定制SRAM 存储器的时序功耗模型的自动抽取∗
2019-11-29田新华胡日辉
田新华 胡日辉
(上海高性能集成电路设计中心 上海 201204)
1 引言
为提升访存性能,处理器的指令和数据CACHE 设计往往采用定制SRAM 存储阵列[1~2],这就需要对这些定制阵列的时序和功耗建模,以将其整合到芯片整体设计与分析流程中。
目前定制SRAM 存储器阵列的时序和功耗建模大多通过spice仿真模拟来实现[3~4],具体来说,就是根据存储阵列的功能及读写时序要求,在多种读写场景下对其进行时序和功耗模拟[5~7],并从仿真结果中抽取时序和功耗模型,最终形成lib 文件,整个过程非常繁琐耗时。为提升工作效率,本文给出了一种借助Siliconsmart 工具对定制SRAM 存储阵列进行时序和功耗建模的方法,实现了对其时序功耗模型lib 文件的自动抽取,从而更便利地将定制SRAM 存储阵列设计整合到后续更高层次的设计与分析流程当中。
2 定制SRAM 存储阵列的基本结构和时序功能
2.1 定制SRAM存储阵列结构
定制SRAM 存储器阵列可以分为单端口读写、双端口读写等结构,主要由SRAM 存储单元阵列以及外围字线译码电路、灵敏放大器、位选、预充等电路组成[8~13]。图1给出了数据DCACHE 中定制双端口SRAM 存储阵列的结构示意图,图中白色的小方框是SRAM存储单元。

图1 双端口SRAM存储阵列结构示意图
对于单端口读写结构,存储单元由6 个晶体管组成,如图2(a)所示,外围电路包括一套字线译码、灵敏放大器、位选、预充控制等电路,而对于双端口读写结构,存储单元由8 个晶体管组成,如图2(b)所示,外围则包括两套字线译码、灵敏放大器、位选、预充等电路分别对应两个端口,如图1 所示,可以看到每个存储单元连接到两个端口的两套字线上。
2.2 定制SRAM存储阵列的功能和时序
根据DCACHE 读写功能及时序的设计要求,定制双端口SRAM 存储阵列的主要功能[14]描述如下:阵列包含两个端口,一个为只读端口P0,在时钟上升沿读使能有效时,读出该端口输入地址存储单元中的数据并在当拍输出;另一个端口为读写口P1,在时钟上升沿读使能有效时,读出该端口输入地址存储单元中的数据并在当拍输出,而在时钟上升沿写使能有效时,在当拍将此端口的输入数据写入输入地址中存储单元,读使能和写使能同时只能一个有效;SRAM 存储阵列两端口相互独立,可在同拍实现两个读操作或一个读操作和一个写操作,前端代码设计需保证两端口同时分别进行读写操作时,地址不发生冲突。

图2 SRAM存储单元结构
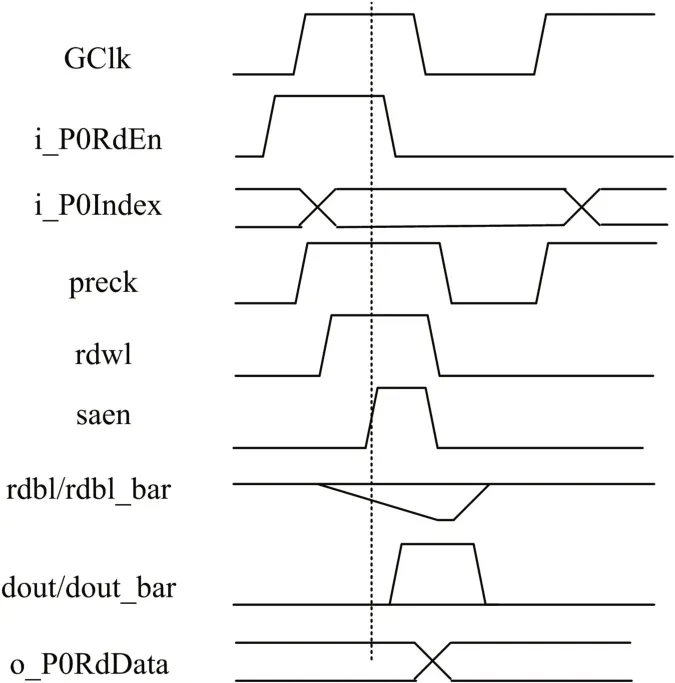
图3 双端口SRAM阵列读操作时序
图3 给出了双端口SRAM 阵列的读操作时序,GClk 为存储阵列的输入主时钟,其上升沿采样读使能RdEn 和输入地址P0Index;preck 时钟是由GClk 产生的时钟,低电平时阵列位线rdbl/rdbl_bar被预充到高电平;rdwl 是读使能RdEn 有效时由译码器产生的字线打开信号;saen 为RdEn 有效时生成的灵敏放大器使能信号;在预充阶段,rdwl 和saen 不能为高电平,否则会导致预充失败;在GClk上升沿读地址译码,preck 上半拍译码完成后读字线rdwl 到达SRAM 存储单元的LWLA 端口上,如图2(b),这时存储单元的T5 和T6 管打开,由于NT 和NC 中一个为“0”,一个为“1”,rdbl 和rdbl_bar 中的一个开始下降,形成电压差,当电压差达到一定的值,saen 信号开始有效,读出单元数据并输出到dout/dout_bar,最终转换为端口输出o_P0RdData,完成一次读操作。
图4 给出了SRAM 阵列的写操作时序,在GClk上升沿读写端口P1写使能WrEn有效时,输入地址P1Index 译码;preck 低电平时位线对wrbl/wrbl_bar被预充到高电平,此时写字线wrwl 和din 不能为“1”,否则将导致预充失败;preck高电平时,译码生成的写字线wrwl 到达存储单元端口LWLB,如图2(b),T7 和T8 管打开,wrbl/wrbl_bar 中的一个根据din 的值通过T7 或T8 管进行放电,另一个维持不变,这时存储单元中的NT/NC中的一个随bl的下降变为“0”,另一个保持为“1”;写入完成后,wrwl 下降,T7 和T8 管关闭,preck 转为低电平,开始对位线对wrbl/wrbl_bar进行预充,完成一次写操作。

