基于小波分解和样本熵的GA-SVM齿轮箱故障诊断*
2019-11-27姜保军
姜保军,曹 浩
(重庆交通大学 a.机电与车辆工程学院;b.城市轨道车辆系统集成与控制重点实验室,重庆 400074)
0 引言
齿轮箱是机械设备中常用装置,一旦发生故障,将会导致机器设备无法正常工作,因此,对齿轮箱故障进行检测有着重要的意义。齿轮箱的故障信号具有非平稳性以及复杂性等特点,其故障诊断方法的研究主要包括特征提取和模式识别这两方面的工作。在特征提取方面,常见的特征提取方法主要包括时域分析[1]、小波变换[2-4]和能量谱等。文献[5]提出了一种利用时序分析方法提取齿轮箱故障特征最终获得较好的实验结果,文献[6]利用小波和能量谱的分析方法对风电机组齿轮箱故障进行诊断,该方法能准确地诊断出故障的形式以及位置。由此可见,小波分解是一种有效的齿轮箱故障诊断方法,对于机械设备的故障诊断具有重要意义。
在模式识别方面,主要的方法包括BP神经网络[7]、支持向量机(support vector machine,SVM)[8]和深度学习[9]等。BP神经网络算法收敛的速度较慢,并且容易陷入局部极值从而导致网络训练失败[10],支持向量机在小样本的分类能力上具有独特的优势[11],但是在故障诊断的过程中受参数选取的影响较大,通常和参数优化算法结合起来完成故障的诊断,常用的参数优化方法包括网格划分法、遗传算法优化(Genetic Algorithm,GA)[12]和粒子群优化算法(Particle Swarm optimization,PSO),粒子群优化算法容易陷入局部最优,并且在算法上容易不稳定[13]。深度学习主要利用含有多隐层的多层感知器进行机器学习提取更加抽象的类别属性以及特征,其训练过程需要在大量的样本下进行学习并且需要耗费较长的时间[14]。
综上所述,选择合适的特征提取方法以及识别模型对于齿轮箱故障检测十分重要。针对复杂且非平稳的齿轮箱故障信号,本文提出了一种基于小波分解和样本熵的遗传优化支持向量机的齿轮箱故障诊断方法,该方法利用3层小波对齿轮箱故障信号进行分解,对分解后的信号进行样本熵计算,并将结果输入到用遗传优化方法优化后的支持向量机中进行分类,实验结果表明优化后的分类模型具有更高的准确率。
1 小波分解和样本熵
1.1 小波分解理论
小波分解是一种比较常用的信号处理方法。多尺度分解是由Mallat等人在进行正交小波基构造时提出的,按照多分辨分析理论,其分解尺度越大,分解的系数长度越小,对于任意的信号f(x)∈L2(R)均可以分解低频部分(近似部分)和高频部分(细节部分),而接近部分最能反映信号的本质信息,高频部分则和噪音相关[15]。多尺度分析只对低频部分进行进一步分解,而高频部分则不考虑,因此,信号f(x)可以分解为:
f(x)=An+Dn+Dn-1+Dn-2+…+D2+D1
(1)
其中,An代表低频近似部分,Dn代表高频细节部分,n代表分解层数。对于∀Ψ∈L2(R),如果Ψ(t)的Fourier 变换Ψ(w)满足条件:
(2)

(3)
根据分解的需要,可对所得到的低频部分作进一步的分解,这样就能到更低频部分的信号以及频率相对较高部分的信号,然而信号的分解层数不是任意的,其最多可分解成log2N层,其中N为信号的长度。在实际过程中,可根据需要选择合适的分层数。
1.2 样本熵
设时间序列x(n)是由N个数据构成,其计算过程如下:
(1)重构一组m维的向量序列X(1),X(2),X(3),…,X(N-m+1),其中,Xm(i)=[x(i),x(i+1),x(i+2),…,x(i+m-1)],1≤i≤N-m+1。
(2) 计算Xm(i)和Xn(j)之间的距离d(i,j),计算公式如下:
d(i,j)=|x(i+k)-x(j+k)|,0≤k≤m-1
(4)

(5)

