基于拉曼高光谱成像的乳粉真伪非定向筛查新方法研究
2019-10-22卜汉萍陈晓宇
宗 婧,卜汉萍,陈 达,陈晓宇,鲍 蕾*
(1.天津大学 精密仪器与光电子工程学院,天津 300072;2.雀巢研发(中国)有限公司 雀巢食品安全研究院,北京 100016;3.中国民航大学 飞机防火及应急研究所,天津 300300)
乳粉作为一种大宗高频的食品原料,在全球经济中占有重要地位[1]。然而由于经济利益驱使,乳粉的掺假行为在相当程度上较为猖獗,严重危害人民群众特别是婴幼儿的生命健康[2]。当前我国食品安全标准检测方法仅针对有限量标准的物质制定,虽然检测目标涵盖千余种化学物质,但仅仅是现有化学物质的极小部分。因此,对乳粉真伪问题进行科学评估成为目前重要而急迫的任务。
常用的乳粉掺假检测方法主要为高效液相色谱法[3]、气相色谱-质谱联用法[3]、液相色谱-串联质谱法[4]、基质辅助激光解吸电离飞行时间质谱(MALDI-TOF MS)[5]等色谱和质谱技术,通过构建大数据库的方式,尽可能地覆盖奶粉中的未知物。这些方法虽然检测灵敏度高,但样品前处理繁琐,费时费力且费用较高,难以实现对乳粉的大批量快速筛查。此外,受限于我国当前的人力物力条件,这类高端仪器的筛查技术难以普及。因此,迫切需要发展新型、高效的乳粉非定向筛查技术。
在各类检测技术中,拉曼光谱技术具有简单、无损、通量高等优点,可同时检测有机和无机组分,在食品安全非定向筛查领域具备良好的应用潜力[6-8]。在拉曼光谱的非定向筛查中,往往依赖主成分分析(PCA)、簇类独立软模型(SIMCA)等数据降维方法进行定性分析[1,7-8],但这些方法仅能针对已知类别画出合理分界线。然而,在食品未知掺杂物的拉曼光谱信号中,掺杂物的存在极可能导致信号产生畸变,而传统的PCA方法和SVM方法无法克服畸变信号对模型的影响,从而导致建模失败。此外,传统的拉曼光谱技术只单纯使用光谱仪采集样品单点数据或多个数据取平均值,而忽略了乳粉样本的非均匀异质特征和取样代表性[9],极有可能淹没低浓度掺杂物的光谱特征,从而导致其检测灵敏度降低,造成对乳粉样本的误判错判。针对以上问题,近年来发展的拉曼高光谱成像技术可有效改善样本取样的代表性,结合新型的化学计量学方法,具备良好的非定向筛查应用潜力。
在实际应用中,拉曼高光谱成像有机结合了拉曼光谱技术和二维成像平台,在大面积扫描样品的同时,准确捕获微区部分的精细信息[10],进而以图谱合一的方式准确记录食品关键组分的空间拓扑结构。然而,拉曼高光谱成像技术在食品领域的应用尚处于起步阶段,如检测牛肉肌肉内脂肪分布的特征[11],定量检测面粉中过氧化苯甲酰添加剂[12],检测辣椒粉中的掺假物[13]等,这些研究均针对特定的食品组分或掺杂组分进行分析,尚未发挥其非定向筛查功能。对于拉曼和近红外等光谱成像技术的定性分析,大部分仅参考待测掺杂物的纯物质光谱,找出典型掺杂物的特征谱峰位置,并结合该位置强度信息画出单波长强度图,根据相应的阈值判据,画出二值成像图[14-18]。除此之外,文献还报道了光谱角测量(SAM)、光谱相关性测量(SCM)和欧式距离测量(EDM)等光谱相似性分析方法,由此比较被测物每个像素点的光谱与纯掺杂物的光谱相似度,通过设置有效阈值的方式达到定性分析食品中掺杂物的目的[11,19]。然而,在乳粉真伪鉴别的实践过程中,由于各类掺杂物质种类繁多,不法商贩极有可能添加新型掺假物来规避检查[6],定向筛查方法难以全面覆盖未知掺杂物信息,传统的拉曼高光谱成像技术难以满足相关要求,发展新型、高效的拉曼高光谱成像迫在眉睫。
