傅里叶变换衰减全反射红外光谱测定米粉中硒代胱氨酸的硒含量
2019-11-15陈美林杜芬妮单长海莫开菊
陈美林 杜芬妮 陈 业 程 超 单长海 杨 迪 莫开菊,3
(湖北民族大学生物科学与技术学院1,恩施 445000) (恩施土家族苗族自治州食品药品检验检测中心2,恩施 445000) (生物资源保护与利用湖北省重点实验室3,恩施 445000)
1973年,世界卫生组织专家委员会正式宣布,硒是人体生理必需的微量元素,1988年,中国营养学会将硒列为15种微量元素之一[1]。硒在增强抗氧化、提高免疫力和预防癌症等方面有重要功效[2,3]。全国有72%的地区处于缺硒、低硒带,膳食中硒摄入量不足[4],需要通过富硒食品补充。土壤中的硒被植物吸收后通过代谢最终以无机硒和有机硒两种形式存在,其中有机硒占总硒含量的80%以上,由大分子硒(硒蛋白、硒核酸和硒多糖等)和以硒代氨基酸及其衍生物形式存在的小分子硒化物(硒甲基硒代半胱氨酸、硒代高胱氨酸、硒代蛋氨酸和硒肽等)组成[5]。GB 5009.93—2017规定了食品中硒含量测定的方法[6],但是这些方法需要引入有毒的化学试剂,前处理繁琐,分析设备昂贵,要求专业的操作人员才能获得准确的测定效果[7]。而红外光谱技术能准确快速灵敏的测定食品中的化学成分且无试剂参与,绿色而环保。
