基于近红外光谱及邻域粗糙集算法的稻谷贮藏品质无损鉴别
2019-12-19苑江浩赵会义
杨 东 常 青 苑江浩 - 曹 阳 赵会义 -
(国家粮食和物资储备局科学研究院,北京 100037)
稻谷是中国三大储备原粮之一,其贮藏品质及食用品质备受国民关注[1-2]。稻谷在贮藏过程中易受仓内温湿度失衡、粮虫侵蚀、霉菌侵染等影响使其品质发生劣变,导致储存稻谷出库时数量及质量损失严重[3-4]。因此,了解稻谷在贮藏过程中的品质变化趋势,明确稻谷在贮藏过程中的宜存状况,建立适宜的检测方法实现稻谷贮藏品质的有效鉴别,是当前粮食贮藏领域急需攻克的技术难题[5]。
脂肪酸值是衡量稻谷贮藏品质变化趋势的重要指标之一[6],又可通过其实测值区间范围确定当前稻谷样品的宜存状况。然而,稻谷中脂肪酸含量的常规检测方法通常以理化试验为主,存在检测周期长、仪器成本较高且损伤样品等问题,不适合现场快速、无损、批量检测的需求[7]。
近红外光谱技术因其快速、无损、操作简单、样品无需预处理等特性,已被广泛应用于水果、蔬菜、肉类等农产品品质检测方面[8-9],也有其应用于稻米品质检测的报道[10]。而且国家已出台了有关稻谷水分、粗蛋白质等指标近红外分析模型的建立标准[11]。蒋晓杰等[12-13]以主成分分析及偏最小二乘回归为核心算法,开展了稻谷中脂肪酸值近红外光谱建模研究工作,并取得一定成效。文韬等[14]研究了稻谷的霉变状况与脂肪酸值的变化规律,建立了二者的关系模型。
特征波段优选是光谱分析建模的重要环节之一,采用适宜的算法优选出能够表征样品本质特性的波长变量,可以提升建模效率和预测精度。邻域粗糙集(neighborhood rough set,NRS)是针对目标不确定性进行数据约减或分类的算法,已在光谱波段选择中得到了应用,Liu等[15]在基于高光谱技术检测大豆品种研究中利用了粗糙集算法进行波段选择,从而实现大豆品种的有效分类;朱启兵等[16]将邻域粗糙集算法与高光谱散射图像相结合,成功地应用于苹果粉质化程度检测。但多数研究所建模型的复杂度可进一步简化,准确性与稳定性还有待提升。此外,将稻谷的贮藏品质作为分类标准,建立近红外光谱鉴别稻谷宜存状态的定性分析模型的研究还未见报道。