(6)
(5)令k=m+1,重复(2)和(3)步骤,得到Bm+1(r)。
(6)求出样本熵SampEn
(7)
由于在实际的计算过程中,N的值不可能无限大,因此当N有限时,其样本熵的估计值为:
(8)
由于参数m和r的取值直接决定最后样本熵的计算结果,因此,本文在对小波系数进行计算的过程中,m设置为2,r设置为0.2。
2 遗传优化算法的支持向量机
2.1 支持向量机
支持向量机(Support Vector Machine,SVM)是由Vapnik 提出来的,其主要思想是建立一个决策分类的超平面作为决策曲面,在解决小样本、非线性以及高维模式下的识别问题中具有特有的优势,其二分类的支持向量机具体形式如下:
给定含有m个样本的样本:
T={(x1,y1),(x2,y2),…,(xl,yl)}∈(X×Y)l
(9)
xi∈X=Rn,yi∈Y={1,-1}(i=1,2,…,l),xi为特征向量。在解决实际问题时,需要选择合适的核函数K(x,x′)和适当的参数C,以达到最优解目的。常见的核函数有三种,即:
线性核函数:
K(x,xi)=xΤxi
(10)
多项式核函数:
K(x,xi)=(γxTxi+r)p,γ>0
(11)
径向基核函数:
(12)
本文选择径向基核函数作为SVM模型的核函数。
2.2 GA-SVM识别模型
遗传优化算法(Genetic Algorithm ,GA)是一种更大范围的寻求全局最优解的算法,它是一种高效、实用且鲁棒性强的技术。基于CV(Cross Validation)意义下的GA优化算法流程如图1所示。
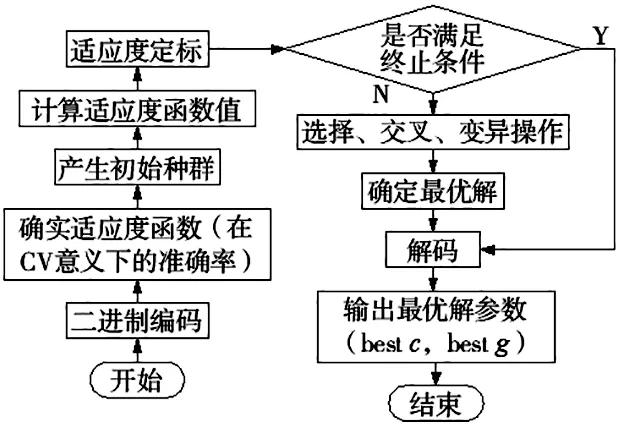
图1 CV意义下的GA遗传优化算法流程图
本文利用GA算法对SVM的参数进行寻优,具体的实验流程如下:
(1)对原始数据进行初步截断处理,以1024个样本点为基准对其进行截断。
(2)对截断后的数据进行小波分解和样本熵计算,构建数据样本特征。
(3)对提取的特征进行归一化处理,归一化的范围为[0,1]之间,对归一化的特征参数数据集进行训练集和测试集划分,并设置相应的训练集标签和测试集标签。
(4)设置遗传算法初始化参数:种群进化代数为200,种群数量为20,惩罚因子c的取值范围为[0,100],径向基参数g的参数范围为[0,100],k-折交叉验证法中的k为5,采用CV意义下训练集精度作为GA的适应度函数值。
(5)利用GA算法选择出最佳的参数c和g,利用训练集训练齿轮箱故障诊断模型。将测试集输入到训练好的SVM模型中进行测试,然后输出测试结果。
3 实验与分析
3.1 齿轮箱故障数据介绍
为了验证本文提出方法在齿轮箱故障诊断中的效果,使用QPZZ-II实验平台模拟齿轮箱故障,获得正常、磨损故障、断磨故障(大齿轮断齿和小齿轮磨损)、断齿故障、点蚀故障(大齿轮点蚀)和点磨故障(大齿轮点蚀和小齿轮磨损)这6种齿轮箱状态数据。数据采样频率为5120Hz,每个齿轮箱状态记录由9个通道进行数据采集,所有的数据均在转速为1470rpm和转速为880rpm下得到,为了验证相同转速下不同负荷时齿轮箱的运转状态,在880rpm的工况下,分别加载0.2A、0.1A、0.05A制动力矩输出电流。4种不同工况下共获得4类数据集,即A、B、C、D数据集,为了验证本文模型在复杂工况下对齿轮箱的故障诊断效果,将相同故障类型数据样本组合在一起构成复合型数据集E。在进行数据预处理的过程中,将数据样本以1024个数据点为基准进行截断,最终同一工况下每种类型数据将得到52个样本,具体的数据如表1所示。

表1 齿轮箱状态样本表

续表
3.2 齿轮箱故障特征提取
对每一类故障数据进行截断之后,需要获得表征齿轮箱类型的特征值,本文采用小波分解和样本熵的方法对样本数据进行特征提取。考虑到小波分解尺度太大会增加数据计算的复杂性,尺度太小可能导致信号分解不彻底,因此本文选择3尺度的小波对样本信号进行分解。在进行3层小波分解时采用db4小波基,然后分别提取不同尺度下分解后的低频系数和高频系数,最后计算其系数的样本熵值,由于一个样本记录由9个通道的数据组成,每一个通道截断后的样本数据通过上述方法处理后得到4个样本熵值,因此一个记录共得到36个样本熵值,最终每个样本由36个样本熵值组成的特征向量表征。利用T-SNE[16]流形学习方法对数据集E进行二维可视化,其结果如图2所示。

