短语音及易混淆语种识别改进系统
2019-10-21李卓茜刘俊南朱光旭
李卓茜,高 镇,王 化,刘俊南,朱光旭
(1. 天津大学 电气自动化与信息工程学院,天津 300072;2. 因诺微科技(天津)有限公司,天津 300392)
0 引言
语种识别技术能够根据给定语段判定语言的种类,在语音、语种、声纹识别、机器翻译、通信和信息检索等领域有较为广泛的应用[1],不仅为我们的生活带来了便利,同时也为不同民族和国家之间的沟通架起了桥梁。当前语种识别技术对长语段识别的准确率已经足够好,但对短语音(时长小于10s)及易混淆语种的识别还有待提升。短语音存在语段特征中有效数据不足、易受多种噪音干扰、无法充分表达语种信息等问题;而易混淆语种存在语音特征中差异信息较弱的问题。本文针对时长小于等于1s的短语音及易混淆语音的语种识别进行了研究。
语音特征的选取是影响语种识别准确率的关键因素之一。语音中包含着丰富的信息,按照从低到高的层次可依次划分为声学层、韵律层、音素层、词法层和句法层。语种识别主要采用声学特征和音素特征。声学特征为基础特征,主要描述语音信号的物理特性(如强度、频率)。常用的有基于人耳听觉模型的梅尔倒谱系数(mel-frequency cepstral coefficient, MFCC)特征、梅尔滤波器组(mel-scale filter bank, Fbank)特征和移位差分谱特征[2]。相比声学特征,音素特征能够更有效地利用上下文的相关性。常用的有移位差分音素对数似然比特征(shifted delta-phone log likelyhood ratio,SD-PLLR)[3-4]和深度瓶颈层特征(deep bottleneck feature,DBF)[5]。
语音特征建模对于识别结果同样至关重要,语种识别系统依据声学单元的统计差异对声学特征进行建模,依据不同语种间音素的搭配关系对音素特征进行建模。声学特征建模的常用方法有高斯混合-通用背景模型、高斯混合-支持向量机模型及全差异变量(total variability, TV)模型。其中,TV模型因对语段信息具有良好的低维表征能力而成为目前主流的声学建模方法[6-7]。音素特征建模的常用方法有音素识别器结合语言模型(phone recognizer followed by language model, PRLM),并行音素识别器集合语言模型(language recognizer followed by language model, PPRLM)和并行音素识别器结合支持向量机模型[8]。此外,近年来发展迅速的神经网络模型也被用于语音特征建模,包括针对声学特征后验概率建模的深度神经网络模型(deep neural network, DNN)、能够获取更好鲁棒性特征的卷积神经网络、能够更多考虑样本间关联性的循环神经网络以及具有一定动态记忆能力的长短时记忆网络[9]等。