试验拟以贮藏稻谷为分析对象,以脂肪酸值为指标将稻谷样品存储状态划分为三类,引入邻域粗糙集算法进行光谱特征优选,与随机森林算法结合建立稻谷宜存状态的鉴别模型,并对模型进行验证和比较,为稻谷品质安全现场快检技术发展提供方法借鉴。
1 材料与方法
1.1 样本制备
稻谷样品主要来源于黑龙江、吉林、江苏、安徽等中国主要粳稻主产区某些地方粮食储备库,选取当地具有代表性,种植品种较多的库存稻谷样品进行扦样,所有样品入库水分含量均在13.4%~14.3%,满足国家收购标准,300余份样品收集后标记密封保存,运到实验室进行后期参数测定。经整理后有效样品285份,首先进行光谱数据采集,随后利用GB/T 15684—2015《谷物碾磨制品 脂肪酸值的测定》方法测定出样品中的脂肪酸值含量。随机选择190份样品作为校正集用于模型的构建,剩余样品作为测试集用于模型的验证。
1.2 仪器设备
近红外光谱分析仪:Sup NIR-3000型,聚光科技(杭州)有限公司;
全温振荡器:HZQ-Q型,广州永程科学设备有限公司;
电子天平:ML 204型,梅特勒—托利多仪器有限公司;
组织捣碎机:8010 BU型,青岛圣吉仪器系统有限公司;
碾米机:JNM-II型,吉林省鼎立机械设备有限公司;
试验砻谷机:THU35B型,北京东孚久恒仪器技术有限公司。
1.3 近红外光谱采集
采集光谱范围1 000~1 800 nm,波长准确性±0.2 nm,波长重复性<0.05 nm,分辨率(10.9±0.3) nm,每间隔1 nm取一次光谱数据,每个样品重复3次装样,扫描32次取平均得到最终样本光谱数据。
1.4 脂肪酸值测定
按GB/T 15684—2015《谷物碾磨制品 脂肪酸值的测定》执行,每个样本作3次平行试验,取平均值作为最终结果。根据GB/T 20569—2006《稻谷储存品质判定规则》中相关规定,粳稻谷脂肪酸值(KOH/干基)可将稻谷宜存状况划分为宜存(≤ 25 mg/100 g)、轻度不宜存(≤ 35 mg/100 g)、重度不宜存(>35 mg/100 g)三类。试验将这三类状态作为模型的输出结果,开展稻谷贮藏品质鉴定方法的研究。
