约束覆盖导向的Web服务测试数据生成
2019-11-11程浩,周辉,钱巨
程 浩,周 辉,钱 巨
(南京航空航天大学 计算机科学与技术学院,南京 211106)E-mail:jqian@nuaa.edu.cn
1 引 言
Web服务是一种通过网络支持可互操作的端到端交互的软件系统(1)http://www.w3.org/TR/ws-gloss.Web服务因其所具有的高通用性、可互操作性与可重用性而受到广泛关注.与其他软件系统不同,Web服务使用了基于XML的WSDL标准文档来描述服务接口,包括服务功能、输入和输出,对外隐藏了复杂业务逻辑的实现.
Web服务与其他软件系统一样,也存在质量问题,而且由于Web服务广泛用于各种应用,尤其是电子商务应用,问题可能会更严重.为此,研究人员为Web服务的测试技术付出了很多努力[1],在测试数据生成[2,3]、单元测试[4,5]、测试预言[6]、故障注入技术[7]、回归测试[8]、安全测试[9]等方面的研究也取得了很多重要成果,但是挑战依然存在.
Web服务测试的挑战之一是生成高覆盖率的测试数据.人们[1]提出了多种测试数据生成方法,包括基于 XML Schema、基于模型、基于规约等方法,其中,基于 XML Schema 的方法根据 WSDL 文档提供的数据类型信息生成测试数据,基于模型的方法通过构建服务内部的行为模型(如自动机)来生成测试数据[10],基于规约的方法一般根据 Web 服务输入和输出的前置与后置条件来生成测试数据[11].相较而言,基于 XML Schema 的方法快而简单,但只是根据粗粒度的数据类型信息生成数据,因此无法确保能够生成有意义的代表性测试数据.基于模型的方法主要适用于 BPEL 组合服务,对于原子服务来说该方法显得过于复杂.与上述两种方法相比,基于规约的测试数据生成方法不仅能够生成更合理的服务输入,而且在为原子服务生成测试数据时通常要比基于模型的方法更高效.
对于原子服务,文献[12]提出了一种基于规约的Web服务测试数据生成方法,先用简单的取值范围约束(如(a≥0∧a≤10)∧(b≥0∧b≤10))来指定服务的输入条件,再基于区间划分技术生成测试数据,测试数据是通过选取每个输入参数的数据分区中的值组合得到的,但该方法并不支持不同服务输入参数之间的复杂约束,如a+b 在更广泛的测试数据生成研究领域中[15,16],还有一些根据规约约束生成测试数据的黑盒方法,但大多数只关注如何求解约束,并未解决如何操纵约束以生成高覆盖率测试数据的问题[17],而且很少有研究方法能够定义明确的规约约束级测试覆盖准则,并利用这些准则指导约束求解以生成测试数据. 考虑到上述问题,本文提出了一种基于规约约束的测试数据生成方法,用一阶逻辑公式定义服务输入和输出的规约约束,能够根据给定的规约约束生成高覆盖的测试数据.本方法的重点是测试原子服务,并支持复杂的一阶逻辑约束,如(3*a+12)*2<100,以及描述变量间关联关系的约束,如x+y>z.本文使用Z3 SMT约束求解器生成测试数据,而且为了生成高覆盖率的测试数据,引入几种规约约束级覆盖准则,并提出生成满足这些准则的测试数据的新算法.实验通过测试两个目标服务得到的结果表明,使用新的测试覆盖准则与相应的测试数据生成算法,可以实现更高的代码覆盖率,因此本文提出的方法能够提高Web服务测试数据的质量. 一个Web服务包含服务实现和服务接口描述,后者通常是由 WSDL 文档表达.WSDL 文档内容由抽象类型定义和部署描述两部分组成.