基于累计工作量的在线大数据分析作业调度算法
2019-10-23李叶飞徐超许道强邹云峰张晓达钱柱中
李叶飞 徐超 许道强 邹云峰 张晓达 钱柱中


摘 要:针对Hadoop和Spark等大数据分析系统中无先验知识任务的高效执行问题,设计了基于累计工作量(CRW)的任务调度器CRWScheduler。该调度器根据CRW将任务在低权重队列与高权重队列间切换;在为作业分配资源时,同时考虑到作业所在的队列和其瞬时占用资源量,无需作业先验知识即显著提升系统性能。基于Apache Hadoop YARN实现了CRWScheduler原型,在28个节点的基准测试集群上的实验表明,与YARN的公平调度机制相比,作业流时间(JFT)平均降低21%,其中95百分位的作业流时间(JFT)最多降低了35%,并且在与任务级调度程序协作时可获得进一步的性能提升。
关键词:数据分析系统;作业流时间;公平性;饥饿避免
中图分类号: TP316.4
文献标志码:A
Online task scheduling algorithm for big data analytics based on cumulative running work
LI Yefei1, XU Chao2, XU Daoqiang3, ZOU Yunfeng2, ZHANG Xiaoda1, QIAN Zhuzhong1
1.Department of Computer Science and Technology, Nanjing University, Nanjing Jiangsu 210023, China ;
2.Electric Power Research Institute, State Grid Jiangsu Electric Power Company Limited, Nanjing Jiangsu 210000, China ;
3.State Grid Jiangsu Electric Power Company Limited, Nanjing Jiangsu 210000, China
Abstract: A Cumulative Running Work (CRW) based task scheduler CRWScheduler was proposed to effectively process tasks without any prior knowledge for big data analytics platform like Hadoop and Spark. The running job was moved from a low-weight queue to a high-weight one based on CRW. When resources were allocated to a job, both the queue of the job and the instantaneous resource utilization of the job were considered, significantly improving the overall system performance without prior knowledge. The prototype of CRWScheduler was implemented based on Apache Hadoop YARN. Experimental results on 28-node benchmark testing cluster show that CRWScheduler reduces average Job Flow Time (JFT) by 21% and decreases JFT of 95th percentile by up to 35% compared with YARN fair scheduler. Further improvements can be obtained when CRWScheduler cooperates with task-level schedulers.
Key words: data analytics system; Job Flow Time (JFT); fairness; starvation-free
0 引言