1.5 数据分析方法
1.5.1 随机森林 随机森林(RF)是一种非参数、非线性的分类和回归算法,利用其集成学习方法的优势,可以快速处理高维数据,能够有效地防止过拟合现象[17-18]。试验中决策树数量的范围设置为1~1 000,决策树具体数量与对应分裂变量个数利用10折交互验证方法优选。
1.5.2 邻域粗糙集概念 经典粗糙集(Rough Set,RS)理论将知识理解为对数据的划分,将分类理解为在特定空间上的等价关系,可对不确定或不精确的知识利用特征属性进行描述或约减[19]。但利用RS理论进行连续数据处理时需首先对其进行离散化,会导致原始数据特征属性出现损失,因此引入邻域的概念到RS理论中,形成邻域粗糙集模型用于解决集合中数值型特征变量离散化的过程[16,20],具体描述如下:
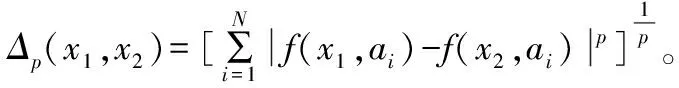
(1)
(2)
(3)
(4)
式中:
Q——邻域属性,归属于整体邻域系统;
D——整体邻域系统的决策属性;
NQD——决策属性D关于Q邻域的下近似或上近似;
Xi——等价类,集合U被决策属性D划分为N个等价类;
xi——样本集数据;
δQ(xi)——由属性Q和度量Δ(xi)生成的邻域信息粒子。
可变精度(β)是邻域粗糙集模型中重要参数之一,通常0.5<β≤1.0。β与邻域范围(δ)的参数设定直接影响到邻域粗糙集模型的性能及对数据的分析结果,因此β与δ参数匹配与选择是模型建立的重要环节[21]。
1.6 模型评价
模型的评价标准主要是通过正确判别率(correct classification rate,CCR)检验,即正确判别的样本个数(Nc)占总样本个数(Nt)的百分比。此外,敏感性和特异性也用于分类模型的评判[22],通常敏感性和特异性的值越接近于1表明模型的性能越好。公式为:
(5)
(6)
式中:
Se——敏感性值;
Sp——特异性值;
TP——真正类,即真样本被判别为真样本的数量;
FN——假正类,即真样本被判别为伪样本的数量;
