进化的加权随机SVM集群算法研究
2019-12-13王志刚胥茜毕夏安
王志刚,胥茜,毕夏安
(湖南师范大学信息科学与工程学院,长沙 410081)
0 引言
随着大量的先进神经影像学工具应用于脑部疾病的临床诊断和研究,该领域取得了许多令人瞩目的成果。功能磁共振成像具有无创伤、无需注射放射性示踪物以及良好的时空分辨率等特点,在脑神经功能和疾病研究领域得到了广泛应用。虽然fMRI数据蕴含大量的脑神经组织与功能方面的重要信息,但是由于脑功能活动的复杂特性,以及部分测量误差的影响,导致数据的处理仍然存在许多不确定因素。因此,对fMRI数据实现有效的处理和分析,尤其是fMRI数据的分类,始终是研究热点。随着人工智能及相关学科的发展,大量的模式识别技术和机器学习算法被引入到脑科学领域中,并应用到fMRI数据的分类研究中。
文献[1]将稀疏学习与SVM分类器相结合研究MCI(Mild Cognitive Impairment,轻度认知障碍)分类,对EMCI和LMCI患者进行分类,准确率为80%左右。文献[2]运用 FIN(Fiber Network Measures,纤维网络度量)和 FLN(Flow Network Measures,流量网络度量)作为特征集,再用SVM分类器对EMCI和LMCI患者进行判别,准确率为63.4%。文献[3]将深度相似网络架构与单个SVM分类器结合,对LMCI和AD患者进行分类,准确率为77.92%。文献[4]选择单个体素的BOLD曲线变化率作为特征,结合SVM分类fMRI数据辅助诊断MCI,准确率为75%。文献[5]运用改进的谱聚类方法获取数据的模式特征,再用SVM分类fMRI数据判别MCI,准确率为82%。文献[6]利用粒子种群算法提取特征参数,组合SVM分类fMRI数据判别精神抑郁症,测试准确率高达84.62%。
虽然在机器学习和人工智能等算法的加持下,脑神经学科领域的研究水平得到了极大的提升,但也存在许多问题:部分算法的通用性不强,分类以及降维效果不佳;一些分类研究注重脑神经病变类型的鉴别,较少深入探索疾病的病理机制,因而限制了研究人员对疾病成因的深度理解。因此,非常有必要探索新的算法,从而实现快速降维、准确捕获异常特征,进而达到快速分类的目标;如能定位引发疾病的病灶,则还可以为有效治疗提供帮助。
本文在研究加权随机SVM集群(WRSVMC)算法的基础上,本着提高降维速度的目的,将进化的思想引入其中,动态地从高维样本中删减无用特征,保留主要异常特征。实验表明算法不仅加速了降维过程,也提高了分类准确率。实验用fMRI数据来源于ADNI。
1 加权随机SVM集群原理
