基于l1,2惩罚典型相关分析的特征选择
2019-10-21赵迎利王凯明肖玉柱宋学力
赵迎利 王凯明 肖玉柱 宋学力
(长安大学理学院 陕西 西安 710064)
0 引 言
从古至今,人们认识(学习)事物的渠道都是多样的。比如,对某疾病诊断,古代中医通过望、闻、问、切四种方式来了解患者;而现代的医生可以通过化验体液、B超、CT、核磁共振和脑电图等多种检查手段来采集患者的数据,以此了解患者的状况。以机器学习的观点,患者可以称为医生学习的一个样本,医生以不同方式采集到患者的数据称作样本的特征,不同的采集方式称为不同的模态。然而,高维特征的多模态数据中不可避免地会含有不相关和冗余的特征。事实上,在机器学习领域,这是一个普遍的现象。对于特定的学习任务,数据的真实维度[1]往往比采样数据的维度低得多[2]。所以,需要对样本特征的所在空间降维,防止维数灾难[3]或者过拟合。降维的方法大致可分为特征提取和特征选择两类。按照某种学习准则或者统计准则,最大可能地保留相关的特征,去除不相关或者冗余特征,这就是特征选择[4]问题。
特征选择的统计准则有很多,稀疏典型相关分析[5-6](Sparse canonical correlation analysis,SCCA)是一种通过提取具有最大相关性的典型相关变量,并且通过稀疏典型向量来实现特征选择的方法。 l1范数是稀疏典型向量的一种常用的具有凸性和连续性的正则化方法[7],文献[8]就是通过l1范数惩罚典型相关向量来实现特征选择。由于数据的群组信息是数据固有的系统机理信息或者满足某种统计信息的特征子集,所以在特征选择的任务里考虑特征的群组信息是必要而且重要的。为了在特征选择里兼顾数据的群组信息,文献[9]引入了l2,1范数惩罚的典型相关分析(CCA)模型,该惩罚对数据特征实现了组间稀疏。事实上,对于某些特定问题的数据,不仅不同的群组之间会有不相关或者冗余特征,而且组内往往也会存在不相关或者冗余特征,所以,特征的组内稀疏也是重要的甚至必要的。文献[10]发现了l1,2范数作为学习目标的正则约束可实现组内稀疏的作用。综上,无论l2,1还是l1,2约束,都需要数据的群组信息。当数据集中的群组信息未知或者不可用时,这种组间或者组内稀疏方法的应用会受到限制。文献[11]提出的特征随机分组方法,使得组信息缺失条件下的组内稀疏成为可能。所以,本文主要研究多模态高维数据的特征选择问题,应用l1,2范数兼顾群组信息作为稀疏惩罚项,通过优化数据之间的相关性来实现特征选择。
本文的主要思想有:1) 考虑数据的组内稀疏问题,选择向量的l1,2范数惩罚CCA;2) 对于组信息缺失的数据,应用随机分组方法产生组信息;3) 从应用的角度,这种方法可以更完整地选取相关特征,所以适用于对特征查全要求较高的实际问题,如某些恶性传染病或者肿瘤疾病的特征选择问题。
