一种网络文本信息情感分类的方法*
2019-12-04姚春华胥小波高弘毅
姚春华,罗 强,胥小波,高弘毅
(1.中电科网络空间安全研究院有限公司,四川 成都 610041;2.海军驻成都地区第二军代室,四川 成都 610000)
0 引 言
网络作为一种新兴媒体,越来越多地发挥出了畅通民意、表达诉求、舆论监督、参政议政的作用。越来越多的人利用互联网表达自己在利益、政治等方面的诉求,表达自己对民生、司法、反腐败等社会热点问题的态度或看法。尤其是在群体性、突发性事件发生时,人们往往会在第一时间通过互联网传递或获取信息。但是,一些敌对势力利用网络的隐蔽环境制造背离主流政治文化的网络舆论,破坏政治稳定和社会和谐;少数别有用心的网民利用网络的便利有意散布假消息甚至谣言,以期达到自己的个人目的;一些网民发泄情绪,在网络上发表庸俗、灰色的言论。传统依靠人工的方法难以应对网上海量信息的搜集与研判,因此需要自动化的情感分类方法判断网络舆情信息,实现对反动、敏感、负面等舆情信息的重点发现。
传统的文本情感分析是基于情感词典进行打分,对文本进行分词处理后匹配情感词典。不同情感词的评分不同,最后对所有词的评分求和,根据评分总数判断文本的情感倾向。在传统方法的基础上,针对长短文本进行不同的识别策略,对短文本采用人工制定分类规则的方法进行情感识别,对长文本分词后采用TF-IDF[1]计算特征权重后,利用训练好的逻辑回归分类器进行情感分类。文本信息情感分类流程图如图1所示。

图1 文本情感分析流程
1 文本预处理
预处理是指采用汉语词法分析系统ICTCLAS对文本进行分词,然后过滤停用词。对目标文档进行情感分类要先进行数据预处理,主要包括分词和去停用词两部分。中国科学院计算技术研究所开发的ICTCLAS汉语分词系统基于层叠隐马尔可夫模型(Hierarchical Hidden Markov Model)[2],能够有效地将输入的文本成功分词,并紧随词性进行输出,并且支持导入用户提供的词典。通过ICTCLAS对输入文本进行分词和词性标注,然后过滤停用词表中的词语,从而去掉无实际意义的词语,实现数据预处理。
2 文本情感分类
2.1 短文本人工情感分类规则分类
对长度小于140个字符的文档,采用人工情感分类规则进行分类。
领域专家分别构建各类别种子词库,通过同义词词林与word2vector[3]扩展种子词库形成各类别特征库;综合计算否定词、句型对词语情感值的影响,判断文档情感值与人工设定各类别情感阀值的大小。流程如图2所示。
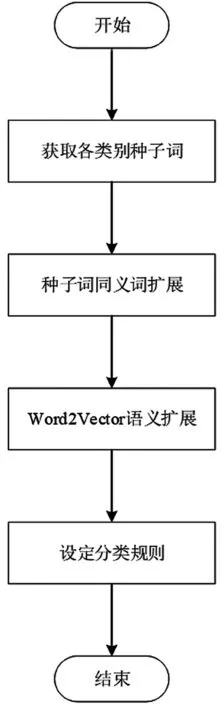
图2 短文本情感分类流程
人工制定文本信息情感分类规则的过程主要包括4个方面。
(1)种子词获取
通过机器学习算法训练文本信息情感分类器,能够得到权重向量w;通过筛选权重值较大的特征词,能够获取到部分分类种子词;综合东北大学、台湾大学、中国知网等机构的情感分类词典,得到最终的情感分类种子词。
(2)同义词扩展
哈工大社会计算与信息检索研究中心发布的《同义词词林扩展版》共包含77 343条词语,按照树状的层次结构把所有收录的词条组织到一起,并提供5级编码。根据《同义词词林扩展版》提供的同义词组,对种子词进行同义词扩展。
(3)Word2Vector语义扩展
Word2Vector是Google在2013年年中开源的一款将词表征为实数值向量的高效工具,利用深度学习的思想,结合词的上下文信息求解文本语义的相似度。Word2Vector使用Distributed Representation[4]的词向量表示方式,采用3层的神经网络对语言模型进行建模,同时获得单词在向量空间上的表示。利用Word2Vector对现有情感分类词进行语义相似度计算,提取相似度较高的词语加入情感分类词典。
(4)根据设定分类规则对文档进行分类,
对情感分类词典中的情感词赋予不同权值,通过否定词与情感词的相对位置信息计算句子内容的情感值,然后结合感叹句、反问句、疑问句等不同句型对整句话情感值的影响,计算句子的整体情感值,将文档所有句子的各类别情感值相加得到的文档情感值与设定的每个情感类别的阀值比较,从而判断文档情感。
2.2 长文本逻辑回归情感分类
对长度大于140个字符的文档,采用TF-IDF计算特征权重后,利用训练好的逻辑回归分类器进行分类。流程如图3所示。
2.2.1 特征提取
通过计算x2统计值选择分类特征,TF-IDF计算特征权重。x2统计也称为CHI统计[5],是统计学中常用的用于度量两个变量的依赖关系的统计量,特征项t和类别c的x2统计值计算如下:

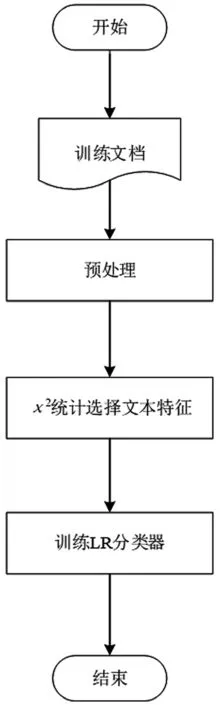
图3 长文本情感分类流程
其中N表示文档总数,A表示包含特征项t并且属于类别c的文档数,B表示包含特征项t并且不属于类别c的文档数,C表示不包含特征项t并且属于类别c的文档数,D表示不包含特征项t并且不属于类别c的文档数。
在得到t在每个类别中的x2统计值后,可以根据式(2)计算t对所有类别的x2统计平均值。

其中,P(t,ci)表示特征项t属于类别ci的概率。
在进行特征选择时设定阀值,仅保留x2统计值大于阀值的词项作为特征项。
在筛选得到特征项后,通过TF-IDF方法对不同特征项赋予权值,对区分度高的特征项给予更大权值。TF-IDF权重计算公式为:

其中tf指的是特征项词频,n表示的是包含当前特征项的文档数,N为文档总数。
2.2.2 训练LR分类器
采用逻辑回归算法(Logistic Regression Model,LRM)[6]构建分类器。通过数据预处理以及特征,提取能够将文本表示为向量空间模型中的N维向量,将此N维向量作为逻辑回归分类器的输入,文档情感判别结果作为分类器输出,对分类器进行训练。在逻辑回归分类算法中,使用交叉熵代价函数来度量预测错误的程度,计算公式如下:

其中y为期望的输出,a为分类器实际的输出。为避免训练过拟合,设置参数c为200,设置梯度下降算法[7]学习J(x)最小值的步长δ参数为0.01。
经过训练能够得到权重向量w以及偏置量b,通过式(5)能够根据给定的输入实例x计算得到其属于某一类别的条件概率分布P(Y|X),而概率值最大的类别则为其所属类别。

3 实验分析
通过网络爬虫获取包括新浪微博、论坛、新闻网站等200 000条数据进行测试,在所有算法判定的结果中随机选择对应数目的观察样本(随机JAVA代码为(int)(Math.random()*n),其中n为200 000条测试数据中算法判定为相应类型的样本数目)。同时,记录5名情感研判人员判定同一观察样本的结果,最后取人数最多的结果为样本的真实结果。表1中的数据为测试结果,可以看出本方法对于反动、敏感、正面、负面的文本情感分类的准确性都较高。

表1 算法测试结果表
4 结 语
本文通过对需要分类的文档进行预处理,根据文本长短,对长度大于140个字符的文档采用TFIDF计算特征权重后利用训练好的逻辑回归分类器进行分类;对长度小于140个字符的文档,采用人工情感分类规则进行分类。与现有技术相比,本文针对长文本、短文本的不同特点,采用机器学习算法构建分类器与领域专家制定分类特征相结合的技术路线,能够快速准确识别文本的情感。实验表明,本文提出的方法具有较高的准确率。