本文拟发展一种基于稳健建模驱动的拉曼高光谱成像技术(RMD-RHIM),以实现乳粉真伪的非定向筛查。在RMD-RHIM方法中,以蛋白质这一典型指标的稳健建模为切入点,将拉曼高光谱掺杂像素点映射为畸变像素点,构建可视化的二值图像,进而以非定向的方式精确识别奇异样本。结果表明,RMD-RHIM方法对绝大部分未知掺杂物均具有很好的识别率,为乳粉真实性的非定向筛查提供了一种新手段,并可拓展到其它食品样本的非定向筛查。
图1 便携式拉曼高光谱成像系统示意图Fig.1 Schematic diagram of the portable Raman hyperspectral imaging system
1 实验部分
1.1 实验装置
实验采用自行搭建的拉曼高光谱成像装置(图1),由二维位移平台(BIOS-105T-304GS型,SIGMA KOKI,日本)、便携式拉曼光谱仪(课题组自主研发)和自行编写的集成控制软件组成。便携式拉曼光谱仪使用激发光源波长为785 nm,功率为100 mW的二极管激光器;CCD检测器为64×1 024像素阵列;波数范围为200~2 200 cm-1。在实验过程中,将采集区域设置为30 mm×30 mm,将二维位移平台步长设置为0.6 mm,单点积分时间为600 ms,以50×50的分辨率采集2 500个点拉曼光谱数据。因此,每个乳粉样品高光谱数据为50×50×1 024的数据立方体。
光谱数据处理采用Matlab R2016a软件进行计算。airPLS和mIRPLS的算法参考文献[20-21],通过相关算法的有机结合,巧妙地将未知掺杂物的筛查问题转化为奇异样本识别问题。
1.2 样品制备
建模样品:采用50个不同品牌、不同批次的市售脱脂奶粉构建正常光谱数据标准库,其蛋白质浓度均采用国标方法[22]进行测试。
验证样本:使用4组验证样品:①15个正常市售脱脂乳粉(阴性样本);②30个含有随机掺杂组分的乳粉(阳性样本);③尿素单掺杂样品15个,按照15个浓度梯度,以0.1%、0.2%、0.3%、0.4%、0.5%、0.7%、1.0%、1.5%、2.0%、2.5%、3.0%、3.5%、4.0%、4.5%、5.0%(质量分数)混合掺入脱脂乳粉中;④三聚氰胺单掺杂样品15个,浓度梯度同③。
掺杂样品③和④的制备:实验试剂为尿素(99%,生物技术级,麦克林)和三聚氰胺(99%,麦克林)。每个样品20 g,按0.1%、0.2%、0.3%、0.4%、0.5%、0.7%、1.0%、1.5%、2.0%、2.5%、3.0%、3.5%、4.0%、4.5%、5.0%(质量分数)加入掺杂物质和脱脂乳粉,使用上海沪西XW-80A涡流混合仪振动5 min混匀,以确保奶粉中掺假颗粒的均匀性。
1.3 RMD-RHIM原理与方法
乳粉是一种非均质复杂体系,其掺杂区域会破坏乳粉原有的关键组分特征分布,进而导致其拉曼高光谱信号产生畸变,破坏后续的多元建模过程。因此,本研究提出一种基于稳健建模驱动的拉曼高光谱成像技术(RMD-RHIM),借助稳健建模的奇异样本识别能力,准确找出畸变数据,将乳品掺杂区域映射为高光谱畸变像素点,在未知掺杂物种类的情况下,高效实现乳粉掺杂的非定向筛查[23-24]。该技术首先采用真实脱脂奶粉样品数据构建正常光谱标准库,同时采集单一的待测样品数据,共同组成动态的训练集样本。在此基础上,使用airPLS算法去除荧光干扰,拉平基线。然后,通过mIRPLS稳健建模算法,找出待测样品中的畸变像素点,并标记为“掺杂区域”,画出包含样品定位信息的二值图,从而得到待测样品的掺杂二值图像。具体流程如图2所示。
