基于文件粒度的多目标软件缺陷预测方法实证研究∗
2019-10-26赵英全
陈 翔 , 赵英全 , 顾 庆 , 倪 超 , 王 赞
1(南通大学 信息科学技术学院,江苏 南通 226019)
2(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
3(广西可信软件重点实验室(桂林电子科技大学),广西 桂林 541004)
4(天津大学 软件学院,天津 300072)
软件产品在软件开发生命周期内(例如需求分析、软件设计和软件实现)都存在引入缺陷的可能性,而含有缺陷的软件产品在部署上线后可能会产生预期之外的行为,在严重的时候甚至会给企业带来巨额经济损失或威胁到产品用户的生命安全.已有的项目管理经验表明:在软件开发生命周期中,检测出项目内缺陷的时间越晚,修复该缺陷的代价也越高并且修复代价呈指数级增长,因此,测试人员希望能够在软件部署上线前尽可能早地预先识别出所有的缺陷程序模块,并对这些缺陷模块投入更多的软件测试资源(即针对这些缺陷模块设计更为充分的测试用例或展开更多的代码审查工作等)[1].软件缺陷预测(software defect prediction)[1−3]是可以预先识别出缺陷程序模块的一种静态分析方法,其通过挖掘和分析软件库(例如项目托管的缺陷跟踪系统和版本控制系统),可以训练出缺陷预测模型,并以此来提前识别出被测项目内的缺陷程序模块.因此该方法可以有效优化测试资源的分配,从而有助于提高最终部署上线的软件产品的质量.
在实际软件测试时,可以使用的测试资源是有限的,因此很难保障对被测项目内的所有程序模块进行充分的软件测试,因此软件质量保障团队希望构建出一个模型,其能够将被测项目内的所有程序模块,按照模块含有缺陷的概率,从高到低进行排序.随后开发人员可以根据该排序列表依次完成对程序模块的代码审查或者软件测试.这样,在测试资源存在约束的时候,软件质量保障团队可以完成对更多缺陷的检测和修复.在上述测试场景中,研究人员常用代价感知(effort-aware)的评测指标对模型性能进行评估.基于代价感知的评测指标,有监督学习方法与无监督学习方法之间的性能比较是最近一个具有争议性的问题.在基于代码修改的软件缺陷预测(change-level software defect prediction,简称CL-SDP)问题中,Yang等人惊奇地发现:存在一些无监督学习方法,其预测性能要显著优于已有的经典有监督学习方法[4].随后,Fu等人[5]以及Huang等人[6]对Yang等人的研究工作[4]进行了重现,并得出了一些新的发现.我们关注了基于多目标优化的有监督学习方法MULTI,并在跨项目缺陷预测(cross-project defect prediction)场景、同项目缺陷预测(within-project defect prediction)场景和基于时序的缺陷预测场景下,深入分析了MULTI方法与Yang等人考虑的无监督学习方法和有监督学习方法之间的性能差异.结果表明,MULTI方法在这3个场景下均能取得更好的预测性能,从而说明有监督学习方法仍然值得研究人员进行关注[7].
与CL-SDP问题不同,基于文件粒度(在面向对象程序实现的项目中,文件粒度也可以被称为类粒度)的软件缺陷预测(file-level software defect prediction,简称FL-SDP)问题将模块粒度设置为文件,因此模块内含有的代码行数更多,考虑的度量元也并不相同.最近,Yan等人[8]针对FL-SDP问题,对Yang等人考虑的无监督学习方法和有监督学习方法进行了深入比较,并得到了相似的结论.但据我们所知:针对FL-SDP问题,在基于代价感知的评测指标下,并没有研究人员将基于多目标优化的MULTI方法[7]与Yan等人考虑的有监督学习方法和无监督学习方法的性能进行深入分析和比较.因此,我们针对上述问题设计并开展了大规模实证研究.基于代价感知的评测指标(例如ACC和POPT),我们发现MULTI方法在同项目缺陷预测场景和跨项目缺陷预测场景下均要显著优于Yan等人考虑的无监督学习方法、有监督学习方法以及最新提出的OneWay方法[5]和CBS方法[6].基于Huang等人提出的PMI和IFA评测指标[6],我们发现MULTI方法与代价感知的指标相比存在一定的折衷,但仍好于在ACC和POPT评测指标下表现最好的两种无监督学习方法.除此之外,基于F1评测指标的结果也进一步验证了MULTI方法的优越性.同时,通过分析模型构建的时间开销,我们认为MULTI方法在模型训练上花费的计算开销处于开发人员可以接受的范围之内.
本文的主要贡献可以简要总结如下:
(1) 我们基于代价感知的评测指标,深入分析了基于多目标优化的MULTI方法在基于文件粒度的缺陷预测问题上的预测性能.
(2) 本文在实证研究中考虑了10个开源项目,在模型性能评估上考虑了同项目缺陷预测场景和跨项目缺陷预测场景.通过将MULTI方法与Yan等人考虑的无监督学习方法和有监督学习方法[8]、Wu和Menzies提出的OneWay方法[5]以及Huang等人提出的CBS方法[6]进行比较,发现MULTI方法在预测性能上均具有显著性优势,从而表明MULTI方法在FL-SDP问题上同样具有优势并值得关注.
本文第1节介绍软件缺陷研究背景,以及无监督学习方法和有监督学习方法在缺陷预测问题上的已有研究成果.第2节深入分析本文重点考察的基于多目标优化的MULTI方法以及Yan等人考虑的有监督学习方法和无监督学习方法.第3节给出本文的实验设计,包括本文考虑的评测对象、评测指标、模型性能评估场景、实验流程以及结果分析时使用的显著性检验方法等.第4节分别针对实证研究结果和有效性影响因素进行了深入分析.第5节总结全文,同时针对未来值得关注的多个研究点进行了展望.
