Cardinality compensation method based on information-weighted consensus filter using data clustering for multi-target tracking
2019-10-26SunyoungKIMChnghoKANGChngookPARK
Sunyoung KIM, Chngho KANG, Chngook PARK,c,d,*
a Department of Mechanical and Aerospace Engineering, Seoul National University, Seoul 08826, Republic of Korea
b BK21+Transformative Training Program for Creative Mechanical and Aerospace Engineers, Seoul National University,Seoul 08826, Republic of Korea
c Automation and Systems Research Institute, Seoul 08826, Republic of Korea
d Institute of Advanced Aerospace Technology, Seoul 08826, Republic of Korea
KEYWORDS Cardinality compensation;Cardinalized probability hypothesis density filter;Data clustering;Information-weighted consensus filter;Multi-target tracking
Abstract In this paper, a cardinality compensation method based on Information-weighted Consensus Filter (ICF) using data clustering is proposed in order to accurately estimate the cardinality of the Cardinalized Probability Hypothesis Density (CPHD) filter. Although the joint propagation of the intensity and the cardinality distribution in the CPHD filter process allows for more reliable estimation of the cardinality (target number) than the PHD filter, tracking loss may occur when noise and clutter are high in the measurements in a practical situation. For that reason, the cardinality compensation process is included in the CPHD filter, which is based on information fusion step using estimated cardinality obtained from the CPHD filter and measured cardinality obtained through data clustering. Here, the ICF is used for information fusion. To verify the performance of the proposed method,simulations were carried out and it was confirmed that the tracking performance of the multi-target was improved because the cardinality was estimated more accurately as compared to the existing techniques.
1. Introduction
Research on algorithms for tracking multiple targets in the field of target tracking has been steadily progressing over the years. Multi-target tracking refers to the problem of jointly estimating the number of targets and their state variables from measurement data. Various techniques related to multi-target tracking can be applied not only to target tracking fields but also to various fields such as computer vision, robotics and autonomous vehicles, space applications, signal processing,and radio navigation.1For example,it can be applied to track multiple frequencies even when multiple interference signals are input in the Global Navigation Satellite System (GNSS)field.2
Multi-target tracking problem in the presence of false alarm and detection probability of sensor measurement less than one is much more complex than the standard filtering problem.There has been the development of algorithms and methods to deal with these problems including measurement origin uncertainty, data association, missed detections, and births and deaths of targets in multi-target tracking. With respect to multiple target tracking algorithms,a Probability Hypothesis Density (PHD) filter was proposed to track multi-target based on the Random Finite Set (RFS) approach.3-7The PHD filter propagates cardinality information with only a single parameter(the mean of the cardinality distribution).When the number of targets is high,the PHD filter estimates the cardinality with correspondingly high variance(increase cardinality uncertainty). Thus, Mahler relaxed the first-order assumption on the number of targets and derived a generalization of the PHD recursion known as the Cardinalized Probability Hypothesis Density (CPHD) recursion.3However, even though the variance of the cardinality(cardinality uncertainty)is reduced by cardinality balancing using the CPHD filter,tracking loss may occur when noise and clutter are high in the measurements in a practical situation. For this purpose,we intended to increase the accuracy of cardinality estimation based on the clutter change from the viewpoint of multi-target tracking. In addition, we tried to accurately cope with cardinality change with time.
Therefore, we propose a cardinality compensation method which is focused on increasing the accuracy of the cardinality estimate to improve the tracking performance of the CPHD filter. The cardinality compensation process is included in the CPHD filter. The cardinality compensation process is based on information fusion step using estimated cardinality obtained from the CPHD filter and measured cardinality obtained by data clustering. In the cardinality fusion step,the Information-weighted Consensus Filter (ICF)8,9is used for information fusion.The ICF is one of the recent consensus filter guaranteed to converge to the optimal centralized performance under certain reasonable conditions. Additionally, it outperforms a conventional Kalman consensus filter and requires computation resource similar to or less than the conventional method. The clustering algorithm used in the proposed method is Fuzzy C-Mean (FCM) clustering10-12and iterative clustering we proposed, which is explained in detail in Section 3. In the existing sequential Monte Carlo (SMC)implementation of the CPHD filter,13the state estimates are extracted by clustering the particles for which the k-means clustering method is used. However, the k-means clustering method is sensitive to the presence of clutter. To combat this,we propose to use the FCM clustering12that is relatively robust to noise and clutter.In addition,even if FCM clustering is applied, it is necessary to determine the optimal number of clustering in order to improve the performance of clustering.For this,the cardinality information obtained from the CPHD filter and the cardinality information obtained through the iterative clustering are fused. We use clustering evaluation index in order to obtain cardinality information in iterative clustering. Among the number of clustering candidates, the number that maximizes the index value is finally selected as the cardinality information for the cardinality compensation.
The rest of this paper is organized as follows.The second section briefly describes the CPHD filter for multi-target tracking.In Section 3,the iterative clustering method is explained in order to obtain additional cardinality information and FCM clustering which is robust to noise and clutter.Cardinality compensation based on average consensus is presented in Section 4.The results of the simulation analysis are shown in Section 5 to confirm the performance of the proposed method.Finally,conclusions and future works are described in Section 6.
2. CPHD filter
The CPHD filter is one of the RFS model-based filters that jointly propagates the intensity function and the cardinality distribution(the probability distribution of the number of targets).The intensity propagation equation in the CPHD filter is much more complex than that in the PHD filter.The propagation of the posterior cardinality distribution is added in the process of the PHD filter and is coupled to the propagation of the posterior intensity. The prediction and update process in the CPHD filter are shown in Fig. 1.13
The prediction process in the CPHD filter is as described in Ref.13:
The predicted cardinality distribution pkk-1|n( ) is given by
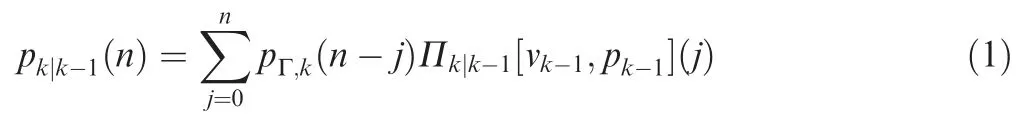
where pΓ,kn-j( ) represents the probability of n-j spontaneous births,and Πk|k-1[vk-1,pk-1](j)is the probability of j surviving targets and is calculated by