本文围绕几种语音特征的对比和语种识别中TV模型的应用优化进行研究。全文安排如下: 第1节介绍SD-PLLR特征和DBF特征。第2节介绍DBF-I-VECTOR语种识别基线系统及改进系统,提出适用于短语音和易混淆识别任务的变速均衡数据方法,并对比不同分类模型的性能。第3节介绍实验设置、实验结果及分析。第4节总结全文,并对下一步工作进行展望。
1 语种识别中的语音特征
本节分别介绍SD-PLLR特征和DBF特征的原理及提取流程。
1.1 SD-PLLR特征原理及提取流程
SD-PLLR特征为音素识别器输出的帧级别特征。为了使识别出的音素尽可能均匀地覆盖测试集中的各语种,需选取一种独立于测试集语种的音素识别器。本研究主要针对东方语种,因而选取Buro科技大学研发的由英文数据训练得到的PhnRec[10]解码器。SD-PLLR特征的原理及具体的提取流程如下:
(1) 将音频输入音素识别器输出第t帧音素单元i的状态s对应的声学后验概率pi,s(t),累加音素对应状态的后验概率得到音素单元i的后验概率,如式(1)所示。
(2) 将第t帧中音素单元i的后验概率按照式(2)规整,将每帧得到的N个对数似然比率的值作为新的PLLR特征。其中,N对应英文音素识别器中音素的数量39。
(3) 对上述PLLR特征进行主成分分析[11],从而在保留原始信息的基础上得到更加准确且能量更加集中的13维新特征,然后进行移位差分操作[12]中所述过程对该特征进行移位差分操作,最终得到23维的SD-PLLR特征。
1.2 DBF原理及提取流程
神经网络具有良好的非线性表达能力。因此,从神经网络中较狭窄的一层中提取的特征可视为对底层输入声学特征的低维压缩表示,该特征称为DBF,是一种具有较好鲁棒性的语音特征。本文希望提取DBF的神经网络在多个语种上训练所得从而能够均衡地表征各语种音素信息,减少由于音素出现的频率差异造成最终提取的特征偏向个别语种。综合考虑语料资源、时间因素等问题,本文选取开源工具BUT[13]来提取DBF。
BUT提供了3个训练好的网络,本文使用基于IARPA BABEL项目提供的17个语种训练的网络。BUT可提取语音信号的DBF或者对应音素状态的后验概率,采用两级瓶颈神经网络堆叠的网络结构(如图1所示)。每级瓶颈网络从输入到输出共6层,其中瓶颈层的维度为80,其余隐藏层维度为1 500。第一级网络的输入为11帧的Fbank加基频特征。对第一级网络的输出进行t-10,t-5,t,t+5,t+10(其中t为当前帧)形式的采样作为第二级神经网络的输入,从而获取到更广泛的上下文信息。第二层网络输出的瓶颈特征作为最终提取的DBF。
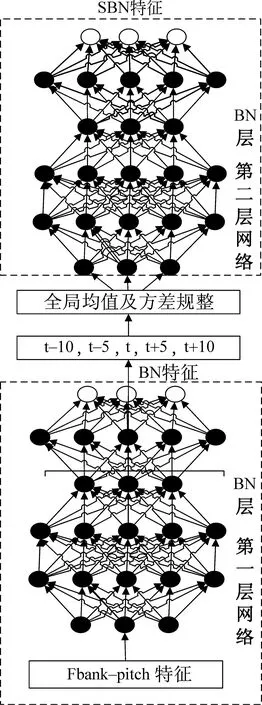
图1 DBF提取器网络结构图
2 DBF-I-VECTOR基线系统及改进系统
为提升短语音和易混淆语种识别准确率,本文针对DBF-I-VECTOR基线系统前端数据准备和后端分类模型进行改进。前者使用变速均衡数据方法,后者使用支持向量机(support vector machine, SVM)、极端梯度提升(extreme gradient boosting,XGBoost)、随机森林(random forest, RF)算法替代传统的概率判别分析(probabilistic linear discriminant Analysis,PLDA)和余弦距离(cosine distance scoring,CDS)分类方法。下面首先介绍DBF-I-VECTOR基线系统,然后介绍实验训练集OLR-2017并详细介绍改进方法。