中红外光谱是由化学成分中基团的基频振动而产生的,具有高度特征性,可利用其化学键的特征吸收来鉴别化合物并定量测定[8]。中红外光谱比较复杂,尤其是像食品这样的多成分的复杂体系中的微量成分的定量分析,难以以某单一峰的强度作为定量分析的依据。因此采用衰减全反射中红外光谱结合化学计量法测定米粉中极其微量的硒代胱氨酸的硒含量将是一项有益的探索。
1 材料与方法
1.1 材料与仪器
东北大米、硒代胱氨酸(98%)、胱氨酸(98%)。
Nicolet iS5傅里叶变换中红外光谱仪、iD7 Transmission衰减全反射附件。
1.2 方法
1.2.1 材料制备
大米在粉碎机内粉碎过140目筛,45 ℃烘备用。
配制1 μg/mL(以硒计)硒代胱氨酸溶液:称硒代胱氨酸(98%)0.108 g(0.05 g)用去离子水定容至1 000 mL(50 μg/mL),取10mL定容至500 mL(1 μg/mL)备用。
将1 μg/mL的溶液用去离子水分别稀释成1、0.98、0.96、0.94、0.92、0.90、0.88、0.86、0.84、0.82、0.80、0.78、0.76、0.74、0.72、0.70、0.68、0.66、0.64、0.62、0.60、0.58、0.56、0.54、0.52、0.50、0.48、0.46、0.44、0.42、0.40、0.38、0.36、0.34、0.32、0.30、0.28、0.26、0.24、0.22、0.20、0.18、0.16、0.14、0.12、0.10、0.05和0 μg/mL的溶液,各取10 mL分别与10 