where pS,kζ( ) represents the probability of target existence at time k given previous state ζ.
The CPHD cardinality prediction is a simple convolution of cardinality distributions of the birth and surviving targets as shown in Eq. (1) because the predicted probability is the sum of cardinalities of the birth and surviving targets.
The predicted intensity vk|k-1(xk) is given by

where pS,kxk-1( ) represents the probability of survival,fkk-1|xkxk-1|( ) is the Markov transition density, vk-1xk-1( )denotes the intensity from previous time-step, and γkxk( ) is the intensity of spontaneous object births Γk. The CPHD intensity prediction of Eq. (3) is the same as the PHD prediction equation.13
The update process in the CPHD filter is as follow:
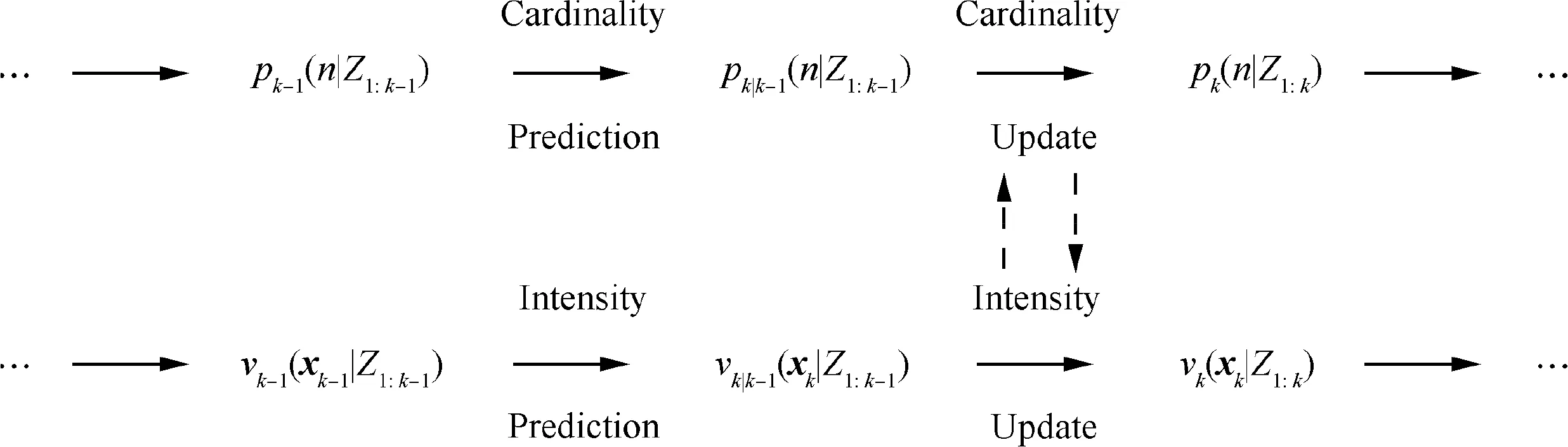
Fig. 1 Prediction and update process in CPHD filter.13
The updated cardinality distribution pkn( ) is given by■ ■
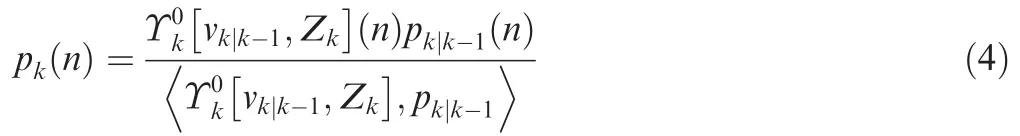
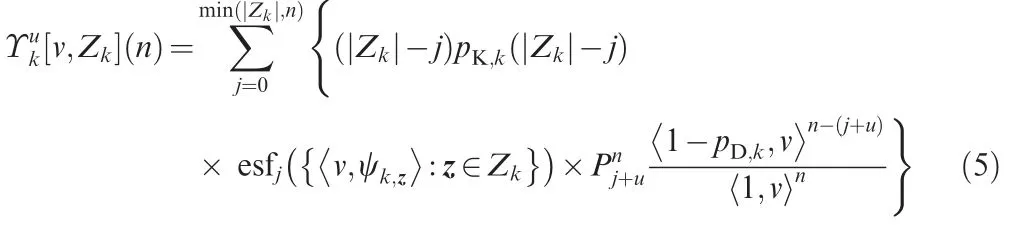
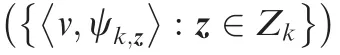

