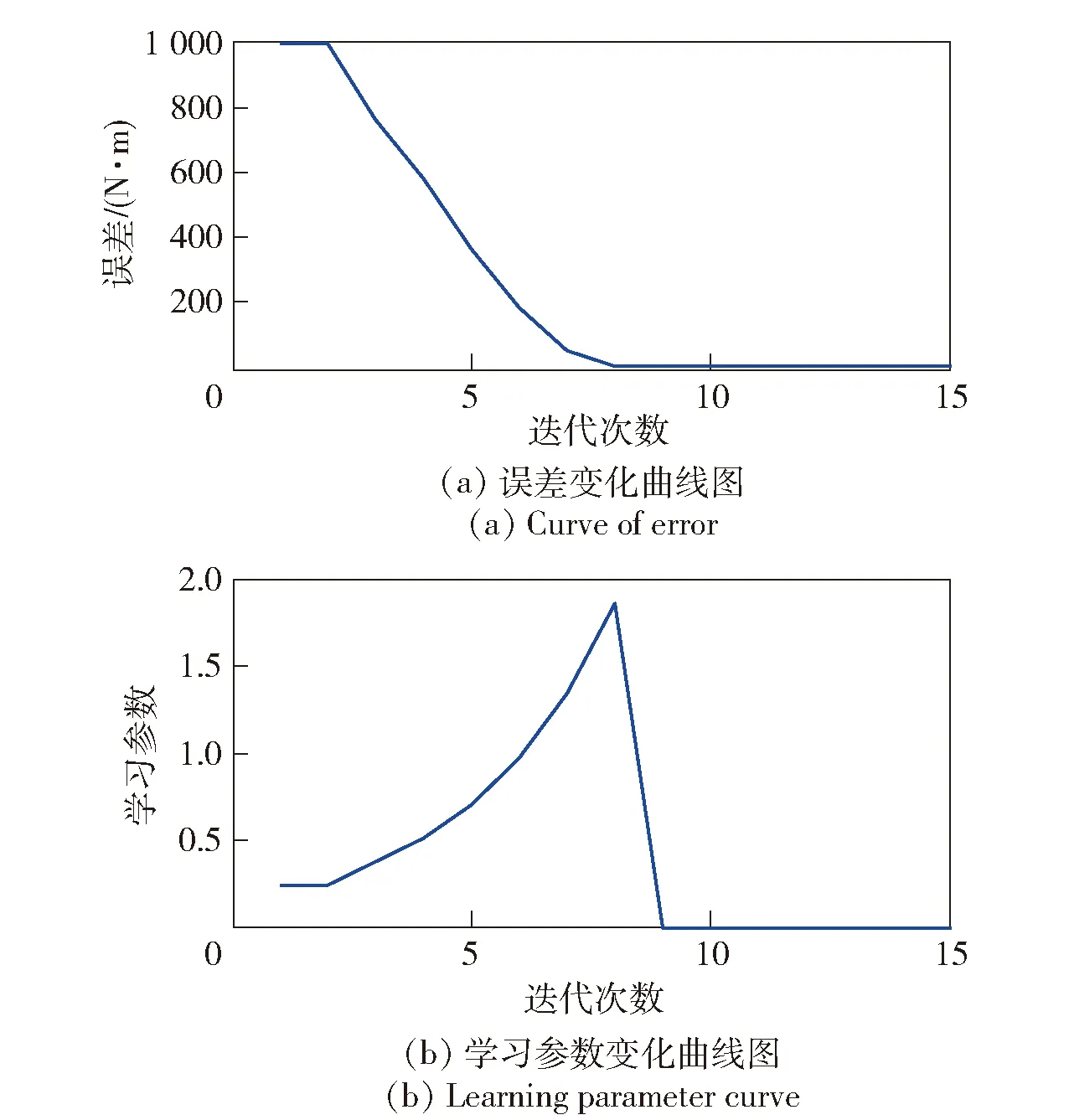
在实际系统中,系统误差总是存在边界的,即ek+1 (21) (21)式代入(18)式中,可得(22)式 (22) 对不等式(21)式两边同时取范数,并根据范数的相容性可得(23)式: (23) 为了进一步证明系统的收敛性,特引入引理1. 根据引理1,如果(23)式中满足如下条件(24)式: (24) 至此,系统在迭代学习方法即(4)式作用下,系统的收敛性证明完毕。(24)式即系统在参数学习方法下收敛的充分条件。可以选取合适的参数L1、p、pL使得不等式(24)式成立,从而保证系统的收敛性。 为了对本文提出方法进行验证,设计并进行了仿真对比实验。在仿真对比实验中,应用了传统迭代学习方法、不带参数学习的引导信号ILC方法和带参数学习的引导ILC方法。引导信号在第1个迭代周期的取值为期待信号,即r1(t)=yd(t),取pL=-0.6,p=0.003. 将选定的3种方法分别用于仿真系统,针对输入为0.5 Hz、幅值为1 000 N·m的正弦信号,系统误差收敛情况对比如图5所示。 图5 收敛速度对比图Fig.5 Comparison of convergence speeds 从图5中可以看出,在3种控制方法作用下系统都能收敛,并使系统的控制误差落入5%的误差区间之内。但是从收敛速度来看,本文提出的方法具有最快的收敛速度,在第6次迭代时就使系统的控制误差到达设定要求。而传统ILC方法和无参数学习的引导信号ILC方法分别需要9次迭代和11次迭代。其对比结果如表1所示。 表1 收敛速度对比对表 从表1可以看出,带有参数学习的引导信号ILC具有更快的收敛速度和更好的控制效果。 