基于差分隐私保护的数据分级融合发布机制
2019-11-11李万杰曹光辉张青云
李万杰,张 兴,曹光辉,李 帅,张青云
(辽宁工业大学 电子与信息工程学院,辽宁 锦州 121001)E-mail:Li_wanjie1014@163.com
1 引 言
随着大数据共享时代的到来,数据的融合能够更好地促进决策分析.例如,人口普查记录的融合能够更全面满足生活情况的调研,病人医疗数据的融合有利于医院分析疾病成因等信息.然而在数据共享带来极大方便的同时,共享的数据存在着隐私泄露的问题.不同的用户对于数据的使用需求不同,当用户的信任等级不同、访问权限不同时,需要发布隐私保护程度不同的数据,这就需要对数据进行分级发布.因此,在数据融合的过程中不泄露数据隐私的前提下,针对用户的不同信任等级、不同访问权限或对数据使用的不同需求,对数据进行融合分级发布,以便达到实现不同等级隐私保护的目的.
国内外学者在数据融合安全发布方面展开了广泛地研究[1-7].K-Anonymity[1]及其改进算法是重要的隐私保护方法.K-Anonymity要求发布的数据记录中至少存在k-1条记录,使得攻击无法识别区分,从而保护用户的隐私信息.K-Anonymity在数据融合方面的研究也一直备受关注.Jiang等人[4]提出了一种安全分布式框架实现了满足K-匿名的数据融合,但当数据量庞大时,该方法花费的时间过长,而且不能实现三表及以上的数据融合.Fung等人[5]提出了一种满足K-匿名的安全融合数据的方法,解决了三表及以上的数据融合问题,但是在每次进行特殊化处理时要计算两方安全最大值,使得整个算法花费较大的时间.文献[6]提出了一种基于K-Anonymity结合自顶向下分类树算法的数据融合算法,减少融合过程所花费的时间,提高融合数据的准确性.但是,这种模型很难抵制背景知识攻击等变体攻击.文献[7]提出了CDTT算法,该算法在差分隐私保护下,构建动态分类树,有效地解决了上述问题,但其算法并没有考虑到用户分级的情况,使得发布的数据利用率不高.
针对上述文献中的不足,提出一种基于差分隐私保护的数据分级融合发布方法,解决了当前数据融合发布机制无法抵御背景知识攻击的缺点,并提供个性化服务的分级发布,同时减少数据融合花费时间并保证了融合发布后的数据具有较好的质量和价值.
2 数据分级融合发布保护的基本工作原理
本节主要阐述一些基本定义及相关概念,包括差分隐私、实现机制、分类树、数据融合等.
2.1 差分隐私
Dwork[8]等人在2006年提出了差分隐私保护模型,其具有严格的隐私定义且可以抵御任意背景知识的攻击.近些年来,被众多研究者应用在隐私保护的场景中.差分隐私保护技术通过向原始数据集的转换或其统计结果添加噪声来达到隐私保护的目的.该方法确保了在任一数据集中更改一条记录的操作而不影响查询的输出结果.此外,该模型可以抵御攻击者掌握了除某一记录外的所有信息的背景知识攻击.差分隐私的定义[7]描述如下:
定义1.差分隐私
给定两个数据集D和D′,二者完全相同或者至多相差一条记录,给定随机算法A,Range(A)表示A的值域,S为Range(A)的子集.如果A满足式(1),则算法A满足ε-差分隐私.
Pr[A(D)∈S]≤eε×Pr[A(D′)∈S]
(1)
其中,概率Pr[·]表示算法的概率,由算法A决定;ε为隐私预算,表示算法A的隐私保护程度,ε的值越小,A的隐私保护程度越高.
2.2 实现机制
实现差分隐私保护常介入两种噪声机制,分别是拉普拉斯机制和指数机制[9].本文主要采用Laplace噪音机制.
Laplace机制[10]通过将服从Laplace分布的噪声介入准确的查询统计结果来达到ε-差分隐私保护的目的.设Laplace分布Lap(b)位置参数为0的概率密度函数为p(x),其表示形式为
(2)
定义2.Laplace机制


图1 Laplace概率密度函数Fig.1 Laplace probability density function
图1为Laplace概率密度函数[12],从不同参数的Laplace分布可得,当ε的值越小,介入的噪声越大.
2.3 分类树
分类树[13]采用泛化技术作为形成分类树的核心技术,将给定数据集中的项作为叶子结点,泛化叶子结点作为分类树的节点,树的根节点是所有叶子结点的集合,其具体表现形式为child(v)→v.图2给出了数据集T={T1,T2,T3,T4}的分类树.