1 软件缺陷研究背景和相关工作
1.1 研究背景
软件缺陷预测[1−3]通过分析和挖掘软件库(例如项目托管的缺陷跟踪系统和版本控制系统),训练出缺陷预测模型,并使用训练出的模型来提前识别出被测项目内的缺陷程序模块,随后开发人员可以针对这些识别出的缺陷程序模块展开更为充分的软件测试或投入更多的代码审查工作量,借助这种方式可以优化测试资源的分配并且有助于提高部署上线的软件产品质量.具体来说,首先可以通过分析软件模块的代码复杂度或软件开发过程中的特点,设计出与软件缺陷存在一定相关度的度量元(metrics)[9,10].其中,软件模块的代码复杂度可以通过分析代码行数(line of code)、Halstead科学度量、McCabe环路复杂度或CK度量元等进行度量,而软件开发过程的特点则可以通过分析模块间的控制/数据依赖性、代码修改的特征、开发人员的编程经验和领域熟悉程度以及项目团队的组织构架等[1]进行度量.随后,通过分析软件库,抽取出所有的程序模块(其模块粒度可以根据应用场景设置为代码修改、文件或类等),借助手工设计的度量元可以对这些抽取出的模块进行度量,随后通过分析代码修改、修改日志信息和相关缺陷报告[11]可以对这些模块进行标记(即将模块类型标记为有缺陷或者无缺陷).基于对模块的度量和类型标记可以构造出用于模型训练的数据集.最后,借助某一分类方法(例如神经网络、支持向量机、朴素贝叶斯或随机森林等[12])来构建出缺陷预测模型.
1.2 无监督学习方法与有监督学习方法间的性能比较
近年来,研究人员提出了大量的缺陷预测建模方法[1],无监督方法和有监督方法是软件缺陷预测研究中常见的两类方法.其中,大部分方法属于有监督学习方法,但这类方法需要基于已标记的训练数据集来构建模型,因此需要花费大量的人力和物力来完成标记数据集的搜集.而无监督学习方法则不需要搜集已标记的训练数据集,可以直接对测试集进行预测,因此可以缓解上述不足,并更容易与企业实际开发流程相结合.
在基于代码修改的软件缺陷预测问题(在一些文献中,该问题也被称为just-in-time软件缺陷预测[13−16])中,其具有模块粒度细、可以迅速找到缺陷相关开发人员等优点.Kamei等人[13]从代码修改的规模、目的、分散度、修改历史以及开发人员经验等角度对抽取出的代码修改进行度量,并提出了基于有监督的EALR(effort-aware linear regression)方法.Yang等人[4]基于代价感知的评测指标,在性能评估时意外地发现:存在一些简单的无监督方法,其比已有的有监督方法(包括Kamei等人提出的EALR方法[13])可以取得更好的性能.Fu等人[5]对Yang等人的实证研究进行了重现,他们发现:并不是所有的无监督方法的预测性能都可以显著优于有监督方法.因此,他们提出了OneWay方法,其可以自动选出更好的无监督学习方法.随后,Huang等人[6]发现:在给定相同的测试成本时,有监督学习方法需要审查更多的代码修改.Liu等人[17]则提出一种新的无监督学习方法CCUM(code churn based unsupervised method),该方法将代码修改涉及到的删除代码量和新增代码量相加,构成CHURN度量元,并根据该度量元完成对代码修改的排序.结果表明,CCUM方法[17]相比于Yang等人考虑的方法,可以取得更好的预测性能.
与CL-SDP问题不同,基于文件粒度的软件缺陷预测问题将模块粒度设置为文件,因此模块内含有的代码量更大.Yan等人在最近的一个研究工作中[8]针对FL-SDP问题,对Yang等人考虑的无监督学习方法和有监督学习方法的性能进行了比较和分析,并得到了相似的结论.
在我们之前针对CL-SDP的研究工作[7]中发现:基于多目标优化的方法MULTI在3种不同的场景(即同项目缺陷预测场景、跨项目缺陷预测场景和基于时序的缺陷预测场景)下,都要显著优于Yang等人考虑的有监督学习方法和无监督学习方法.基于上述研究工作,我们希望继续分析基于多目标优化的MULTI方法在FL-SDP问题中,其性能是否能够显著优于Yan等人考虑的有监督学习方法和无监督学习方法.
2 基于文件粒度的软件缺陷预测方法
该节首先简要分析本文考虑的基于多目标优化的MULTI方法,随后依次介绍需要与MULTI方法比较的基准方法[8],这些基准方法可分为两类:有监督学习方法和无监督学习方法.
2.1 基于多目标优化的MULTI方法
MULTI方法针对FL-SDP问题设置了两个不同的优化目标:其中第1个优化目标被设置为模型需要尽可能多地识别出缺陷模块数,第2个优化目标被设置为模型需要尽可能地减少代码审查工作量.不难看出,模型设置的这两个优化目标之间存在一定程度的折衷关系.即如果训练出的模型需要识别出更多的缺陷模块数,则需要投入更多的代码审查工作量;与此相反,若需要减少代码审查工作量,则训练出的模型有可能会遗漏掉一些缺陷模块[7].
本文借助Logistic回归方法来训练预测模型,假设程序模块用n个特征(即软件缺陷预测的度量元)进行度量,则预测模型的系数可以表示为一维向量w={w1,w2,…,wn}.给定预测模型的系数向量w和需要预测的程序模块mi,其中,程序模块mi的第j个特征取值用vi,j表示,则可以使用公式(1)计算出该程序模块包含缺陷的概率为