TN——真负类,即伪样本被判别为伪样本的数量;
FP——假负类,即伪样本被判别为真样本的数量;
2 结果与讨论
2.1 脂肪酸值实测数据分析
表1为稻谷样本脂肪酸值实测数据基础参数统计结果。其中校正集样本(n=190)均值和方差分别为24.15,10.67 mg/100 g,测试集样本(n=95)分别为22.47,9.27 mg/100 g,两个数据集具有可比较的参数统计量,此外,测试集样本脂肪酸含量数据范围(12.98~60.21)恰好被校正集样本数据范围(12.11~67.90)所覆盖,符合基本建模需求,进一步表明样本数据集的划分具有一定的合理性。图1为校正集样本脂肪酸值实测数据散点图。由图1可知,稻谷样本多处于宜存或轻度不宜存状态,只有少量样本脂肪酸值>35 mg/100 g,处于重度不宜存状态。三类状态样本点数据离散的分布在各自阈值区间内,可作为分类模型的参考依据,但在阈值(25,35 mg/100 g)边缘处存在易混状态样本,可能会影响模型的性能。
2.2 光谱特性分析
图2为采集到稻谷样品经过平滑处理后的光谱数据分布图。由图2可知,在测试范围内(1 000~1 800 nm),所有稻谷样品光谱曲线分布趋势基本一致,不同脂肪酸含量样本在吸光度方向上呈现梯度式变化趋势。脂肪酸含量的变化致使其光谱吸收特性存在差异,可能与稻谷在贮藏过程品质变化趋势相关。测试范围内含有多个不同的吸收波段(1 116,1 204,1 450 nm),可能与稻谷样品中包含OH、CH、NH等含氢基团的内部组分及其含量的不同相关[23]。这些特征差异可作为定性分析模型的建立基础。

表1 校正集与测试集稻谷样品脂肪酸值统计结果
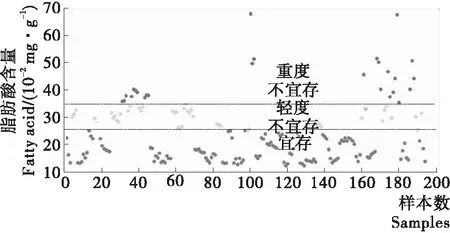
图1 校正集稻谷样品脂肪酸含量散点分布图
Figure 1 Scatter distribution of fatty acid values of paddy samples in calibration set
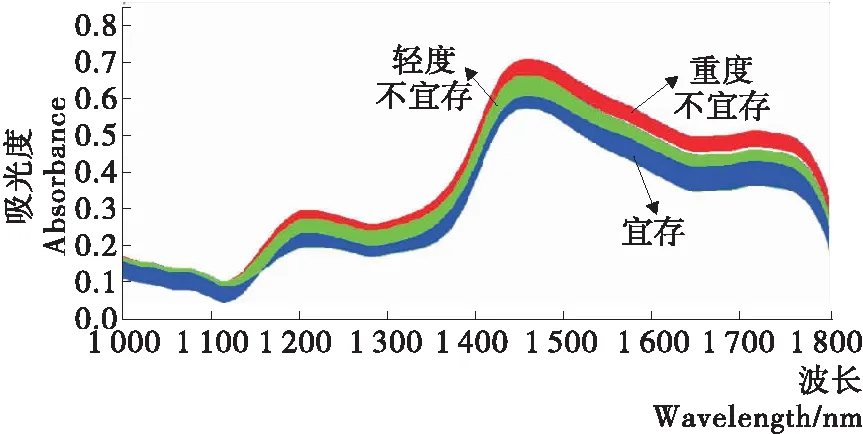
图2 不同宜存状态稻谷样品的光谱趋势图