图2 简单数据集分类树Fig.2 Simple dataset classification tree
图中T{1,2,3,4}是分类树的根结点,例如T{1}和T{2}是叶子结点,泛化为T{1,2}作为分类树的节点.在数据融合时,数据拥有者提供数据表的属性分类树.
2.4 数据融合
数据融合是指将两个数据集通过记录中的相同ID合并或将不存在的ID记录加入集合,融合形成新的具有更多属性、更为全面的数据集.数据的融合有利于数据分析者做更好地决策分析.例如,表1为3个用户A、B、C在超市S1购买啤酒I1、可乐I2、牛奶I3产生的购物数据,表2为4个用户A、B、C、D在超市S2购买啤酒I1、可乐I2、牛奶I3、咖啡I4产生的购物数据,将表1和表2的数据融合生成新的融合数据表(如表3所示),为统计并挖掘分析用户的购买行为做好准备.

表1 超市S1购物数据Table 1 Supermarket S1 shopping data

表2 超市S2购物数据Table 2 Supermarket S2 shopping data

表3 融合后购物数据Table 3 Shopping data after fusion
3 基于差分隐私的数据分级融合发布机制
3.1 问题定义
对多个数据拥有者的数据表进行融合,每张数据表代表完整数据集的一部分属性.由于数据使用者的权限等级、付费情况或对于发布数据的使用需求不同,需要对用户进行分级处理,利用用户的等级划分,对数据属性的重要度进行划分,按照重要程度设置不同的隐私预算,在融合数据集中加入与其对应的Laplace噪声.同时保证融合发布后的数据满足:
1)数据具有较好的利用率,可以有效地提供决策分析等操作;
2)数据能够较好地保护数据隐私且不会导致隐私预算耗尽等问题.
3.2 基本框架
数据分级融合发布主要由多个数据源、可信代理及查询用户组成.
1)多个数据源拥有者通过分类融合算法融合数据;
2)对融合后的数据进行个性化的差分隐私处理,在进行差分隐私处理的过程中,根据用户的权限等级或付费情况,设置合理的隐私预算参数;
3)在用户进行查询时,为保护查询用户的身份不被泄露,使用假名机制来实现对用户的隐私保护.该数据分级融合发布机制的框架如图3所示.

图3 满足差分隐私保护的数据融合发布框架Fig.3 Data fusion publishing framework satisfying differential privacy protection
在系统初始化阶段,首先,查询用户需要通过可信代理服务器利用假名机制获得与其身份对应的假名标识符(Alias(ID),ID为用户身份).其次,依据用户访问权限、付费情况或对于数据使用的不同需求,进行等级划分,访问权限高或付费多的资源需要分配高等级,反之则分配低等级(相应等级记为L).可信代理将用户等级存储至查询服务器.数据融合发布系统根据用户身份对应等级,设置不同的隐私预算ε,发布具有相应隐私保护程度的数据集.身份假名与相应隐私预算等级划分如表4所示.

表4 身份假名-隐私预算等级划分表Table 4 Identity pseudonym-privacy budget breakdown table
3.3 算法的基本思想
在数据融合发布机制中,通过介入不同数值拉普拉斯噪声实现敏感数据的隐私保护,本算法根据设定的用户不同等级以及与用户等级相应的的隐私预算ε,实现不同隐私保护程度与查询用户级别的对应关系,最终输出介入不同数值拉普拉斯噪声的差分隐私融合算法融合后的数据,实现对融合的数据分级化发布.
对于数据融合而言,首先初始化一个数据集D0,选出D0出现一次的记录,根据此记录中任意两项出现的次数,选择两项作为第一个分支,然后选出的次数出现最少的两项,选择在其所在行中的最大的值作为第二个分支,依次迭代地选取其它项集与这两个分支组合,直至所有的项集被选出,为D0构造分类树C-Tree(0).设置更新增量H以及与查询用户级别对应的隐私预算εi,其中根据查询用户授权或付费情况等方式来划分用户级别,按照支付金额或授权大小,为用户分配高级别或低级别,并且相应获得的查询结果的准确性也遵循从高到低的原则.当新的数据集Di与D0融合时,先将Di中记录添加到C-Tree(i-1)的根节点,对Di中的记录作下列步骤:(1)如果某记录不为空且被分配到C-Tree(i-1)的非叶子节点中,就按照C-Tree(i-1)的分类方法分配该记录;(2)如果某记录被分配到C-Tree(i-1)的叶子结点,则分割该节点并重新分配该节点的差分隐私预算;(3)如果某记录为空,则对下一条记录做上述步骤,直至所有记录分配完生成新的分类树C-Tree(i),根据分配好的隐私预算向C-Tree(i)的叶子节点添加Laplace噪音,最后依次迭代对于不同的隐私预算参数ε进行以上步骤即可,最终产生具有不同隐私保护级别的融合后的隐私数据.
3.4 算法的描述
采用上述思想设计的算法过程如下.
算法1.
输入:初始数据集D0,D1,D2,…,DH,用户ID(m),更新增量H