本文将FL-SDP问题建模为经典的二元分类问题,同时将模块分类阈值设置为0.5,即若预测出的含有缺陷的概率取值大于0.5,则将该程序模块预测为有缺陷;否则,将该程序模块预测为无缺陷.其计算公式如下所示.

随后依次给出两个优化目标的计算公式.假设需要进行预测的模块用集合M来表示,候选解用w来表示,则针对模型设置的第1个优化目标,可将其计算公式定义如下.

其中,buggy(mi)用于表示程序模块mi是否包含缺陷:如果该模块内含有缺陷,其取值为1;否则,其取值为0.
针对模型设置的第2个优化目标,可将其计算公式定义如下.

其中,LOC(mi)表示文件模块内含有的代码行数,在该研究工作中,我们假设模块含有的代码行数越多,则需要投入的代码审查量越大(即需要投入更多的软件测试资源).
我们通过一个虚拟实例对这两个优化目标的具体计算过程进行解释.表1展示了训练集中含有的文件和各个文件在某个模型下对应的预测类型Y(⋅)、实际类型buggy(⋅)以及代码审查代价LOC(⋅).则第1个优化目标的值可借助公式(0×1+1×0+...+1×1)计算出,第2个优化目标的值可借助公式(1×50+0×80+...+1×20)计算出.