g米粉混匀配成硒浓度梯度分别为100、98、96、94、92、90、88、86、84、82、80、78、76、74、72、70、68、66、64、62、60、58、56、54、52、50、48、46、44、42、40、38、36、34、32、30、28、26、24、22、20、18、16、14、12、10、5、0 μg/100 g的样品,烘箱里45 ℃烘6 h后研钵里研磨均匀。
1.2.2 样品光谱采集
取适量样品置于衰减全反射附件的晶体上,压实;光谱扫描范围:4 000~400 cm-1;扫描次数:32次;扫描间隔:2 cm-1;每个样本分别采集3次。
1.2.3 数据分析
应用TQ Analyst做数据处理、PLS建模和校验。
2 结果与分析
2.1 波段选择
每种化合物都有特征的红外光谱,因此可以进行物质的定性和定量分析。多组分样品红外光谱数据集相对较大,难以简单辨析物质的特征吸收光谱。因此需要合理的选择光谱区间进行分析。选择合适波段能减少计算量、提高精度[9]。
图1为胱氨酸及硒代胱氨酸标准品的红外图谱。由于3 000.00~2 800.00 cm-1受羟基影响大,650 cm-1以后光谱又有较大的噪音,因此取1 600~650 cm-1为特征吸收光谱。由图2能清楚看出硒代胱氨酸较胱氨酸特征波数往波数小的方向移动,波数越小波长越长,即发生了红移,分子折合质量越小,振动频率(波数)越大;键的力常数越大,振动频率越大[10]。这与硒取代了硫元素导致分子折合质量增大、偶极矩减小导致振动频率变小的事实相符。