1.用户ID(m)→Alias(ID(m))→Lm→εm

3.构造D0的矩阵A
4. 找到A中出现任意两项出现次数最多对应的项集Mmax[i,j]
5.Q1=Mmax[i,j]
6. 在i,j所在行找出次数最小的项集Mmin[t,s]
7. 在t,s所在行找到最大的项集Mmax[a,b]
8.Q2=Mmax[a,b]
9.迭代上述步骤对于Q1,Q2
//**构造D0的分类树C-Tree(0)
10.对D1,D2,…,DH做下列步骤
11.V=D0,D1,D2,…,DH
12.G=Di中的所有记录
13.g→cut=C-Tree(0)的根结点

15. 将G添加到C-Tree(i-1)的根结点
16. 对G中的记录gi做下列步骤
17. IFgi不为空且不是叶子结点
按照C-Tree(i-1)的分类方法分配此节点


20.V=gi∪V
21. IFgi不为空或gi分配到叶子结点
22. 分割该节点,执行18至20步
23. ELSE IFgi为空
24. 则返回16步
25.返回C-Tree(i)
//**分配Di中的所有记录
26.发布融合后的C-Tree(i)中叶子结点的信息

3.5 算法隐私保护效果分析
1)数据的分级融合满足差分隐私
通过Laplace机制添加噪声实现了数据敏感属性隐私保护,使用假名机制有效地保护了用户的身份隐私,将用户访问权限、付费情况或对于数据使用的不同需求,进行等级划分,并与隐私预算εm关联实现数据分级融合,根据差分隐私的串行性质,分级融合机制满足εm-差分隐私.实现融合数据个性化的隐私保护程度,分级融合数据发布机制使得查询输出结果可控.
2)分级融合发布机制满足差分隐私
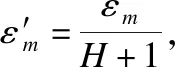
3.6 正确性与复杂性分析
正确性:
1)对于数据信息需求而言,基于差分隐私的数据融合方法融合后的数据具有可靠的利用率,可以实现决策分析等操作工作;
2)对于数据隐私而言,使用差分隐私保护方法能够弥补K-匿名不能抵制背景知识攻击的缺点,而且不会导致隐私预算耗尽等问题.
复杂性:算法主要花费表现在以下两个方面:
1)构造分类树.选出数据集出现一次的记录,根据此记录中任意两项出现的次数,选择两项作为第一个分支,然后选出的次数出现最少的两项,选择在其所在行中的最大的值作为第二个分支,依次迭代地选取其它项集与这两个分支组合,直至所有的项集被选出,在此过程中,需要根据任意两项出现的次数生成关系矩阵,遍历整个数据集.
2)数据融合隐私预算分配.当新的数据集Di进行融合时,Di中的记录被插入到C-Tree(i-1)的根结点中,迭代地分配到不同的分支中,并且重新分配隐私预算.在此过程中需要根据分类树将融合的数据记录划分为单个子分割.
其中,构造初始分类树的时间复杂度为O(|L|·|I|),|L|表示初始数据集的长度,数据融合的时间复杂度为O(N·|D|·|I|),N表示融合数据集个数,|D|表示融合数据集长度.
4 实验分析
4.1 实验参数设置
本文设计的算法由Java语言和MyEclipse集成开发软件开发实现.实验硬件环境为Inter(R)Core I3 4510CPU 3.5GHz处理器,内存16G;操作系统为Windows 7.在实验数据方面,采用从Http://ipums.org下载的Income数据集,该数据集包含Age、Education、Gender、Birthplace、Work-class、Occupation、Income、Race、Marital status等8个属性,其中Income为敏感属性,该数据集的8个属性全部为数值型数据.