Table 1 A synthesized instance表1 虚拟实例
基于上述分析,本文将FL-SDP问题建模为经典的双目标优化问题,为了方便后续描述,我们首先对与多目标优化相关的概念进行定义.
定义1(Pareto支配关系).假设用于训练FL-SDP模型的两个候选解分别用wa和wb进行表示,则waPareto支配wb,当且仅当:
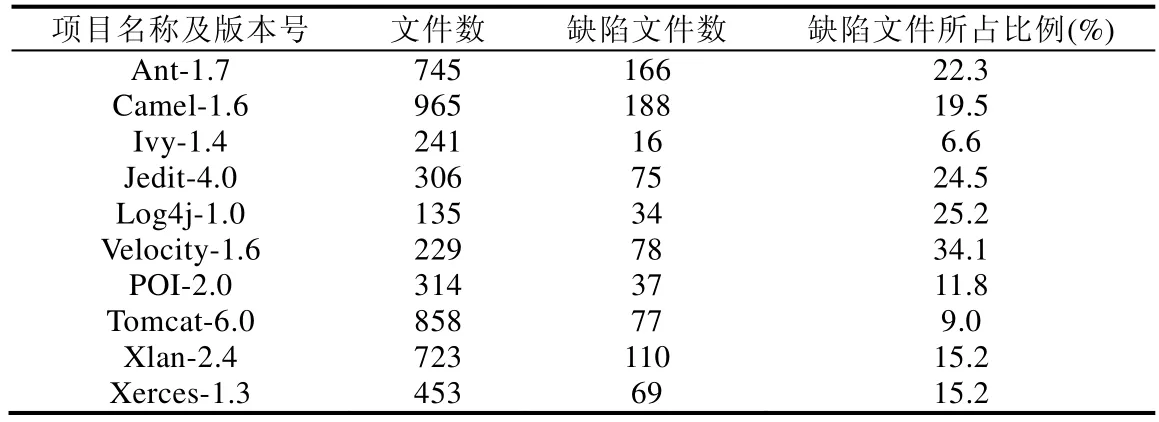
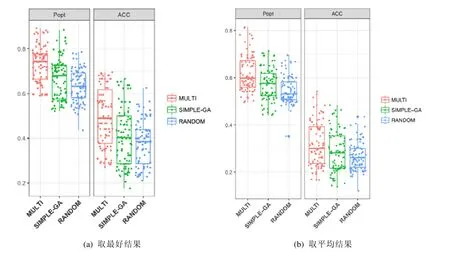
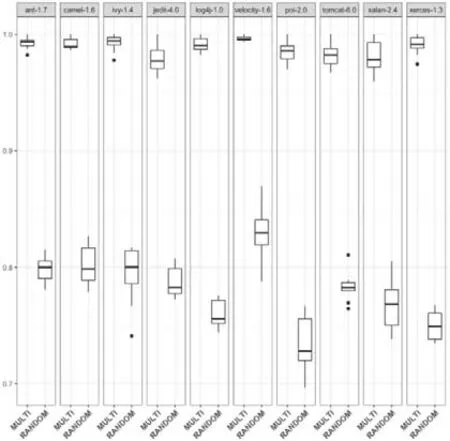
(benefit(wa)>benefit(wb) andcost(wa)≤cost(wb)) or (benefit(wa)≥benefit(wb) andcost(wa) 定义2(Pareto最优解).一个候选解w被认为是Pareto最优解,当且仅当不存在其他候选解w*,该解能够Pareto支配w. 定义3(Pareto最优解集).所有Pareto最优解可以构成Pareto最优解集. 定义4(Pareto前沿).所有Pareto最优解对应的不同优化目标值在空间内形成的曲面被称为Pareto前沿. 针对多目标优化问题,研究人员已经提出了大量不同类型的算法,这些算法主要基于演化算法来构造出Pareto前沿.目前,多目标优化算法在软件工程问题中已经取得了较多的成功应用[7,18].本文考虑的MULTI方法[7]主要基于一种经典的多目标优化算法NSGA-II[19],NSGA-II算法本身具有一定的机制(即基于分层的快速非支配排序算法、染色体的拥挤度计算方法和精英保留机制)可以有效避免种群的过早收敛问题.具体来说:NSGA-II算法在每次进行种群演化时,首先使用演化算子产生新的染色体,随后将这些新产生的染色体与上一轮种群内的染色体进行合并,并使用基于分层的快速非支配排序算法来完成染色体的排序,同时,对于每个非支配层中的染色体依次计算出各个染色体的拥挤度,最后同时考虑非支配关系和染色体的拥挤度,选出指定数量的高质量染色体并形成新的种群..MULTI方法将种群中的染色体编码为预测模型的系数向量,在训练集上可以借助染色体对应的系数向量来训练出预测模型,并随后分别使用benefit函数(见公式(3))和cost函数(见公式(4))依次计算出该预测模型设置的两个优化目标取值.其伪代码如算法1所示. 算法1.MULTI方法. 输入:种群规模N,最大迭代次数T; 输出:Pareto最优解集. MULTI方法的具体执行过程可以总结如下:首先对种群进行初始化(步骤2),染色体对应的向量内元素被随机赋值.随后,使用交叉算子和变异算子可以生成新的染色体(步骤4).具体来说,变异算子会基于指定的变异概率随机挑选出一个染色体,对其进行变异并产生一个新的染色体.交叉算子会基于指定的交叉概率随机选出两个染色体,对其进行交叉并产生两个新的染色体.随后,MULTI方法基于选择算子并通过分析Pareto支配关系,从当前种群内的染色体中选出一定数量的高质量染色体到下一轮种群.具体来说,首先将当前种群内的染色体和基于两种演化算子生成的新染色体合并到集合Bt中(步骤5).然后使用fastNondominateSort函数计算出Bt中的每个染色体的NDR(non-dominated rank)取值(步骤6).该计算过程总结如下,首先从Bt中选出所有不能被Pareto支配的染色体,将它们的NDR值设置为1,同时将它们从集合Bt移到集合F1.随后,继续从Bt中选出所有不能被Pareto支配的染色体,将它们的NDR值设置为2,同时将它们从集合Bt移到集合F2.重复执行上述过程,直到集合Bt不再含有任何染色体.不难看出,基于染色体的NDR取值,MULTI方法会优先选择NDR取值更小的染色体到下一轮种群(步骤7~步骤15).除此之外,MULTI方法还通过拥挤距离[19]来避免选出高相似度染色体,从而确保种群内的染色体具有一定的多样性.当达到指定的最大迭代次数MaxT后,MULTI方法将返回当前种群中的所有Pareto最优解.这里值的注意的是,MULTI方法仅基于训练集来计算出Pareto最优解集,随后基于该集合内的每个最优解训练出缺陷预测模型,并在测试集上计算出该对应模型的预测性能. 2.2.1 有监督学习方法 Ghotra等人[12]最近深入分析了大量有监督学习方法的性能在软件缺陷预测上是否存在显著性差异.本文考虑的31种无监督学习方法主要来自于Ghotra等人[12]在实证研究中考虑的方法,具体见表2. Table 2 Overview of supervised methods表2 本文考虑的有监督学习方法 这些方法也被广泛用于其他文献中[4,6−8].这31种无监督学习方法可以细分为6类.具体来说,function类型包括4种方法,Lazy类型包括1种方法,Rule类型包括2种方法,Bayes类型包括1种方法,Tree类型包括3种方法.集成学习类方法根据集成方式的不同又细分为4个子类(bagging对应的简称为BG、adaboost对应的简称为AB、rotation forest对应的简称为RF、random subspace对应的简称为RS),每个子类各包括5种方法.以BG+LMT为例,其表示该方法采用LMT方法作为基方法,以BG作为集成学习方法.不难看出,这些方法基本上可以覆盖目前机器学习领域中比较经典的有监督方法. 2.2.2 无监督学习方法 与有监督学习方法相比,无监督学习方法具有不需要已标记训练数据、计算开销小以及实现简单等的优点,因此成为当前软件缺陷预测研究中的一个关注热点.Koru等人[20,21]发现,模块的代码规模与其含有缺陷的概率呈正比,因此,代码规模越小的模块,越需要优先给他分配测试资源.这样才能在给定的测试资源下,检测出更多的缺陷.Menzies等人[22]基于Koru等人的发现提出了ManualUp模型,随后,Zhou等人[23]在他们的实证研究中对ManualUp模型的有效性进行了验证.