卷积神经网络低位宽量化推理研究∗
2019-11-29姜晶菲
付 强 姜晶菲 窦 勇
(国防科技大学计算机学院 长沙 410073)
1 引言
深度卷积神经网络最近在图象分类[1]、物体检测[2]等任务中取得了全面进展,得到了广泛的关注与应用,但也存在着计算和访存量巨大的问题。ImageNet[10]图片分类、FaceNet[5]人脸识别,都需要在高性能GPU 或CPU 集群上训练几百小时以上。Xception[6]在谷歌3.5 亿张私有数据集图片上使用了60 块英伟达K80 GPU 训练了1 个月仍未完全收敛。目前公布的最好的人脸检测算法RetinaFace[3]在Tesla P40 上执行4K(4096*2160)输入图片的人脸检测时需要2s/帧。较流行的MTCNN[4]人脸检测算法,当输入4K 图片、最小检测脸为12 像素时,仅P-Net 的计算量就达到16.1G 乘累加操作,中间激活值达1.82GB(单精度浮点数据格式)。因此,本文主要关注卷积神经网络的非重训练量化。对采用大量数据和算力得到的预训练模型直接进行低比特量化,尽量保留模型权值的有效信息进行推理预测。
卷积神经网络权值的初始化及中间激活值的均衡在采用随机梯度下降(SGD)方法训练的网络中对网络收敛起到决定性作用,不同于早期网络使用的Dropout[7]、LRN[1]方法加速网络收敛,批规范化[8](BatchNorm,BN)对卷积层输出激活值的各通道实现批规范化,能更有效地加速网络收敛。Re-LU[9]使用分段线性激活函数代替传统的sigmoid 或tanh激活函数,能够加速网络训练收敛速度却几乎不影响网络的精度。因此当前广泛使用的卷积神经网络普遍采用卷积-BN-ReLU 激活的方式进行运算。论文利用RGB 图像均衡和融合后的批规范化层权值、激活值的分布特点,提出使用16bit-9bit的全局量化方法,实现目标检测任务精度与数值表示精度的平衡,并在人脸关键点检测任务上验证了该方法的效果。
2 基于BN 与ReLU 的卷积神经网络推理计算过程
在图像检测任务中,一般需对输入RGB 图像进行数值均衡。不同于ImageNet 分类任务中减去大规模数据集上的RGB 通道统计均值,检测任务中一种常用的方法是对输入的RGB 通道减去127或127.5 进行数值均衡,从而使输入图片像素值分布在[-127 128]或[-127.5 127.5]之间。
在采用批规范化的卷积神经网络中,卷积层的输出并不加偏置,因此可以将卷积层输出激活值yi看为权值W 与卷积窗口像素值x 的向量内积:

对卷积层与批规范化层融合后的输出激活值计算公式为

式(2)中μ 为卷积层各输出通道在训练集上的统计均值,σ2为卷积层各输出通道在训练集上的方差,ε 是为避免除0风险而引入的超参数,γ 为缩放系数,β 为平移系数,yˉt为批规范化后的最终输出激活值。当网络训练完毕进行推理预测时,由于μ、σ2、γ、β 均已确定。式(3)中Wˉ为层融合后的权值,βˉ为层融合后的偏置值。在上述计算后,使用ReLU 激活:ReLU(yˉt)=max(yˉt,0),然后进行接下来的卷积或池化运算。