where esfj() is the elementary symmetric function14of order defined by a finite set of real numbers, ζ is previous state, Sxis any closed subset that satisfies Sx⊆Zk, pD,kxk( ) represents the probability of detection,gkz xk|( )is the likelihood function,and κkz( ) denotes the clutter intensity.
The cardinality update of Eq.(4)includes the clutter cardinality, the measurement set Zk, the predicted intensity, and predicted cardinality distribution. This equation is a Bayes update with the denominator as the normalizing constant and the likelihood of the multi-target observation Zkgiven that there are n targets.
The updated intensity vkxk( ) is given by
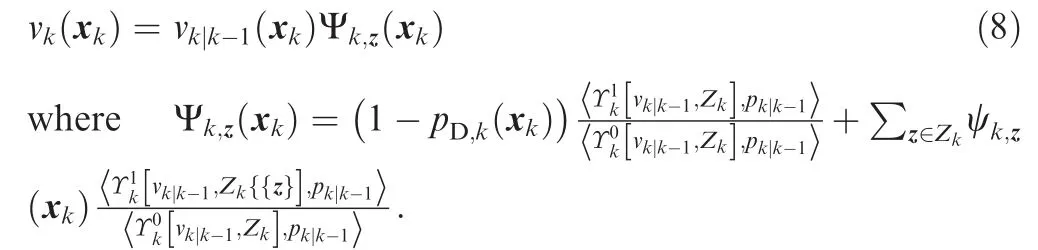
As shown in Fig. 1, the CPHD cardinality and intensity update equations (Eqs. (4) and (8)) are coupled, whereas the CPHD cardinality and intensity prediction (Eqs. (1) and (3))are uncoupled. Nonetheless, the CPHD intensity update of Eq. (8) is similar to the PHD update because both have one missed detection term and Zk| |detection terms.We introduced a special form of the CPHD recursion which explicitly shows the propagation of the intensity and cardinality. Previous research proposed closed-form solution to the CPHD recursion for linear Gaussian multi-target models.13,15A full SMC implementation of the PHD recursion was also proposed in Ref.16with relevant convergence results established in Refs.16-18. Thus, as we just focused on the improvement of the SMC based CPHD for applying to multiple GNSS frequency tracking, the detailed information of SMC PHD filter structure is omitted in this paper. Details about the SMC implementation of the PHD filter and the filter structure can be found in the earlier mentioned papers.13,15-18
Even though the variance of the cardinality (cardinality uncertainty) is reduced by cardinality balancing using the CPHD filter, tracking loss may occur when noise is high in the measurements in a practical situation, especially multiple GNSS interference tracking problem. If the accuracy of cardinality estimate increases,tracking loss caused by missing target numbers may be reduced.Therefore,we have implemented the following structure focused on increasing the accuracy of cardinality estimates to improve the tracking performance of the CPHD filter in the GNSS.
3. Clustering for cardinality compensation
Clustering technique is used to improve cardinality estimation performance in two ways. First, an iterative clustering technique was used to generate additional cardinality information for cardinality compensation. Herein, the technique used in the clustering process is the FCM clustering technique and was performed on the unknown clustering number. Next,unlike the k-means clustering method for extracting state variables from the conventional CPHD filter, to further improve the estimation accuracy, this study used the FCM clustering method in the last process of estimation.