在现代主流分布式大数据分析系统(例如Apache Hadoop、Apache Spark、Apache Tez)中,作业是由一系列任务构成的,可表示为有向无环图(Directed Acyclic Graph, DAG),其中每个顶点表示一个任务,边表示任务之间输入与输出的依赖关系。为提升资源利用率,作业之间会共享集群资源[1-3]。用户级公平性确保所有用户都能够在共享集群中获得资源[4-10]。然而,从用户的角度看,除了可以获得的资源量,如何高效地利用已分配的资源来快速完成其作业同样是一个重要问题。作业完成效率一般用作业流时间(Job Flow Time, JFT)来刻画,其值定义为作业完成时间减去作业提交时间。本文针对分布式大数据分析系统的作业调度问题,研究任务调度算法,在确保用户之间公平性以及无饥饿的前提下,加速DAG作业的完成。
即使是在离线场景(offline setting)中,最小化平均作业流时间的DAG调度问题都是NP难的。而Hadoop和Spark中的默認集群调度机制将资源划分为固定大小的资源块(Slots),例如〈2个CPU内核, 1GB内存〉,并将资源块提供给作业。在此过程中调度器并未考虑作业的执行进展情况,使得作业完成时间变长[4,10-11]。为此,Carbyne[12]和Graphene[13]等优化的作业调度机制将不同的任务分类以提高集群整体的吞吐率,同时根据初始的作业量(所有任务正在处理的时间总和)以短作业优先(Shortest Job First, SJF)[14]的方式调度DAG作业,从而减少了平均作业流时间。一方面,短作业优先的策略会导致长作业饥饿,损害作业级的公平性;另一方面,这种调度机制预先假设已知作业的全部先验知识,如:DAG的结构和任务处理时间。对于一些重复出现的作业确实可以在当前集群中预测其特征[15-17],但在一般的情况下,由于集群的动态性(任务中断、推测执行)等难以预先获取完全的作业信息,从而限制了这些调度机制的实用性[2-3]。
LAS (Least-Attained Service)[17]是一种基于作业提交后已展现的运行信息来进行调度的策略,由于它不需要提前获取完全信息,具有更强的实用性;并且,当作业的工作量服从重尾分布时,LAS能近似最优策略的性能[3]。但传统LAS策略仅考虑了计算量一个维度,而大数据处理作业对CPU与内存的消耗具有同等重要的地位。为此,本文基于LAS思想,提出了支持多类型资源(CPU、内存等)的非饥饿集群调度机制CRWScheduler。CRWScheduler基于主资源[4]的累计运行工作量(Cumulative Running Work, CRW)来预测作业的总工作量,从而无需提前获取作业特征,即可减少平均作业流时间。
通过使用权重多队列架构,CRWScheduler将基于CRW的启发式算法(有利于重尾分布)和先进先出(First In First Out, FIFO)思想(有利于轻尾分布)组合起来。每个作业基于其CRW会被分配到特定的队列中, CRW较小的作业队列被设置较低的权重;而在分配资源时,CRWScheduler首先按照“分数”将队列进行排序,然后依据分数递增的顺序分配资源。分数的计算同时依赖队列中作业当前占用资源的情况和队列的权重。一方面,当前不占用资源的队列其分数为0,有最高优先级获得新资源,又由于每个队列中作业为先进先出,进而避免了作业出现饥饿的情况。另一方面,由于CRW较小的队列的权重较小,相比有相同资源的队列有更高的优先级获得新资源。这样做模拟了短作业优先的策略,降低了平均作业流时间。有别于PIAS (Practical Information-Agnostic flow Scheduling)[18]和Aalo[19-20]等其他基于LAS策略的网络流调度机制,CRWScheduler避免了PIAS等调度机制导致作业饥饿的问题,也克服了Aalo等机制需要无限分割资源,但并不能实际满足DAG作业的最小资源需求的缺陷。
本文基于Apache Hadoop YARN (Yet Another Resource Negotiator)[21]实现了CRWScheduler,并将系统部署在28个节点的集群中。通过全面的工作负载测试结果显示,与公平调度相比,CRWScheduler的平均作业流时间缩短了10%~35%,而其中95百分位的作业流时间缩短了21%~35%。
1 研究现状
大数据分析系统
目前的数据分析系统大致可分为资源管理和计算框架两类。资源管理平台,如Apache YARN[21]和Apache Mesos[7]。从物理机器抽象出资源,使弹性计算框架易于构建和有效运行。研究人员和从业人员已经开发出了多种易于编程的框架,如Apache Tez[1]、MapReduce[2]、Dryad[3]和Apache Spark[3]。这些框架通常将作业看成DAG,从而使得它们可以表达对资源的偏好和约束。吴信东等[22]比较了MapReduce和Spark在不同场景中的性能。
大数据分析的任务调度