2.2 模型建立与验证
定量分析模型建立,打开TQ Analyst软件,建模窗口从左向右设置参数:
在Description窗口下选择定量模型的算法Partial least squares(PLS)(偏最小二乘法):在Pathlength窗口下选择光程类型,Constant(恒定光程);在Components窗口下设置定量组分的信息如组分名称、浓度范围等;在Standards窗口下导入数据并选择作为建模和验证的数据;在Spectra窗口下设置数据格式,如Spectrum(原始光谱)、First derivative(一阶导数光谱)、second derivative(二阶导数光谱)等;在Regions窗口下选择波数160 0~650 cm-1;在Other窗口下设置因子数,选择Optimize number of factors each time calibration is changed(每次校准更改时优化因子数);其他设置为默认。
C语言作为一门多数工科类学生必修的计算机语言类课程,被多数高校师生所推崇。通过学习C语言,可以掌握程序设计的基本知识,了解一些通用的计算机算法,培养学生对计算机编程的兴趣,养成良好的编程习惯,同时培养学生能够使用计算机思维去思考和解决专业上所遇到的实际问题。
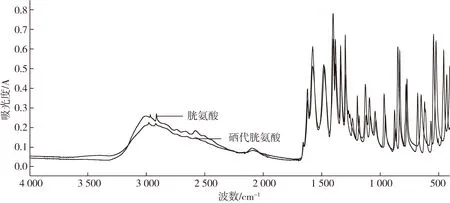