本文重点考虑了Yan等人[8]提出的无监督方法,具体来说,对某个度量元M,其相应的建模方法为R(c)=1/M(c),其中,c表示文件模块,R为预测的缺陷概率.不难看出,在该方法中,度量值较小的模块将排在更前面. 本文在实证研究中重点分析如下实验问题. · RQ1:在同项目缺陷预测场景下,基于多目标优化的MULTI方法的预测性能是否好于基准方法? · RQ2:在跨项目缺陷预测场景下,基于多目标优化的MULTI方法的预测性能是否好于基准方法? · RQ3:若基于PMI和FIA指标,基于多目标优化的MULTI方法与基准方法相比,表现如何? 前两个实验问题基于代价感知的评测指标来比较多目标优化方法MULTI与Yan等人考虑的基准方法的性能差异.后两个指标则由Huang等人[6]提出,重点从测试的模块数以及模块测试时的误报问题这两个角度进行比较,其具体含义见第3.2节. 本文考虑的评测对象来自PROMISE数据集[24],这些评测对象来自于开源项目,具有代码规模大、项目较为有名、项目活跃时间长等特点.除此之外,这些项目也覆盖了不同类型的应用领域,因此具有一定的典型性.如Ant属于程序构建工具、Tomcat属于Web服务器.这些评测对象在度量文件模块时考虑的度量元的类型、名称和具体含义件表3. 基于这些评测对象搜集到的数据集的统计特征见表4,包括项目的名称和版本号、含有的文件数、缺陷文件数以及缺陷文件数所占的比例.不难看出,这些数据集都存在一定的类不平衡问题,缺陷文件占所有文件的比例介于6.6%~34.1%之间. Table 3 Metrics used by experimental subjects表3 评测对象考虑的度量元 Table 4 Statistics of datasets表4 数据集的统计特征 本文重点考察测试代价感知的评测指标,Mende等人[25]首次将测试代价引入到缺陷预测的建模过程,Kamei等人[26]则将传统指标下的实证研究结论在代价感知的评测指标下进行了重新验证.与已有研究工作[4,13]保持一致,本文重点考虑了两个评测指标:ACC和POPT.这两个指标均考虑了软件测试代价,并且都是取值越大,对应的模型性能就越好.本文将程序模块的规模视为测试代价,其中,ACC指标计算的是当使用了指定比例(一般该比例被设置为20%)的测试资源后,模型针对缺陷模块的查全率;而POPT指标则可以认为针对基于测试开销的指标进行了归一化处理,其计算示意图如图1所示,图中共有3条曲线,分别对应预测模型m、最优模型optimal和最差模型worst. 在最优模型中,模块按照其实际的缺陷密度从高到低进行排序,在最差模型中,模块则按照其实际的缺陷密度从低到高进行排序.Area(optimal),Area(worst)和Area(m)分别表示模型optimal,worst以及m对应曲线下的面积.最终POPT指标的计算公式如下所示. Fig.1 Illustration of Popt performance metric图1 Popt 指标的示意图 除此之外,本文还考虑了 Huang等人[6]提出的两种新评测指标.具体来说,PMI(proportion of modules inspected)指标计算在花费20%的测试资源后,测试的模块所占比例.其取值越高,表示在相同的测试成本下进行测试的模块数越多,这意味着需要开发人员进行更多的上下文切换,并可能对他们的开发效率产生影响[27].IFA(number of initial false alarms)指标返回开发人员依次审查模块时,当遇到第1个真正缺陷模块之前需要测试的模块数.该指标在软件缺陷定位研究中[28]经常被用到,其取值越高,表示误报问题越严重,并可能会对开发人员的信心和耐心造成影响. 与Yan等人的研究工作[8]保持一致,本文同样考虑了两种模型性能评估场景:同项目缺陷预测场景和跨项目缺陷预测场景.已有的研究工作大部分集中于同项目缺陷预测场景,即基于一个项目的部分数据来训练预测模型,并用该项目内的剩余数据来评估训练出的模型的预测性能.目前,一般采用10折交叉验证方式,即将数据集借助分层采样方法划分为10等份,轮流将其中的9份作为训练集,剩余1份作为测试集.重复上述过程10次,以确保每个模块都能被预测到1次.同时为了避免数据集中实例次序对预测结果的影响,在实验中,我们将10折交叉验证重复了10次,每次执行前使用不同的随机种子将数据集中的模块进行随机打乱,论文将上述模型性能验证方式称为10×10折交叉验证. 但在实际软件开发的时候,需要进行预测的项目(即目标项目)可能是一个全新启动项目,或这个项目已搜集的标记数据不多,一种解决方法是使用搜集自其他项目(即源项目)的标记数据来训练模型.本文将这种模型验证方式称为跨项目缺陷预测[29−31].假设数据集内含有n个项目,则总共可构成n×(n−1)个跨项目缺陷预测场景.由于本文共考虑了10个项目,因此最终可构成90个跨项目缺陷预测场景. 根据多目标优化算法在数值问题上的参数设置经验[32],本文在实验时将MULTI方法的参数和具体取值分别设置如下:种群规模被设置为200,系数向量内元素的有效取值区间被设置为[−10000,10000],在种群初始化时,系数向量内元素的有效取值区间被设置为[−10,10],最大迭代次数被设置为400,变异概率被设置为0.05,交叉概率被设置为0.5. 考虑到MULTI方法内部存在多个随机因素,我们会独立运行MULTI方法10次并每次会设置不同的随机种子.每次运行时,MULTI方法基于训练集会计算出一组Pareto最优解集.因此独立运行10次后,会累计计算出10组Pareto最优解集.最终,MULTI方法会返回这10组Pareto最优解集中能够在测试集上取的最好性能的解.其具体运行过程如图2所示. Fig.2 Experimental process of MULTI method图2 MULTI方法的实验流程 对需要比较的有监督学习方法,其超参数取值的设定与Yan等人[8]保持一致.