延迟调度[10]和Quincy[23]通过调度单个任务以更接近于其输入数据,从而提高单个任务的数据本地性。ShuffleWatcher[24]提高了阶段(stage)之间的shuffle局部性;Tetris[15]确保多台机器能更好地打包任务;Corral[16]同时考虑了结合数据和计算位置的优化。这些工作集中于任务调度级别,同时CRWScheduler能够更好地与其协作。
对于调度一个单独的作业,列表调度和工作窃取调度[25]是常见的异步优化方案,比如对于多个DAG作业共享一个并行多主机集群,LAPS (Latest Arrival Processor Sharing)[26]有良好的性能,然而并没有得到应用。文献[13]中证明了短作业优先(SJF)算法与LAPS有相近的性能,并且不涉及参数。王习特等[27]提出了基于序列的任务调度策略SEQ(SEQuence-based task scheduling strategy)來最大化集群运行作业的收益。本文验证了CRWScheduler能够在无先验知识的情况下达到近似于SJF的性能。
2 DAG作业调度
首先形式化地定义DAG作业调度问题以及一些相关的概念,然后量化分析实际生产中的工作负载,最后用一个例子展示基于CRW的调度机制所获得的性能提升。
2.1 问题定义
本节定义DAG作业调度问题,之后给出问题的计算复杂度,最后形式化地定义累计运行工作量(CRW)。
假设一个用户在时刻0提交了若干个作业J,每个作业包含若干个任务,crij表示第i个作业的第j个任务对于资源r的需求量。假设dij表示相应任务的处理时间,且dij并未考虑持续时间内位置环境的影响。Dij表示表示作业i中任务j的依赖任务集合,只有当Dij中的任务全部完成,作业i中任务j才能被调度执行。整个集群包含机器的集合为P,每台机器s包含资源r的容量为prs。假设Aij代表作业i中任务j分配的机器,Bij表示任务分配发生的时间,Itij指示在时刻t,作业i的任务j是否在集群上运行。
定义1 作业i的流时间为其到达时间与其最后一个任务完成时间的间隔时间,即:max j∈i {t>0 | Itij>0}。
约束条件:
1)在任何时刻,一台机器上的所有任务使用的资源总和不得超过当前机器相应资源的容量:
r,t,s∈P,∑ Aij=s crij·ltij≤Prs
(1)
2)调度器不能在一个任务还未完成前中断任务:
Itij= 1, Bij≤t≤Bij+dij0, 其他
(2)
3)一个任务只有等到其所依赖的任务全部执行完才能被调度执行:
Bij≥max k∈Dij {Bik+dik}
(3)
目标函数:最小化平均作业流时间(即最小化作业流时间之和):
∑ i∈J max j∈i {t>0 | Itij>0}
(4)
定理1 满足上述目标(4)和约束条件(1)~(3)的DAG作业调度问题为NP难问题。
证明 通过证明该问题的一个特殊情况是NP难来证明该问题的计算复杂性。对于所有作业中的任务,假设Dij为空集且任务的执行时间为1;假设在0时刻共有 | P | 个箱子。若能够将所有任务打包起来所需的箱子数小于 | P | ,那么所有作业的完成时间为1;否则在1时刻开启另外 | P | 个箱子,来判断是否能将剩余的任务打包。因为判断最少的箱子数是NP难的[20],故DAG作业调度问题是NP难的。
注意到即使没有任务位置偏好,DAG作业调度问题仍然为NP难。鉴于NP难问题的复杂度[28],本文在考虑非饥饿的同时寻找有效的启发式方法以最小化平均流时间。
为了论述方便,预先定义以下概念。
定义2 作业i的总工作量(Original Work)是指对于特定资源,任务需求与任务处理时间的乘积与集群资源容量的最大比率,即:
R(i)=max r 1 ∑ s∈P prs ∑ j∈i crij·dij
定义3 作业i在t时刻的当前运行任务数为:
CR(i,t)=∑ j∈i Itij
定义4 作业i在t时刻的累计运行工作量(Cumulative Running Work, CRW)是指对于每种资源,该作业已经完成的任务和正在运行任务中对该资源的需求量和可用量比值的最大值,即:
RW(i,τ)=max r 1 ∑ s∈P prs ∑ j∈i ∑ t≤τ crij·Irij
2.2 工作负载分析
如表1所示,Yahoo!采集了在2500个节点的集群中的作业所使用资源(以Slot数量计算)的情况。作业的资源使用情况在实际生产中满足重尾分布[29]:即大部分的作业都属于轻量级,它们只占用少量的集群资源;小部分繁重的作业占据着大部分的集群资源。
在重尾分布中,一个作业已经完成的程度将是其实际工作的一个好的预测值[13]。在本文所讨论的场景中,CRW很好地近似了作业总工作量,因此基于CRW的调度机制(CRW较小的作业优先)在实际负载工作中近似于短作业优先(SJF)。