抽象类型定义包括 types、message、portType 等 XML 元素,其中 types 元素描述了该服务中使用的数据类型,可以是简单数据类型如整型、字符串等,也可以是类似于 C 语言结构体的复杂类型;message 元素描述了服务的输入和输出;portType 元素定义了服务支持的操作,操作就像是面向对象语言中类的一个方法.部署描述定义了服务的 URL 和调用服务的协议.这些元素中,types 元素是测试数据生成的关键. 图1是描述Web服务Sum的WSDL文档,Sum服务有一个sum操作,由 在基于规约的原子Web服务测试中,每个测试目标由一个三元组表示: F= 其中S表示待测的原子Web服务,O是服务S中可被调用的操作,C是由服务S中若干前置条件和后置条件组成的约束系统.前置条件定义了服务输入应满足的约束,用于生成Web服务的测试数据,后置条件则定义了服务输出应满足的约束,用于检查测试数据的执行结果. 图1 WSDL文档示例 为了表达Web服务中输入和输出参数之间的关联关系,本文拟采用一阶逻辑公式定义约束,并基于SMT(Satisfiability Modulo Theories,可满足性模理论)约束求解器[18]生成测试数据.SMT 约束求解器用于查找满足一阶逻辑公式的一组数据,被广泛用于软件验证、测试用例生成等方面. Z3是微软发布的一款 SMT 约束求解器[19],支持各种复杂的理论公式,包括算术表达式、布尔表达式、逻辑表达式等.本文将基于Z3约束求解器生成 Web 服务测试数据. 但是直接使用Z3求解约束得到的测试数据无法保证能够覆盖所有的输入方案,例如,对于以下约束: a>20∨b<10∨a>b, 使用Z3求解可以得到一个有效的测试数据(a=15,b=12),该数据只覆盖了条件子句a>b,未覆盖a>20和b<10,这种低覆盖率的测试数据会影响Web服务故障的发现. 为了解决以上问题,本文提出了一种基于一阶逻辑公式规约和Z3约束求解器的高覆盖率测试数据生成方法,如图2所示. 图2 测试数据生成过程Fig.2 Test data generation process 方法的输入包括待测Web服务的WSDL文档、服务对应的前置条件约束以及选定的覆盖准则,方法的输出是一个满足输入覆盖准则的测试集.测试数据生成的过程包括两个主要步骤:1)根据覆盖准则进行约束转换;2)基于Z3 SMT约束求解器的测试数据生成.生成的测试数据将被封装于SOAP包中用于 Web 服务测试.表1给出了测试数据生成的一个实例,其中最后一列的测试数据是根据第一列中给定的前置条件生成的.本文主要关注整数类型的变量. 表1 测试数据生成示例Table 1 An example for test data generation Web服务的测试规约由前置条件和后置条件给定,它们都是用一阶逻辑公式表达的约束,而且是 SMT 求解器可求解的.与传统范围约束(如a<10)只能限定单个变量不同,一阶逻辑公式约束能够定义不同变量之间的关联关系,例如,a=b或a+b<10 等描述的复杂关系. 规约语言的语法如图3所示,其中 Variable,Value分别表示约束变量与常数值,expr,bexpr 分别是算术表达式和布尔表达式,constraint 表示约束中的逻辑公式. 图3 规约语法Fig.3 Grammar of the specification language 规约语法中的约束变量对应于服务操作的输入或输出参数,例如,对于图1中的 Sum 服务,参数a可以表示为: value(svc/sum/a), 其中,svc是给定服务的宏定义,svc/sum表示Sum服务支持的操作sum.