在用静息态fMRI数据研究脑神经类疾病时,两两脑区时间序列之间的皮尔逊相关系数是主要的功能特征数据,近年脑区网络的图论特征也被用作特征数据,但这些数据都具有高维特性。为了有效利用小样本、高维度的fMRI数据,首要任务便是降维。传统的主成分分析(PCA)、线性判别分析(LDA)和等度量映射(Isomap)等降维方法都会损失部分信息,也不便于解释低维度特征。直接从原始特征中提取对分类性能具有强影响力的特征,可以降低图像噪声的不利影响。
1.1 随机SVM集群简介
SVM模型能很好地处理fMRI数据,但在高图像噪声情况下,依然很难获得稳定和鲁棒的泛化能力。文献[7]研究了一种由多个SVM分类器组成的随机SVM集群(RSVMC),通过集成学习使得互有差异的各SVM形成一个强大的分类器簇,从而获得优秀的泛化性能。但是各SVM具有同等的投票权,忽视了它们之间的强弱差异,对整体性能有较大影响。
1.2 加权RSVMC简介
文献[8]在RSVMC的基础上,通过对每个SVM基分类器增加权重,构成加权随机SVM集群(Weighted Random SVM Cluster,WRSVMC),提高了分类的稳定性和准确率;运用该算法对MCI患者的fMRI数据进行的分类结果表明,准确率最高可达87.67%。图1是该模型的示意图,它克服了RSVMC因各SVM之间分类能力差异而性能不稳定的问题,但在高维数据的降维问题上没有很好的作为。
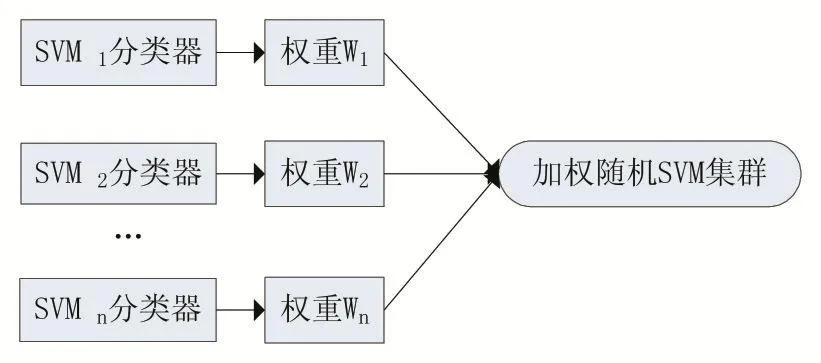
图1 WRSVMC模型
2 进化的加权随机SVM集群设计
2.1 进化的加权随机SVM集群原理
为了进一步优化特征选择,将进化的思想引入WRSVMC,动态地从高维样本特征中逐步删减无用特征,构成EWRSVMC。为了确定所删除的是无用样本特征,设置阈值以控制样本特征的收敛速度。图2是其进化过程,若初始样本特征为d维,经过k轮进化后的样本特征维数是dk(dk≤dk-1)。
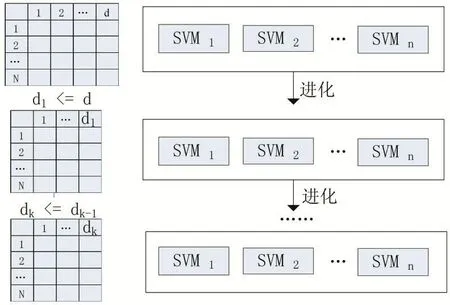
图2 EWRSVMC的进化过程
2.2 EWRSVMC的实现
fMRI脑功能图谱的网络构造、网络边值的处理以及特征的选择与WRSVMC中的方法相同,每一个图谱的4275个特征是分类器的初始输入数据[8]。
将数据集D划分为Dtrain、Dvalidation和Dtest三个集。Dtrain用来训练分类器,Dvalidation用来获取SVM的权重,Dtest用来测试模型的泛化性能。
(1)训练n个基学习器的RSVMC,计算SVMi对验证集数据中的分类正确率Wi,并作为其权重。
(2)挑出Wi<0.5的弱SVMi,找出它们所选中的特征,累加相同特征的权重Awj:
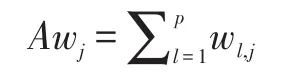