2.3 特征波长优选
利用NRS算法约减光谱变量,参阅文献[21]可知,通常邻域尺寸取值以0.05为步长,范围标准化到[0,1]区间,β取值以0.05为步长在[0.5,1]区间变化。结合文献[16]的参数取值结果,试验中β设定为0.75和0.85,δ设定为0.05,0.10,0.15,0.20,β与δ分别进行组合完成邻域粗糙集优选算法参数的设置(分别设定为组合1和组合2),经过多次校正实现特征波长的优选,结果如表2所示。
组合1针对不同邻域尺寸分别优选出16,13,12,10个波长变量,分布状况如图3(a)所示,优选出的特征波段基本都分布在主要吸收峰附近。进一步分析可知,不同邻域尺寸优选出的特征波长存在一定的共性,图3(a)中标识出的波长变量均被共同优选出,因此针对组合1的优选结果进一步凝练出10个具有共性的特征波长变量(1 057,1 116,1 204,1 282,1 298,1 354,1 450,1 592,1 651,1 762 nm)用于分类模型的建立。
组合2针对不同邻域尺寸分别优选出12,10,8,6个波长变量,分布状况如图3(b)所示,组合2共同优选出的特征波长数量减少,与组合1优选结果的吸收波段位置存在差异,但同样分布在主要吸收峰附件。针对组合2的优选结果凝练出8个特征波长变量(1 086,1 148,1 234,1 276,1 400,1 576,1 682,1 754 nm)用于分类模型的建立。优选出的特征波长变量能否表征稻谷的宜存状态还需进一步通过建立的分类模型来验证。
2.4 分类模型建立
基于NRS算法,利用组合1和组合2各自优选出的特征波长变量与RF相结合,分别建立NRS-RF-1和NRS-RF-2分类模型用于稻谷贮藏品质的鉴定,分类结果如表3所示。模型NRS-RF-1和NRS-RF-2在校正集的分类准确率相互接近(CCR均>94%),均达到较理想分类结果,其中,对重度不宜存状态的稻谷样品的判别均只误判了1个。进一步分析可知,由于轻度不宜存属于过度存储状态,致使处在宜存和重度不宜存状态的稻谷样品易被误分为该状态(脂肪酸含量处于阈值边缘的样本)。