假定Sum服务的输入参数必须满足都相等或者都不相等,对应的规约如图4所示.规约可以保存在独立的文件中,也可以集成到XML文档中.规约提供了更多服务操作的输入空间信息,通过全面探索输入空间可以获得更高覆盖率的测试数据. 图4 规约示例Fig.4 An example specification 目前 WSDL 规范支持一种限定(restriction)机制,以限制服务输入和输出的取值,常用的限定类型包括范围限定和枚举限定.范围限定用于限制变量的最大或最小值,图5(a) 表示参数a的取值范围是[0,10].枚举限定给出了变量的有效取值集合,图5(b) 限定参数b只能取0或1. 除上述两种限定之外,还有其他更为复杂的限定在本文中没有用到.为了生成合理的测试数据,WSDL 描述中的这些限定将被转换成逻辑约束,并加到约束系统中.结合图4和图5可得,Sum 服务中 sum 操作完整的前置条件如下: Csum=(a≥0∧a≤10)∧(b=0∨b=1)∧ ((a≠b∧b≠c)∨(a=b∧b=c)), 本文将使用该约束生成测试数据. 为了对给定的Web服务生成充足的测试数据,本文定义了几种规约约束级测试覆盖准则,涵盖了更多基于规约约束的情形,基于这些准则进行测试可以为指定服务测试更多的输入方案.规约约束级测试覆盖准则包括判定覆盖、条件覆盖、判定条件覆盖、范式子句覆盖,这些准则借鉴了白盒测试中代码级覆盖的部分概念. 在白盒测试中,判定覆盖要求测试用例能够覆盖每个判定中真或假的结果.在基于规约约束的测试中,判定覆盖则要求测试数据不仅要满足规约约束(有效数据),还要满足约束的否定形式(无效数据). 定义1.(判定覆盖) 对于给定前置条件C的服务,如果测试集T满足以下条件: ∃t∈T,eval(C,t)=true∧∃t′∈T,eval(C,t′)=false, 就称测试集T满足判定覆盖,其中eval(C,t) 用于判断测试数据t是否满足约束C. 对于3.2节给出的规约约束Csum,测试集Tdc(a,b,c)={(1,1,1),(20,1,1)} 覆盖了有效数据和无效数据,因此该测试集满足判定覆盖. 判定覆盖无法保证给定的测试集能够覆盖所有产生有效测试数据或者无效数据的不同情形.例如,Tdc没有覆盖b=0的情况.一种提高覆盖率的途径是要求测试集能覆盖每个基本条件的不同结果.在白盒测试中,这种覆盖叫做条件覆盖,本文将其引入到规约约束级覆盖准则中.在基于规约约束的测试中,条件覆盖要求测试数据不仅要满足服务参数前置条件中的原子条件,还要满足各原子条件的否定形式. 定义2.(条件覆盖) 对于给定前置条件C的服务,如果测试集T满足以下条件: ∀e∈BExpr(C){∃t∈T,eval(e,t)=true 就称测试集T满足判定覆盖,其中BExpr(C)是前置条件C中原子条件的集合. 对于3.2节给出的规约约束Csum,测试集Tcc(a,b,c)={(1,1,1),(-1,0,-1),(20,0,20)} 能保证覆盖所有的原子条件及各自的否定形式,因此该测试集满足条件覆盖. 对于(a>b∨c>d)类似的约束,覆盖每个原子条件的不同结果并不能保证覆盖整个约束真或假的结果.为此,本文定义了规约约束级的判定条件覆盖准则.在基于规约约束的测试中,判定条件覆盖要求为给定前置条件的Web服务生成的测试数据不仅要满足判定覆盖,还要满足条件覆盖. 定义3.(判定条件覆盖) 对于给定前置条件C的服务,如果测试集T满足以下条件: ∃t∈T,eval(C,t)=true∧∃t′∈T,eval(C,t′)=false 就称测试集T满足判定条件覆盖. 