基于联合优化多任务学习的细粒度图像识别
2019-12-11朱阳光刘瑞敏
朱阳光,刘瑞敏,王 震,王 枭
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
近几年,由于深度学习的快速发展,计算机视觉领域取得了巨大成功,使得图像识别性能得到了前所未有的改善[1]。然而,相比于以ImageNet为代表的通用图像分类方法来说,识别汽车类型、动物种类或食物等细粒度类别仍然是一项具有挑战性的任务。原因是细粒度类别的外观可能非常相似,如何识别它们在关键部分上的微妙差异至关重要[2]。
在深度神经网络发展之前,研究人员使用一些比较强大的特征,如Kernel descriptors[3]、Poof[4]和SIFT等,然后使用定位精度比较高的算法,在CUB200-2011[5]鸟类数据集上达到了50%~60%的分类精度[6]。随着深度学习的发展,在细粒度图像识别方向也取得了突破性进展。如Zhang等[7]提出了Part R-CNN算法,采用R-CNN对图像进行检测,在CUB200-2011上取得了73.9%的分类精度。Yang等[8]提出一种名为Navigator-Teacher-Scrutinizer的网络结构,在仅使用类别标签的条件下,从原始图像中提取K个信息量最大的区域,与整体图像的特征进行整合,最后进行分类,在Stanford Cars[9]数据集上实现了93.7%的分类精度。可以看出,大多数方法都集中在提高分类精度上。例如学习可以区分不同子类图像间的关键部分[10],或者通过度量学习来减缓子类图像间较大类内差异的问题[11]。然而,这些研究很少致力于去学习一种可以在不同相关水平上发现相似图像的结构化特征表示。图1所示为Stanford Cars细粒度数据集中一些相似车型。具有相同细粒度标签的车型表示它们是完全相同的品牌、型号和年份。但是,尽管有些汽车具有不同的细粒度标签,仍然具有相似的车型。换句话说,不同的细粒度类别可能仍然共享相同的语义信息。因此,可以利用这种共享信息来学习结构化特征。如果能够在这些细粒度特征表示中探索出相似层结构中的这种共享信息,将会有重大意义。例如,可以应用到电子商务中相关产品的推荐,产品在语义和视觉上相似,但不属于同一个细粒度类别。

图1 Stanford Cars数据集中的一些相似车型
1 联合优化的多任务学习
1.1 网络模型的设计
为了获得细粒度特征表示,可以结合相似性约束来完成。例如,Wang等[12]提出了一种深度排名模型,通过采样图像三元组来学习相似性度量。但是,这些方法对细粒度数据集来说存在一些局限性:
(1)尽管使用Triplet Loss学到的特征在发现相似类型时效率很高,但它的分类精度却不如那些注重分类损失的微调模型,此外,使用这种方法收敛速度通常很慢;
(2)没有利用标签结构中的共享信息,这些信息对于定位具有不同级别相关性的图像至关重要。
提出两种方法来解决这个问题:
(1)首先,设计了一种多任务学习框架,能够在有效学习细粒度特征的同时还不会降低分类精度。图2所示为设计的多任务学习框架。具体来说,我们联合优化卷积神经网络中的Softmax Loss和Triplet Loss,它们可以生成分类结果并辨别特征表示。这两个约束的结合不仅能够提高分类精度,还能够在细粒度数据集上发现视觉和语义相似的实例。