2.1 DBF-I-VECTOR语种识别基线系统
DBF-I-VECTOR语种识别基线系统如图2所示。首先,将训练和测试语音输入1.2节介绍的BUT提取器。然后,使用TV模型对DBF特征进行建模。

图2 DBF-I-VECTOR语种识别基线系统
2.2 DBF-I-VECTOR语种识别改进系统
2.2.1 OLR-2017数据集
本文的训练集为海天瑞声和清华大学联合举办的 “东方多语种识别竞赛(challenge-oriental language recognition challenge,OLR)”所提供的OLR-2017数据集。[14]该数据集采集了697名发音人的10万条语音,数据总量达到116小时。数据集包含十个语种,分别为汉语普通话、粤语、维吾尔语、哈萨克语、藏语、日语、韩语、俄语、越南语、印尼语。本文实验中统一选取OLR-2017数据集中的train和dev集合(共106 602句)为训练集。
2.2.2 变速均衡数据方法
2.1节中的基线系统存在如下三个问题: 1)由于训练数据集中各语种语段数量不均衡,会导致训练得到的I-VECTOR模型统计量参数偏向语段数量多的语种,影响整体识别准确率;2)短语音时长过短,语段中能提取到的有效信息非常有限,易受噪音、信道等外界干扰的影响,这会造成测试集与训练集语种的I-VECTOR向量匹配度降低,降低识别准确率;3)易混淆语种具有相似的语音特征。因此,从训练语料中获取的有效信息区分度有限。
本文拟使用均衡数据方法解决第一个问题。由于不同语速下同一特征向量所含信息有所不同,且语速的改变不会引入太多失真。所以,本文通过改变语段速度来扩充信息,从而解决后两个问题。综合考虑上述方案提出变速均衡数据方法,其流程如下:
(1) 若训练集中语种n的语段数量为xn,使用sox工具将各语段分别变速至0.9、1.1倍速,得到各语种变速数据集yn=xn+0.9倍速xn+1.1倍速xn。
(2) 以变速数据集yn中语段数量最多的14 470*3=43 410(训练集中藏语语段数量为14 470)为基准,计算藏语外的其余各语种变速数据集yn与43 410的语段数量差l,l=43 410-yn。
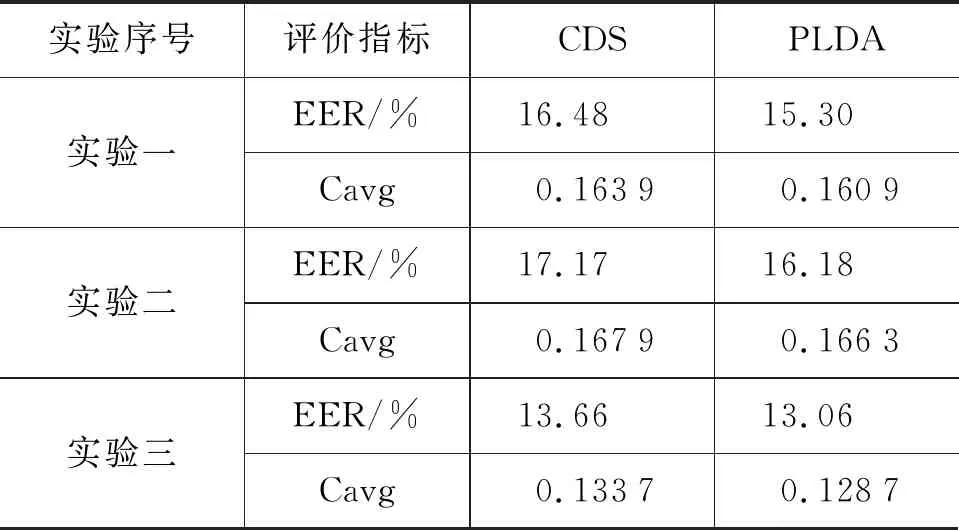
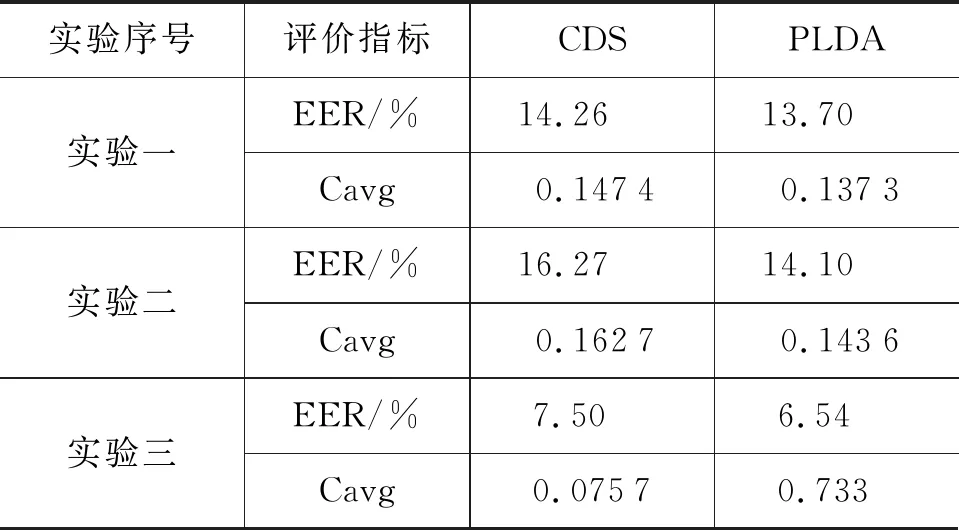
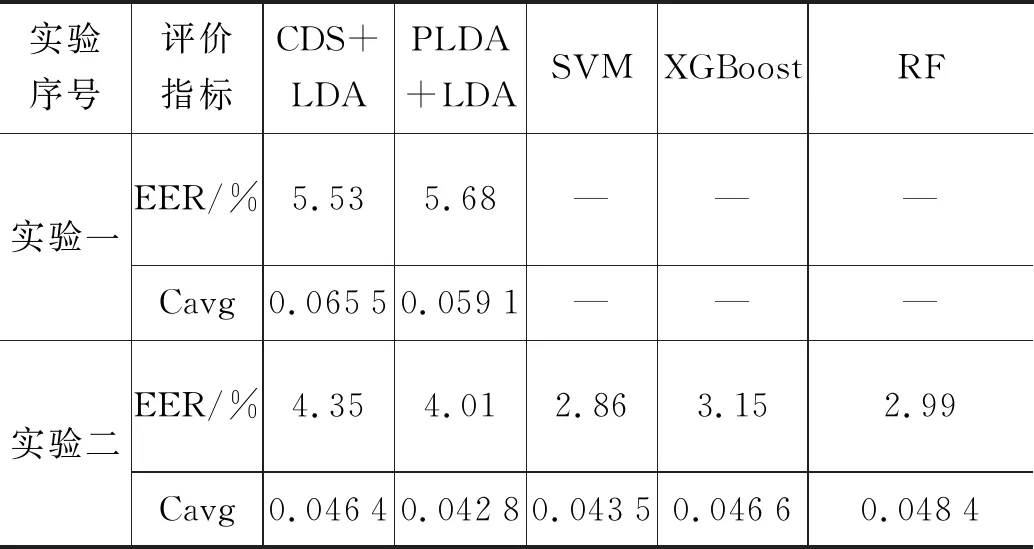