Fig. 2 Block diagram of iterative clustering.
FCM allows one piece of data to belong to two or more clusters10and is one of the most widely used fuzzy clustering algorithms.FCM was first proposed to cope with clusters adding noise as a method of indicating the degree of belonging as membership grades.11FCM clustering constitutes the oldest component of software computing and is suitable for handling the issues related to the understanding ability of patterns,incomplete/noisy data, mixed media information, and human interaction, and it can also provide approximate solutions faster.12The structure of FCM is very similar to the k-means algorithm and produces results close to k-means clustering in an ideal case.However,FCM requires more computation time than k-means because of the fuzzy measure calculation in the algorithm.12In addition, the results of FCM can depend on the initial value of weight and has a local minimum.Nevertheless, the reason for choosing FCM instead of k-means is to improve the estimate performance of the cardinality in the CPHD filter, which is as follows; in clustering analysis, the problem of outliers is considered to be one of the most critical problems.Clustering using k-means is very sensitive to outliers and its performance is severely degraded in a practical case.Thus,we selected FCM clustering to increase the performance of the cardinality estimate because we need to estimate the cardinality of the frequency using received data with measurement disturbance (clutter and noise).
First,the FCM clustering method is used in the part of the CPHD filter for selecting the optimal clustering number,which is called the iterative clustering process as shown in Fig. 2.
The iterative clustering process is where the FCM clustering method is iteratively performed (m times) with the set of candidate clustering numbers, smand the Clustering Evaluation Indexes (CEIs)19are calculated from the clustering results of the FCM clustering process, respectively. The optimal clustering number (sopt) is then selected, of which the CEI is the largest in the set S.
The CEI is a way to measure the quality of clustering and can be classified into external evaluation and internal evaluation. External measures are based on known data that was not used for clustering, such as ‘‘ground-truth”. A commonly used external measure is the Rand index,19which computes how similar the clusters are and is in [0, 1], and an index of 1 indicates a perfect match. There are many other methods,such as adjusted Rand index, F-measure, Jaccard index, Dice index, Fowlkes-Mallow index, etc., but we do not cover them in detail.19
Internal measures only rely on properties intrinsic to the data set and evaluate the cluster itself as a result of clustering the data set.These methods usually assign the best score to the algorithm that produces clusters with high similarity within a cluster and low similarity between clusters. One disadvantage of using internal criteria in cluster evaluation is that a high score does not necessarily guarantee that it is close to the true ground truth since only the result of clustering data is judged.
When these arrived at the palace with the beautiful young maiden everyone pitied her fate; but she herself was of good courage, and asked the queen for another bridal chamber11 than the one the lindorm had had before
Nevertheless, we aim to estimate the target number of unknowns, so the internal measure is used to estimate the number of clusters. Among the various internal measures,three performance indexes, the Silhouette (SI) index, the Calinski-Harabasz (CH) index, and the Davies-Bouldin (DB)index, are representatively considered. A brief description of each index is as follows.
The SI index is defined as cluster compactness based on the pairwise distances between all points in the cluster,and separation based on pairwise distances between all points in the cluster and all points in the closest other clusters.The SI index19is written as

The CH index is defined as compactness based on the distance of points in a cluster to its centroid, and separation as the distance of the cluster centroid to the data centroid. The CH index11is written as

The DB index is defined as compactness based on the distance of points in the cluster to its centroid, and separation based on distances between centroids. The DB index19is written as
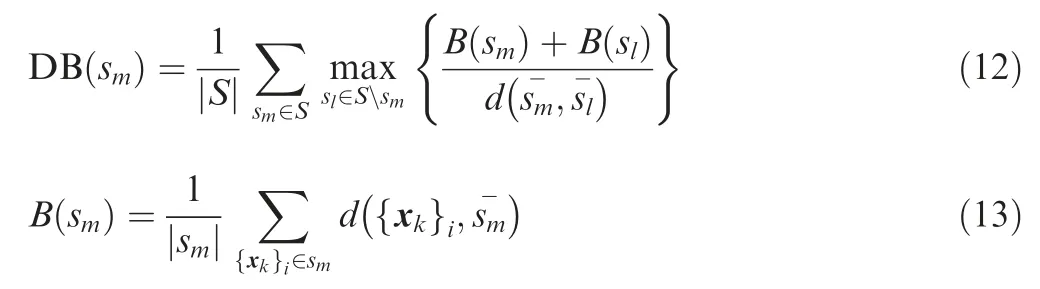