图2 多任务学习框架
(2)基于此框架,通过设计三元组嵌入标签结构,例如层次结构(如汽车的车型、年份等)。因此,标签结构中的共享信息可以有效地作为额外的约束和扩充的数据。这种嵌入标签结构的方法能够有效地发现不同级别中具有相似性的相关图像。我们在Stanford Cars公开细粒度数据集上进行了实验,结果表明,这种特征表示可以精确地区分细粒度或子类图像,并且还有效地发现了不同相关级别的相似图像,这两者都是具有挑战性的问题。
1.2 优化方法

(1)
其中P(li|ri)表示ri被分类为第li类的后验概率。
将Triplet Loss与分类目标融合作为相似性约束。一个三元组由3个图像组成,用(ri,pi,ni)表示,ri表示目标图像,pi表示与ri同一类别的图像,ni表示与ri不同类别的图像。给定输入图像ri,Triplet Network可以生成一个特征向量ft(ri)∈RD,其中超参数D是嵌入标签之后的特征维度。理想情况下,对于每个ri,期望它与所有不同类别的图像ni的距离比同一类别的图像pi的距离大出一定余量m:
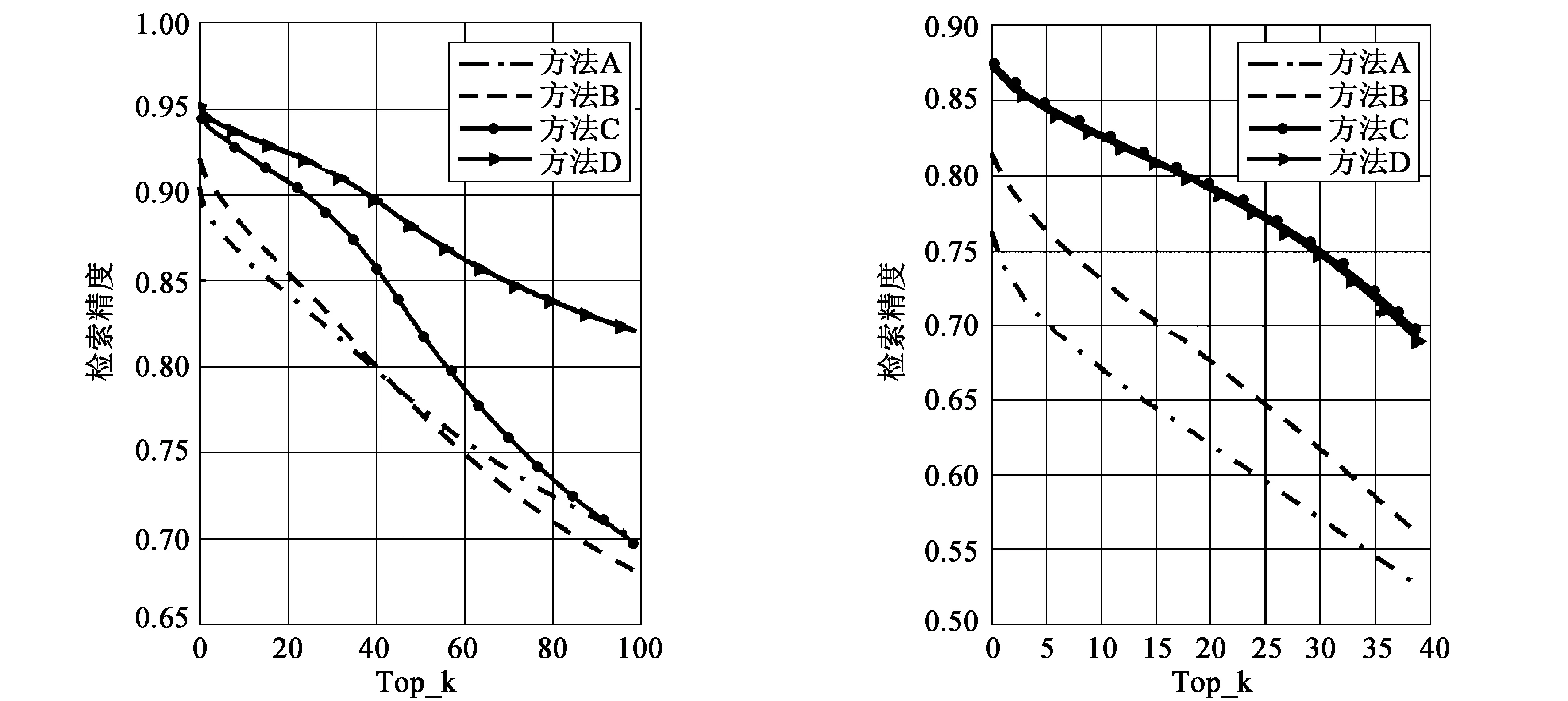
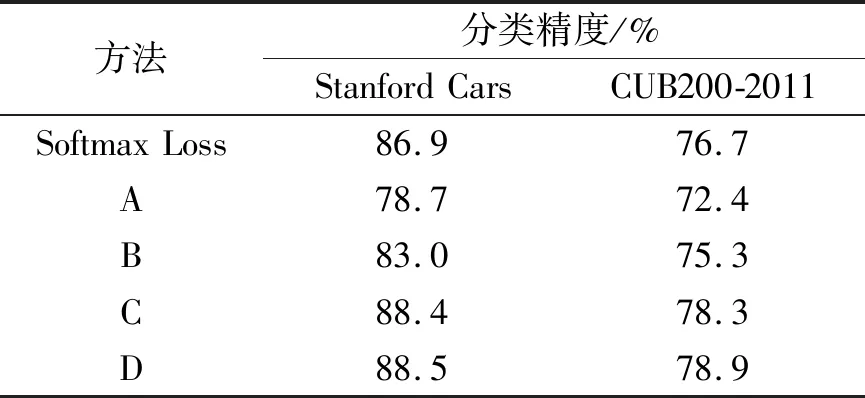
d(ri,pi)+m (2) 其中m>0,d(·,·)是Triplet network的两个标准化向量ft(·)之间欧氏距离的平方。为了在卷积神经网络中实施上述约束,式(2)可定义为以下Hinge Loss: (3) 在ft(·)定义的特征空间中,通过最小化Et(r,p,n,m)可以将r和p组合在一起,同时远离n。梯度计算方法如下: 当d(ri,ni)-d(ri,pi) (4) 与Contrastive Loss不同,Triplet Loss允许一定程度的类内方差。尽管它在学习特征表示方面具有优点,但对于识别任务仍有几个缺点。例如,给定具有N个图像的数据集,所有可能的三元组的数量是N3,并且与在C类中提供特定标签的分类约束相比,每个三元组包含更少的信息,这可能导致收敛缓慢。此外,如果没有明确的分类约束,区分类的准确性可能不如传统的使用Softmax Loss的CNN,特别是在细粒度识别问题中,子类图像间的差异非常微妙。 鉴于仅对Triplet Loss进行训练的局限性,我们提出使用多任务学习方法联合优化两种类型的损失。图2显示了联合学习的CNN架构。在训练过程中,R、P、N三个网络共享相同的参数。在经过L2正则化后,3个网络的输出传送到Triplet Loss层来计算相似性误差。与此同时,网络R的输出传送到Softmax Loss层来计算分类误差。然后,通过加权组合将这两种损失进行整合: E=λsEs(r,l)+(1-λs)Et(r,p,n,m), (5) 其中λs是控制两种类型损失之间权衡的权重。这个由3个网络组成的框架不仅可以学习判别特征,保留类内方差,而且还不会降低分类准确性。此外,它解决了仅使用Triplet Loss时收敛缓慢的问题。 