图1 胱氨酸及硒代胱氨酸标准品中红外光谱
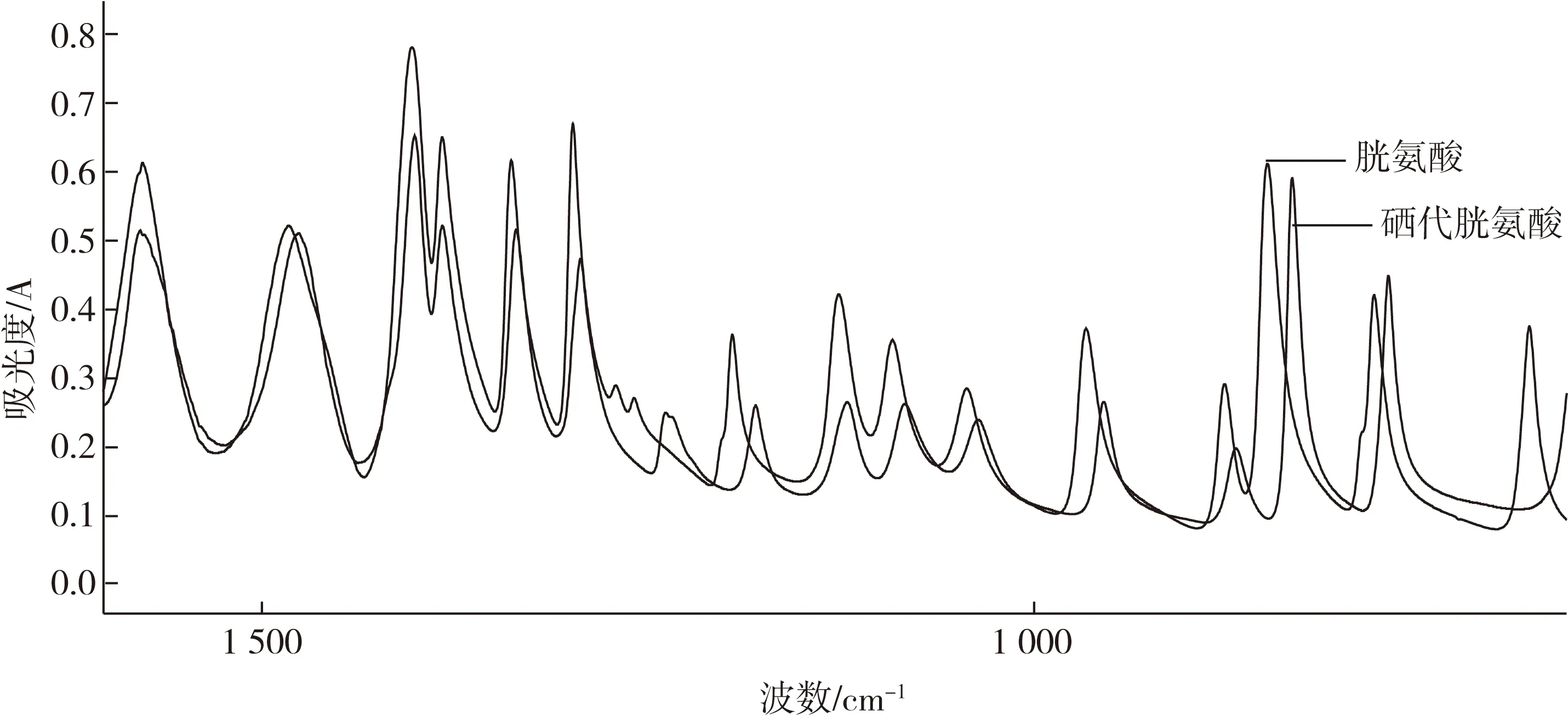
图2 标准样品中红外光谱特征波数
建模窗口设置完后点击工具栏上的Calibrate按钮,计算校正模型,当前窗口就会显示模型决定系数、校正均方差、预测均方差、因子数和校正结果,点击菜单栏上Diagnostics下的Cross-Validation对模型作内部交叉验证,当前窗口就会显示决定系数、交叉验证均方差、因子数和校正结果。
2.2.1 留多模型建立
交叉验证(Cross-validation)主要用于PCR、PLS回归建模中。在给定的建模样本中,拿出大部分样本进行建模,留小部分样本用于对建立的模型进行预测检验。留一交叉验证每次只留一个样本作为验证数据,这样能保证每次计算有最大的训练集,被认为是渐近无偏的估计,当样本量较少时采用留一法,当样本量较大时,留一法计算较繁琐,耗时,留多交叉验证则改进了计算的复杂性,但通常会产生不可忽略的偏差[11];当样本量很大的时候留多验证可以减轻计算量,节约时间。
留多交叉验证每次从数据集中抽出多个样本,用剩余的样本建模并预测被抽出的多个样本,该过程重复多次。若样本数为n,抽出的验证数据为m,则需要进行n/m次交叉验证并获得n/m个模型。对于中度或较小的数据集(n<50),m的取值不应过大,最好的留多交叉验证是m=n×30%[12]。