(3) 若l≤xn,则从xn中随机取l段音频,将其变0.8倍速得到0.8倍速l;若xn 该过程的流程图如图3所示。 图3 变速均衡数据流程图 2.2.3 改进的后端分类模型 基线系统后端采用传统的余弦距离打分CDS和PLDA[15]模型。CDS为判别式模型,该模型通过将测试语段I-VECTOR矢量和语种注册信息I-VECTOR矢量的余弦距离得分与阈值进行比较,从而判定测试语段所属语种的类别。PLDA属于生成式模型,能够对I-VECTOR语种识别系统进行信道增益优化。通过计算测试样本矢量和语种均值矢量来自同一模型及来自不同模型的对数似然比对语段所属语种类别进行判定。作为基于LDA[15]思想的概率扩展方法,PDLA方法具有一定的线性区分能力,相同条件下分类效果通常优于CDS。 生成式模型基于数据的统计分布反映同类数据的相似度,判别式模型则通过寻找不同类别间最优分类面反映异类数据的差异。传统的PLDA分类模型假设语种的先验概率和I-VECTOR的条件概率都是高斯分布,这种假设与实际情况不一定相符。而且,语种识别是一个区分目标语种和非目标语种的明确分类任务,采用相比CDS具有更好区分度的判别式模型将是一个更合理的选择[16-17]。 典型的判别式模型包括SVM、XGBoost和RF。下面对这几种算法的原理进行简单的介绍: (1) SVM算法[18] SVM算法使用非线性变换将低维的输入空间变换至高维,通过在高维空间中寻找最大分类间隔的分类面划分类别。语种识别系统中,将训练集语段的I-VECTOR作为输入,训练得到SVM模型,用于对测试语段进行分类。SVM算法中常用的核函数包括线性核函数、径像核函数、多项式核函数和sigmod核函数。该算法是语种识别领域一种常规的建模方法,在小数据集情况下依然具有良好的泛化能力。 (2) XGBoost算法[19] XGBoost算法使用了提升树模型,通过集成学习构架形成一个强分类器。其算法思想为:将给定的训练集训练得到k棵分类树集合;将输入样本按照属性值分割点划分到不同的对应实时分数的叶子节点;最终,通过对各棵分类树叶子节点预测分数加和确定最终的分类结果。该算法具备对稀疏数据的处理能力,相比神经网络具有可解释、易于调参等优点。又因其较高的运行效率和预测精度,在科学竞赛和工业界取得了较好的分类效果。 (3) Random Forest算法[20] RF与XGBoost算法同属于机器学习领域的集成算法,基本单元是决策树,相比于单个决策树来说具有更强的分类能力。该算法基于bagging思想: 每次从训练样本中等概率随机选取部分特征来构建决策树,每棵决策树相互独立,样本的最终分类结果由这些树的共同规则决定。对于一个输入样本、每棵决策树都会得到一个分类结果。最终输出的类别判定结果综合所有决策树的分类结果,将判定次数最多的类别做为输出类别。该算法具有较好的抗噪声能力、较高的灵活度、极好的准确率并能有效地运行在大数据集上。因而,在近几年国内外大赛如Kaggle数据科学竞赛、2014年阿里巴巴天池数据竞赛中被广泛使用。 使用2.2.2节的变速均衡数据方法和2.2.3节的判别式模型后得到的DBF-I-VECTOR语种识别改进系统如图4所示。 图4 DBF-I-VECTOR语种识别改进系统 本节首先介绍实验数据集,然后针对短语音和易混淆语音的语种识别任务,比较语音特征的性能及DBF-I-VECTOR基线系统与DBF-I-VECTOR改进系统的性能。 