1 基础知识
1.1 典型相关分析
给定两个数据集X∈Rn×p、Y∈Rn×q,其中,X包含有n个样本、p个特征;Y包含有n个样本、q个特征。CCA[5]是以最大的相关性找到数据X和Y特征之间的典型相关变量,模型表示如下:
(1)
s.t.uTXTXu=1,vTYTYv=1
式中:u和v分别表示X和Y对应的典型向量。
1.2 惩罚项的提出
向量w=[w1,w2,…,wd]T∈Rd的l1,2范数可表示为[10]:
(2)
式中: 将w按分量分成G个组,wg表示第g个组。
基于此范数,构造本文优化目标所需的惩罚项P1、P2。
假设数据X按特征分为G组,对其典型向量u=[u1,u2,…,up]T构造惩罚项P1,表示为:
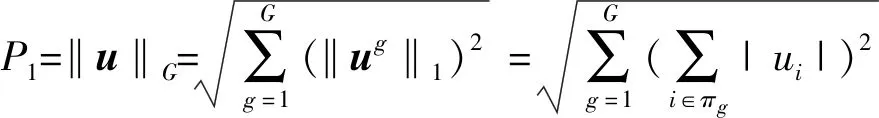
(3)
式中:πg是第g组的指标集。相应地,把数据集Y的特征分为H组,对应的v=[v1,v2,…,vq]T构造惩罚项P2,表示为:
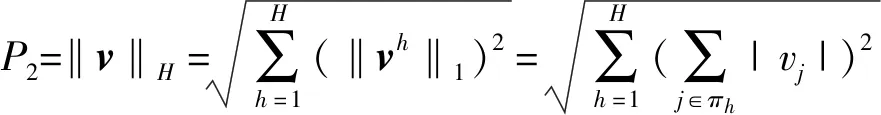
(4)
式中:πh是第h组的指标集。
1.3 模型的提出
本文针对数据组信息不全甚至缺失的特征选择问题,分别将数据X、Y按特征随机分成互不相交的G、H组并尽可能地让每组包含相同数目的特征,在典型相关分析的框架内引入惩罚项P1、P2,构造目标函数如下:
(5)
s.t.uTXTXu=1,vTXTXv=1
式中:ug和vh分别表示根据特征被随机分组后对应的第g组和第h组。
这样,我们通过正则项P1、P2惩罚X和Y的典型向量u、v,以及稀疏随机分组后的组内特征,实现携带组关联信息的特征选择。
1.4 模型的求解以及算法设计
由于大多数应用l1稀疏约束的正则优化问题都采用软阈值算法求解,而为了求解简便,都会假设特征之间正交,即XTX=I、YTY=I[12]。然而,在大多数真实数据中,这个假设是不合理的,因为特征之间往往不具有正交的特性。所以这个假设将会不可避免的限制识别有意义的关联信息。为了克服这个局限性,本文利用拉格朗日乘子法,采用交替最小二乘法解决这个优化问题。为了求解方便,将式(5)转化为如下等价形式:

(6)
s.t.uTXTXu=1,vTXTXv=1
首先对式(6)构造拉格朗日方程:
L(u,v,λ,β)=-uTXTYv+λ1‖u‖G+λ2‖v‖H+
(7)
式中:β1、β2为拉格朗日乘子,可利用交叉验证估计。 考虑到本文使用的惩罚项P1、P2中含有l1范数,如果|ui|=0、|vj|=0,则目标函数L在0点处不可微,可以通过分别给ui、vj加上一个很小的正数ξ来改善。
然后对u和v分别求偏导,利用极值存在的必要条件得到:
(8)
(9)
即:
(10)
(11)
最后求解式(10)和式(11)得到:
(12)