4.2 实验数据分析
图4反映了隐私预算参数ε与采用拉普拉斯机制实现隐私保护的查询结果错误率的对应关系.
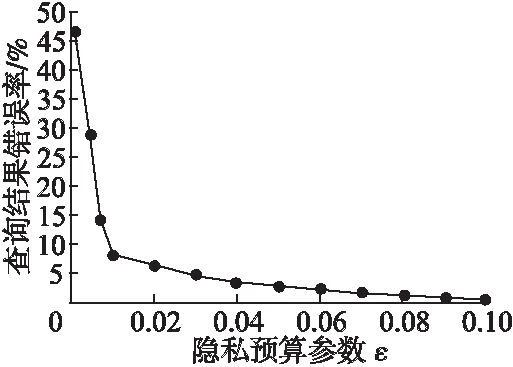
图4 隐私参数与查询结果错误率的对应关系Fig.4 Relationship between privacy parameters and the error rate of query results
对于用户等级的划分标准,可依据发布数据错误率来衡量.若数据使用者期望得到查询结果错误率小于 1%的数据,则取ε=0.1;若期望查询结果错误率在10%~20%之间的数据,则取ε=0.005.由此可见,可以把ε取自集合(0.001,0.1),按照ε的取值大小来对应划分用户等级.
实验主要测试针对不同的差分隐私预算参数ε,不同数量的属性,不用数量的数据表,完成数据融合所花费的时间和得到融合发布记录的分类精度.
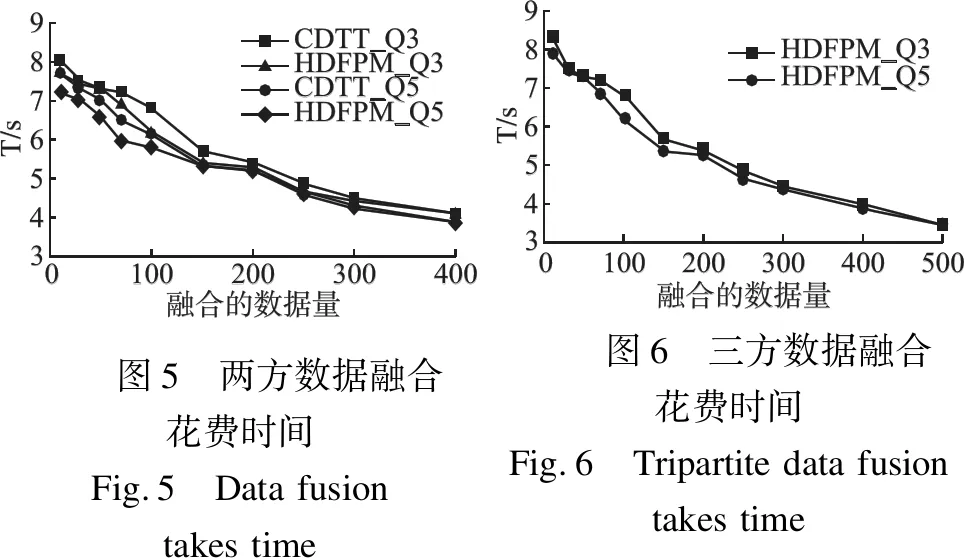
98765430100200300400融合的数据量Ts/CDTTQ3_HDFPMQ3_CDTTQ5_HDFPMQ5_图5 两方数据融合花费时间Fig.5 Datafusiontakestime98765430100200300400500融合的数据量Ts/HDFPMQ3_HDFPMQ5_图6 三方数据融合花费时间Fig.6 Tripartitedatafusiontakestime
为了与CDTT算法[7]的性能进行比较,实验中取ε=0.005,数据集记录数为10k~400k,比较二者花费时间.图5为Income数据集分为两方数据,比较HDFPM算法与CDTT算法进行数据融合时花费的时间,Qi表示融合记录的属性数量.从图5中可以看出,在相同的隐私预算参数ε和相同的Qi下,HDFPM算法进行数据融合所花费时间比CDTT算法花费更少.
图6为HDFPM算法在属性不同情况下,三方数据融合所花费的时间.从图6中可以看出,融合同一大小的数据记录数,属性增加时,花费时间会增加;随着数据记录数的增加,二者花费时间基本相同.
实验中分别取ε=0.05、ε=0.5、ε=1.0满足来分级条件,Qi=5,以此进行实验,对比提出算法HDFPM与CDTT算法、DiffGen-Max算法融合后数据分类的精确度.图7为不同ε下三种算法的分类精度图.
从图7中可以看出,当ε值较小时,即用户等级较低,三种算法分类精度基本一致,但随着隐私预算参数的增加,即用户等级的增大,HDFPM算法算法相比于CDTT算法、DiffGen-Max算法分类精度相对更高,数据质量相对更好.

图7 不同ε时分类精度Fig.7 Classification accuracy at different ε
5 结束语
本文提出的基于差分隐私的数据分级融合发布机制,在数据融合发布过程中,保持了融合后数据的可用性,同时保护了数据中的敏感信息.本文方法与基于K-匿名系列方法相比,在融合的过程中,主要有三处改进:第一点是将数据融合与差分隐私保护结合,把差分隐私技术引用到数据融合中,使得融合发布后的数据更具安全性;第二点采用分级方法,使得融合后的数据对于隐私保护程度更具针对性;第三点提出的基于分类树的隐私预算方法能够更合理地分配隐私预算,避免隐私预算的过早耗尽.实验表明,本文算法既能在一定程度上减少花费时间实现数据的分级融合,又能保持数据的可用性且能够有效的保护敏感数据的隐私性.未来将继续研究差分隐私保护在数据融合发布中的应用.