使用随机梯度下降优化式(5),采样方法可以使用FaceNet[13]中的方法或者使用Hard mining从训练集中寻找有挑战性的样本,这两种方法在我们的框架中都是可以使用的,因为联合优化Es(r,l)有助于搜索好的解决方案,为采样提供一定的灵活性。 在测试阶段,该框架将一个图像作为输入,并通过Softmax层生成分类结果,或者在L2正则化之后生成细粒度特征表示。这种判别特征表示可以用于各种任务,例如分类、验证和检索,这比单独优化Softmax更有效。 如前所述,有效的特征表示应该能够有效地发现不同级别中具有相似性的相关图像,尽管它们不在同一个细粒度类中。我们的框架可以嵌入标签结构,而不降低分类精度。细粒度标签可以基于语义或领域知识自然地分组在树状层次结构中。 图3 细粒度汽车数据集中的标签层次结构 为了在粗类和细类标签的层次结构中构建这样的共享信息,我们根据三元组进行了推广,4个图像之间的这种等级关系可以用两个不等式来描述: (6) 其中两个超参数m1和m2满足m1>m2>0,负责控制两个级别的距离边界。如果满足不等式(6),则d(ri,pi)+m 与三元组相比,这种方法能够在不同级别(即粗级标签和细粒度标签)之间构建更丰富的标签结构。因此,学习的特征表示可以发现适用于特定场景的相关实例,例如,定位具有特定车型和年份的汽车,或从不同车身类型找到SUV。 (7) 实验过程中使用的卷积神经网络都基于GoogLeNet,在细粒度数据集上进行微调以获得最佳性能。输入数据的形式是(ri,pi,ni,li,m),其中li是图像ri标签,m是传统Triplet Loss中可以根据层次结构调整的裕度。输入数据被送入R、P、N网络中,训练过程中它们共享参数。与P和N不同,R的最后一个全连接层与两个模块相连。一个和标签li计算Softmax Loss,另一个被送入L2正则化层生成ft(ri)来计算Triplet Loss。最后,两个损失由λs加权组合进行反向传播来调整参数。 对于超参数,由于将特征尺寸从128至512之间进行过实验,分类精度变化不明显,我们将特征尺寸设为200。将边缘m和基边距mb设置为0.2。Softmax Loss分配更高的权重有助于提高分类精度(即λs>0.5),当λs设置为0.8时,达到较好性能。 为了评估我们的模型,使用Stanford Cars和CUB200-2011作为细粒度数据集。CUB200-2011一共有11 788张鸟类图像,包含200种不同的类别,其中5994张用于训练,5794张用于测试。Stanford Cars包含196个汽车类别的16 185张图像(带边框),其中8144张用于训练,其余用于测试。品牌、型号和年份作为细粒度标签。与文献[14]中的方法相同,将每个细粒度标签分配给9种粗级标签(车身类型)中的一种,形成两级层次结构。 比较了4种能够生成细粒度特征表示方法的检索精度(retrieval precision):(1)基于Triplet Loss的深度神经网络(方法A);(2)在SoftMax之后进行基于Triplet Loss的微调,没有进行联合优化(方法B);(3)提出的联合优化方法,不嵌入标签结构(方法C);(4)嵌入标签结构的联合优化方法(方法D)。 