对于3.2节给出的规约约束Csum,4.2节中的测试集Tcc符合上述定义,因此该测试集满足判定条件覆盖. 对于规约约束,当测试数据有效时析取范式(DNF)会有不同的情况,当测试数据无效时合取范式的否定则会有不同的情况.这些情况常对应于 Web 服务的不同行为,因此应更好地被测试集覆盖.然而条件覆盖和判定条件覆盖都不能保证这些情况都能被覆盖.例如,测试集Tcc虽然覆盖了b=0和b=1的情况,但是并未覆盖b的取值不在集合{0,1}中的情况. 为此,本文介绍一种范式子句覆盖准则,要求测试数据不仅要满足前置条件中析取范式的每个子句,还要满足合取范式中每个子句的否定.这样一来,产生有效数据或无效数据的不同情形都能被覆盖到. 定义4.(范式子句覆盖)对于给定前置条件C的服务,如果测试集T满足以下条件: ∀f∈DNF(C),∃t∈T,eval(f,t)=true 就称测试集T满足范式子句覆盖,其中DNF(C)、CNF(C) 分别是前置条件C中析取范式子句、合取范式子句的集合. 对于3.2节给出的规约约束Csum,析取范式子句有: (a≥0∧a≤10)∧(b=0)∧(a≠b∧b≠c), (a≥0∧a≤10)∧(b=0)∧(a=b∧b=c), (a≥0∧a≤10)∧(b=1)∧(a≠b∧b≠c), (a≥0∧a≤10)∧(b=1)∧(a=b∧b=c), 合取范式包括: a≥0,a≤10,(b=0∨b=1),(a≠b∨a=b), (b≠c∨a=b),(a≠b∨b=c),(b≠c∨b=c). 根据这些子句生成的测试集Tnfcc(a,b,c)={(1,0,2),(0,0,0),(0,1,2),(1,1,1),((1,0,2),(11,0,2),(1,2,2),(1,1,0),(0,1,1)} 满足范式子句覆盖. 设Z3是根据给定约束生成有效随机数据的函数,本节将基于Z3函数介绍满足不同测试覆盖准则的测试数据生成算法. 对于给定前置条件C的服务,通过将Z3函数作用于条件C及其否定形式C,可以生成满足判定覆盖的测试集T: T={Z3(C),Z3(C)}. 对于3.2节给出的规约,满足判定覆盖的测试集可通过将Csum代入上式得到: Tdc(a,b,c)={(1,1,1),(20,1,1)}. 对于给定前置条件C的服务,其中C的原子条件集合为BExpr(C),若要生成满足条件覆盖的测试集,则要求数据集同时满足BExpr(C)中的每个条件e及其否定形式e.由于满足条件e的测试数据也可能满足其他条件,因此根据每个条件直接生成对应的数据会带来冗余,为此,本文使用算法1所示的工作队列算法来生成整个测试集. 算法1.满足条件覆盖的测试数据生成算法 Input:C:规约约束 Output:T:测试集 Begin E=BExpr(C)∪ {e|e∈BExpr(C)}; whileE≠Ødo removeeifromE; t:=Z3(ei∧C); ift≠ nullthenT:=T∪ {t}; else t:=Z3(ei∧C); ift≠ nullthenT:=T∪ {t};end end foreachek∈Edo ifeval(ek,t)==truethen E:=E-{ek}; end end end returnT; End 算法首先创建包含所有需要覆盖的条件的工作队列E,然后根据E中的每个条件ei使用Z3生成对应的服务输入t.为了生成合理的完整输入,需要先将ei和前置条件C(或其否定形式C)进行逻辑与操作,再用Z3 求解得到输入数据t,此时从工作队列E中删除ei,而且t满足的其他条件也要删除.