融合掩码约束算法的Spindle Net行人重识别网络
2019-11-23吴丹方明付飞蚺
吴丹,方明,付飞蚺
(长春理工大学 计算机科学技术学院,长春 130022)
行人重识别是指在不同摄像机下进行同一行人的查找和匹配,其主要应用在公共安全领域。虽然行人重识别技术已经发展了20多年,而且目前对其的研究工作也越来越多,但是依然有很多没有很好解决的问题,由于行人重识别是在多个摄像机下进行匹配,这会造成很多问题,例如被遮挡、不同摄像头下的位姿变化和相似的不同行人间的区分等。
本文在Spindle Net[1]网络的基础上导入了行人的掩码策略。Spindle Net能较好解决遮挡和位姿问题,所以本文以Spindle Net为基础加入掩码信息,与一般的行人重识别方法相比,由于添加的行人图片的掩码图中含有很多隐含的信息,掩码边缘特征作为图片中行人最基本的特征之一,将其应用到神经网络中进行特征提取,有助于提取到更多特征,抑制冗余或干扰的特征,在提取更多隐含特征的同时去除背景的干扰并且减少图片的噪声干扰,并在后续减少不必要的数据量处理,最终使得重识别准确率有所提升。本文使用Mask R-CNN来提取行人掩码图,该方法对目标的分割十分精确,为目前效果最好的几种方法之一[2]。本文方法与目前集中行人重识别方法相比,准确率有明显提升。
1 相关工作
对于行人重识别问题的研究可以追溯到1996年,主要针对的是无重叠的监控视频,即多相机追踪[3]。2006年澳大利亚国家信息与通信技术研究所首次提出行人重识别这一概念,此后行人重识别就成为机器视觉领域的热门研究问题。Gheissari等人[4]通过对行人图片的研究和分析,提取到了行人外貌中的稳定区域,主要为行人的颜色和边缘特征,然后使用三角模型对行人的特征进行匹配。Weinberger等[5]提出了LMNN方法,该方法类似于支持向量机方法[6],同类间距离尽可能小,不同类间隔尽可能大。Dikmen等人[7]在LMNN的基础上提出了改进的LMNN-R算法。Li等[8]定义了多种行人服饰的属性,并将LFDA方法应用其中。Zheng等[9]将尺度学习与行人重识别技术融合,提出了PRDC这种改进的距离度量学习算法。Matsukawa等[10]提出了GOG方法,主要是通过像素点分布来表征行人。

图1 网络结构
现阶段的行人重识别技术,只提取行人的全局特征的模型已经达到瓶颈,目前大多都使用局部特征模型。Rahul等[11]将行人图片进行水平分割,分别放入LSTM网络中各自提取特征,最后再将其融合。Zhao等[12]提出了一种类似attention models的思想,旨在只对图片中的行人进行处理,而非整张行人图片。Wei等[13]提出了一种类似于Spindle Net的方法,不同点在于Spindle Net是对整体损失进行计算,而该方法是对不同部分分别计算其损失。
2 网络模型
本文将掩码图与已有的行人重识别网络Spindle Net相融合。网络结构如图1所示,主要分为三部分,局部提取网络、特征提取网络与特征融合网络。
2.1 局部提取网络
局部提取网络主要分为两部分,一个是掩码提取部分Mask R-CNN网络,另一个是骨架提取网络RPN。Mask R-CNN是一种用于实例分割的速度较快且准确率较高的方法,能准确输出目标区域的掩码图。RPN是一种基于串行化的全卷积网络结构,通过使用卷积层学习纹理信息和空间信息进行人体姿态估计。CNN由3个卷积层、1个Inception模型构成。
Mask R-CNN是在Faster R-CNN的基础上加入了输出目标掩码的功能,其网络框架主要分为三个部分,首先是目标检测,就是直接在图片上绘制边界框(bounding box)。其次是对每个边界框中的目标进行分类,本文中使用到的是人的分类。最后是对目标进行像素层面上的分割,输出行人的掩码图。掩码图经过CNN网络后得到原始图片经过CNN后得到

