基于两层叠加方法的武器装备名识别
2019-11-18范文婷
范文婷,王 晓
(太原科技大学 计算机科学与技术学院,太原 030024)
随着信息化技术在军事领域的广泛应用,当前军事信息量激增,作为军事领域信息抽取的基础,军事武器装备名的识别对于分析和理解军事信息具有重要作用,如有助实现军事文本到自动标绘图的智能转换[1]、作战命令的高精度分词[2]等。研究如何实现准确、高效地从海量军事文本中识别军事命名实体具有重要意义[1-3]。
目前,军事领域命名实体的识别方法同通用领域的命名实体识别任务[4-5]相似,主要包括三种类型:基于词典的方法、基于规则的方法和基于统计机器学习的方法,或者三种方法的结合。例如,游飞等[6]采用基于统计机器学习的深度神经网络分类模型识别军事文本中的武器名称。冯蕴天等[7]建立了基于统计机器学习的条件随机域模型对军事命名实体进行识别,并使用词典和规则对结果进行了校正,取得了90.9%的F值。
除了在机器学习模型的基础上,使用规则或词典进行对结果进行进一步优化外,也可以将多个机器学习模型进行组合,利用各单个机器学习模型的优势,克服单个分类器的不足,实现优势互补,从而获得更好的识别性能。例如:张晓艳等[8]采用混合统计模型(隐马尔可夫和最大熵混合)分别从整体上和局部范围对汉语命名实体的识别进行研究。姜文志[9]等采用多模型结合的方法,分别构建了支持向量机和条件随机域模型对军事命名实体进行识别。
本文采用两层叠加方法,实现军事领域中的命名实体——武器装备名的识别。将第0层四个单独分类器的识别结果进行组合作为第1层的输入,使用第1层的模型对第0层的结果进行更充分的归纳学习,同时发现并纠正结果的误差,克服单个分类器的局限,得到最终的识别结果。从实验结果看,对军事武器装备名的识别,该方法获得比各单独分类器更好的性能。
1 基于两层叠加方法的武器装备名识别模型建立
1.1 特征选择
参考兵器百科全书[10]的武器名,针对武器装备名识别模型选择以下5种特征建立特征函数。
1) 词特征:对军事文本进行分词后的词本身和它的上下文。
2) 词性特征:对军事文本进行分词后得到的词的词性标注。研究表明[11],引入词性特征可以显著提高命名实体的识别性能。
3) 中心词特征:军事武器装备名中通常包括一些特定名词,这些词很大程度上预示武器装备名的出现,这些词称为中心词。如“PLZ-05型自行火炮”中的“火炮”为中心词。
4) 词形特征:武器装备名通常包括英文字母、短横线及数字的组合,即词形通常由英文字母、短横线及数字共同组成,如“WZ-10重型武装直升机”。
5) 词长特征:词的长度信息,确定词的长度是1、2、3-5、≥6中的一种。
1.2 单个分类器构建
基于条件随机域CRF(Condition Random Field)、支持向量机SVM(Support Vector Machine)、最大熵ME(Maximum Entropy)三种不同的机器学习算法,构建了四个有差别的机器学习模型。
Mallet:使用MALLET工具包训练出来的识别模型,MALLET工具包是常用的基于CRF原理和JAVA语言的序列标注工具。
CRF++:使用CRF++工具包训练得到的识别模型,CRF++工具包在命名实体识别上具有较好的性能。
SVM:使用支持向量机SVM训练得到的识别模型。
ME:使用Maximum Entropy工具包训练得到的识别模型。
1.3 两层叠加方法
两层叠加方法的核心思想是,将识别过程分为两层进行,在第0层机器学习的基础上进行第1层的再学习,从而得到最终的识别结果,其中每一层可以选择适合的学习算法。本文中,两层叠加方法的识别过程如下:
1) 第0层:
本层的主要工作是通过学习来构建第1层的训练语料和测试语料,具体包括两步:
①构建第1层的训练语料。针对原始训练语料集D,使用M个不同的学习算法(M为4,即Mallet、CRF++、SVM和Maximum Entropy),进行5倍交叉验证得到M个分类器对训练语料D的标注结果,将这M个标注结果组织成第1层的训练语料集D1.
② 构建第1层的测试语料。针对原始测试语料集T,使用训练语料集D和M个分类器对测试语料集T进行标注,将这M个标注结果作为特征,构建第1层测试语料集T1.