文中实验所采用的训练集为2.2.1节所述的OLR-2017数据集。测试数据集为短语音和易混淆数据集。其中,短语音测试集为OLR-2017[14]数据集中语段时长小于等于1s的test_1s(共22 051句)集合。由于2017年没有发布易混淆的测试任务,所以选取2018年发布的易混淆测试任务task_2(共7 357句)集合为本文的易混淆测试数据集。易混淆集合中,包含中文普通话、粤语和韩语。 该部分对比MFCC特征、SD-PLLR特征和DBF在短语音和易混淆语种识别中的性能。使用TV模型对上述特征建模,综合考虑识别准确度、计算复杂度、时间开销及存储空间的影响。实验中统一设置UBM的维度为512,I-VECTOR度为400。实验后端采用余弦距离打分(cosine distance scoring,CDS)、概率线性判别分析(probabilistic linear discriminant analysis, PLDA),各组实验设置如下: 实验一语音特征为常规的39维MFCC[21](13维MFCC +一阶Δ+二阶Δ)特征。 实验二语音特征为1.1节中提取的SD-PLLR特征。 实验三语音特征为1.2节中提取的DBF。 选取EER和平均代价(c-average,Cavg)作为实验结果的评价指标,对test_1s和task_2的实验结果分别如表1、表2所示。 表1 test_1s短语音语种识别特征对比 表2 task_2易混淆语音语种识别特征对比 基于表1和表2可得到如下结论: (1) 在短语音和易混淆语音语种识别中,MFCC特征优于SD-PLLR特征。这是由于解码音素序列的PhnRec解码器是由英文数据训练所得。解码器中,音素数量较少且训练解码器的网络结构相对简单,造成提取音素信息的能力有限、不能够突出语种间的差异和充分反映语段中的音素信息。若能够提升解码器中的音素数量或对网络结构有更好的改善则SD-PLLR特征的识别效果将会提升。 (2) 短语音语段时长过短,噪音对语段中有效信息的影响更大。而DBF具有抗噪性,因此其在语段时长极短情况下具有更好的表现。DBF在易混淆语种识别中性能远远优于MFCC和SD-PLLR,这是因为易混淆语段时长足够保证了能够提取到稳定信息。DBF作为基于音素层的信息比声学特征具有更好的区分度,因而有利于区分相似的语种。 该部分设置UBM的维度为512,I-VECTOR维度为400,测试集为test_1s和task_2, 选取EER和Cavg作为实验结果的评价指标,各组实验设置如下: 实验一2.1节中所述的DBF-I-VECTOR语种识别基线系统 实验二2.2节中所述的DBF-I-VECTOR语种识别改进系统。其中,各算法模型参数设置如下: SVM中的核函数为径像核(即高斯核),XGBoost算法中学习率设置为0.1,决策树个数为3 000,RF模型中子树的个数设置为3 000,模型中其它参数采用默认设置。 