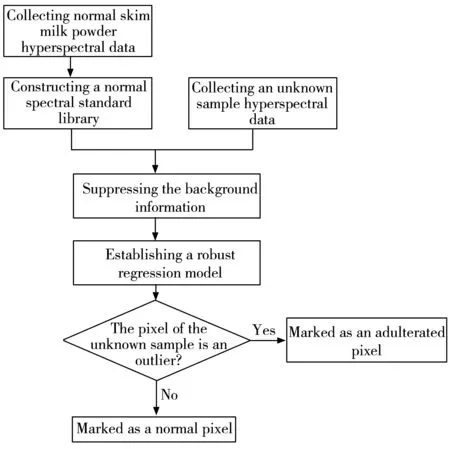
图2 基于稳健建模驱动的拉曼高光谱成像方法流程图Fig.2 Flowchart of the robust model driven Raman hyperspectral imaging method(RMD-RHIM)
1.3.1 光谱预处理脱脂乳粉是有机样品,其原始拉曼光谱具有强烈的荧光背景,严重影响后续模型的建立,需提前扣除,且高光谱数据量大,需要相关预处理算法具有快的处理速度。本研究采用自适应迭代重加权惩罚最小二乘算法(airPLS)[20],通过连续多次调用加权惩罚最小二乘算法,拟合出荧光背景的平滑曲线,并将其扣除。由于airPLS算法运用稀疏矩阵技术,其运算速度仅与信号的长度呈线性关系,处理速度快。因此,适用于本研究中拉曼高光谱数据的基线校正。
1.3.2 稳健建模算法本研究采用的稳健建模算法是改进的迭代重加权PLS(Modified iterative reweighted PLS,mIRPLS)算法[21],该算法通过检测删除了光谱变量中多个畸变点,构造出可靠的PLS模型。在mIRPLS中,使用了自适应的调整参数,当第i个样本(1≤i≤n)的预测误差超过训练集样本浓度[-3σi,3σi]的范围,则视其为一个畸变点。其中,n是建模集样品的总数,σi是使用留一法n-1个样本的标准偏差,ri是第i个样本(1≤i≤n)的预测误差。其数学表达式为:
本研究将Φi=0的像素点标记为“掺假”,将Φi≠0的点标记为“正常”。
2 结果与讨论
2.1 光谱信号预处理
脱脂乳粉中蛋白质的荧光背景严重干扰模型建立,因此,采用airPLS算法对原始拉曼光谱进行预处理,以克服荧光背景干扰,光谱预处理结果见图3。正常脱脂乳粉的原始拉曼光谱出现了明显的基线漂移(实线),使用airPLS算法后(虚线),其基线平整,荧光背景被有效扣除,表明airPLS能有效克服拉曼光谱中荧光背景的干扰,为后续稳健建模分析奠定了良好的基础。
2.2 基于mIRPLS稳健建模驱动的可视化非定向筛查

图3 使用airPLS进行光谱预处理前后对比图Fig.3 Comparison of Raman spectra before and after airPLS
RMD-RHIM方法最重要的步骤是稳健模型的建立。本方法将50个建模样本的高光谱数据与待测样本高光谱数据输入mIRPLS稳健建模方法中建立模型。通过mIRPLS的畸变点检测功能,挑选出掺杂奶粉中畸变的拉曼高光谱像素点,标记为“掺杂”,其他像素点标记为“正常”,并最终转化为可视化的二值图像。
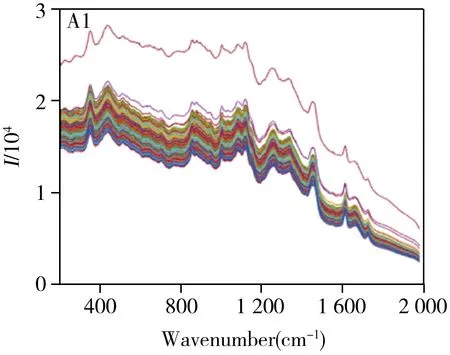