2.3 典型实例分析
图1以具体的例子显示了现有调度器的缺陷:公平调度器(fair scheduler)总是将资源分配给当前资源占有量最少的作业[30];容量调度器(capacity scheduler)根据作业提交时间分配资源[31];SJF[14]能够实现最优的调度,但是它依赖于作业提交时完全的先验的作业特性。
假设用户在时刻0提交作业A和B,在时刻1提交作业C。每个任务需要1个单位的处理时间,每个任务有不同的资源需求。假设所有资源的总量为1。作业流时间定义为从作业的提交时间到作业最后一个任务完成的时间间隔。基于固定资 源块(每个slot的资源为〈0.5, 0.5〉)的公平调度器以实时最大 最小公平(max-min fairness)的方式为作业分配资源[30]。公平调度器作用下的平均作业流时间为17/3,而容量调度器导致平均流时间也为17/3。考虑已知DAG结构和细粒度任务需求,SJF调度策略将会根据其总工作量逆序调用作业,使得平均作业流时间为5。基于CRW的调度器将资源分配给具有最小累计运行工作量的作业。在时刻1,基于CRW的调度器将为作业C分配2个任务,而不是1个,因為作业A、B、C在时刻1的CRW分别为0.4、0.5、0。基于CRW的调度器可使得平均作业流时间为16/3。在这个例子中,基于CRW的调度器不需要先验的作业特性,但能够近似最优的调度器,实现更低的平均作业流时间。
基于此,本文试图根据作业的累计运行工作量设计在线的动态调度器来分配资源以保证无饥饿的同时减少平均作业流时间。
3 基于CRW的作业调度机制
如图2所示,在分配资源时,用户级调度机制根据用户在集群中的份额排序。公平调度机制为最小(内存)份额的用户提供资源[10],然而主资源公平的调度机制(Dominate Resource Fairness, DRF)将其扩展为考虑多类资源(如CPU、内存)[4]。任务调度器尝试提高任务的数据本地性[10],或者最小化集群资源碎片[15],或者根据任务依赖约束进行分类[12]。CRWScheduler位于用户之间的调度和任务调度之间,将每个用户内部的作业作为输入,试图缩短平均作业流时间。
3.1 权重多队列框架
在多个DAG作业共享多台机器的场景中,作业到达和离开的时间都是在线的,难以获得完整的作业信息,因此最短作业优先原则实际上是无法实施的。因此,依据2.2节分析和定义4,累计工作量是作业总工作量的良好的预测值,一个直观的启发式方法是基于累计运行工作量的思想近似最短作业优先。
在t时刻,为作业i赋予分数CR(i, t) * CRW(i, t),按照分数非递减的方式分配资源。这样做的目的是在保证饥饿不发生的前提下减少平均作业流时间:因为饥饿作业的分数为0(因为CR(i, t)=0),在分配资源时具有最高的优先级;并且,较低CRW的作业有较高的优先级,又因为CRW可以很好地评估一个作业的总工作量,所以这个启发式方法有助于最小化平均作业流时间。
然而,对于满足轻尾的作业分布,上述启发式算法实际上就退化成了作业之间公平共享资源,这并不能最小化平均作业流时间。例如,两个相同的作业等待调度执行,其中一个作业被选中执行,这个作业的分数提高了,将导致另一个作业被调度执行,因此,两个作业的完成时间都变成了最优时间的两倍。而在这种情况下,FIFO调度策略能最小化平均完成时间。因此,本文算法通过权重多队列框架将基于CRW的机制和FIFO策略组合起来,具体介绍见3.2节。
3.2 DAG作业调度CRWScheduler
本文通过将基于CRW的启发式思想和FIFO的启发式思想综合起来考虑,引入权重多队列框架(Weighted Multi-Queue Framework,WMQF)。CRWScheduler基于运行中作业的CRW值将其划分到相应的队列Q1,Q2,…,Qn中去。在队列Qi中的作业的CRW值属于[Qi-1.th,Qi.th],其中Qi.th是队列Qi的阈值同时满足Qi+1.th>Qi.th;且 Q0.th=0。CRWScheduler从Q1到Qn以递减的方式设置队列权重Qi.weight。一个作业的CRW值随着其任务在集群中执行单调递增,一旦其CRW值超出所在队列的阈值,当前作业将从当前队列转移到下一个队列。
CRWScheduler实时记录每个作业的CRW值,同时在必要时调整作业所在的队列。当一个作业周期性地向集群报告其心跳时,将调用UPDATECRW:为作业分配新的slot(Cn)以执行其任务,同时返回完成后的slot(Cr)给集群调度器。当作业更新后的CRW值超出队列的阈值时,该作业将会转移到下一个队列(代码第7)行)。
Qr.score=Qr.weight· 1 | Qr | ∑ i∈Qr CR(i,τ)
(5)
算法1