All the three above defined measures are essentially a ratio of cluster compactness (points in the same cluster should be similar) and separation (points in different clusters should be dissimilar). They differ in how these two concepts are defined,and how they are combined.19
A simple simulation was performed to see if any of the above three indexes could compensate for the cardinality obtained from the CPHD filter. It was assumed in the simulation that there were two cluster groups, and the average of each cluster group was 150 and 350, respectively (the whole region is [0 500]). In addition, the center of each cluster group does not change with time, and the number of clutter only changes according to the interval in order to confirm whether the index can indicate clustering quality well. In the simulation, the clutter had the Poisson distribution property of the uniform region, and the Poisson average rate (λ) value of the clutter was changed as shown in Fig. 3 in a total of 300 simulation times. The larger λ is, the larger the number of clutter per unit area is.
In Fig.4,the y-axis represents the quality of clustering.The quality is better when the magnitude is larger. In order to improve the quality, the cardinality information obtained by the evaluation index was balanced with that from the CPHD filter, using the design parameters, and the results were as shown in Fig.4.The blue chain line is the quality of the cardinality information obtained by evaluating with the SI index,the green broken line is that by evaluating with the CH index,and the red solid line is that by evaluating with the DB index.Through Fig.4,we choose the DB index because the DB index can generally compensate for the quality of the cardinality information obtained from the CPHD filter. In this paper,we experimentally determined the DB index, and these results can be verified through Ref.19where the index is used to evaluate spectral clustering which is difficult to distinguish. In addition,as shown in Table 1,the DB index has an advantage in terms of computation time even though its complexity is similar to that of the CH index. The simulation results of the proposed overall algorithm were shown in Section 5.
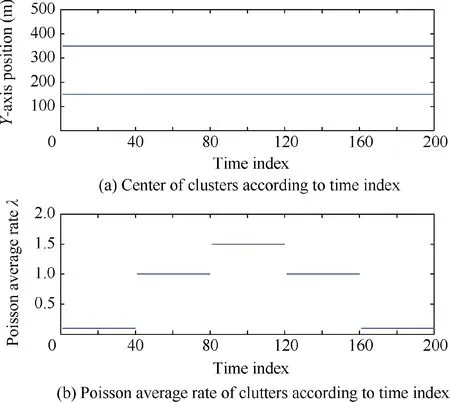
Fig. 3 Clutter distribution.

Fig. 4 Comparison of clustering quality.
As mentioned earlier, in order to increase the tracking performance regardless of the existence of clusters or disturbance in measurement, the FCM clustering method was also used to estimate sample point set and estimate the cardinality in the last process of the CPHD filter.
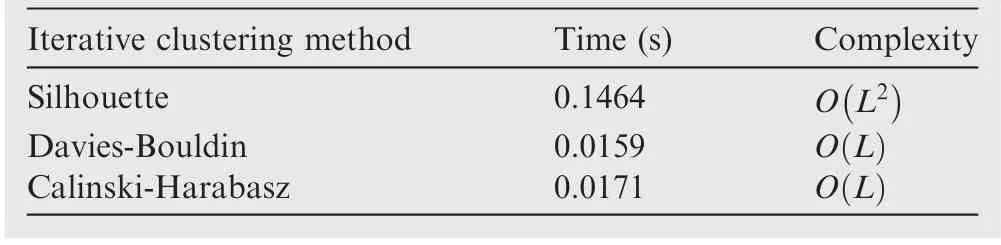
Table 1 Comparison of clustering evaluation index.
4. Cardinality compensation
In this study, the cardinality compensation was performed as two parts. In the first, the cardinality was calculated by iterative clustering based on FCM clustering,and then the information fusion process was performed using the estimated cardinality obtained from the CPHD filter and the measured cardinality from the clustering results. The flowchart of the proposed algorithm is shown in Fig. 5. The red squares in the figure are different from the existing CPHD structure and were newly added to improve the cardinality performance and the tracking performance in the CPHD filter. The proposed method can improve the performance of the existing CPHD filter because the method can estimate the number of targets with a smaller error than that of the existing CPHD filter when extracting state variables from the SMC based CPHD filter using the clustering technique and the data fusion technique.
The method proposed in this paper is described step by step as follows.First,when measurements come in,the CPHD filter updates the intensity function and the cardinality distribution function and then performs a prediction process. Since we implemented this CPHD filter on the basis of SMC, the particles undergo resampling process in predicted intensity function and updated intensity distribution function. For this purpose,the sequential importance resampling methods were used.Among them,systematic resampling method,one of the traditional resampling methods, was used. Since the resampling process is not covered in this paper, details about resampling can be found in Ref.20. These resampled particles are used in the iterative clustering process in order to obtain the cardinality needed for cardinality compensation.At this time,the clustering number that maximizes the index among the candidate's number of clustering is found by using the clustering evaluation index, and the found optimal clustering number is used as cardinality information for cardinality compensation. The cardinality information obtained from the cardinality estimation in the CPHD filter is fused with the cardinality information obtained from iterative clustering using the concept of average consensus. The state variables are finally extracted by FCM clustering of resampling particles using the final cardinality information obtained through fusion. In other words,the cardinality obtained through cardinality compensation is used as the number of clustering for FCM clustering, and the resampling particles are used as data for these clustering.