为了保证验证集分布较均匀,将全部样本分为低中高浓度,分别用随机数生成器产生1/3的样本作为验证集,剩下2/3作为建模集,模型内部采用留一交叉验证。表1是不同预处理后的PLS模型参数。
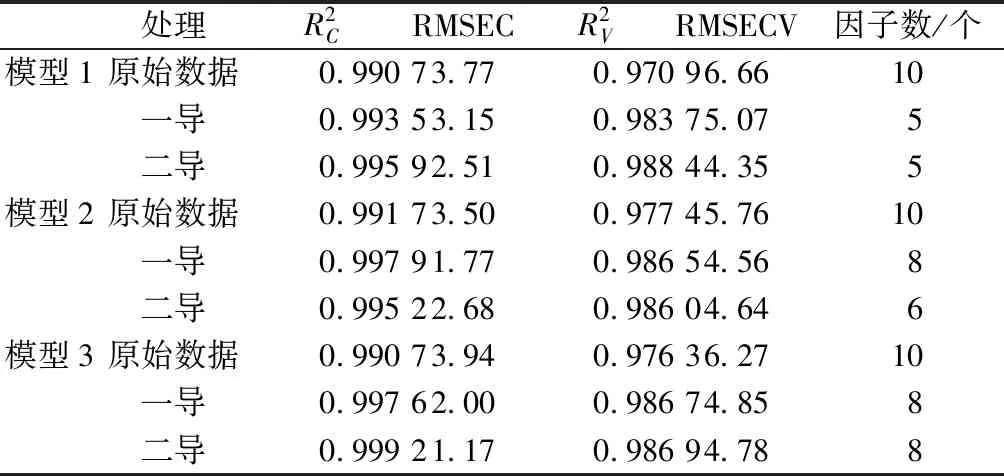
表1 模型参数
2.2.2 留多模型验证
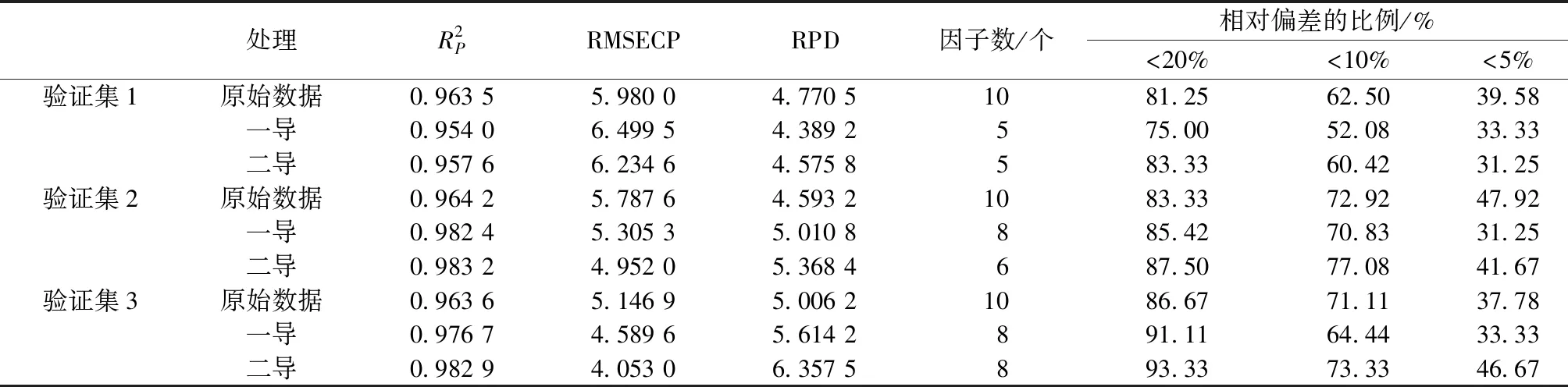
表2 验证集的预测效果
结果显示原始数据及经过一导、二导处理的验证集决定系数都达到0.95以上,RPD都大于3,说明模型都具有很好的预测性能;除验证集1外经过一导、二导处理后预测值与真实值的决定系数都达到0.97以上,较原始数据增大,说明其经过一导、二导处理后预测值与真实值之间的整体方差较小,相对原始数据准确性提高了,二导处理后模型的预测效果比一导略好二导模型验证数据的预测值与真实值的相对偏差在20%以内的占87.50%以上;验证集1经过导数处理后决定系数、RPD都不如原始数据,可能由于模型1只提取出了5个因子,因此丢失了些信息导致预测偏差较大。
为了更清楚看其预测效果,验证集用经二导处理模型计算的预测值与真值的比较如表3~表5。
由表3~表5可知,相对偏差大于20%集中分布在含量小于18μg/100 g的样本中,少数分布在验证集1稍高浓度样品中,这可能是因为模型1的因子数较少导致预测误差较大;含量在18μg/100 g以上的123个样品中只有4个样品相对偏差在20%以上,最高偏差为35.50%,也即相对偏差在20%以内的占了96.75%,含量在50 