基于游客签到数据的旅游兴趣点挖掘
2019-12-13白刚
白刚
(桂林旅游学院旅游管理学院,桂林 541006)
0 引言
游客签到数据由于手机的GPS定位服务及LBS服务的支持,提交便捷,所以在微信、微博、携程等各种具有社交属性的网络媒体中普遍存在,数据量庞大,为旅游兴趣点的挖掘研究提供了良好的数据基础。如何从海量的签到数据中找出兴趣度最大、热度最高的签到点,是本文研究的主要内容。
1 签到数据格式及数据清洗
1.1 签到数据格式
由于不同数据来源的签到数据格式相对混乱,为避免过多的数据格式转换,本文采用的数据集采集自新浪微博的地点签到数据。
签到数据采集方法为Python网络爬虫采集,采集时间段为2017.3-2017.9,除去无效数据后,签到地理坐标在广西的数据总量为125221条。
数据格式如表1所示。

表1
1.2 数据清洗
爬虫抓取的原始数据存储为csv格式,由“,”进行字段分割,然而由于地点名、地址等字段本身存在逗号,导致导入Excel后有很多数据缺失或存在列混乱的情况,尤其是最为重要的坐标信息,存在很多经度和维度列混乱的情况,需要做基础清洗工作。在Excel中采用VBA进行数据清洗,部分清洗代码如下。
Sub cleandata()
Dim i As Long
For i=1 To ActiveSheet.UsedRange.Rows.Count
If Not IsNumeric(Range("D"&i).Text)Then
Range("C"&i).Value=Range("C"&i).Value&","&Range("D"&i).Text
End If
If Not IsNumeric(Range("E"&i).Text)Then
Range("C"&i).Value=Range("C"&i).Value&","&Range("E"&i).Text
ElseIf Range("E"&i).Text> 100 Then
Range("D"&i).Value=Range("E"&i).Value
Range("E"&i).Value=Range("F"&i).Value
Range("F"&i).Value=Range("G"&i).Value
Range("G"&i).Value=Range("H"&i).Value
Range("H"&i).Value=Range("I"&i).Value
Range("I"&i).Value=Range("J"&i).Value
Range("J"&i).Value=""
End If
清洗完成后的数据格式如表2所示。

表2
2 算法逻辑
签到数据中的一些字段可以直观反映出地点的热门程度,或者理解为地区(聚类)的兴趣度。但是,单独的签到次数并不能完全说明此地点就是热门的旅游兴趣点,例如火车站,作为游客到达城市后的第一站,同时也是城市的门户,很可能是签到次数最多的地点,但是,明显大部分城市的火车站都无法作为热门旅游景点来吸引游客参观。所以,在旅游兴趣点的挖掘中,除了基本的签到次数数据以外,还需要综合考虑其他字段的权重,结合字段数据和地理数据的加权计算结果。
在旅游兴趣点挖掘时,要对不同的签到数据建模,建模参考基于层次图模型的多用户轨迹聚合方法,如上图所示。首先,对签到数据中的旅游点进行提取,并放入相应的集合中,接下来采用某种合理的密度聚类算法,对对应的旅游点进行层次化聚类,结合地理坐标,在可区分的地理空间尺度上,把近似的旅游点分配到同一个聚类中,根据地理空间尺度的大小不同,聚类分配在不同的层级,层级越低,聚类越小,粒度越细,代表的地理空间也就越小。
聚类完成后,我们得到了一棵不同地理空间尺度的层次树模型。接下来,将其他相关指标因素加权映射到这棵树的不同聚类层次上,从而得到不同的模型。