当工作队列E为空时算法终止. 对于3.2节给出的规约约束Csum,首先创建工作队列E={e1=(a≥0),e2=(a≤10),e3=(b=0),e4=(b=1),e5=(a≠b),e6=(b≠c),e7=(a=b),e8=(b=c),e1,e2,e3,e4,e5,e6,e7,e8},然后根据条件e1使用Z32http://axis.apache.org/axis2/java/core 生成服务输入t1=(1,1,1),t1也满足条件e2,e4,e7,e8,e3,e5以及e6,因此将这些条件从E中删除,得到E={e3,e5,e6,e1,e2,e4,e7,e8}.接下来根据条件e3使用Z3生成另一个服务输入t2=(-1,0,-1),t2也满足条件e5,e6,e1,e4,e7以及e8,将这些条件从工作队列中删除后得到E={e2}.最后使用Z3求解到服务输入(20,0,20),算法终止.最终的测试数据集合为Tcc(a,b,c)={(1,1,1),(-1,0,-1),(20,0,20)}. 对于给定前置条件C的服务,要生成满足判定条件覆盖的测试集,可以先生成满足条件覆盖的测试数据集,再向其中加入必要的测试数据以确保满足判定覆盖.详细的测试数据生成算法如算法2所示.算法首先调用CC(C)生成满足BExpr(C) 中的每个条件e及其否定形式e的测试数据集,然后判断该数据集是否同时满足条件C及其否定形式C,若不满足条件C,则根据条件C使用Z3生成服务输入;若不满足条件C,则根据条件C使用Z3生成对应的服务输入. 算法2.满足判定条件覆盖的测试数据生成算法 Input:C:规约约束 Output:T:测试集 Begin T:=CC(C); B:=Ø; foreacht∈TdoB:=B∪ {eval(C,t) };end iftrue∉BthenT:=T∪Z3(C); elseiffalse∉BthenT:=T∪Z3(C); end returnT; End 对于3.2节给出的规约约束Csum,算法首先使用CC(C)得到满足条件覆盖的测试集Tdcc={(1,1,1),(-1,0,-1),(20,0,20)},Tdcc同时满足条件C及其否定形式C,因此Tdcc满足判定条件覆盖,无需生成额外的输入以满足判定覆盖. 对于给定前置条件C的服务,其中C的析取范式子句集合、合取范式子句集合分别为DNF(C)、CNF(C),为了生成满足范式子句覆盖的测试集,需要生成包括满足DNF(C)中每个子句的数据,以及不满足CNF(C)中每个子句的数据,具体过程如算法3所示. 算法3.满足范式子句覆盖的测试数据生成算法 Input:C:规约约束 Output:T:测试集 Begin F=DNF(C)∪{e|e∈CNF(C)}; foreache∈Fdo t:=Z3(e); T:=T∪{t}; end returnT; End 对于3.2节给出的规约约束Csum,算法首先得到需要覆盖的9个范式子句,由4.4节中给出,然后使用Z3 为每个子句生成相应的服务输入,最终的数据集为4.4节中的Tnfcc. 为了验证本方法的有效性,我们实现了该方法并在两个 Web 服务上对其进行测试,以回答以下的研究问题: 问题1.本文提出的测试覆盖准则在缺陷检测方面的表现如何? 实验并未为服务注入故障,主要通过检查这些测试覆盖准则是否可以带来更高的代码级覆盖率来回答这个问题. 问题2.本文中的测试数据生成算法能否用更少的测试数据来满足文中提出的测试覆盖准则? 问题3.