DAG作业调度CRWScheduler。
程序前
procedure UPDATECRW(JOB i, Cn, Cr)
//在作业向集群报告其心跳时调用
1)
R ←当前累计运行资源向量
2)
k←作业i的队列index
3)
在新分配的slot Cn中启动任务
4)
fo r c∈Cr∪Cn do:
5)
R +=c· r (time.Now-c.lastUpdateTime)
6)
if max( R )>Qk..th then
7)
将作业i从队列Qk转移到Qk+1
procedure CRWSCHEDULE(NODE n)
//在机器向集群报告其心跳时调用
8)
wh ile n has free resources do
9)
decide user u to offer resources to
10)
jobList=SCOREDLIST(u)
11)
offer resources to jobList
procedure SCOREDLIST(USER u)
//将作业排序
12)
n←用户u所在的队列数
13)
fo r i=1 to n do:
14)
使用式(5)计算Qi.score
15)
根据score对队列进行排序
16)
jlist←连接有序队列中的作业
17)
return jlist
程序后
CRWScheduler維持了用户级别的公平性(代码第9)行),并在每个用户内部调度作业。当一台机器周期性地报告其心跳时,CRWSchduler被调用,同时将重新分配资源。通过设置权重随队列索引递减,CRWScheduler使用式(5)计算每个队列的分数(代码第14)行),其中∑ i∈ Q r CR(i,τ)表示的是队列Qr中当前所有作业正在运行的任务数量之和, | Qr | 表示的是队列Qr中当前的作业的数量。也就是说,Qr.score为队列中当前运行任务的平均值与队列权重的乘积。按照Qr.score非递减的顺序排序可使得CRWSchduler为重尾作业分布保留了基于CRW的启发式特性:因为有较低CRW的作业所在队列的权重较大,导致其作业排在jlist前面;与此同时,也保证了FIFO思想在轻尾作业分布中的优势,即在同一队列中的作业是FIFO的,从而使CRWScheduler有效地防止了队列和作业中饥饿现象的发生,同时缩短了平均作业流时间。
3.3 CRWScheduler的实现
Tez[1]、Hadoop[21]和Spark[32]等经典的数据分析系统将集群功能划分为多个角色,包括集群管理器(resource manager)、节点管理器(node manager)与作业管理器(job manager),图3中带“+”的部分为CRWScheduler在已有架构上的修改与扩展。为了保证系统的扩展性、性能以及可靠性,类YARN的数据分析系统[10]将集群功能划分为若干个不同的守护进程。本文通过如下修改将CRWScheduler整合到Apach Hadoop YARN框架(Hadoop 2.6)中。集群管理器为每个用户管理多个队列框架,同时在资源分配中实现CRWScheduler。节点管理器进行slot分配的同时追踪slot的运行时间。作业管理器负责增加自身的CRW值,并在必要时使用UPDATECRW调整其所在的队列。
对Apache Hadoop YARN框架所做的修改并不影响原有调度器的可扩展性,因为CRWScheduler在分配资源时将队列排序,而原有的调度器是直接对作业进行排序。CRWScheduler在作业更新时增加了累计运行工作计算,这是一个工作量适中的操作,同时实验结果也显示这一花销并不会影响系统的性能。
4 实验评估
4.1 实验配置
本文在28个节点的集群中运用各种类型的工作负载评估CRWScheduler,并且以仿真的方式在更大的集群中评测CRWScheduler的开销。
集群中的每个节点采用2核CPU,4GB内存,1Gb/s NIC网卡,运行Ubuntu14.04系统。
对比方法:将CRWScheduler与Hadoop 2.6中实现的调度算法进行对比。为了与公平调度器[10]和DRF调度器[4]相比较,CRWScheduler替换了这些调度机制中的作业调度组件,同时保留了用户之间的调度组件。同样将CRWScheduler与容量调度器[4]相比较。本文利用延迟调度机制[10]作为默认的任务调度机制。
性能指标:主要关注于提升作业流时间(平均作业流时间或者绝大多数作业流时间)和作业吞吐量。
测试负载:使用Apach Spark来生成运行在YARN上的DAG作业。评估中使用的作业来源于如下数据分析应用:WordCount、TPC-H基准、迭代机器学习以及PageRank。如表2所示,对于每一类工作负载,数据集大小仿照真实生产环境的集群按比例缩放(Yahoo![8]和Facebook[10])。对于作业的分布,设置46%、40%和14%分别为小型、中型、大型的作业,这与实际应用中作业的分布相似[10]。