图4表示的是在细粒度级别和粗级别使用4种方法的检索精度。在细粒度级别,提出的多任务学习的结果优于其他方法,在前40个检索中至少高出13.6%的精度。原因是联合优化方法通过三元组利用相似性约束增加了训练信息,帮助网络实现更好的解决方案。无论在我们的框架中使用传统的三元组,还是嵌入标签结构后的三元组,精度差异都在0.5%以内,这可能是由采样方法造成的。在粗标签级别,没有嵌入标签结构的方法也无法在前100个检索中实现高精度,而使用嵌入标签结构后的三元组明显优于其他三元组,证明了嵌入标签方法的有效性。为了便于观察,使用传统的方法和加入标签后的三元组从我们的多任务学习框架中提取特征,并在降维后将其可视化(图5)。随机选择6个粗级类,并从每个粗级类中抽取5个精细级类。由于标签结构的嵌入,始终能比传统三元组的特征更好地分离。 (a) 粗标签级别 (b) 细粒度标签图4 4种方法在Stanford Cars数据集上的检索精度比较 (a) 没有嵌入标签 (b) 嵌入标签 图5 降维后的可视化特征 表1显示了在Stanford Cars和CUB200-2011数据集上几种方法分类准确性的比较。可以看出,一个微调的GoogleNet达到86.9%的分类准确性。而通过三元组学习深度特征达到78.7%,低于微调的GoogleNet的准确性。因为使用Softmax Loss的CNN可以明确地最小化分类错误,而三元组试图通过约束相似性度量来隐式地分离类别。与我们的方法类似,Softmax Loss之后使用Triplet Loss进行微调也是为了结合两种方式进行优化。然而,与我们的联合优化方法不同,它是在学习分类器后嵌入Triplet Loss。这可能会对细粒度图像分类中的分类准确性产生不利影响,因为Triplet Loss仅隐含地约束分类误差,可能会影响在微调期间进一步区分子类。结果,它达到了83.0%的分类精度,比经过微调的GoogleNet差。 表1 不同方法在两种数据集上的分类准确性 我们的多任务学习框架在联合优化两种类型的损失时达到了88.4%(嵌入标签结构)和88.5%(没有嵌入标签结构),高于其他学习特征表示的方法。值得注意的是,使用或不使用标签结构的方法对于分类结果具有非常相似的准确性,因为嵌入标签结构的目的是发现不同相关级别的类似实例,不是为了改善细粒度分类。嵌入标签结构的方法并不能很好的提高分类精度,它主要用来将整个图像作为输入来学习特征表示。它能够在细粒度特征表示中探索出相似层结构中的共享信息,可以应用到电子商务中相关产品的推荐。 本文介绍了一个多任务学习框架,通过嵌入标签结构可以有效地生成细粒度的特征表示。在本文的方法中,标签结构通过所提出的广义三元组无缝地嵌入到卷积神经网络中,可以在不同的相关性水平中结合相似性约束,既能保留具有细微差别的子类图像的分类准确性,同时显著提高了在细粒度数据集上不同级别的标签结构的图像检索精度,这在电子商务中相关产品的推荐方面将有重要意义。但是,对于细粒度图像分类性能没有太大的提高,后续研究会尝试改变网络框架,在提高检索精度的同时也能提升分类性能。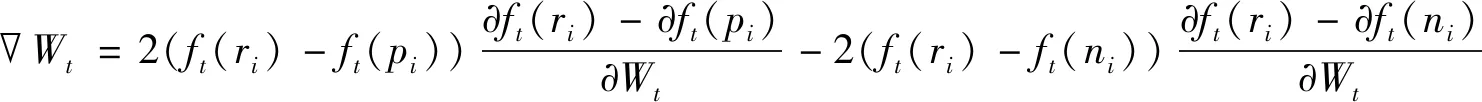
2 嵌入标签结构



3 实 验

4 结 论