(13)
模型算法的伪代码如算法1所示。
算法1模型算法
Input:X=[x1,x2,…,xn]T,Y=[y1,y2,…,yn]T
Output: 典型变量u和v
1) 初始值t=0,ut,vt;
2) While not converged do
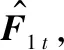
4) 固定vt,解ut+1;
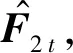
7) 固定ut+1,解vt+1;
9)t=t+1;
10) end while
11) 返回u和v的值
1.5 算法的收敛性分析
受文献[13]的启发,下面给出本文算法的收敛性分析。算法的目标的是求解式(6)的最小值,所以根据单调有界原理,算法的收敛性证明可转化为验证目标函数具有以下两个性质:1) 目标函数有下界;2) 目标函数单调递减。
首先验证目标函数有下界。为方便起见,在式(7)中,记:
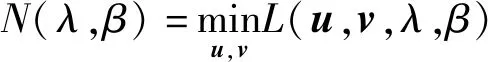
(14)
下面证明式(14)中函数N(λ,β)有下界。
根据式(6)和式(7)可知,显然N(λ,β)≤-uTXTYv。
分别对N中的β1、β2求偏导,有:
(15)
(16)
这表明: 1) 当u,v∈[-1,1]、-uTXTYv∈[-1,1];2) maxN(λ,β)=-uTXTYv。
令:
-uTXTYv
(17)
即N*∈[-1,1],即证得目标函数有下界。
然后验证目标函数单调递减。为了证明目标函数的单调递减性质,对向量w的l1,2范数引入如下引理。
引理1[10]:
(18)
式中:wt、w表示两个非零向量,wt表示w更新后的值,w、wt按分量分成G个组,wg、(wt)g表示第g个组中的部分分量。
利用引理1,把目标函数单调递减证明分为两步。
第一步,对于目标函数L(u,v,λ,β),固定v解u时,关于u的目标函数变为如下形式:
(19)
由引理1并且从算法的第8)步可得:
(20)
这就证明了第一步,L(ut,v)≤L(u,v)。
第二步,类似地,对于目标函数L(u,v,λ,β),固定ut解v时,同第一步证明,可得L(ut,vt)≤L(ut,v)。
综上,可以证明L(ut,vt)≤L(u,v),即算法在每次的迭代过程中,目标函数是单调递减的,所以由单调有界原理,模型的算法是收敛的。
2 模型仿真
2.1 构造模拟数据
为了验证算法的有效性和正确性,本文构造了一组模拟数据对算法进行测试。给定X、Y的样本数为80,特征数分别为100、120,模拟实验的数据集生成方法如下[14]:1) 预先设定数据集X、Y的结构,分别产生u和v;2) 生成潜在变量ξ~N(0,In×n);3) 生成数据X,其样本满足xi~N(ξiu,Σx), (Σx)pl=exp-|up-ul|,uρ、ul分别为u的第ρ、l个坐标;4) 生成数据集Y,其样本满足yi~N(ξiv,Σy),其中(Σy)pl=exp-|vp-vl|,vρ、vl分别为v的第ρ、l个坐标。将X中的特征随机分为10个不相交的组,将Y中的特征随机分为12个不相交的组。