对test_1s和task_2的识别结果分别如表3和表4所示, 表3 基于短语音test_1s的语种识别系统对比 表4 基于易混淆task_2的语种识别系统对比 对比表3和表4中的实验一、实验二可知,单独使用变速均衡数据方法分别降低了短语音和易混淆语种识别的等错误率,该方法在提升两种任务的识别准确率上均有不错的效果。 由表3中实验二的结果可知,SVM分类性能优于LDA+CDS,但略差于LDA+PLDA。XGBoost和RF分类性能优于LDA+CDS和LDA+PLDA。由表4中实验二可知使用SVM、XGBoost、RF降低了CDS+LDA、PLDA+LDA的EER结果。综上可知,改进系统中的分类模型在两种任务中均具有较好的分类效果。 在短语音分类任务中RF算法获得了最好的分类性能。这是由于RF算法结合了多个基学习器的预测结果,从而改善了单个学习器的泛化能力和鲁棒性,是更适合多分类任务的分类模型。在易混淆语种的分类任务中,SVM分类结果最优。在上述分类模型中,CDS、PLDA训练速度较快,均在15分钟内完成了训练;RF分类器训练速度次之,大约需要40分钟,但其占用的存储空间较大;SVM分类方法的训练速度略快于XGBoost方法,需要大约3个小时;XGBoost由于每轮迭代产生的弱分类器都依赖上一轮的迭代结果,因而需要的训练时间最长,大约3个半小时。由上述结果可知,对于固定数据集样本的分类任务,判别式模型具有更好的区分性,能够提升识别的效果。这部分的实验结果验证了2.2节中的实验思路。 本文通过实验对比MFCC特征、SD-PLLR特征、DBF在不同测试任务中的表现,证明了DBF是语种识别中适合短语音和易混淆任务的较好语音特征,其在易混淆语种识别中表现出突出的性能。 为提升识别准确率,本文提出DBF-I-VECTOR语种识别改进系统。该系统中的变速均衡数据方法在两个语种识别任务中均能够有效提升识别结果。在短语音识别任务中,XGBoost、RF模型均超越传统的LDA+CDS、LDA+PLDA分类模型。其中,RF模型训练速度快且分类结果最优,是适合短语音多分类任务中的较好模型。在易混淆识别任务中SVM、XGBoost、RF均超越传统的LDA+CDS、LDA+PLDA分类模型。其中SVM分类结果最优,是适合此小数据集(易混淆测试集中只含3个语种,语段数较少)的分类模型。DBF-I-VECTOR改进系统相比基线DBF-I-VECTOR系统有效提升了识别结果。 后续工作将更多关注短语音和易混淆语种识别中语音特征及语种识别模型的改进、创新工作。值得一提的是,在对比引言所提到的PRLM、PPRLM、DBF-I-VECTOR、TDNN模型性能时,发现对短语音语种识别来说,PRLM、PPRLM模型均存在模型失配问题。EER打分结果较差,TDNN略逊色于DBF-I-VECTOR。更多有关语种识别模型的研究、创新工作将于后续工作中继续展开。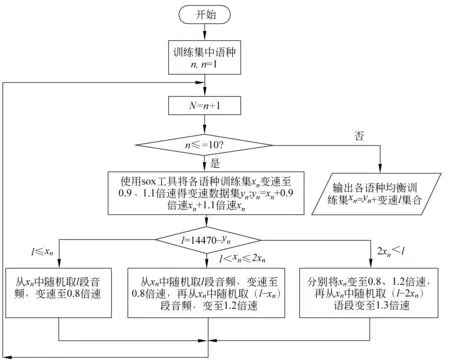

3 实验与分析
3.1 实验数据集
3.2 语音特征的对比
3.3 DBF-I-VECTOR基线系统与改进系统性能比对

4 总结及展望