2) 第1层
使用第0层得到的D1作为训练语料,T1作为测试语料,选择CRF++工具包(CRF++在序列标注问题上性能较好),并结合一些其它特征(包含中心词特征、词形特征、词长特征)进行再学习,从而得到最终的标注结果。两层叠加方法的流程如图1所示。
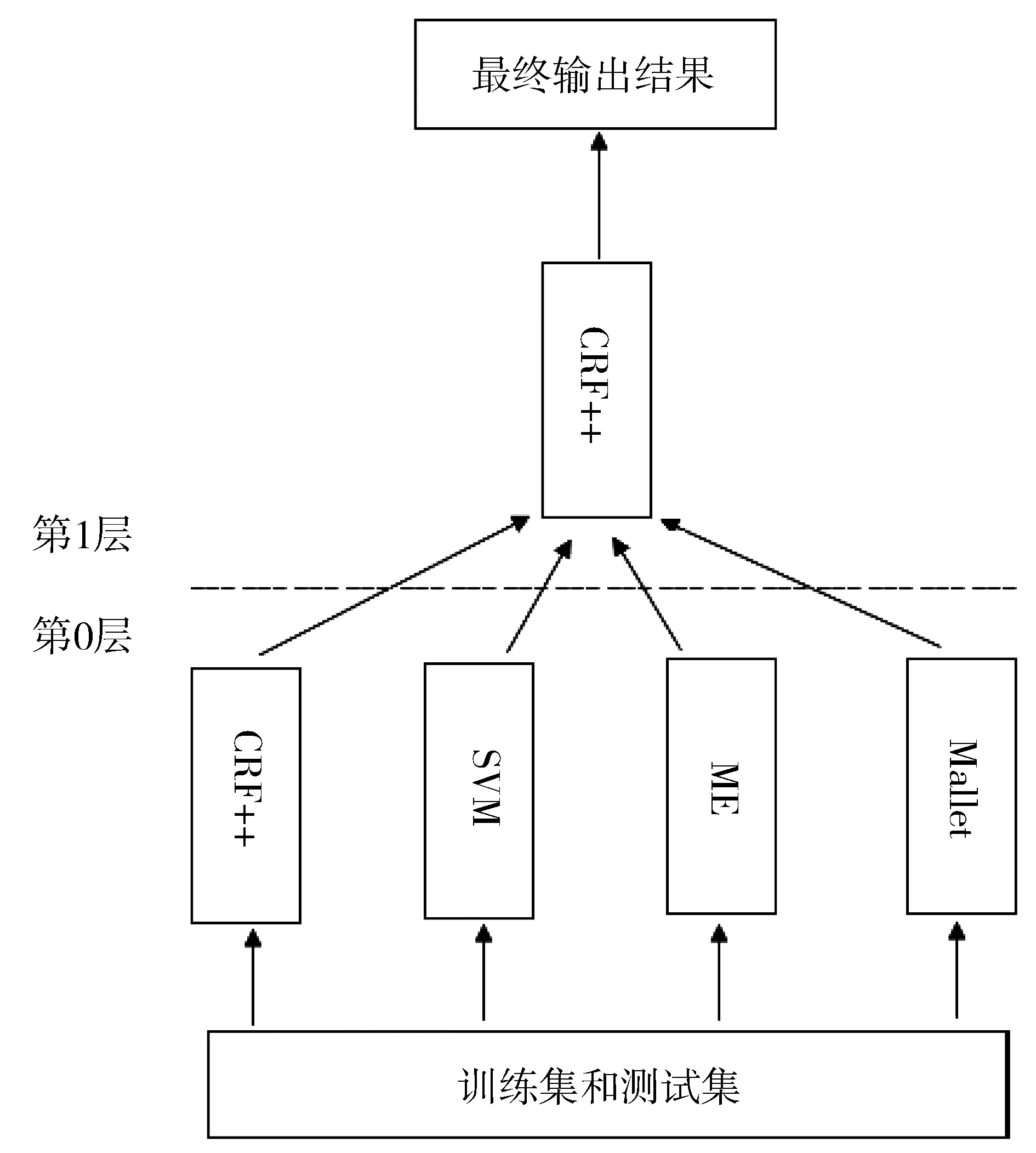
图1 两层叠加方法流程图Fig.1 Flow chart of two-layer stacking architecture
2 实验结果和分析
2.1 实验设置
军事领域文本中的命名实体包括军事机构名、人员军职军衔名、军事武器装备名以及军用地名等多种类型,本文主要针对军事武器装备名进行识别。
由于目前没有比较权威、开放的中文军事语料,因此采用人工收集的方式构建军事文本库,爬取环球网、西陆军事等军事网站文章共6 000篇,对其进行分词和武器装备名标注后作为实验语料,随机抽取80%(4 800篇)作为训练集,其余20%(1 200篇)作为测试集。针对这些军事文本,本系统中设置了两大组实验。
实验组一:采用单个分类器识别
分别采用1.2中的四个分类器对实验语料中的武器装备名进行识别,得到四个单独分类器的识别结果。
实验组二:使用两层叠加方法识别
利用单独分类器的性能和分类器之间的差异性,通过采用不同的组合策略和第1层的再学习得到两层叠加方法的识别结果。
2.2 评测标准
参考命名实体识别常用的测评方法,本文通过准确率P、召回率R和F值三项指标对武器装备名的识别结果进行评测。


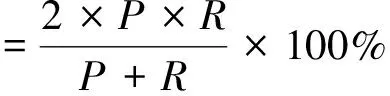
2.3 实验结果与分析
(1)单个分类器的结果
表1列出了四个单独分类器的识别结果,同时在表1中给出了使用各单个分类器进行武器装备名识别所需要的时间开销。
从表1中可以看到,CRF++取得了86.48%的F值,识别效果比其它三个分类器要好,验证了CRF++在命名实体识别上的优势所在。同时在时间开销方面,由于语料比较大,整个训练过程花费时间相对都比较长,其中CRF++性能最好同时消耗的时间也最少,需要8.5 h,而其它三个分类器的时间消耗都超过9 h.因此,在两层叠加方法中,选择CRF++作为第1层的分类器,对武器装备名进行再识别。

表1 四个单独分类器的识别结果Tab.1 Recognition results of four single classifiers
(2)两层叠加方法的识别结果
许多基于两层叠加方法的系统[12-13]表明,两层叠加方法的性能依赖于参与组合的单个分类器的性能、分类器的个数,不同分类器之间的差异性几个因素。鉴于此,在第0层的分类器中,综合考虑各分类器的性能和数目,使用不同的组合策略进行多个实验。其中,由于CRF++的性能最好,将它作为基准,然后按分类器数目和分类器之间的差异性逐一向该基准中加入其它分类器进行实验,得到最终两层叠加方法的识别结果,如表2所示。

表2 两层叠加方法的识别结果Tab.2 Recognition results of two-layer stacking architecture