The information fusion method is used to combine two types of information for increasing the accuracy of the cardinality estimate.Information fusion is mainly used in the sensor fusion field and is also used to fuse information obtained using various sensors. Typical methods include cross covariance,covariance intersection, sequential covariance intersection,and consensus filtering.21Among them, the ICF8,9is used to fuse information for improving the cardinality accuracy in the CPHD filter and is one of the consensus filtering techniques22for multi-sensor fusion in a system with unknown correlations in the sensor network field.The goal of this filter is to track all the targets using the measurements from all the sensors in a distributed manner.The ICF is sub-optimal like Kalman consensus filter,23which is one of the first proposed consensus filters.Nevertheless,this filter has advantages of distributed schemes such as being scalable for large networks,tolerant to node failure, and less complicated to install. In addition, the ICF can maintain the measurement convergence performance of multiple sensors even if the measurement update cycle is different for each sensor, or if there is a naı¨ve sensor node in the sensor network.
The system model and the measurement model of the ICF are as follows:

where the system noise w k( ) and the measurement noise vik( )are simplify modeled as white Gaussian noise with zero mean and variance Q and Ri, respectively, F is the state transition matrix, and Hiis the observation matrix.


Fig. 5 Flowchart of proposed algorithm.
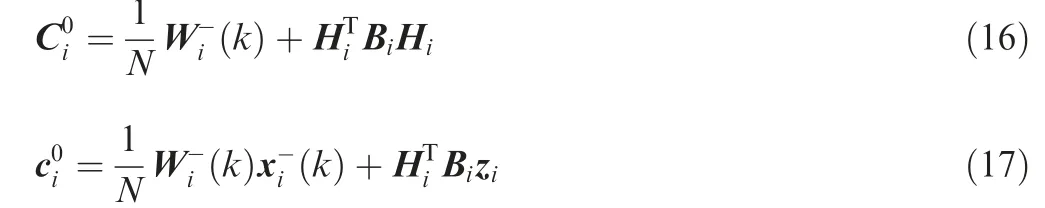
where N represents the number of sensors,k( )represents the prior state estimate, andk( ) denotes the prior information matrix which is the reciprocal of the covariance of the prior state estimate.
The information matrix Ciand the matrix-vector ciof the ith node sensor independently perform an average consensus,repeating Eqs. (18) and (19) from t=1 to t=Tt(consensus iteration).

where h represents all neighboring sensors which exchange information with connected sensors as shown in Eqs. (18)and (19). ε is the rate parameter which should be chosen between 0 and 1/Δmax, where Δmaxis the maximum number of connected sensors. The rest of the detailed explanation on the ICF is written in Ref.8.
The process of the proposed cardinality compensation method is given below.
Inputs: Prior compensated cardinality x-k( ), prior information matrix W-k( ),consensus rate parameter ε,state transition matrix F, process covariance Q.
Compute initial information matrix and vector
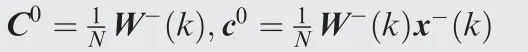
Perform average consensus on C0and c0independently
for t=1 to Ttdo

end
Compute a posteriori compensated cardinality and information matrix for time k