图2 数据集E特征可视化结果
从可视化结果可知,对于数据集E中的6类齿轮箱状态特征数据,同一种类别的数据被有效地聚集起来,而不同类别的数据之间呈现较好地分离状态。这说明原始信号经过小波分解和样本熵的特征提取方法后所得到的特征数据具有较好的分类性。
3.3 实验结果与分析
对于数据集A、B、C、D,每个数据集均有312组样本,其中每类故障样本数均为52。从每类状态样本中随机选择26个样本作为训练样本,剩余26个样本作为测试样本,最终每种工况得到的训练集样本数为156和测试集样本数为156个。随机进行10次试验,将最后得到的准确率取平均值,其结果如表2所示。

表2 SVM模型和GA-SVM模型随机试验10次平均结果
从表2可以看出,对应数据集A而言,虽然正常样本的识别率大体相当,但是其余故障类型的识别率均是GA-SVM分类模型比较高,对于数据集B而言,两个模型每类状态样本的识别率整体相当,这可能是样本的特征值均具有较高的区分性。对于数据集C和数据集D而言,除了正常样本、磨损样本以及点蚀样本的识别率相当之外,其余类别的样本识别率均是GA-SVM模型高于SVM模型,因此进行参数优化的SVM识别模型具有更有效的识别率。
为了验证复杂工况下,本文提出模型的实验效果,利用数据集F进行试验,其中“NOR”代表正常样本,“MS”代表磨损故障样本,“DM”代表断磨故障样本,“DC”代表断齿故障样本,“DS”代表点蚀故障样本,“DM1”代表点磨故障样本, 实验结果如图3、图4 和表3所示。

图3 GA算法适应度曲线

图4 GA-SVM测试集样本分类结果

表3 GA-SVM算法分类结果
从图3中可以看出,通过遗传算法优化后得到的最佳惩罚因子参数值c为44.5004,径向基参数g的值为0.18911,CV意义下的准确率为98.89%。由图4可以看出,在624个样本中,只有8个样本预测错误,从表3可以得出,正常样本和断齿故障样本的识别准确率为99%(103/104),磨损和点蚀故障样本的识别准确率为100%(104/104),点蚀磨损的识别准确率为96.2%(100/104),平均准确率为98.7%(616/624)。由此可见,GA-SVM模型能较好的用于齿轮箱故障诊断,并能获得较高的识别准确率。
3.4 对比试验结果分析
为了进一步验证分类模型的实验效果,分别构建传统的SVM、GA-SVM、BP神经网络和SAE(稀疏自编码器),其中SVM模型的核函数为RBF核函数(径向基核函数),BP神经网络输入层节点数为36、隐含层节点数为37、输出层节点数为6, SAE由两层的稀疏自编码器构建,其第一层隐含层节点数为80,第二层隐含层节点数为30,利用Softmax作为分类器。选择数据集A、C和E随机进行10次试验,选择数据A、C和E的原因是这几类数据是常见工况下的故障数据类型,其结果如图5、图6和图7所示。

图5 数据集A随机10次试验准确率

图6 数据集C随机10次试验准确率

图7 数据集E随机10次试验准确率
从图5~图7中可以看出,在随机试验过程中,SVM模型和GA-SVM模型得到的实验结果均高于其他模型,而所有数据集中GA-SVM分类模型所得到的准确率均高于单独使用SVM分类模型所得到的准确率,并且波动比较小,相对比较稳定,这说明遗传优化算法能对SVM中的核函数的参数进行优化并能提高分类器的性能。对于数据集A、C、E,经过SAE堆栈所得到分类模型的准确率不稳定,并且在数据集A中得到的分类准确率最低,因此深度学习网络适用于解决大量样本数据的分类问题。
4 结论
在齿轮箱的故障诊断中,常见的故障诊断只是针对于点蚀、磨损以及断齿进行故障诊断,本文针对齿轮箱4种工况下6类齿轮箱状态样本进行诊断,得出如下结论:
(1)利用小波分解和样本熵方法对信号数据进行特征提取,能达到不同类别样本具有较好区分度的目的。
(2)GA算法能对SVM的核函数参数和惩罚因子参数进行优化,将优化后的参数值输入SVM模型中能获得较高的分类识别率,且准确率均高于单独使用SVM分类模型、BP神经网络模型、经过SAE堆栈得到的深度学习模型,因此本文提出的方法适用于解决多工况下齿轮箱故障分类问题。