图1 基于层次图模型的多用户轨迹聚合
2.1 兴趣点与签到数据的关系
兴趣点和签到数据的关系可以分解为景区兴趣度和游客互动程度两个子关系。一般说来,签到数量的多寡直接反映了该点的热门程度,同时,如果该点的属性是博物馆、餐饮美食、公园、动物园、景点、星级宾馆等与旅游直接相关的类型,即可认为签到数量的多少直接反映出该旅游点的热门程度。另外,为了验证该旅游点的热门程度与签到数量的相关性,需要引入照片上传数量(游客互动程度)作为验证参考。再有,从地理特征上分析需要考虑热门旅游点是否具有空间聚集性,交通可达性对其热门程度的影响是否可量化。
2.2 各指标相关性分析及算法逻辑
计算指标可以分为两个大类:用户指标和地理指标。
用户指标包括地点名称、地点类型、签到数量、上传照片数量。地理指标包括经纬度信息。
算法逻辑如图2所示,分为综合排序算法与地理空间分析算法两个部分。
其中综合培训算法流程为首先对地点按照签到次数进行综合排名,就可以把具有较高排名的地点(包含但不限于旅游点)作为粗评的兴趣点筛选出来,接下来根据签到点类型筛除所有旅游点,游客互动程度主要反映在游客的照片上传数量等指标上,在排序完成后,对排序列表增加游客照片数量进行加权重新计算并再次排序。
综合排序完成后,将旅游点的地理坐标XY数据形式导入ArcGIS中,叠加到校准后的带有地理投影坐标的卫星地图上,然后对点元素进行密度分析,按照分析结果进行赋值,再综合上面得出的综合排名进行旅游点排名的加权运算,最终得出该景点的兴趣值最终排名。
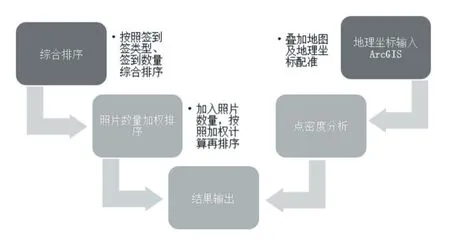
图2 算法逻辑
3 算法设计
3.1 语言及工具选择
本算法总共使用了三种编程语言或工具。
VBA:Visual Basic for Applications是一种 Visual Basic的一种宏语言,主要能用来扩展Windows的应用程序功能,特别是Microsoft Office软件。也可说是一种应用程序视觉化的Basic Script。VBA在本算法中,主要用于对爬虫抓取的数据进行清洗。
Python:Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。Python在本算法中,用于对清洗后的数据进行读取后初步排序,包括单列排序和多列加权排序。主要使用到的包为pandas。
ArcGIS:ArcGIS Desktop是一个集成了众多高级GIS应用的软件套件,它包含了一套带有用户界面组件的Windows桌面应用。ArcGIS具有强大的地理空间分析能力,包含了聚类分析、热点分析、缓冲区分析等各种常用地理空间分析工具,非常适合本算法。
ArcGIS承担的工作为地理坐标匹配到地图,对点元素进行空间分析及最终的加权计算等。
3.2 算法框架
Python排序与ArcGIS空间分析加权算法流程图如图3所示。
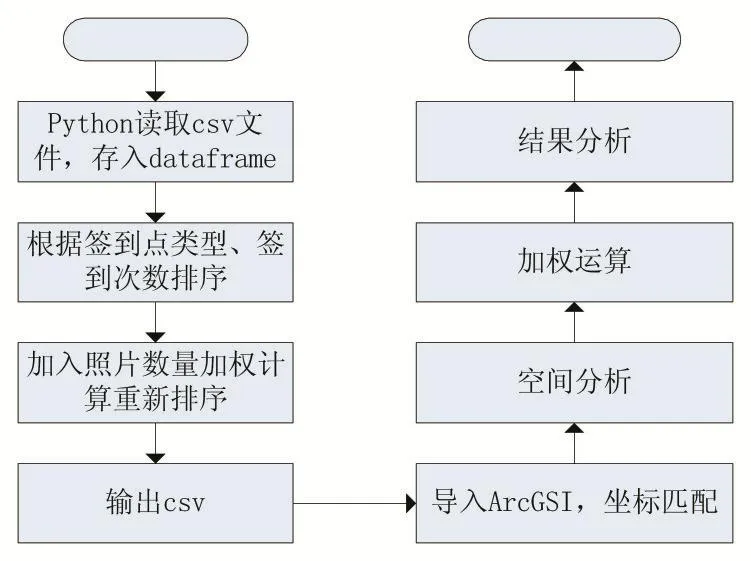
图3 算法流程图
图3左侧部分为Python实现部分。
在对爬虫抓取的数据进行数据清洗后,导出Excel或csv文件,使用Python的第三方库pandas读取Excel或 csv文件内容,生成 pandas的 dataframe,再对dataframe的内容进行筛选(根据点类型进行模糊筛选)和排序(根据签到次数,降序排序),完成后清理签到次数呈现个位数的数据,以减少计算工作量。