针对测试集样本,两个模型的分类能力均呈现出下降趋势,NRS-RF-1的CCR为93.68%,错误判别了6个样本数据,而NRS-RF-2模型的分类能力下降明显,CCR为86.31%,13个样本被错误划分为其他类。综合考虑可知,NRS-RF-1模型的分类能力与稳定性要优于NRS-RF-2模型,组合1优选出的10个特征波长变量更能表征稻谷贮藏品质的本质特性。
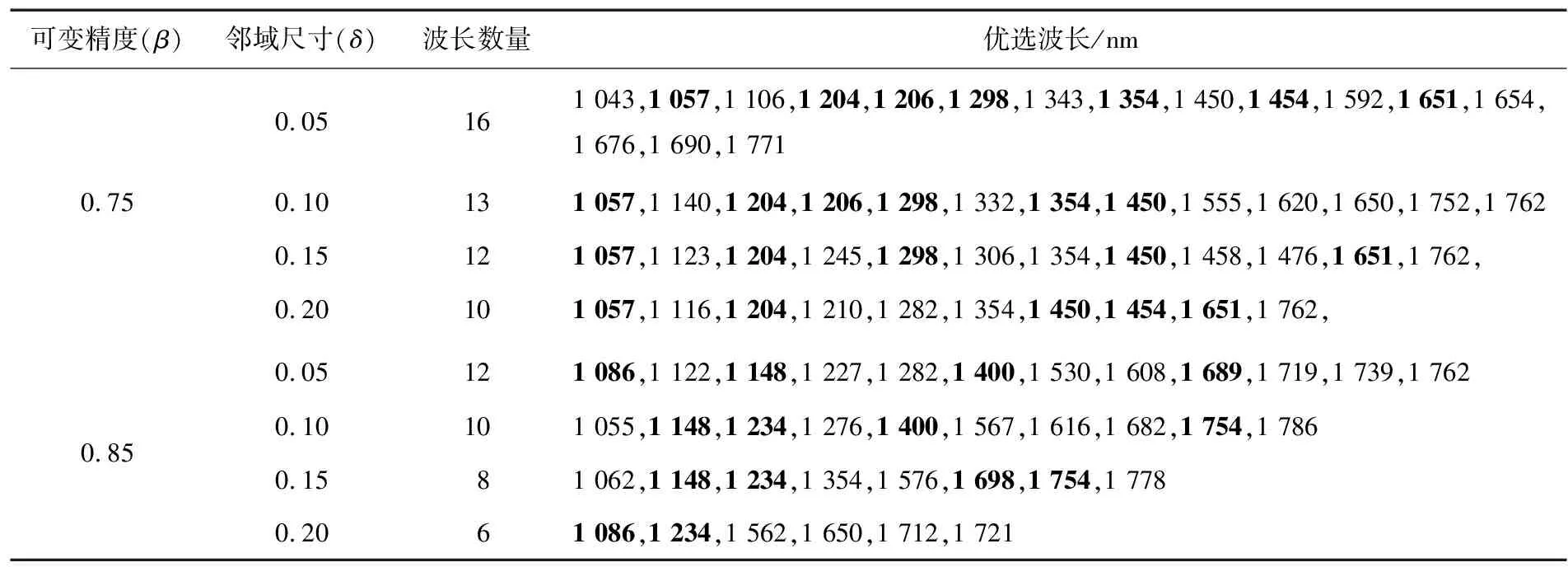
表2 邻域粗糙集算法优选特征波长统计结果†
† 加粗数据表示不同β和δ组合共同优选出的特征波长。
2.5 与其他模型比较分析
为了验证NRS-RF-1模型的分类能力,进一步采用常规的主成分分析(PCA)和连续投影算法(SPA)分别对原始光谱数据进行降维处理,沿用RF算法分别建立PCA-RF和SPA-RF分类模型用于稻谷贮藏品质的鉴别,结果如表4所示。PCA-RF模型校正集与测试集分类准确率均<90%,分别为88.94%,86.31%,其中校正集与测试集分别有21,13个稻谷样本的宜存状态被误判到其他类属。模型分类能力明显不及NRS-RF-1模型。SPA-RF模型的分类能力略优于PCA-RF模型,校正集CCR达到94.73%,仅10个样本状态判别错误,测试集CCR下降到89.47%,表明SPA-RF模型的分类稳定性还需进一步提升。
选取NRS-RF-1和SPA-RF模型通过敏感性和特异性指标的计算结果进一步比较模型性能。由表5可知,NRS-RF-1和SPA-RF模型校正集敏感性和特异性指标分布在0.96~0.99和0.92~0.99,没有明显差异,分类结果较为理想。测试集中,NRS-RF-1模型评价指标分布在0.93~0.98,具有较理想的模型稳定性,而SPA-RF模型的分类准确性和稳定性均出现下降趋势(0.88~0.98)。由此可知,SPA-RF模型针对稻谷样品贮藏品质的整体分类性能同样不及NRS-RF-1模型的鉴别结果,利用NRS算法优选的10个光谱特征波长结合RF算法建立的NRS-RF-1模型用于稻谷样本贮藏品质的鉴定是可行的。