图2 局部提取网络中的提取区域
RPN是用来定位人体的14个关节点,关键点如图2(a)所示,通过这14个关节点将人体分为7个区域,其中宏观区域为:头部区域F2=[1 , 2,3,4]、躯干区域F3=[3 , 4,5,6,7,8,9,10]、腿部区域F4=[9 , 10,11,12,13,14]。微观区域为:左臂F6=[4 , 7,8] 、右 臂F5=[3 , 5,6]、左 腿F7=[9 , 11,12]、右腿F8=[1 0 ,13,14],7个区域如图2(b)所示。
2.2 特征提取网络
经过特征提取网络(FEN)处理后得到包含整体行人、掩码图和七个局部区域在内的9个256维的特征,FEN包含3个网络,特征提取网络1(FEN1)、特征提取网络2(FEN2)与特征提取网络3(FEN3)。
FEN1是由1个ROI pooling构成,将F2、F3、F4依次与进行ROI池化得到,经过FEN1后,统一输出大小为24×24的5个特征图;FEN2由1个Inception模型和1个ROI池化所构成的,在FEN2中将上一层网络中的输出作为输入,得到再将与区域提取网络中的部分输出F5、F6、F7、F8作为输入,分别与进行ROI池化从而得到,经过FEN2后,统一输出大小为12×12的9个特征图。FEN3是由1个Inception模型、1个global pooling层和1个Inner product层构成,以上一层的所有输出作为输入,得到9个256维的特征。
2.3 特征融合网络
特征融合网络采用对应元素取最大值的方法将FFN中输出的9个256维特征,融合成1个256维特征,用该特征表示输入行人的最终特征F。融合过程如图1所示。
3 实验结果及分析
本文的实验是在装载有两个NVIDIA GEFORCE GTX 1080 GPU显卡的电脑上,在Ubuntu 16.04系统下的Caffe环境中运行,本文采用与JSTL相同的设置来生成训练、验证和测试图像集/候选图像集样本,训练和验证集中的行人与所有数据集的测试集行人没有重叠。将PSDB与CUHK02数据集也作为训练样本,但是不用来做测试。在训练过程中本文采取与Spindle Net相同的策略即分步训练方法,该方法是在训练时将所有数据集整合到一起,然后打乱顺序对其进行训练。
图3为Mask R-CNN掩码提取情况,由图可知,该方法的行人掩码提取十分准确,其对后续的特征提取有很大帮助。

图3 Mask R-CNN掩码示例
本文分别在 Shinpuhkan[14]与 Market-1501[15]数据集中进行了测试,采用CMC评估方法,对重识别的准确率进行对比。实验结果如表1与表2所示所示。
从表中可知本文方法在Shinpuhkan数据集中Top-1的准确率有大约5%的提升,而在Market-1501数据集中Top-1的准确率有2%的提高。
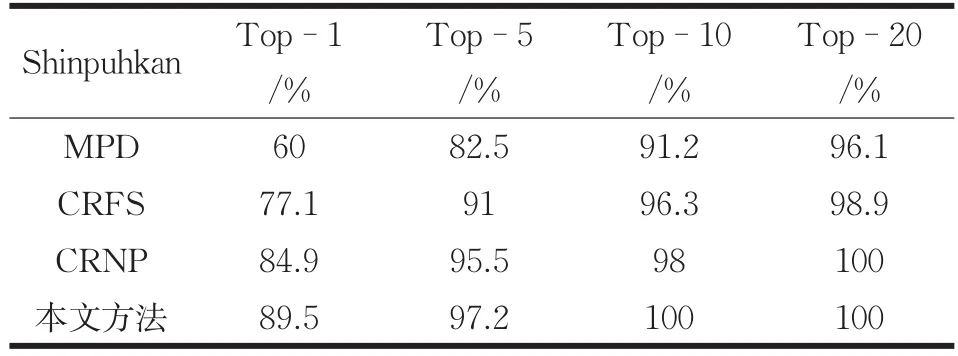
表1 Shinpuhkan方法准确率对比
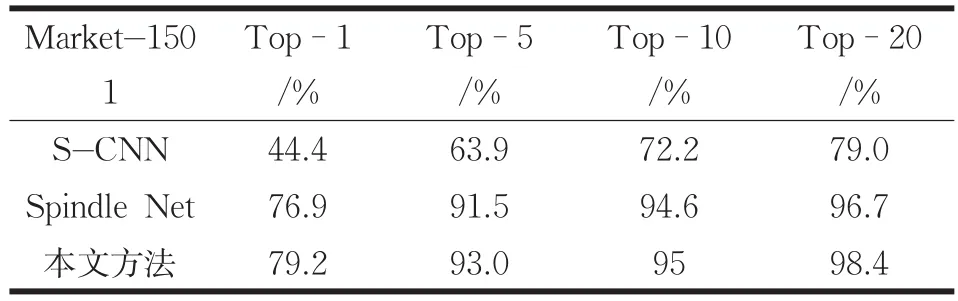
表2 Market-1501方法准确率对比

图4 CMC曲线准确率
为了更直观的表述本文方法与其他方法的准确率,针对不同的数据集,绘制了不同方法在该数据集上的重识别准确率,如图4所示,4(a)为包含本文方法在内的四种方法在Shinpuhkan数据集的准确率对比,可以很直观的看出本文方法对比准确率较高的方法,Top-1的准确率有5%左右的提升,4(b)是在Market-1501数据集中的准确率对比结果。该方法在各个数据集中Top-1的准确率平均有3%的提升。
4 结论
本文在现有准确率较高的行人重识别方法Spindle Nec的基础上引入掩码图,使得重识别的准确率平均提高3%左右,证明该方法对重识别的准确率有一定提高,但同时还有很大改进空间,下一步会对该方法进行更进一步的改进,例如对网络结构进行进一步的精简,或者对网络参数进行微调以继续提高重识别的准确率。