图4 双端口SRAM阵列写操作时序
3 定制SRAM 存储阵列的时序功耗模型的自动抽取
本文基于Siliconsmart 工具针对定制SRAM 存储器开发了时序功耗模型的自动抽取流程。Siliconsmart是Synopsis提供的一种能对定制电路单元进行模拟刻画并抽取模型的工具,支持对定制SRAM 存储器阵列进行模拟刻画和模型自动抽取[15]。针对上述双端口SRAM 存储阵列,整个时序功耗抽取流程如图5 所示,包括导入设计数据及模板、配置、初次仿真及内部约束节点定位、仿真刻画、建模五个步骤。
3.1 导入设计数据及模板
该步骤通过在siliconsmart 的shell 环境下执行如下命令来完成:
import-template xx-netlist xx$CELLName
此步骤的输入包括:SRAM 存储阵列带寄生参数的网表spf 文件,工艺foundry 提供的spice model文件,全局配置configure.tcl 文件和模板文件template.tcl文件。
全局配置文件configure.tcl 描述了建模过程所需要的温度、电压及工艺corner 等PVT 条件,电地pin 名称、输入输出接口pin 的类型信息、还包括spice model文件的路径、建模仿真器的名称及其配置选项的信息,此外还包括建模仿真算法所需各种运算资源的调度方式及其配置信息。
模板文件template.tcl 是Siliconsmart 对定制SRAM 阵列进行模型抽取时所必须提供关于定制SRAM 存储阵列结构的描述文件,对于上述双端口SRAM 存储阵列,其模板文件内容如图6,图中两位的SAEN_SEL用于配置灵敏放大器使能信号SAEN相对preck上升沿的延迟。
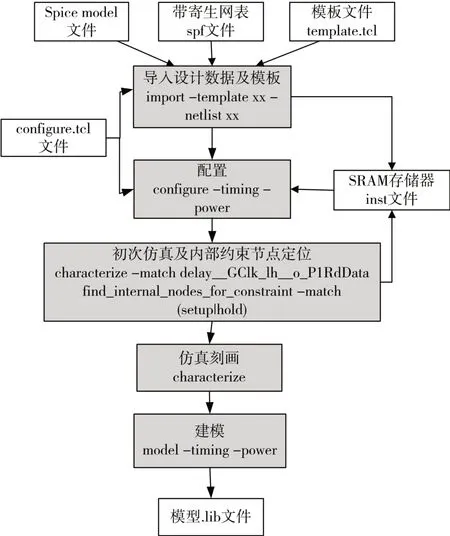
图5 基于Siliconsmart抽取定制SRAM存储器时序功耗模型流程
完成此步骤后,流程会产生一个$Cellname.inst文件,定制阵列的设计者需根据存储阵列的功能和接口时序关系在此文件中添加相应配置,对后续的仿真和建模过程进行配置。

图6 双端口SRAM存储阵列template.tcl配置内容
3.2 配置仿真建模
该步骤通过在Siliconsmart 的shell 环境下运行下列命令来完成:
该步骤吃入全局配置文件configure.tcl 和上一步骤产生的Cellname.inst文件Cellname.inst文件里面已经包含了从定制SRAM 存储器的网表中抽取的端口pin 信息,以及根据模板template.tcl 得到的接口配置信息等;但是在运行configure配置命令之前,设计者还需要根据定制SRAM 阵列的功能和时序要求,添加阵列的状态转换表及相应的接口约束到此inst 文件当中,以便对后续的仿真刻画和建模过程进行配置,具体如图7所示。