针对FL-SDP问题,本文主要考虑了19种无监督学习方法(每种度量元对应一种方法,未考虑LOC度量元的原因是因为本文需要使用LOC值来度量模块的测试代价). 除此之外,针对多目标优化方法和有监督学习方法,我们进行了如下数据预处理. (1) 已有研究表明,数据集内含有的冗余特征会降低随后构建出的模型的预测性能[33].如果一个特征重复了其他单个或多个特征含有的信息,则称该特征为冗余特征.因此,借助Yan等人[8]考虑的特征选择方法移除具有高冗余性的特征.这样可以保证本文所提的方法与Yan等人考虑的方法进行公平的比较. (2) 对所有数值型特征取值进行Log转换处理,以缓解特征取值的偏斜(skew)问题. (3) 在训练集上应用随机欠采样方法来解决搜集的数据集内存在的类不平衡问题.该处理方式与文献[8]保持一致.即会在训练集上随机移除无缺陷程序模块,直至无缺陷程序模块的数量与有缺陷程序模块的数量相等. 除此之外,为了保证结果比较的公平性,针对无监督学习方法,我们仅基于测试集内的程序模块来训练预测模型. 本文借助Scott-Knott检验[34]为本文考虑的所有方法(总共51种)进行排序和分组.Scott-Knott检验尝试将这些不同的方法划分到具有显著性差异的秩中(α=0.05).具体来说,Scott-Knott检验使用分层聚类分析为每个方法设置不同的秩.其首先将所有方法基于平均性能(基于ACC或POPT指标)划分成两组.如果处在一组内的方法仍存在显著差异性,则其会迭代使用上述过程将该组内的方法继续分组,直至组内的方法之间不存在显著差异性为止. 为了分析基于多目标优化的MULTI方法相比其他基准方法是否具有显著性优势,本文考虑了Benjamini-Hochberg(BH)修正后的p值[35],并将其显著水平设置为0.05.如果MULTI方法具有显著优势,则进一步采用Cliff’sδ来度量这种差异程度.其差异程度及建议取值范围与文献[35]保持一致,具体见表5.具体比较过程总结如下:如果MULTI方法显著优于/差于指定的基准方法,需要BH修正后的p值小于0.05,同时,其差异程度不是negligible的;如果MULTI方法与指定的基准方法不存在显著性差异,则BH修正后的p值不小于0.05,或者虽然BH修正后的p值小于0.05,但其差异程度是negligible的. Table 5 Magnitude of effectiveness level of Cliff’S δ and its thresholds表5 Cliff’s δ的差异程度及其建议取值范围 首先,我们通过将MULTI方法与两种简单的搜索方法相比,来验证FL-SDP问题的求解难度.求解难度是指在问题对应的搜索空间内搜索到高质量解的难度.如果问题对应的搜索空间比较简单,则仅使用本文考虑的两种简单搜索方法就可以找到高质量解,这样就不需要求助更加复杂的搜索方法(例如本文提出的基于多目标优化的MULTI方法)了.第1种简单搜索方法是基于单目标优化的遗传算法(SIMPLE-GA).给定需要预测的程序模块集M和候选解w,其搜索优化目标可以通过如下公式进行计算. 不难看出,该简单搜索方法将MULTI方法考虑的两个不同优化目标拟合成一个单一优化目标(这里仅简单地将这两个优化目标的权重各自设置为0.5),同时,在拟合时我们将两个不同优化目标的取值归一到同一取值区间[0,1]内. 另一种简单搜索方法是基于多目标优化的随机搜索算法(RANDOM),与MULTI方法相比,其使用随机搜索代替了其中的遗传算法. 由于这两种简单搜索方法的内部均含有随机因素,因此我们同样独立运行10次,并返回其中最好的结果和平均的结果.同时,将这两种简单搜索方法的参数取值(例如种群规模、最大迭代次数、系数向量成员的有效取值区间)与MULTI方法保持一致.基于跨项目缺陷预测场景下的比较结果如图3所示.不难看出,MULTI方法相对于两种简单搜索方法在ACC和POPT指标上均可以取的更好的预测性能.除此之外,我们在同项目缺陷预测场景下也得到了相似的结论,由此验证了FL-SDP问题的求解难度. Fig.3 Comparision between MULTI with two simple search methods in cross-project defect prediction scenario图3 跨项目缺陷预测场景下MULTI方法与两种简单搜索方法的比较 随后,我们使用hypervolume(HV)指标来比较MULTI方法与RANDOM方法生成的Pareto前沿的质量.HV指标是多目标优化算法评估中常用的一种经典指标[36],其可以很好地衡量Pareto前沿覆盖的目标空间的容量,因此HV取值越大,表示对应的Pareto前沿质量越高.我们同样基于跨项目缺陷预测场景,将MULTI方法与RANDOM方法生成的Pareto前沿基于HV值进行了比较,最终结果如图4所示.通过图4不难看出,MULTI方法生成的Pareto前沿质量更高. 同项目缺陷预测场景下,不同方法的Scott-Knott检验结果如图5所示.其中,虚线用于分隔不同的分组,所有方法按照他们的秩进行排序.蓝色表示无监督学习方法,黑色表示有监督学习方法.从图中不难看出:无论是基于ACC指标还是基于POPT指标,MULTI方法均显著优于Yan等人考虑的无监督学习方法和有监督学习方法. Fig.4 Comparision between MULTI with RANDOM based on HV in cross-project defect prediction scenario图4 跨项目缺陷预测场景下MULTI方法与RANDOM方法在HV值上的比较 Fig.5 Result of Scott-Knott test in within-project defect prediction scenario图5 同项目缺陷预测场景下的Scott-Knott检验结果 随后,我们基于每个项目来将MULTI方法与基准方法进行比较.