4.2 实验结果
本文首先讨论CRWScheduler在多用户环境下相比现有调度策略在性能上的提升,同时集中分析对于单用户作用吞吐率的提升效果,之后将隔离提交作业以模拟轻尾工作负载,最后评估经过修改的架构与初始架构相比所产生的额外开销。
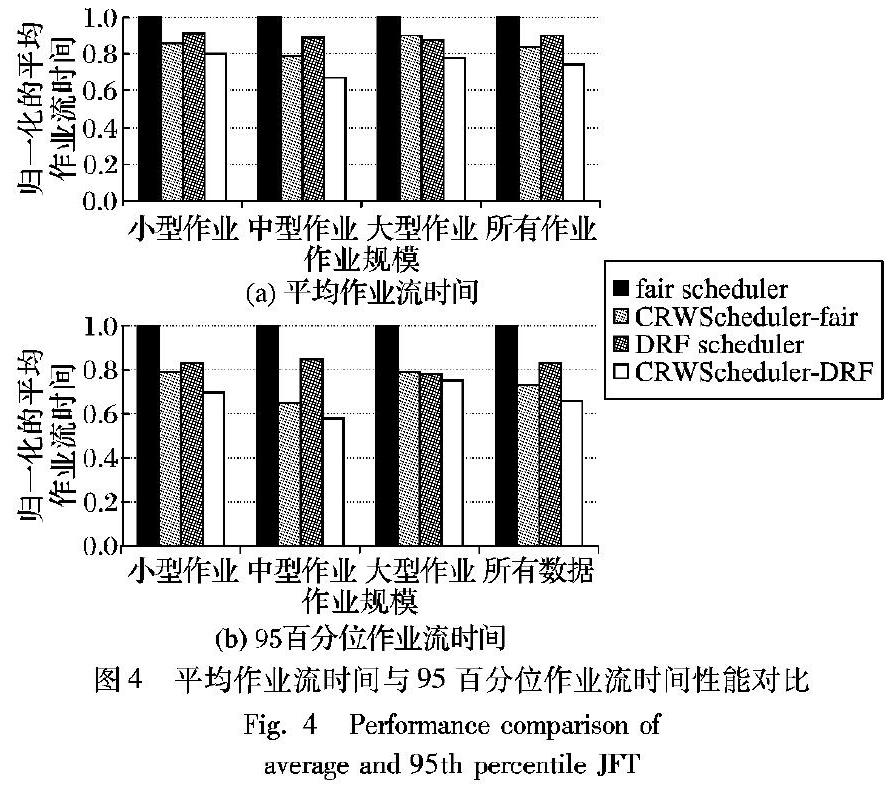
1)多用户环境实验。假设有7个用户,为每个用户生成300个作业。图4显示了当CRWScheduler与公平调度器协作(CRWScheduler-fair)以及与DRF调度器协作(CRWScheduler-DRF)时的性能提升,所有的指标均按公平调度标准化。 图4(a)显示,与fair scheduler相比,CRWScheduler-fair处理小型、中型、大型作业的平均JFT分别减少了14、21和10个百分点,对于所有的作业而言,JFT平均减少了16个百分点;与DRF调度器相比,CRWScheduler-DRF处理小型、中型、大型作业的平均JFT分别减少了10、22以及10个百分点,对于所有的作业而言,JFT平均减少15个百分点。图4(b)描述了95百分位的作业流时间的提升效果。
2)单用户环境实验。为了突出在资源竞争激励的环境下CRWSheduler对性能的提升,设置的实验环境为:单用户每隔20s提交一次作业。对每种调度策略进行1h的实验,并分别统计其吞吐量。如表3所示,CRW公平调度策略相于单纯的公平调度策略吞吐量提升了32%,CRWSheduler-DRF调度策略相比DRF吞吐量提升了45%。
3)轻尾作业分布。实验为每个尺寸的作业生成100个作业,并且分开提交到服务器集群。容量调度程序在这些轻尾作业分布中进行最优调度。图5显示,CRWScheduler的调度效果近似于容量调度器,因为CRWSchduler能保持作业在相同的队列中进行FIFO调度,所以优于公平调度。
4)额外开销:使用300节点集群进行仿真实验,每个机架有30台服务器,同时生成10000个作业,计算从节点中作业处理和更新的平均时间。表4显示,对于每个作业心跳的额外开销在0.05ms以内,这对于集群管理者来说可以忽略不计。在节点心跳中,公平调度器直接对运行中的作业排序,而CRWScheduler首先對队列进行排序,之后通过合并有序的队列得到有序的作业列表,从而使得CRWScheduler在资源分配时能达到更短的响应时间。
表格中的“事件平均处理时间”是算法的开销,而“更短的响应时间”是指之前实验中作业流时间这个指标,确认表述正确
5 结语
目前的DAG作业调度机制都需要预先获得完整的作业信息,但在大量实际应用中难以实现。为此,本文提出了累计运行工作量(CRW),以估算作业总工作量,并设计了CRWScheduler调度器。它基于作业的CRW值将当前运行的作业划分成多个队列,同时考虑作业瞬时资源占用率以及不同的队列权重,不仅能缩短平均作业流时间,也抑制了“饥饿”现象。而通过保持作业在每个队列中的FIFO顺序,CRWSheduler还提高了轻尾作业分布的性能。本文基于Apache Hadoop YARN实现了CRWSchduler原型系统,通过部署在28个节点的集群中进行多类型数据分析应用的测试。实验结果显示,相比YARN的公平调度机制,CRWScheduler将平均作业流时间缩短21%,而95百分位的作业流时间缩短35%。然而,当前任务执行时的资源使用是隧道化的,同一时刻会同时使用多种资源。多任务同时运行在同一物理机上时会造成不可预知的资源竞争,从而难以对任务执行时间建模。元任务(monotask)是将任务划分成更小的粒度,每个元任务只消耗一种资源(磁盘、网络和内存等)。通过将每个任务划分成元任务,能够更好地对任务和作业的执行时间建模。下一步拟研究针对元任务的调度机制,以进一步提高集群的资源利用率和作业性能。
参考文献
[1] Apache Software Foundation. Apache Tez [EB/OL]. [2017-12-21]. http://tez.apache.org/.
[2] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [C]// Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation. Berkeley, CA: USENIX Association, 2004, 6: 10-10.