图7 定制双端口SRAM阵列inst文件配置内容
图7 中的add_table 命令给出了定制双端口SRAM 阵列的状态转换表,此表被“:”分成三块,左边块表示阵列输入pin 的状态,中间块表示阵列中的存储单元和输出端转换前的初始状态,其中,mem表示低位地址存储单元,mem_2表示高位地址存储单元,iqa/iqb 分别表示端口A/B 的输出端,右边块表示阵列中存储单元和输出端发生转换后的状态;表中的“r”表示时钟上升沿,“H/L”表示高/低电平,“-”表示don't care,“n”代表状态保持不变。
图7中的add_forbidden_state给出了输入pin中读使能和写使能在同一端口不能同时有效,在不同端口,操作地址相同时读使能和写使能不能同时有效的约束。
此外,add_pin mem_int default-internal-spice{dummy}用于阵列setup/hold 约束的内部检查点定位,将其预置为dummy,在后续的约束内部节点定位步骤时,dummy 将被改写替换为实际的setup/hold约束内部检查点,也就是读写操作目标存储单元的网表节点。
完成配置命令运行后,流程会根据configure.tcl和$Cellnam.inst 文件的配置,为后续模拟刻画步骤生成仿真文件模板、testbench 以及仿真激励,为后续的模拟刻画步骤做准备。
3.3 初次仿真及内部约束节点定位
该步骤通过在siliconsmart 的shell 环境中运行下列命令来完成:
characterize-match delay__GClk__lh__o_P1RdData
find_internal_nodes_for_constraint-match(setup|hold)
通过characterize命令带-match选项,仿真器将只仿真该定制阵列GClk 上升沿到P1 端口输出数据的读出延迟的任务,若仿真成功,则验证了上一步骤inst 文件内配置信息的正确性,若失败,则需要修改上述inst文件。
运行find_internal_nodes_for_constraint 命令将会在定制SRAM 存储阵列的spf 网表文件中寻找阵列读写操作目标存储单元的存储节点NT 做为setup/hold 时序仿真检查时的内部检查点,步骤完成后流程会自动修改$Cellname.inst 文件中的约束内部检查节点,将文件中的预置的约束内部节点{dummy}替换为网表中的这个实际的内部检查点。
3.4 仿真刻画与建模
仿真刻画步骤通过运行characterize 命令来进行,该步骤根据配置步骤产生的仿真文件模板以及testbech 文件与仿真激励,产生若干个模拟仿真任务,这些任务的目标包括:模拟仿真存储阵列的初始化、读写delay、setup/hold 时序、leakage power、输入pin 翻转时的power 等,每个模拟仿真任务成功完成后都将产生与文件名前缀相关的任务目标结果文件,诸如setup __i_P0RdEn__hl__GClk__lh__ACQ_1.sof.gz此类的文件,若模拟仿真任务失败,则会产生对应的spice 仿真文件供用户查找失败原因,再去调整配置。
当仿真刻画的所有任务完成后,则进入建模步骤,该步骤通过运行以下命令来完成:
model-timing-power$CellName
该步骤将会吃入仿真刻画步骤生成的结果文件,最终为定制SRAM 存储器产生lib文件。图8给出了所产生的时序功耗模型lib文件的片段。
4 结语
我们通过运行上述流程为DCACEH 中使用的定制双端口SRAM 存储器抽取了时序功耗模型lib文件,并将其与通过直接多场景spice 仿真得到仿真结果后通过脚本处理手动得到的lib 文件进行了比对,由于直接多场景spice 仿真结果的处理脚本只处理时序数据,即手动生成的lib 文件只有时序信息,故只对两者的时序结果进行了比对,比对结果如表1所示:

图8 双端口定制SRAM阵列时序及功耗模型lib文件片段

表1 Siliconsmart建模与hspice+nanotime手动建模时序结果比较
从上述比较数据来看,hold 的偏差似乎较大,但这是由于直接spice 仿真得到的手动建模lib 文件为hold 约束添加了13.5ps 的设计margin,而siliconsmart 抽取的lib 文件未添加这个margin,故实际偏差应可接受。
另外,通过Siliconsmart 抽取的时序模型比直接spice 仿真手动抽取的模型结果稍偏乐观,这是由于Siliconsmart 使用的是包括了整个存储单元阵列、时钟、字线译码、预充控制、位选和灵敏放大器等所有部分的打平的网表,而直接spice 仿真得到的lib 文件的产生过程,采用的SRAM 阵列只是包含了一列包含位选和灵敏放大器的block 级阵列,根据多个读写场景的仿真结果产生的手写model,再通过nanotime 时序分析工具吃入多个例化的block级阵列的model以及时钟、译码电路等进行建模分析得到的lib 文件,其分析是层次化的,这里面会添加一些额外的时序开销。