我们从基准方法中选出性能最好的两种有监督方法和两种无监督方法.最终结果见表6和表7. Table 6 MULTI vs.top two supervised and unsupervised methods in within-project defect prediction scenario using ACC表6 同项目缺陷预测场景下MULTI方法与最好的两种有监督方法和无监督方法的比较(基于ACC) Table 7 MULTI vs.top two supervised and unsupervised methods in within-project defect prediction scenario using POPT表7 同项目缺陷预测场景下MULTI方法与最好的两种有监督方法和无监督方法的比较(基于POPT) 表中记录的是对应方法在每个数据集上进行10×10折交叉验证时,所有预测值中的中位数.这两个表中的倒数第行表示各个方法在不同数据集上的均值,最后一行的Win/Draw/Loss(简称W/D/L)表示MULTI方法显著优于/相似/差于对应方法的数据集的数量.具体来说: (1) 若基于ACC评测指标,平均来说,MULTI方法与最好的无监督方法AMC和RFC相比,其性能有105.81%和118.52%的提高;MULTI方法与最好的有监督方法EALR和AB+LMT相比,其性能有123.34%和200.00%的提高. (2) 若基于Popt评测指标,平均来说,MULTI方法与最好的无监督方法AMC和RFC相比,其性能有35.61%和34.97%的提高;MULTI方法与最好的有监督方法EALR和AB+J48相比,其性能有38.70%和65.95%的提高. W/D/L分析结果也进一步确认了MULTI方法的优越性. 跨项目缺陷预测场景下,不同方法的Scott-Knott检验结果如图6所示.从图中不难看出:无论是基于ACC指标还是基于POPT指标,MULTI方法均要显著优于Yan等人考虑的无监督学习方法和有监督学习方法. 随后,我们基于每个跨项目缺陷预测场景来将MULTI方法与基准方法进行比较.我们从基准方法中选出性能最好的两种有监督方法和两种无监督方法.由于篇幅所限,这里并不罗列出具体结果,总体来说: (1) 若基于ACC评测指标,平均来说,MULTI方法与最好的无监督方法AMC和RFC相比,其性能有22.42%和25.66%的提高;MULTI方法与最好的有监督方法EALR和RBFN相比,其性能有34.95%和60.81%的提高. (2) 若基于Popt评测指标,平均来说,MULTI方法与最好的无监督方法AMC和RFC相比,其性能有11.45%和10.80%的提高,MULTI方法与最好的有监督方法EALR和RBFN相比,其性能有17.92%和37.28%的提高. Fig.6 Result of Scott-Knott test in cross-project defect prediction scenario图6 跨项目缺陷预测场景下的Scott-Knott检验结果 在该实验问题中,我们基于PMI和IFA评测指标,将MULTI方法与基准方法进行比较.由于基于ACC和POPT指标,可能MULTI方法返回的最优模型并不一样,所以本文用MULTI_A和MULTI_P分别表示基于ACC指标和POPT指标下得到的最优模型.最终,基于同项目缺陷预测场景和跨项目缺陷预测场景下的结果分别如图7(a)和图7(b)所示.不难看出,在考虑20%的测试资源时,MULTI方法需要审查的程序模块数较多,但在同项目缺陷预测场景中要低于无监督学习方法RFC、AMC、WMC、MAX_cc和AVG_cc.在跨项目缺陷预测场景下,要低于无监督学习方法RFC和AMC. IFA指标返回是模型在遇到第1个缺陷模块时,审查过的无缺陷模块的数量.最终,基于同项目缺陷预测场景和跨项目缺陷预测场景下的结果分别如图 8(a)和图 8(b)所示.在同项目缺陷预测场景中,MULTI_A和MULTI_P分别排名第5和第4.在跨项目缺陷预测场景中,MULTI_A和MULTI_P分别排名第3和第4. 综上所述,不难看出ACC指标和POPT指标与Huang等人提出的PMI指标和IFA指标之间存在一定的折衷,即MULTI方法虽然在ACC指标和POPT指标上性能更好,但在PMI指标和IFA指标上则取值稍高,因此需要开发人员根据自己的实际需求做出合理的选择.但我们也发现:与最好的两种无监督学习方法(即RFC和AMC)相比,MULTI方法能够取得更好的ACC值和POPT值;同时,PMI值和IFA值都要好于这两种无监督学习方法.因此,体现了MULTI方法具有一定的竞争性. Fig.7 Result of Scott-Knott test for PMI图7 基于PMI指标的Scott-Knott检验结果 Fig.8 Result of Scott-Knott test for IFA图8 基于IFA指标的Scott-Knott检验结果 Fig.8 Result of Scott-Knott test for IFA (Continued)图8 基于IFA指标的Scott-Knott检验结果(续) 4.4.1 与OneWay方法和CBS方法的比较 OneWay[5]是Fu等人提出的最新的一种有监督学习方法,其基于训练集自动从已有的无监督方法中选出最好的方法.CBS(classify-before-sorting)方法[6]是Huang等人提出的最新的一种简单的改进型有监督学习方法,其首先对数据集进行一定的预处理(例如特征选择、类不平衡学习以及对特征取值进行log取值转化);随后,基于Logistic回归建模方法构建模型,在测试集上,根据模型的预测结果将模块分为两类:有缺陷的和无缺陷的;随后,根据模块代码规模将预测为有缺陷类中的模块按照代码规模从小到大进行排序. 