表2的结果显示,尽管ME在单个分类器中的性能最差,但CRF+++ME比CRF+++Mallet的识别结果要好,这是由于ME与CRF++采用完全不同的原理构建,而Mallet与CRF++都是使用条件随机域算法进行实体识别,前者较后者差异性更大,因此性能也更好。同时从表2中也可以看到,CRF+++SVM+Mallet+ME的结果较CRF+++Mallet+ME差(从92.1%下降到90.98%,下降了1个百分点),即将四个分类器全部参与组合,性能反而降了,这说明并不是分类器的数目越多越好。
从表2中可以看到,CRF+++Mallet+ME取得了最好的识别性能,取得了92.1%的F值。
(3)两层叠加方法和单个分类器的识别时间开销比较
由于两层叠加方法需要对训练语料进行N倍交叉验证,同时还需要在第0层学习的基础上进行第1层的再学习,过程相对更复杂,所花费的时间也较长,为了评价性能和时间的综合质量,选择单个分类器和两层叠加方法不同组合情况中性能最好的模型加入了时间开销对比,结果如表3所示。

表3 各模型识别所需时间开销对比Tab.3 Comparison of time cost for each recognition model
表3的结果显示,由于两层叠加组合模型CRF+++Mallet+ME要经过第0层的交叉验证和第1层的再学习,同时第1层CRF+++Mallet+ME所引入的特征数比单个CRF++要多,使得总花费时间相对比单个CRF++长一些,需要多花费4.6 h.但由于充分利用了分类器之间的差异性,两层叠加方法的性能要比单个分类器有很大提升,从86.48%上升到92.1%,CRF+++Mallet+ME的F值要比单个CRF++高5.62%.作为军事领域信息抽取的基础,武器装备名识别的高精度对后续任务具有重要意义,综合考量时间开销和性能提高,在有限的时间开销内,获得了较大的性能提升,两层叠加方法是有效的。
(3)综合分析
表1和表2综合看到,相比于识别性能最好的单个CRF++分类器(86.48%的F值),两层叠加方法性能更好,即使是最差的组合CRF+++Mallet也能取得86.83%的F值。这是由于两层叠加方法可以在单个分类器的基础上利用分类器之间的差异性,克服单个分类器的不足,同时在第0层学习的基础上进行了第1层的再学习,从而产生较好的性能。
3 结论与讨论
针对军事武器装备名,本文提出了两层叠加方法的识别模型,并通过实验验证了它的有效性。相比于单个分类器识别,两层叠加方法能在第0层学习的基础上进行第1层的再学习,过程更加充分,在再学习的过程中,能够充分利用各单独分类器的优势和分类器之间的差异性,获得较高的识别性能。
在今后的研究工作中,尝试引入外部资源,如军用词典等信息,并结合武器装备名命名规则,对识别结果进行修正,来进一步提高系统的识别性能。同时现在只是实现武器装备名的统一识别,即不对识别出的武器装备进行类别划分,拟作为下一步研究的方向,即对现有语料进行类别标注,然后在此基础上,提出和改进分类算法实现武器装备名分类。