针对参数学习过程中的某一时刻,以t=500 ms时刻为例,其前15次迭代过程中该时刻点的学习参数Lk(500)的变化曲线如图6所示。 图6 学习参数变化曲线图Fig.6 Changing curve of learning parameter 从图6中可以看出,在迭代过程中,该时刻点的误差呈现减小的趋势,表明该点当前的参数调整是有效的,因此学习参数一直呈现增长趋势,期望该点的控制误差能够尽快减小到门限值。当该点误差在第6次迭代达到设定的门限值以后,该点停止迭代学习,学习参数变为0并维持不变。 1)针对传统迭代学习在实际控制系统中出现的系统发散问题,本文提出了带参数学习的引导信号ILC方法。该方法充分结合了PID控制和迭代控制的优点,使系统在完全受控的情况进行迭代学习,并让系统具备了一定的智能型。为了增强系统的智能型,提出的改进方法使得系统的学习参数本身也具备学习能力。 2)在收敛性分析和证明中,针对实际情况中每个迭代周期初始状态不一致的情况,本文证明了带参数学习的引导信号ILC方法的收敛性并给出了收敛的充分条件,说明了该方法的实用性。 3)将改进后的的控制方法同传统ILC方法和不带参数学习的引导信号ILC方法进行对比,从实验对比结果可以看出,改进后的控制方法具备更快的收敛速度和更好的控制效果,充分说明了本文方法的有效性和优越性。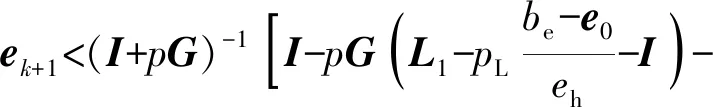
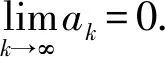
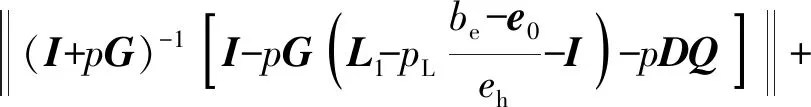
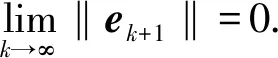
4 对比实验及验证
4 结论