测试数据生成算法的效率如何? 实验用本文提出的方法分别测试了两个典型的Web服务:Triangle与MiddleNumber[12,20,21],这些服务的变体广泛用于软件测试研究中.Triangle服务根据输入三角形的三条边长a,b,c判断该三角形是一般三角形、等腰三角形还是等边三角形,MiddleNumber服务根据输入的三个数i,j,k判断k是否为介于i和j之间的中间数字.实验用Java实现这些服务,并将它们部署在Axis2容器2中,测试数据生成算法也用Java实现,实验用Java版的Z3进行约束求解. 为了生成测试数据,实验为两个服务定义了前置条件.实验对本文提出的测试数据生成算法与现有方法进行代码覆盖率和效率的比较,以说明本方法的有效性. Triangle服务的前置条件如下: CT=C1∧C2, C1=(a>0)∧(b>0)∧(c>0)∧(a<100) ∧(b<100)∧(c<100)∧(a+b>c) ∧(b+c>a)∧(a+c>b), C2=((a=b∧a≠c)∨(b=c∧b≠a)∨(a=c∧a≠b)) ∨(a=b∧b=c)∨(a≠b∧a≠c∧c≠b)). 其中,条件C1对边长的范围做出限制以形成一个有效的三角形,条件C2列举了所有可能的三角形类型的条件,以覆盖更多的输入情况. MiddleNumber服务的前置条件如下: CM=(i>0)∧(j>0)∧(k>0) ∧(i<100)∧(j<100)∧(k<100) ∧((k>i)∧(k 该条件对输入参数的值进行范围限制,并要求k介于i和j之间. 表2列出了Triangle和MiddleNumber服务的前置条件约束,其中文献[12]提出的测试生成方法(本文称其为MATDG)并不支持变量之间的关联约束,表中的约束是简化后得到的. 问题1.本文提出的测试覆盖准则在缺陷检测方面的表现如何? 实验通过比较MATDG[12]、随机方法以及本文所提方法的代码级语句覆盖率和分支覆盖率来回答这个问题:代码覆盖率越高,缺陷检测能力越好. 实验分别对Triangle和MiddleNumber服务进行测试,实验结果如表3所列,其中SC%、BC%分别表示语句覆盖率和分支覆盖率,CN是不同方法生成的测试数据数量,Avg是每种方法对应统计项的均值. 对于MATDG方法,实验在两种典型配置下生成测试数据<0,1>与<1,1>(配置 表2 Web服务的规约约束Table 2 Specification constraints of Web services 表3 生成测试数据的语句覆盖率(SC)和分支覆盖率(BC)Table 3 Generated test data and their statement coverage(SC) and branch coverage(BC) rates 图6 比较三种方法的语句覆盖率和分支覆盖率Fig.6 Comparison of the three evaluated approaches in source code level statement and branch coverages 然而,有些语句和分支仍未覆盖到,这是因为使用有限数量的测试用例很难覆盖所有的条件组合,满足范式子句覆盖的测试用例覆盖了最多的分支和语句,尤其是正常计算代码的覆盖方面. 问题2.本文中的测试数据生成算法能否用更少的测试数据来满足文中提出的测试覆盖准则? 实验通过比较达到相同规约约束级覆盖率时随机方法生成的测试用例数量与本文所提方法生成的测试用例数量来回答这个问题:数量越少,效果越好. 