正常脱脂乳粉(阴性样本)、含有1.90%水解乳清(相当于5%蛋白质掺杂)的脱脂乳粉和含有0.91%三聚氰胺(相当于10%蛋白质掺杂)的脱脂乳粉的RMD-RHIM非定向筛查结果见图4。其中A1、B1和C1分别为三者的2 500个像素点的拉曼光谱数据,由图可见脱脂乳粉的荧光背景较强,需先使用airPLS方法去除基线背景,以显著提升后续稳健建模的可靠性。A2、B2和C2为经RMD-RHIM方法检测出的畸变点(深红色)并结合二维位移平台的定位信息画出的掺假成像二值图,其像素点的采样间隔为0.6 mm(30 mm范围内有50个像素点),以白色表示正常脱脂乳粉,红色表示掺假的畸变像素点。由图可见,当样品为正常脱脂乳粉(A2)时,掺假成像二值图为全白色,代表并无任何掺假物质的存在。而当样品为掺假样品时,二值图用深红色像素点表示出此为掺假样品,且显示出掺假物的分布情况(B2、C2)。由此可见,RMD-RHIM能以可视化的方式实现乳粉真伪的非定向筛查。
图4中B2和C2的掺杂像素点分布较为均匀,符合正常的乳粉掺杂分布模式,侧面证明了此成像方法的有效性。此外,B2为含有1.90%水解乳清的阳性样品,C2为含有0.91%三聚氰胺的阳性样品,单从掺杂物质的质量分数来看,B2的掺杂像素点应多于C2,但结果却恰恰相反。其原因在于,本研究使用的拉曼光谱仪的激光器的光斑远大于掺杂物质的颗粒,因此一个像素点并不代表一个掺杂颗粒。这可以由像素点的拉曼光谱图B1和C1证明,其光谱并非纯的掺杂物质信号,而是在纯乳粉拉曼光谱的基础上,叠加掺杂物光谱。乳清蛋白掺杂物不具有明显的特征峰,如图B1所示。反观图C1,部分像素点光谱的674.3 cm-1波数具有很尖锐的谱峰,这是三聚氰胺作为一种富氮类化合物所具有的明显特征尖峰,其相对纯乳粉光谱畸变明显。因此三聚氰胺颗粒即使占激光光斑面积的很小一部分,该像素点所采集的拉曼光谱也会发生明显畸变,进而被RMD-RHIM方法标记为掺杂像素点。因此出现了如B2和C2这种掺杂像素点个数与掺杂物质浓度不成比例的现象。由此可见,RMD-RHIM方法对含有尖锐谱峰的掺杂物更加灵敏。
2.3 RMD-RHIM方法效果评价
采用本方法对15个正常脱脂乳粉(阴性样本)的第1组验证样本和含有60个掺假样品(阳性样本)的第2、3、4组进行验证,计算方法的识别率,其计算公式如下:
识别率(Classification rate)=正确分类数量(Correct classification numbers)/样品总数(Numbers)
RMD-RHIM方法评价结果见表1。阴性样本的正确识别率为93.3%,阳性样本的正确识别率为98.3%,表明非定向筛查的准确识别率可满足实际工业需求。为进一步验证RMD-RHIM方法的检测灵敏度,分别采用含有0.1%~5.0%(质量分数)的尿素和三聚氰胺的掺假脱脂乳粉样品进行验证(Set 3、4)。发现其对尿素和三聚氰胺的检测灵敏度均达到0.1%,正确识别率为100%,完全满足乳粉真伪识别的需求。

表1 基于RMD-RHIM方法非定向筛查模型预测结果评价Table 1 Evaluation of prediction results of RMD-RHIM method
-:no data
3 结 论
本文提出了一种稳健建模驱动的拉曼高光谱成像方法,该方法借助拉曼高光谱成像技术,将乳粉中未知掺杂物的识别问题转化为拉曼高光谱信号的畸变处理问题;借助稳健建模方法,将畸变信号转化为奇异样本识别问题,进而巧妙地克服了定向筛查无法遍历所有掺杂物的问题。实验结果表明,RMD-RHIM能较准确地识别乳粉的阴性和阳性样本,以可视化的方式实现乳粉真伪的非定向筛查,并为其他食品体系的非定向筛查提供了一种新思路。