[3] ISARD M, BUDIU M, YU Y, et al. Dryad: distributed data-parallel programs from sequential building blocks [C]// Proceedings of the 2nd ACM Special Interest Groups in Operating Systems (SIGOPS)/European Conference on Computer Systems. New York: ACM, 2007: 59-72.
[4] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing [C]// Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 15-28.
[5] GHODSI A, ZAHARIA M, HINDMAN B, et al. Dominant resource fairness: Fair allocation of multiple resource types [C]// Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 323-336.
[6] GHODSI A, ZAHARIA M, SHENKER S, et al. Choosy: max-min fair sharing for datacenter jobs with constraints [C]// Proceedings of the 8th ACM European Conference on Computer Systems. New York: ACM, 2013: 365-378.
[7] HINDMAN B, KONWINSKI A, ZAHARIA M, et al. Mesos: A platform for fine-grained resource sharing in the data center [C]// Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 295-308.
[8] VAVILAPALLI V K, MURTHY A C, DOUGLAS C, et al. Apache hadoop YARN: yet another resource negotiator [C]// Proceedings of the 4th Annual Symposium on Cloud Computing. New York: ACM, 2013: 1-16.
[9] WANG W, LIANG B, LI B. Multi-resource fair allocation in heterogeneous cloud computing systems [J]. IEEE Transactions on Parallel and Distributed Systems, 2015, 26(10): 2822-2835.
[10] ZAHARIA M, BORTHAKUR D, SARMA J S, et al. Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling [C]// Proceedings of the 5th ACM European Conference on Computer Systems. New York: ACM, 2013: 265-278.
[11] Apache Software Foundation. Hadoop MapReduce Next Generation — Fair Scheduler [EB/OL]. [2018-10-21]. http://tinyurl.com/j9vzsl9.
[12] GRANDL R, CHOWDHURY M, AKELLA A, et al. Altruistic scheduling in multi-resource clusters [C]// Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 65-80.
[13] GRANDL R, KANDULA S, RAO S, et al. Graphene: packing and dependency-aware scheduling for data-parallel clusters [C]// Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 81-97.