其中p是弱分类器数量,wl,j是第l个弱分类器的第j个特征的权重。
(3)特征的权重越高,对分类的影响越小。阈值r用来鉴别和删减这些特征,若Awj≥r,则第j维特征的权重重置为零,从而得到进化后的特征集。

设第i轮进化所删减的特征数目是Ki,则第n轮进化后保留的特征数目为:

当进化轮数达到预设阈值时算法停止。图3是进化流程。
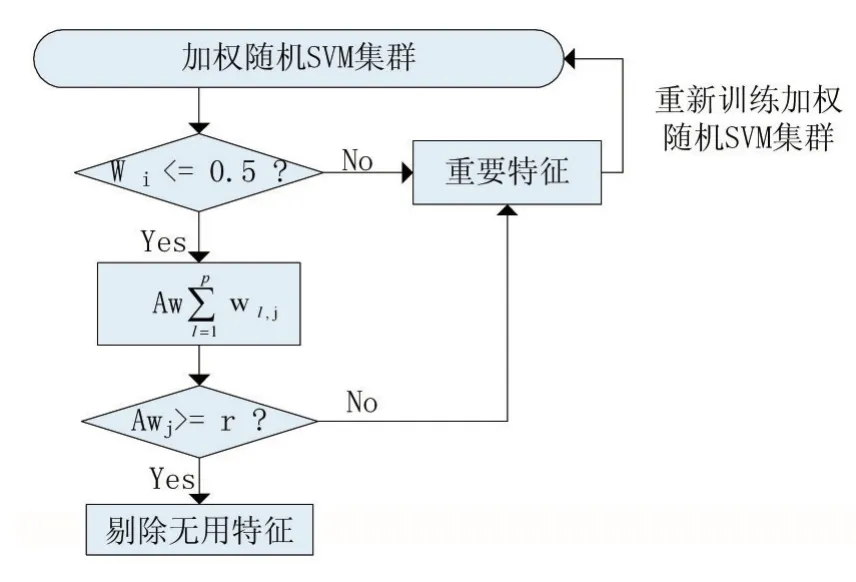
图3 EWRSVMC进化流程
2.3 性能评价指标
预测Dtest集中的每一个样本的类别。将样本x通过各分类器检测,若fi(x) 是样本x经SVMi预测的结果,Ι(∙) 是指示函数,则求得x属于a类别的加权总得票数为Sa。
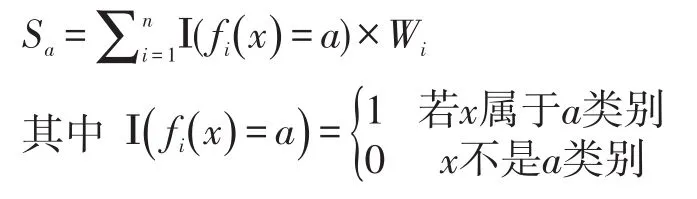
经过加权后选出得票数最多的类别A作为样本的最终预测类别:
A=Arg max(Sa)
通过对比样本的预测类别和它们在原始实验集中的真实类别,可以得到Dtest集样本被正确分类的数量Ttrue,若Crad(Dtest)=T,则分类准确率为:
Pre=Ttrue/T
3EWRSVMC的应用与评估
EWRSVMC可以用来研究脑区疾病和功能变异。首先求出进化后对算法分类性能有重要影响的特征集,这些特征也是和被研究疾病直接相关的异常特征。然后在脑区寻找与异常特征吻合的区域,异常区域越多,则相对应的脑区频数越高,与相应的脑功能异常越相关。将脑区的频数降序排列,就能检测出与疾病相关的脑区。下面通过对fMRI数据的AD分类,评估算法的性能。
共执行了两组实验,每组实验主要被分为4个步骤:
(1)将实验数据集按2:1:1比例划分为训练、验证及测试集。
(3)找出最优特征子集。计算每一轮进化后的准确率,将最高准确率的模型所对应的基分类器数目设定为最优。
(4)检测异常脑区。根据最优特征子集中每条特征含有的两个脑区,统计同一脑区出现的频数,将部分频数最高的脑区作为异常脑区。
图4的结果表明在第34轮进化前准确率基本保持增长趋势,之后达到最高准确率88.89%。与现有的分类算法相比,EWRSVMC的分类性能更优;同时AUC值也达到了0.9091,说明算法在处理分类问题上很稳健。

图4 进化轮次与准确率关系
4 结语
针对fMRI图谱数据的高维特性,在WRSVMC分类模型基础上引入进化机制,能有效地去除特征数据中的冗余部分,保留异常特征,加快了降维过程,分类速度和准确率提高幅度较为明显。另外,该算法还能找到与这些特征相关联的异常脑区,如颞上回、颞中回和脑岛部位的异常,从而可以确定AD疾病与这些脑区的病变过程有着不可分割的关联,为分析与研究AD病理的成因提供了一个新视角,还可以有效地帮助医师对AD患者进行辅助诊断。