μg/100 g(不含)以上的样品中,有93.33%偏差在10%以内,只有6.67%偏差在10%以上,没有偏差大于20%的样品。以上数据说明当米粉中硒含量高时,所建模型预测较准确。表5中50 μg/100 g的样品偏差在14.89%~23.23%之间,数据偏大,可能在测试过程中环境条件的偶然变化所致,对这种低概率的非系统偏差应尽量避免,如减少人员进出对环境的扰动。
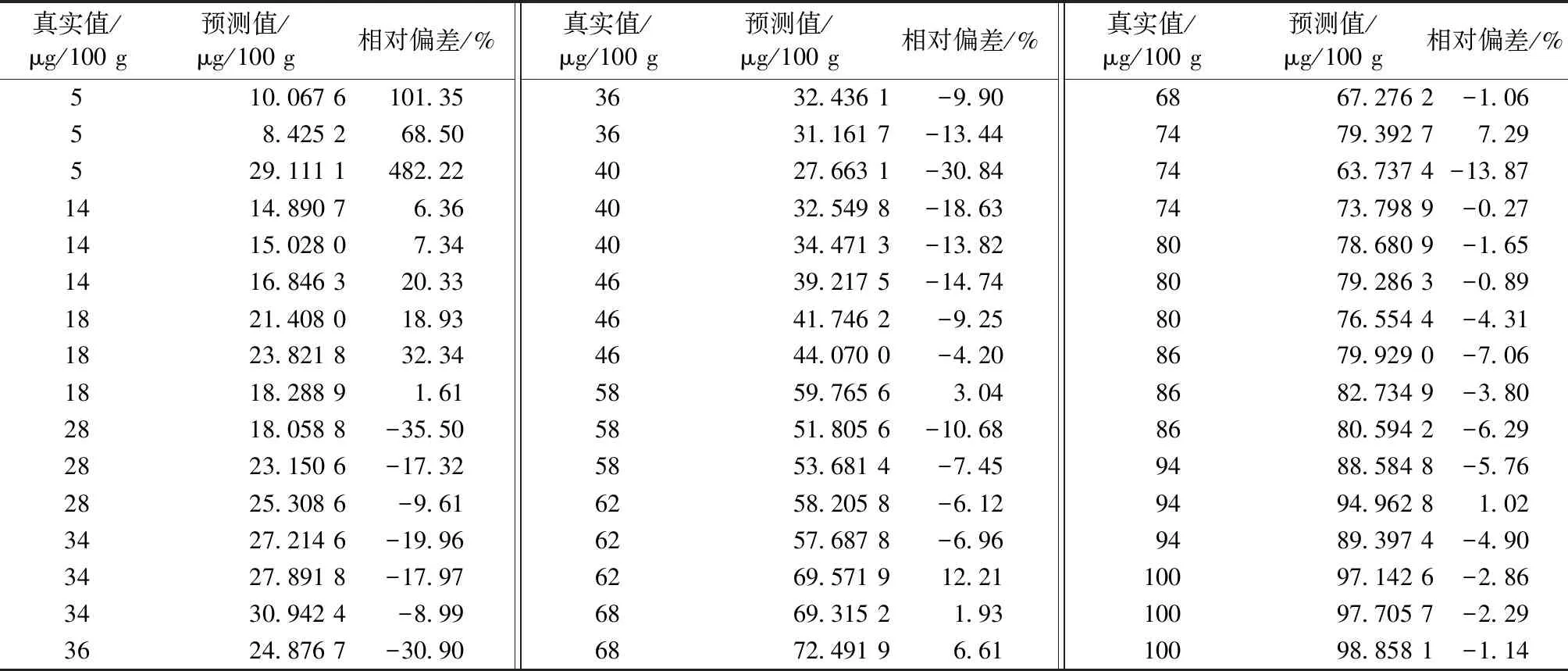
表3 验证集1
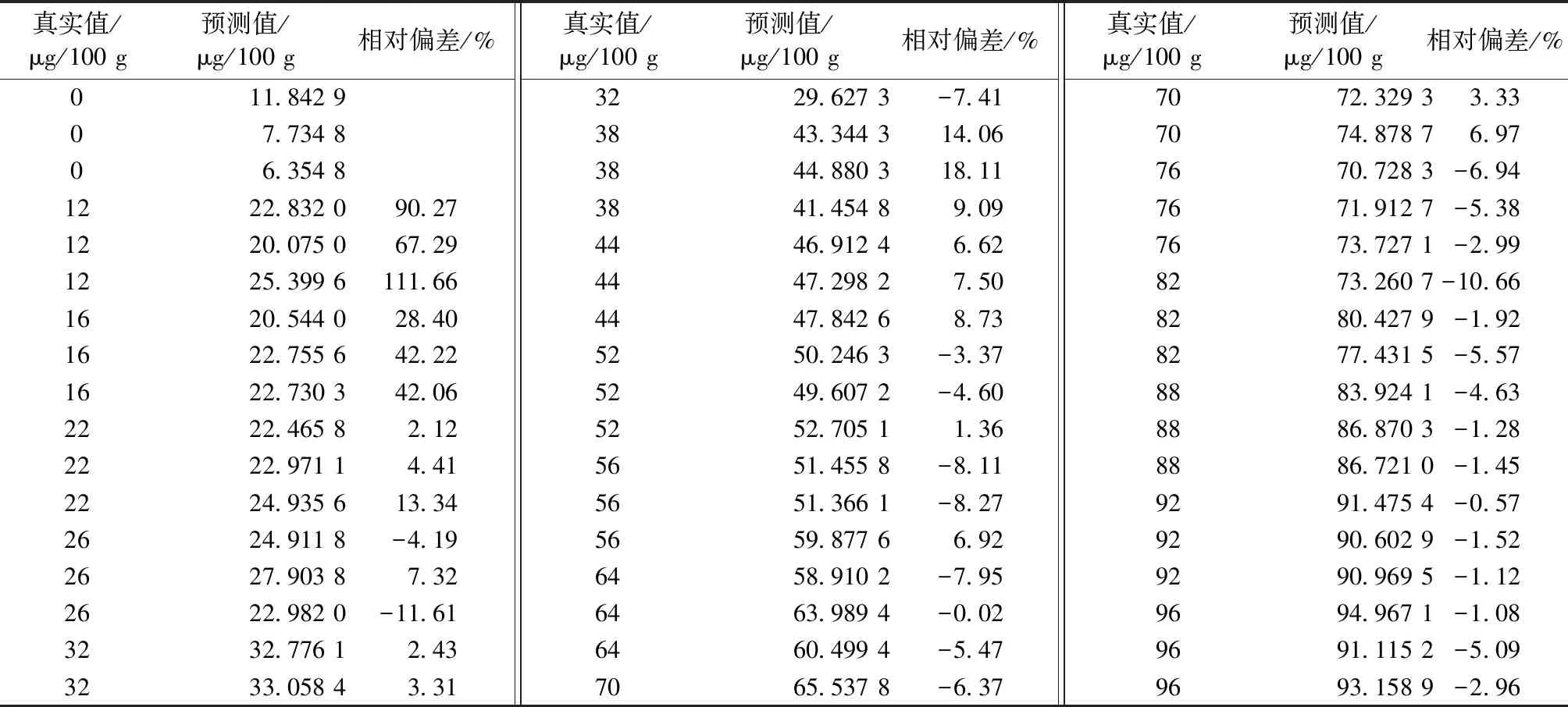
表4 验证集2
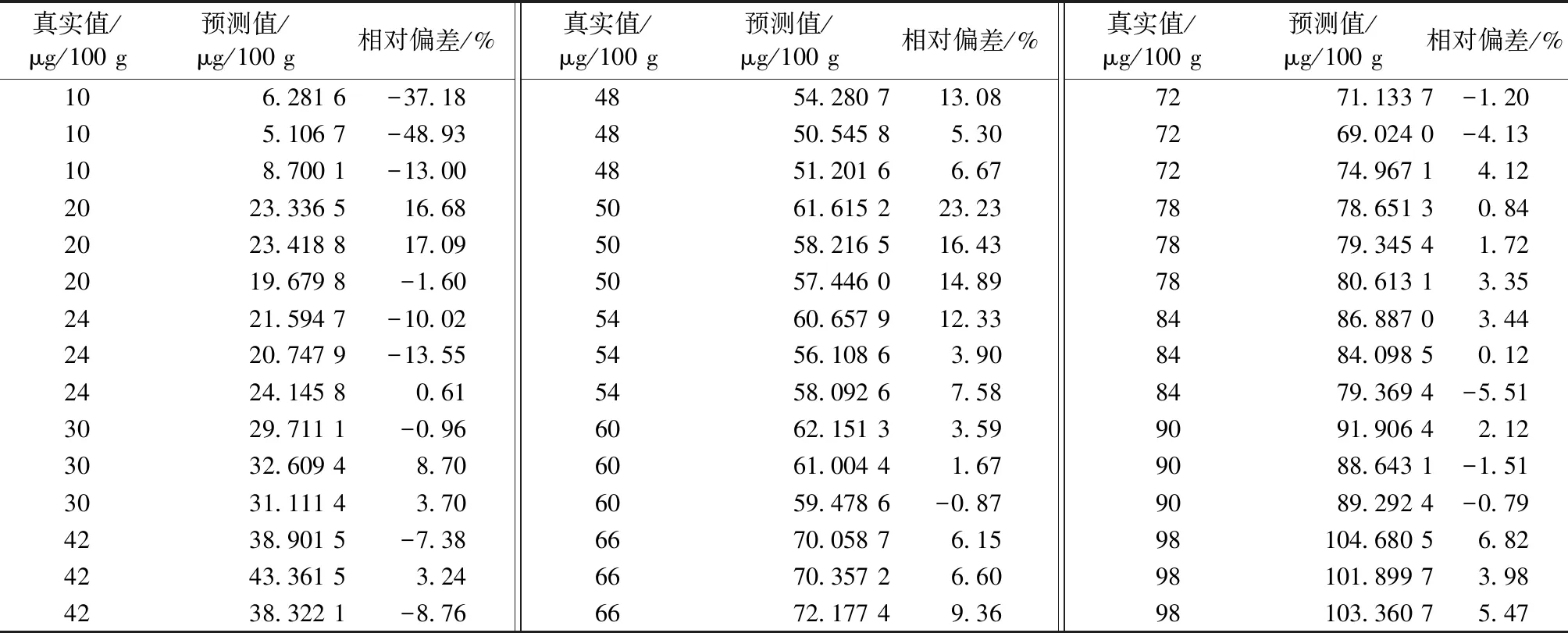
表5 验证集3
为了更直观的比较预测效果,将二导预测值与其真实值进行拟合作图(图3)。虚线是理想拟合线,表明预测值与真实值没有偏差;实线为实际拟合线。
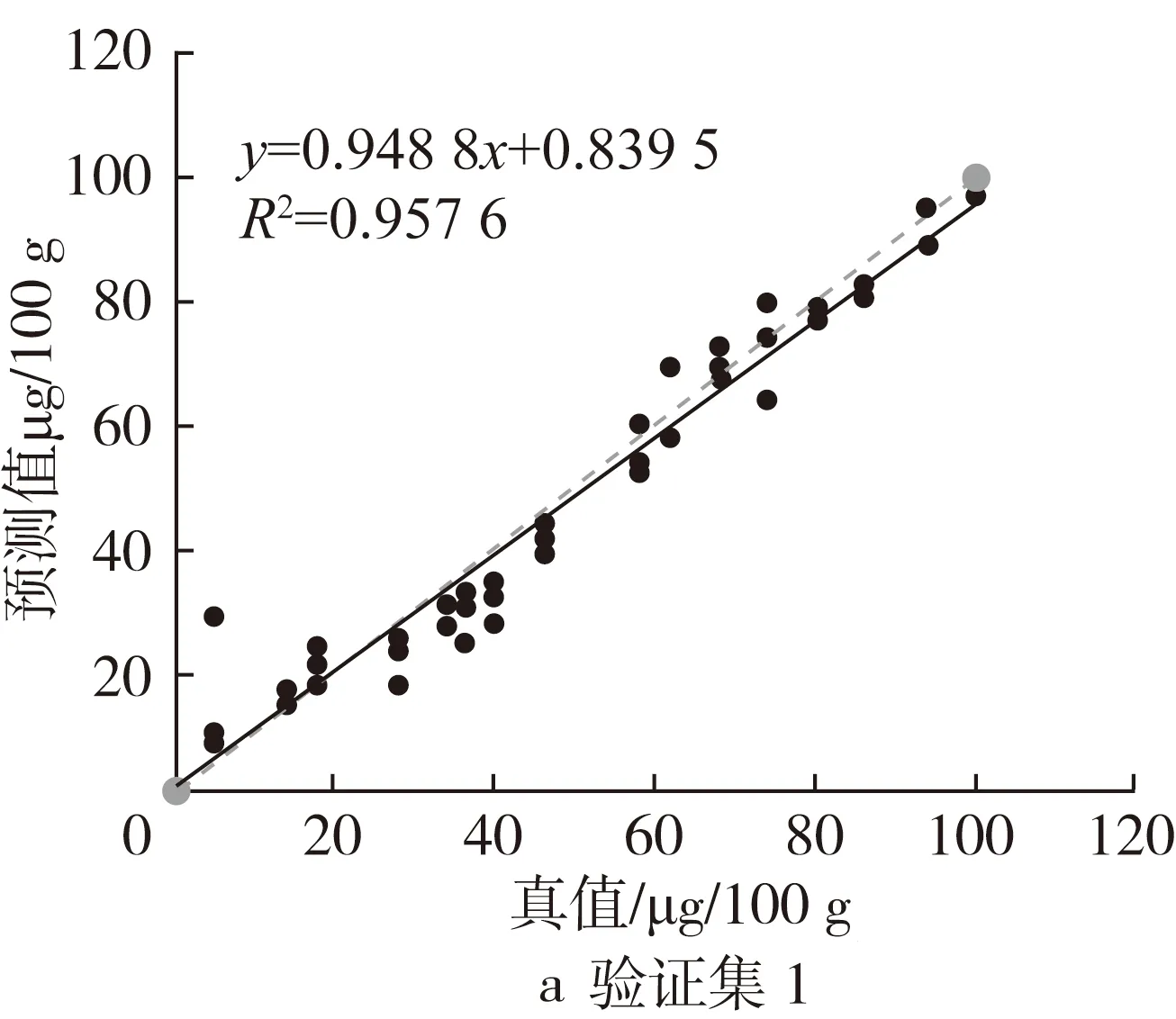
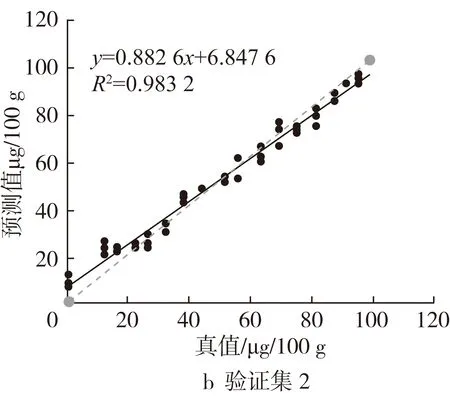
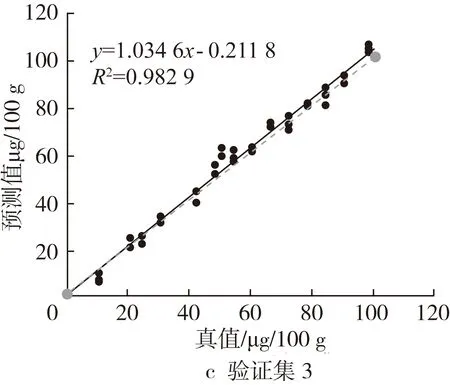
图3 预测值与真值相关性比较
由图3可知验证集1较验证集2和3分布分散,验证集3较验证集2斜率接近1,验证集3整体偏移实际较小。各模型决定系数到达到0.95以上,斜率也较接近1,说明其方差较小且没有整体偏移,预测效果较好。