表4列出了满足四种规约约束级覆盖准则所需的测试用例数量,可以看出,基于规约约束的方法只要使用少许几个测试用例就能满足规约约束级覆盖准则,而随机方法需要数百个用例才能达到相同的覆盖率,因此基于 Z3 的算法在给定覆盖准则下可以更为有效地生成低冗余的测试用例. 问题3.测试数据生成算法的效率如何? 图7 生成测试数据的时间Fig.7 Time spent on test data generation 实验通过收集生成分别满足四个规约约束级覆盖标准的测试数据所花费的时间来说明测试数据生成算法的效率.图7给出了为Triangle 服务和 MiddleNumber 服务生成测试数据时所花费的时间,可以看出,生成满足判定覆盖(DC)的测试数据所花时间最少,生成满足范式子句覆盖(NFCC)的测试数据所花时间稍多一点,而生成满足条件覆盖(CC)和判定条件覆盖(DCC)的测试数据需要花费更多的时间.结合表3中的语句和分支覆盖率可以得到以下结论:使用范式子句覆盖准则生成的测试数据更有效,而且效率更高. 表4 达到不同规约约束级覆盖率时的测试用例数量Table 4 Test cases needed to achieve coverages at the different level of specification constraints 本文提出了一种基于规约约束的 Web 服务测试数据生成方法,该方法中使用的规约约束系统不仅支持简单的服务输入取值范围约束,而且还支持服务输入参数之间的复杂关联约束.本文还提出了四种规约约束级覆盖准则——判定覆盖、条件覆盖、判定条件覆盖以及范式子句覆盖.利用这些覆盖准则,可以通过 Z3 SMT 求解器产生高覆盖率的测试数据,从而更好地揭示服务中的缺陷.本文的研究仍然存在一些不足,首先,实验论证还有待在更大规模、更复杂 Web 服务上做进一步加强,另外,尽管本文的方法已经能够达到较高测试覆盖率,但仍有进一步提升的空间.为此,未来将开展更多实验研究,为方法的应用提供更多参考.同时,计划不断研究新的覆盖准则,如结构化测试中的修正条件判定覆盖准则(MC/DC)[22]等,以完善所提出的方法.2 背 景
2.1 Web服务
2.2 基于规约的 Web 服务测试

Fig.1 An example WSDL document2.3 基于 SMT 约束求解器的测试数据生成
3 基于Z3的测试数据生成方法概述
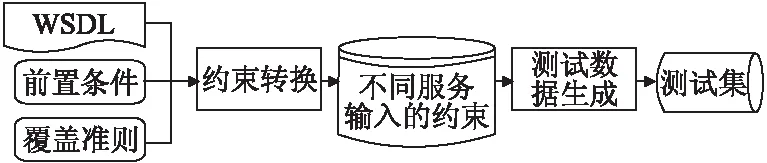

3.1 Web 服务规约语言


3.2 WSDL 描述中的限定

4 基于规约约束的测试覆盖准则
4.1 判定覆盖
4.2 条件覆盖
∧∃t′∈T,eval(e,t′)=false},4.3 判定条件覆盖
∧∀e∈BExpr(C){∃t∈T,eval(e,t)=true
∧∃t′∈T,eval(e,t′)=false},4.4 范式子句覆盖
∧∀f∈CNF(C),∃t′∈T,eval(f,t′)=false,5 测试数据生成算法
5.1 满足判定覆盖的测试数据生成算法
5.2 满足条件覆盖的测试数据生成算法
5.3 满足判定条件覆盖的测试数据生成算法
5.4 满足范式子句覆盖的测试数据生成算法
6 实 验
6.1 实验设置
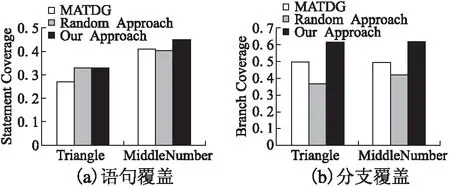
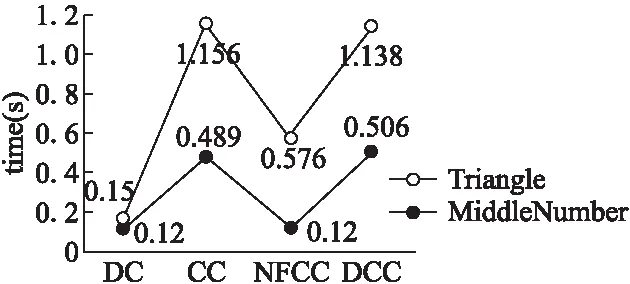
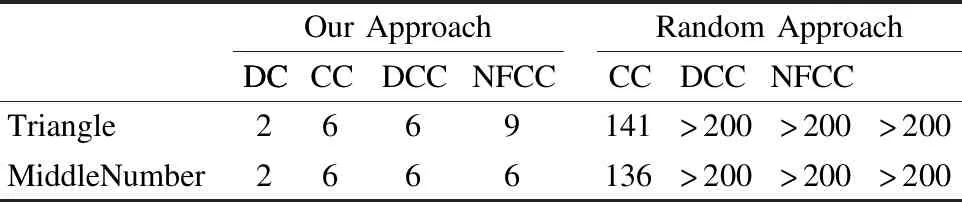
6.2 实验结果


7 结束语