从式(3)可以看出批规范化融合后的卷积层也可以表示为卷积加偏置的计算过程,与不使用批规范化的卷积层有统一的计算形式。
3 BN层融合后的全局量化推理方法
3.1 卷积神经网络权值与激活值分析
由于自然图像在进行数值均衡后任然分布在[-127 128]的较大数值范围内,这与采用批规范化的卷积神经网络中间层激活值分布在0 点附近较小范围内不同,因此根据卷积操作的线性性质,将第一层除128,使其数值限定在[-1+1]范围内,并在融合后的第一层权重上乘128,公式为
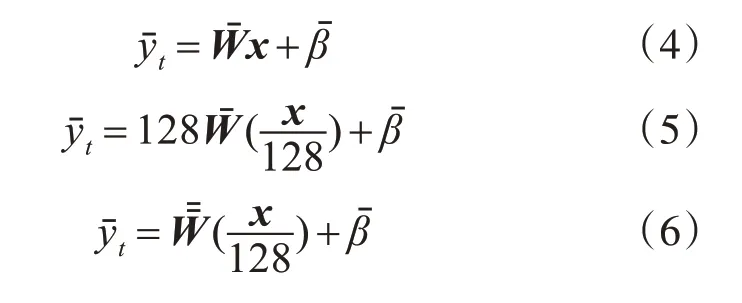
3.2 卷积神经网络16-9bit全局量化
基于第3.1 节的分析,我们提出一种卷积神经网络批规范化层融合后的全局16-9bit量化方法。
3.2.1 首层输入像素值量化
首先认为输入的RGB图像像素值为[-2+2]区间内的9 位定点带符号小数,数据格式为1-1-7bit(1 符号位、1 整数位、7 小数位)。同时对批规范化层融合后的卷积权值放大128 倍,从而实现了式(12)中的等效变换并充分保持了原始输入数据的精度。
3.2.2 权值全局量化
使用1-1-14bit(1 符号 位、1 整数位、14 小数位)的定点小数结构表示所有层的权值,充分保留权值的精度,对于权值小于2×10-14的数值统一量化为0,这等效于全局权值剪枝。
3.2.3 激活值全局量化
在采用ReLU 的卷积神经网络中,所有的激活值都为正值,因此我们在激活值逐层存回时认为其为8bit 无符号正数。在激活值从内存载入进行下一层的运算时,我们在8bit输入激活值的基础上高位补0构成9bit带符号数进行卷积的计算。激活值的格式为1-1-7bit,与第一层输入图像像素的格式保持一致。
3.2.4 乘累加单元配置
由于乘累加单元(MAC)的输出值寄存器和累加值寄存器并不占用过多资源,我们使用25bit(1-2-22)保 存16-9bit 的 乘 积 值,使 用32bit(1-9-22)保存累加值的结果。偏置值(bias)使用与权值一致的16bit。整体的MAC 单元为16-9bit乘法器。图1为MAC单元执行卷积操作的配置。
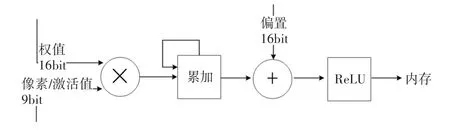
图1 16-9bit卷积乘法单元配置图
4 实验结果与分析
4.1 实验配置
我们使用Caffe[11]对一个采用两个Inception[12]模块的人脸5 关键点检测网络预训练模型[13]进行了批规范化层融合,并对该网络第一个批规范化层融合后的卷积层权值乘128。使用Xilinx Vivado HLS 的定点计算库ap_fixed 模拟CNN 网络中16-9位宽乘法操作。CNN 网络以外的部分(包括NMS、图像插值缩放、边界框生成)与原始Caffe 实现保持一致,均为单精度运算。
我们采用与CASIA WebFace[14]数据集收集类似的方法从IMDB 网站上收集了100 张500*500 到2000*2000 大小的图片作为测试集,这100 张图片包含10 个人,每个人10 张图片。手工确认每张图片只包含指定的1个人。图2展示了测试图像的图例。