对排序完成和清理后的数据进行加权运算再排序,本算法中,对照片数量赋予0.4的权重。计算完成后,对最终培训的点的经纬度坐标、点类型、名称等列输出csv文件。
右侧部分为地理空间分析部分,用ArcGIS实现。
将Python排序后导出的csv文件输入ArcGIS中,底图使用水经注地图下载器选择合适的坐标系和投影后进行下载。导入后ArcGIS会自动按照点的经纬度匹配到底图上。
接下来对点进行包括符号化、密度分析、加权叠加等操作,最终得到分析结果。
3.3 算法实现及地理处理
import pandas as pd
data=pd.read_csv('Guilin.csv')
found=data.loc[data['type'].str.contains('景点|公园|户外|住宿|餐|游乐场|景区|度假区')]
found.sort_values(by=['sin','ph'],ascending=False,inplace=True)
found.to_csv('Guilinsort.csv',index=False,sep=',')
输出csv文件格式如下:
110.4933929,24.77607346,省级景点,9815,6997,阳朔
110.36981000000002,25.29235,省级景点,7541,3316,桂林尧山景区
110.50668999999999,24.76511,省级景点,6225,3207,印象刘三姐
110.5020936,24.77280803,国家级景点,5977,3871,漓江
110.2960834,25.27491496,公园户外,3943,2472,桂林市中心广场
110.29951570000001,25.28214797,国家级景点,3743,1711,靖江王城与独秀峰景区(广西师范大学王城校区)
导入ArcGIS时,选择GCS_WGS_1984坐标系,导入后ArcGIS后,对点进行分级符号设置后如图4所示。
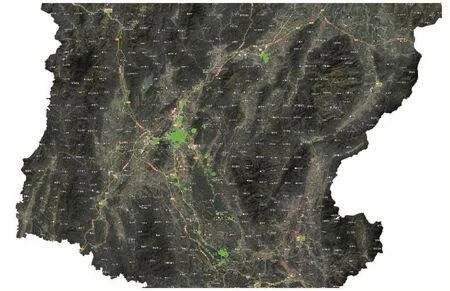
图4
点大小代表了签到数量和照片上传数量加权运算后结果的大小,从图4可以看出,热度最高的点对应了大桂林范围的著名景点,且沿国道分散。
然后对点图层做核密度分析,第一次对population字段采用签到数量,第二次population字段采用上传照片数量,加权叠加后得到如图5所示的结果。
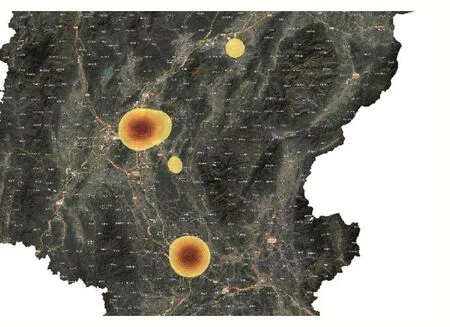
图5
从图5可以明显看出加入签到数量后的点密度分布具有强烈的地理聚集性,可以看出距离城市中心远近对签到点的影响很大。
叠加两个图层,得到如图6-图7的结果。

图6

图7
图7去掉了底图干扰,可以清晰的看出,大部分高兴趣度热点与点密度分布高度集中区匹配。从图6看出有部分热点与点密度集中区偏离较远,与城市间主干道的分布或水道分布有直接相关性,如世外桃源景区在桂林至阳朔的321国道通过范围内,九马画山景区、阳朔漓江景区等都位于漓江水道通路上。
4 结语
签到点的兴趣度排名涉及到多个因素,包括直观的签到数量、照片数量以及地理坐标、地理位置等地理要素。本文从数据清洗开始,经过数据筛选、排序,输入ArcGIS进行地理处理,最终发现旅游点的热度与签到数量、上传照片数量、距离城市中心距离、距离主干道或水路距离都具有很大的相关性。