[14] AGRAWAL K, LI J, LU K, et al. Scheduling parallel DAG jobs online to minimize average flow time [C]// Proceedings of the 27th annual ACM-SIAM Symposium on Discrete algorithms. Philadelphia, PA: Society for Industrial and Applied Mathematics, 2016: 176-189.
[15] FERGUSON A D, BODIK P, KANDULA S, et al. Jockey: guaranteed job latency in data parallel clusters [C]// Proceedings of the 7th ACM European Conference on Computer Systems. New York: ACM, 2012: 99-112.
[16] GRANDL R, ANANTHANARAYANAN G, KANDULA S, et al. Multi-resource packing for cluster schedulers [C]// Proceedings of the 2014 ACM Conference on SIGCOMM. New York: ACM, 2014: 455-466.
[17] JALAPARTI V, BODIK P, MENACHE I, et al. Network-aware scheduling for data-parallel jobs: Plan when you can [C]// Proceedings of the 2015 ACM Conference on SIGCOMM. New York: ACM, 2015: 407-420.
[18] RAI I A, URVOY-KELLER G, BIERSACK E W. Analysis of LAS scheduling for job size distributions with high variance [C]// Proceedings of the 2003 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems. New York: ACM, 2003: 218-228.
[19] BAI W, CHEN L, CHEN K, et al. Information-agnostic flow scheduling for commodity data centers [C]// Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2015: 455-468.
[20] CHOWDHURY M, STOICA I. Efficient coflow scheduling without prior knowledge[C]// Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication. New York: ACM, 2015: 393-406.
[21] Apache Software Foundation. Apache Hadoop NextGen MapReduce (YARN) [EB/OL]. [2017-12-21]. http://tinyurl.com/zyy8kbc.
[22] 吳信东,嵇圣硙.MapReduce与Spark用于大数据分析值比较[J].软件学报,2018,29(6):1770-1791. (WU X D, JI S W. Comparive study on MapReduce and Spark for bid data analytics [J]. Journal of Software, 2018, 29(6): 1770-1791.)
[23] ISARD M, PRABHAKARAN V, CURREY J, et al. Quincy: fair scheduling for distributed computing clusters [C]// Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles. New York: ACM, 2009: 261-276.
[24] AHMAD F, CHAKRADHAR S, RAGHUNATHAN A, et al. Shufflewatcher: Shuffle-aware scheduling in multi-tenant mapreduce clusters [C]// USENIX Proceedings of 2014 USENIX Annual Technical Conference. Berkeley, CA: USENIX Association, 2014: 1-12.
[25] BLUMOFE R D, LEISERSON C E. Scheduling multithreaded computations by work stealing [J]. Journal of the ACM. 1999, 46(5): 720-748.
[26] EDMONDS J, PRUHS K. Scalably scheduling processes with arbitrary speedup curves [J]. ACM Transactions on Algorithms, 2012, 8(3): 256-265. [C]// Proceedings of the twentieth annual ACM-SIAM symposium on Discrete algorithms. New York: ACM, 2009: 685-692.
[27] 王習特,申德荣,于戈,等.MapReduce集群中最大收益问题的研究[J].计算机学报,2015,38(1):109-121. (WANG X T, SHEN D R, YU G, et al. Research on maximum benefit problem in a MapReduce cluster [J]. Chinese Journal of Computers, 2015, 38(1): 109-121.)
[28] VAZIRANI V V. Approximation Algorithms [M]. Berlin: Springer, 2003: 74-78.
https://www.logobook.ru/prod_show.php?object_uid=11146016
[29] NAIR J, WIERMAN A, ZWART B. The fundamentals of heavy-tails: properties, emergence, and identification [C]// Proceedings of the ACM SIGMETRICS/International Conference on Measurement and Modeling of Computer Systems. New York: ACM, 2013: 387-388.
[30] WIKIPEDIA. Max-min fairness [EB/OL]. [2017-12-21]. http://tinyurl.com/krkdmho.
[31] Apache Software Foundation. Hadoop MapReduce Next Generation — Capacity Scheduler [EB/OL]. [2018-12-01]. http://tinyurl.com/j739ojm.
[32] Apache Software Foundation. Apache Spark [EB/OL]. [2018-11-07]. http://spark.apache.org/.