图2 测试集图像
4.2 实验结果
我们对单精度Caffe 实现的检测框与采用16-9bit量化CNN 生成的检测框进行了交集除并集(IOU)计算。作为比较,进一步计算了权值与激活值均为半精度浮点数时检测结果,以及激活值为9bit,权值偏置值为8bit时的检测结果。
我们使用当前广泛使用的MTCNN[4]以及RetinaFace[3]对100张图片进行了5关键点检测,人工剔除误检测的关键点,取MTCNN 与RetinaFace 的平均值作为GroundTruth 关键点。并分别使用单精度、半精度、16-9bit 定点与8-9bit 定点、测试了平均IOU,结果如表1。
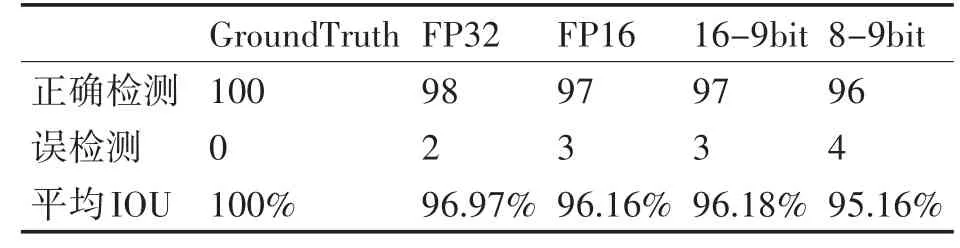
表1 不同数值表示精度检测效果
为了检验关键点对后续人脸核验任务的影响程度,我们使用通用的5 点相似变换对人脸进行了转正,并使用同样在CASIA WebFace[14]数据集上训练 的SphereFace[15]模 型 提 取 了100 张 检 测 脸 的 特征,通过比较余弦距离绘制了ROC 曲线如图3。图中实线表示caffe 单精度浮点运算实现的人脸检测网络的SphereFace 识别效果,虚线代表本文提出的16-9bit 定点人脸检测网络的SphereFace 识别效果。

图3 单精度检测与16-9bit人脸检测下的人脸识别ROC曲线
4.3 结果分析
从实验结果可以看出,使用16-9bit 量化的效果在IOU指标上达到了接近半精度的效果,证明了采用这种量化方法的有效性。在表2 中我们对采用2 个inception 模块[13]进行人脸检测的网络权值与激活值的访存量进行了分析。16-9bit 量化对访存量的需求显著减小。
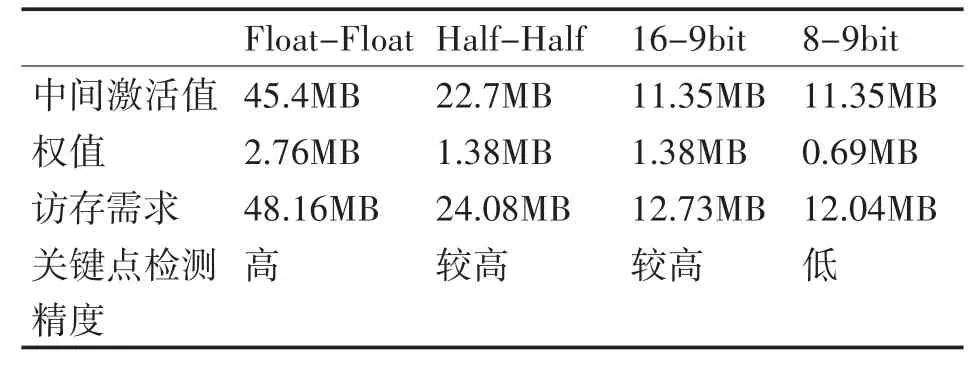
表2 不同精度运算时的访存量分析
限于仿真的耗时,我们采用的测试数据集较小,这导致从人脸识别任务的ROC 曲线看,16-9bit量化的效果与原始单精度推理还存在一定差距。但如果综合考量硬件逻辑复杂程度、功耗以及表2中列出的访存成本,16-9bit 量化方法则具有较大优势。
5 结语
我们通过分析卷积神经网络随着输入图像增大造成计算量及访存量急剧增加的特点,并进一步分析当前广泛使用的卷积-批规范化-ReLU激活计算特点,提出批规范化层融合后使用高精度量化权值,使用低精度量化激活值。在此基础上我们考虑到在FPGA 上部署时的资源运用特点,提出一种非重训练的16-9bit卷积神经网络量化加速方法。该方法非常适合在定制硬件上设计实现。不同于以往在ImageNet 分类和边界框检测上的量化压缩评估方法,我们在具有挑战性的人脸关键点检测问题验证了本方法的精度与量化加速效果。下一步工作中我们将在FPGA 上实现此量化方法,并在大规模人脸检测与识别数据集上进一步验证不同量化位宽对检测精度带来的影响。