3 讨论
校正样本的代表性、数量和分布都会影响模型的准确性[19]。化学计量法分析模型是基于统计学原理建立,结果可靠性取决于基础校正集样品数据的代表性,校正样品选择很重要。一般而言样品越多、分布越广,分布越均匀,代表性越强,模型越好。模型3矫正数据范围大,验证集数据都包含在内,分布均匀,所以预测也较准确,模型1和模型2验证集在低含量分布较多,矫正数据分布在相对高含量区域,会导致对低含量区域的预测偏差较大,验证集1和2的预测偏差确实偏大,特别是低含量的更明显。
4 结论
衰减全反射中红外光谱结合偏最小二乘法能建立有效的大米硒代胱氨酸硒的定量分析模型。作为一种快速、准确的定量检测方法,选择1 600~650 cm-1作为特征波段,经导数处理后建模,预测值与真实值的线性拟合决定系数能达到0.95以上,预测与真实值的相对偏差在20%以内的高达87.94%以上,而含量在18 μg/100 g以上的样品相对偏差在20%以内的高达96.75%。本文采用的是单点反射附件,经过一次衰减全反射(单点反射),光透入样品深度有限,样品对光吸收也有限,所得光谱吸收带弱、信噪比差,表现在低含量时信噪比差,预测不稳定、偏差较大,而在高含量时预测更稳定、准确。为了进一步提高18 μg以下低含量样品测定的准确性,今后将采用多点反射法以增加全反射次数使吸收谱带增强,提高测试过程中的信噪比。