Predict a compensated cardinality and information matrix for time k+1( )
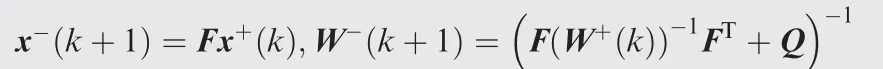
Output: Compensated cardinality x+k( ), information matrix W+k( )
where F=I, W-k( ) is the reciprocal of the covariance of the prior compensated cardinality x-k( ), and N represents the number of fusion information and was set to 2 in this study(one is from the CPHD filter and the other is from the clustering process). S denotes the set of clustering candidates,S= 1,2,3{ }in Fig.2,to select the optimal number of the candidate clusters. In the iterative clustering process, the computational complexity may increasingly depend on the number of clustering candidates. In the future, further research for considering the computation load is needed. Finally, the compensated cardinality is used to track multiple targets and is used as input clustering number to FCM clustering.As mentioned in Section 3,the CPHD filter in the benchmark paper13uses k-means clustering for extracting states using particles,but k-means can make the tracking performance and the cardinality estimation performance degrade in the presence of measurement disturbance (clutter and noise). Thus, we replaced the clustering method in the proposed algorithm as shown in Fig. 5.
Recently, various papers have been published using the concept of ‘‘average cardinality consensus”.24-26The concept of‘‘average consensus(cardinality compensation)”used in this paper is similar to the concept of the references, but there are differences as follows. In references, the consensus structure is used to correct cardinality by incorporating them into the field of sensor networks, and the same measurements are used for distributed system fusion. On the other hand, in the proposed method, two sensor nodes are connected rather than multiple systems,and two system results calculated from different viewpoints are merged. One is the cardinality obtained from the CPHD filter and the other is the cardinality value calculated by the clustering. The average consensus is used in order to combine the two results for the information fusion point of view.
5. Simulation
The performance of the proposed algorithm was verified in simulations which reflect the 2D target tracking system and its system model and measurement model set the same as those of Ref.13. As mentioned in the introduction section, we intended to increase the accuracy of cardinality estimation based on the clutter change from the viewpoint of multitarget tracking. In addition, we tried to accurately cope with cardinality change with time.In order to confirm this,2D simulation is performed as in this paper,where state variables are the x-axis and y-axis position of the target. Moreover, since only one axis is changed to simplify the performance analysis,the x-axis represents the time index and the y-axis represents the position(unit:meter)of the y-axis in the simulation results.
To quantitatively analyze the tracking performance, an Optimal SubPattern Assignment (OSPA), which is a performance index used in the multi-target tracking field, was calculated.27The OSPA defines a performance index considering estimation error and the estimated number of target errors.The OSPA distance between two finite sets Xoand Yois computed by
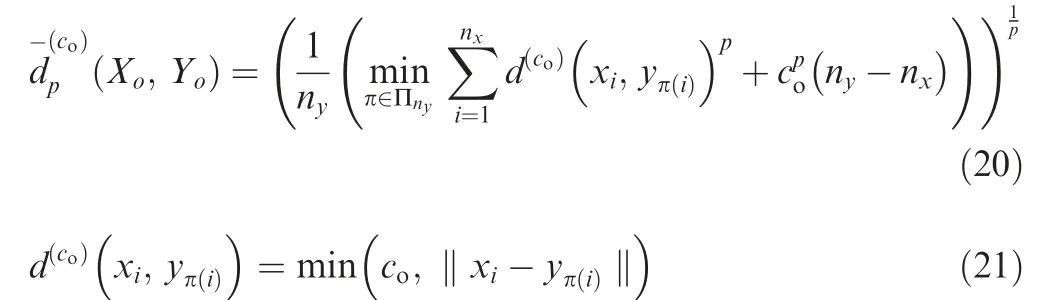

Fig. 6 Multi-target tracking result and cardinality estimate result (Case 1).
The target tracking result and the cardinality estimate result from the CPHD filter are presented as shown in Fig.6,Fig.7 and Table 2.In Figs.6(a),(b)and(c),the solid red lines represent the true trajectory, the gray crosses indicate the target measurements with the clutter of the CPHD filter, and the black dots indicate the targets estimated by the CPHD filter.In Fig.6(d),the true value of the cardinality is ‘2' and other notations indicate the cardinality estimated using the CPHD filter with k-means clustering (conventional), FCM clustering, and cardinality compensation (proposed), respectively. In the case of k-means clustering, the track loss was partially caused by the estimated value not keeping up with the true value as shown in Fig.6(a).From Figs.6(a)and(b),the tracking performance of the CPHD filter using FCM clustering was slightly better than that of the CPHD filter using k-means clustering.
However, as shown in Fig. 6(b), there was still track loss.The performance of the cardinality estimate was rather deteriorated.Thus,we applied the cardinality compensation method to improve track loss problem.As shown in Figs.6(c)and(d),the performance of the target tracking and the cardinality estimate were improved when the cardinality compensation was applied. Of course, the cardinality compensation method still needs to be improved in the future because the current cardinality compensation method cannot get perfectly true tracking result and the cardinality estimate.