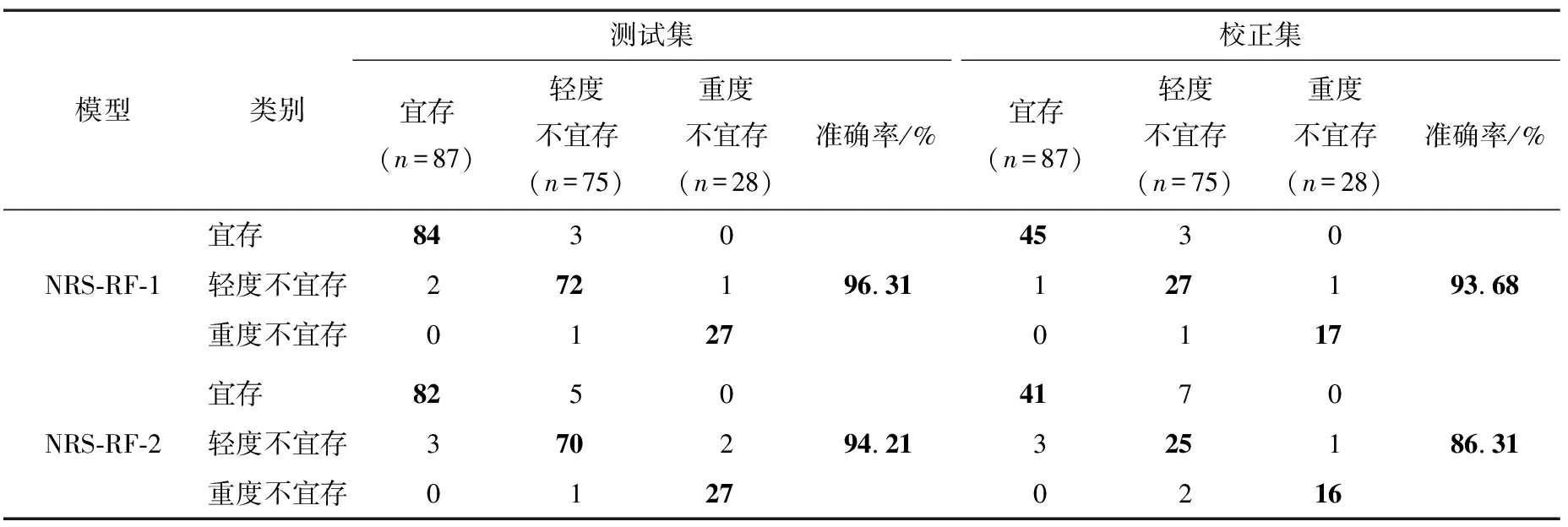
表3 基于NRS-RF模型的稻谷宜存状态分类结果†
† 加粗数据表示分类正确的样本数量及分类准确率。
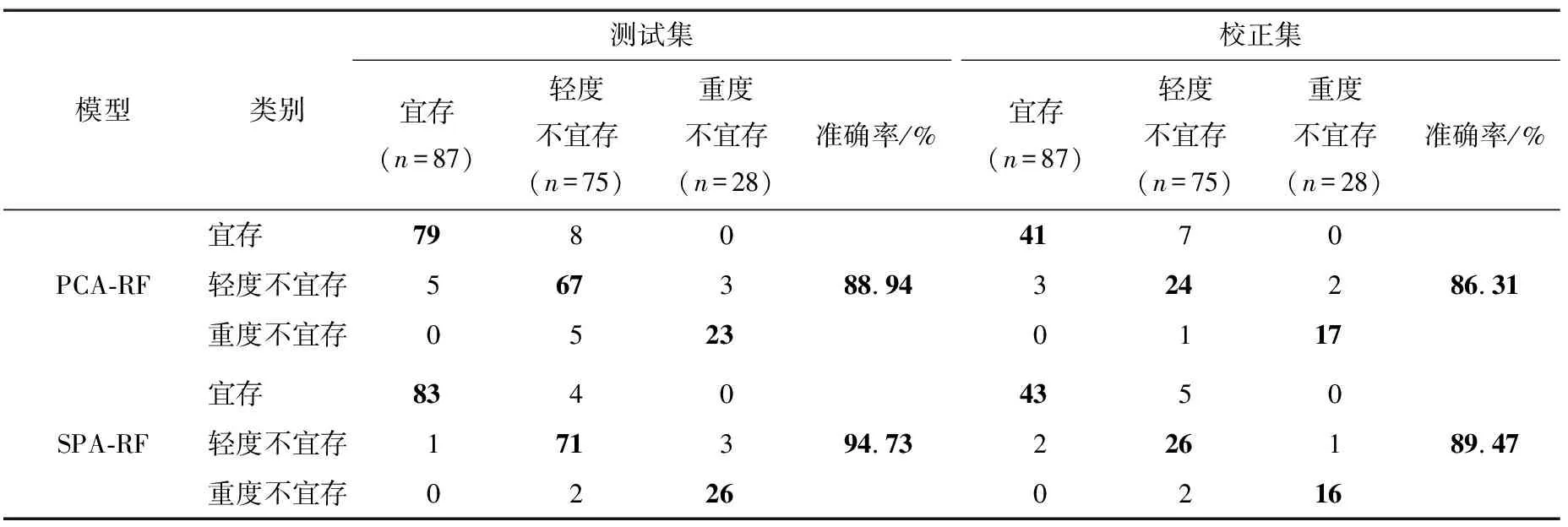
表4 基于PCA-RF和SPA-RF模型的稻谷贮藏品质分类结果†
† 加粗数据表示分类正确的样本数量及分类准确率。
表5基于NRS-RF-1和SPA-RF模型的敏感性和特异性指标统计结果†
Table 5 The results of sensitivity and specificity based on NRS-RF-1 and SPA-RF models
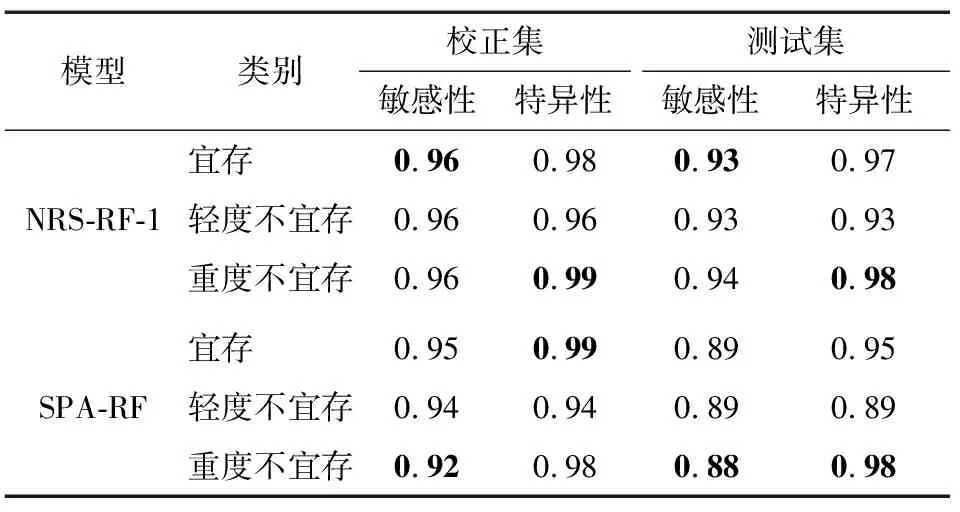
模型类别校正集敏感性特异性测试集敏感性特异性NRS-RF-1宜存 0.960.980.930.97轻度不宜存0.960.960.930.93重度不宜存0.960.990.940.98SPA-RF宜存 0.950.990.890.95轻度不宜存0.940.940.890.89重度不宜存0.920.980.880.98
† 加粗数据表示敏感性和特异性指标的分布范围。
3 结论
采集1 000~1 800 nm的稻谷样品近红外光谱数据,利用参数调整后的邻域粗糙集(NRS)算法优选出10个能表征稻谷样品脂肪酸值变化趋势及其宜存状态的特征波长变量,并结合随机森林(RF)算法构建了分类模型NRS-RF-1,用于稻谷贮藏品质的鉴定。该模型校正集与测试集CCR均>93%,敏感性和特异性分布在0.93~0.99,具有可观的分类准确性与稳定性。经分析比较,NRS-RF-1模型性能同样优于试验中所建立的SPA-RF和PCA-RF两类模型。结果表明,NRS算法优选出的特征变量能够代表稻谷样品的本质特性,构建的NRS-RF-1模型用于稻谷贮藏品质的鉴定是可行的,后期可进一步融合色泽、品尝评分值、水分等多贮藏品质指标细化稻谷宜存状态等级,改进现有模型算法,建立更加适宜的分类模型,为储粮品质安全现场快检设备研制及多光谱在线检测系统研发提供技术支持。