和第2.2节提到的一系列基准方法一样,OneWay方法和CBS方法均可用于CL-SDP问题和FL-SDP问题.除此之外,作为有监督方法,这两种方法均采用了第 3.4节所示的同样的数据预处理方法.MULTI方法与OneWay和CBS方法的比较结果如图9所示.从图中不难看出,无论是基于同项目缺陷预测场景还是基于跨项目缺陷预测场景,MULTI方法在ACC评测指标和POPT评测指标上,其性能均要显著优于OneWay方法和CBS方法. Fig.9 Comparision among MULTI,OneWay and CBS图9 MULTI方法与OneWay和CBS方法的比较 4.4.2 基于F1指标的比较结果 除了ACC和POPT评测指标以外,本文也考虑缺陷预测研究中经常使用的F1评测指标[1,31].具体来说,假设仅能使用20%的测试资源,则使用precision表示审查到的模块中缺陷模块所占的比例,使用recall(即ACC)表示审查到的缺陷模块占所有缺陷模块的比例,F1则是precision值和recall值的调和均值.以跨项目缺陷预测场景为例,本文将MULTI方法与Yan等人采用的方法[8]、OneWay方法[5]以及CBS方法[6]进行了比较,结果如图10所示.不难看出,MULTI方法均要显著优于这些基准方法. Fig.10 Result of Scott-Knott test in cross-project defect prediction scenario based on F1图10 跨项目缺陷预测场景下的Scott-Knott检验结果(基于F1评测指标) 4.4.3 时间开销分析 我们进一步分析MULTI方法的模型构建时间开销.由于无监督方法实现简单,因此其运行时间极短,本文主要将MULTI方法与不同的有监督学习方法(包括Yan等人考虑的方法、OneWay方法和CBS方法)进行比较.这些方法运行在MAC OS High Sierra操作系统上(CPU 2.3 GHz Intel Core i5,内存8GB),最终结果见表8. Table 8 Model construction time of different FL-SDP supervised methods (s)表8 不同FL-SDP有监督方法的构建时间 (秒) Table 8 Model construction time of different FL-SDP supervised methods (Continued) (s)表8 不同FL-SDP有监督方法的构建时间(续) (秒) 通过表8不难发现:MULTI方法的模型构建时间虽然都高于基准方法,但处于可接受的范围之内(介于10s~17s之间),其主要计算开销集中在种群演化阶段,即每一轮中,种群内染色体适应值的计算以及常见演化算子的计算开销等. 这一节主要分析可能影响到本文实证研究结论有效性的影响因素,具体说明如下. (1) 内部有效性主要涉及到可能影响到实验结果正确性的内部因素.第一个有效性影响因素是代码实现是否正确,为了减少该影响因素的影响,我们参考了Yang等人[4]、Wu和Menzies[5]、Yan等人[8]提供的代码,并确保与他们实证研究的结果保持一致.除此之外,我们使用了第三方提供的成熟框架,例如来自Matlab和R中的机器学习包.其次,在ACC指标和PMI指标设定时,我们假设可用的测试资源比例是20%,该设定与已有研究工作保持一致[4,13]. (2) 外部有效性主要涉及到实验研究得到的结论是否具有一般性.为了确保实证研究结论的一般性,我们选择了FL-SDP问题研究中经常使用的PROMISE数据集,该数据集累计搜集了10个开源项目,选择的这些项目是开源项目中具有一定代表性的项目,同时,这些项目也覆盖了不同类型的应用领域,可以确保研究结论具有一定的代表性. (3) 结论有效性主要涉及到使用的评测指标是否合理.本文重点考虑了测试代价感知的评测指标POPT,ACC和F1指标;除此之外,我们也深入分析Huang等人[6]提出其他两个评测指标PMI和IFA. 本文针对FL-SDP问题,将基于多目标优化的MULTI方法与Yan等人考虑的基准方法[8]、Wu和Menizes提出的OneWay方法[5]以及Huang等人提出的CBS方法[6]进行了深入的分析和比较.结果表明:无论在同项目缺陷预测场景还是跨项目缺陷预测场景,若考虑代价敏感的评测指标,MULTI方法的预测性能均要显著优于这些基准方法,从而表明MULTI方法在FL-SDP问题上同样值得关注. 本文仍存在很多值得探讨的下一步工作:首先,我们希望能够从开源项目和商业项目中搜集更多的数据集,来验证本文所得的实证研究结论是否具有一般性;其次,本文考虑的数据集预处理方法较为简单,未来可以考虑更为有效的特征选择方法或者类不平衡学习方法[33,37];接着,需要考虑与最新提出的FL-SDP方法进行比较,例如Nam等人提出的CLA和CLAMI方法[38]以及Zhang等人提出的基于谱聚类(spectral clustering)的方法[39]等;最后,本文仅简单使用模块规模来度量模块的测试开销,该假设较为简单[40],在下一步工作中,需要考虑更为合理的测试开销度量方法. 为了方便研究人员重现本文的实证研究,我们将相关代码和实验结果进行了共享,其访问网址是https://github.com/Hecoz/FL-SDP.
2.2 基准方法

3 实验设计
3.1 评测对象

3.2 评测指标

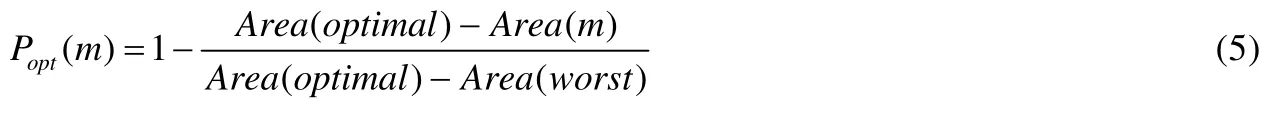
3.3 模型性能评估场景
3.4 实验流程极其方法参数设定

3.5 显著性检验方法

4 实证研究结果的分析

4.1 针对RQ1的结果分析



4.2 针对RQ2的结果分析

4.3 针对RQ3的结果分析



4.4 进一步讨论




4.5 有效性影响因素分析
5 总结和展望