Fig. 7 Multi-target tracking result and cardinality estimate result (Case 2).
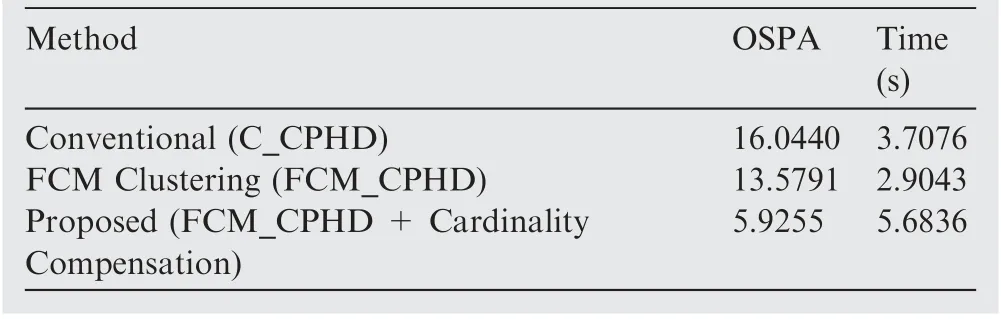
Table 2 Comparison of tracking result.
In order to analyze the performance of the proposed algorithm,the additional simulation was conducted.The condition of the added simulation was that the number of targets changes from 2 to 1, and the remaining conditions were the same as that of the first simulation as shown in Fig. 6. The additional simulation result was shown in Fig. 7. As shown in the simulation results in Fig.7,the added simulation results were confirmed that the proposed algorithm was also less affected by the clutter, and the estimation performance was also good even in the time-varying number of target case.
Table 2 represents an average of the comparison results(OSPA and operation time) shown in Figs. 6 and 7. The proposed method had the smallest OSPA,and the cardinality calculation and tracking performance were excellent, but the computation time was doubled when compared with the conventional method. Thus, future research is also needed toimprove the computational efficiency of the proposed algorithm.

Table 3 Comparison of tracking result according to clustering evaluation index.

Fig. 8 Four-targets' trajectories.
The simulations were conducted to compare the final tracking performance by clustering evaluation indexes as shown in Fig. 4 and Table 1. The scenario is the same as Fig. 6 (Case 1)and the final tracking results according to clustering evaluation index are shown in Table 3.As can be seen from the table,the OSPA performance index is the smallest when the DB index is used in the proposed technique. This result proves why we selected the DB index through an analysis of the performance index quality.
Finally, we benchmarked Ref.28and proceeded with the simulation.The simulation was performed for multiple targets with various trajectories, and the results were analyzed using the performance analysis parameters which are used to analyze the scenarios in the benchmark paper.28
The scenario is set as follows.In Fig.8(a),the solid red lines represent the true trajectory of four targets and the gray crosses indicate the four targets' measurements with clutter.Fig. 8(b) shows the trajectories of four targets, respectively.Table 4 shows the Root Mean Square Error (RMSE) and track loss results for four targets using the three methods compared in Table 2.Since the track loss result was reflected in the RMSE calculation,it was confirmed that the RMSE value was proportional to track loss result. On average, we found that the proposed method has small RMSE and track loss ratio although there are some differences depending on the tracks.
From the simulation results, we confirmed that the estimation performance of the cardinality, which is obtained from using FCM clustering instead of k-means clustering when extracting state variables in the conventional CPHD filter, is improved. We also verified that the estimation performance of the cardinality, which is compensated by using cardinality information obtained from the DB evaluation index, is more improved.
6. Conclusions
In the proposed CPHD filter structure,the cardinality for state variables'extraction is calculated using FCM clustering which is more robust to noise and outliers as compared to k-means.In addition, the cardinality is compensated by the ICF using the cardinality obtained from the iterative clustering algorithm result in order to reduce track loss and improve the tracking performance.
Through simulations,we confirmed that the estimation performance of the cardinality and the tracking performance of targets in the conventional CPHD filter were greatly improved,but there are still needs for improvement. First, when the DB evaluation index is used in the iterative clustering process, the optimal selection of the clustering candidates is needed for increasing computational efficiency of the proposed algorithm.In addition,since the CPHD filter is based on SMC,research is needed to apply various resampling techniques to the filter.

Table 4 Comparison of tracking result according to targets.
Acknowledgements
This work has been supported by the National GNSS Research Center Program of the Defense Acquisition Program Administration and Agency for Defense Development,and the Ministry of Science and ICT of the Republic of Korea through the Space Core Technology Development Program(No.NRF-2018M1A3A3A02065722).
杂志排行

CHINESE JOURNAL OF AERONAUTICS的其它文章
- Heading control strategy assessment for coaxial compound helicopters
- An adaptive integration surface for predicting transonic rotor noise in hovering and forward flights
- An algorithm to separate wind tunnel background noise from turbulent boundary layer excitation
- Simulation of mass and heat transfer in liquid hydrogen tanks during pressurizing
- Leakage performance of floating ring seal in cold/hot state for aero-engine
- Six sigma robust design optimization for thermal protection system of hypersonic vehicles based on successive response surface method