2.2 参数选取
式(12)和式(13)中有四个可调参数,采用五折交叉验证,将所有的样本随机分成五份,其中四份作为训练集,剩余的一份样本作为测试集进行测试,从[10-2,10-1,100,101,102]中产生最优的参数。
2.3 评价标准
实验的评价标准为找到与真实相关系数最接近的一组,为了尽可能地减小因选择训练集与测试集的差异而对结果造成的影响,本文选择5次实验中训练集与测试集所得的相关系数之差最小的一组u和v作为最终的结果,具体形式为:
(21)
式中:corr表示Pearson相关系数,k表示交叉验证的次数(此处k=5),corrtrain=corr(Xtrainu,Ytrainv),Xtrain、Ytrain表示训练集,corrtest=corr(Xtestu,Ytestv),Xtest、Ytest表示测试集,u、v分别表示由训练集得到的典型向量。
2.4 实验结果与分析
本文对同一组数据集采用五折交叉验证的方法将基于l2范数和基于l2,1范数的典型相关分析的特征选 择方法与本文的方法作对比,分别得到三种方法下的每一折的相关系数与其对应的平均值对比表,分别关于典型变量u、v的实验效果对比图和估计的典型变量的AUC对比表,如表1所示。
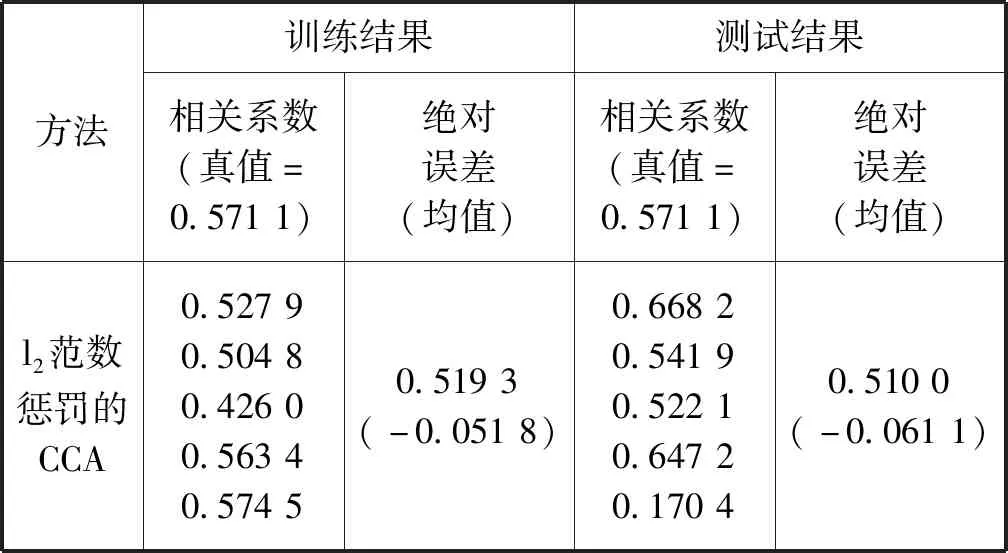
表1 模拟数据集上的五折交叉验证结果
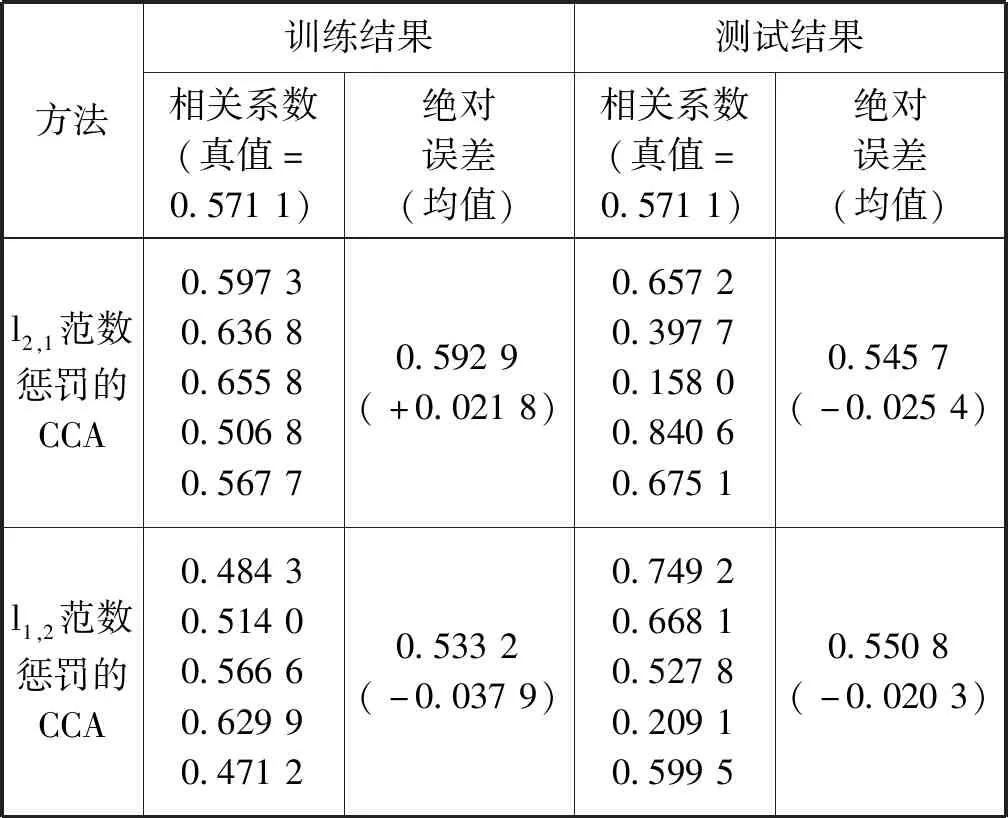
续表1
表1给出了三种方法下的五折交叉验证后训练集与测试集的相关系数的估计值。可以看出,在训练集上,基于l2,1范数特征选择的方法有较小的平均估计误差;但是在测试集上,基于l1,2范数特征选择的方法有较小的平均估计误差。一般而言,测试集上的结果比训练集上的结果更能体现模型的泛化性能[13]。
图1和图7给出了典型向量u、v设计的真实值(后均称为真实值)。图2和图8分别表示基于l2范数的特征选择方法得到的u和v。图3和图5分别表示基于l2,1范数和l1,2范数的特征选择方法应用随机分组得到的u。图9和图11分别表示基于l2,1范数和l1,2范数的特征选择方法应用随机分组得到的v。为了更清晰直观地展示实验效果,将图3、图5中的u和图9、图11中的v按照特征索引还原之后分别得到图4、图6和图10、图12。
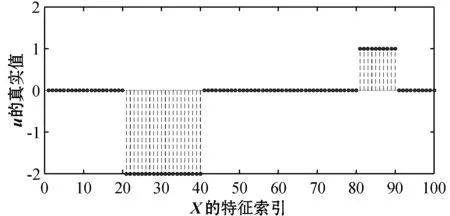
图1 典型向量u的真实值
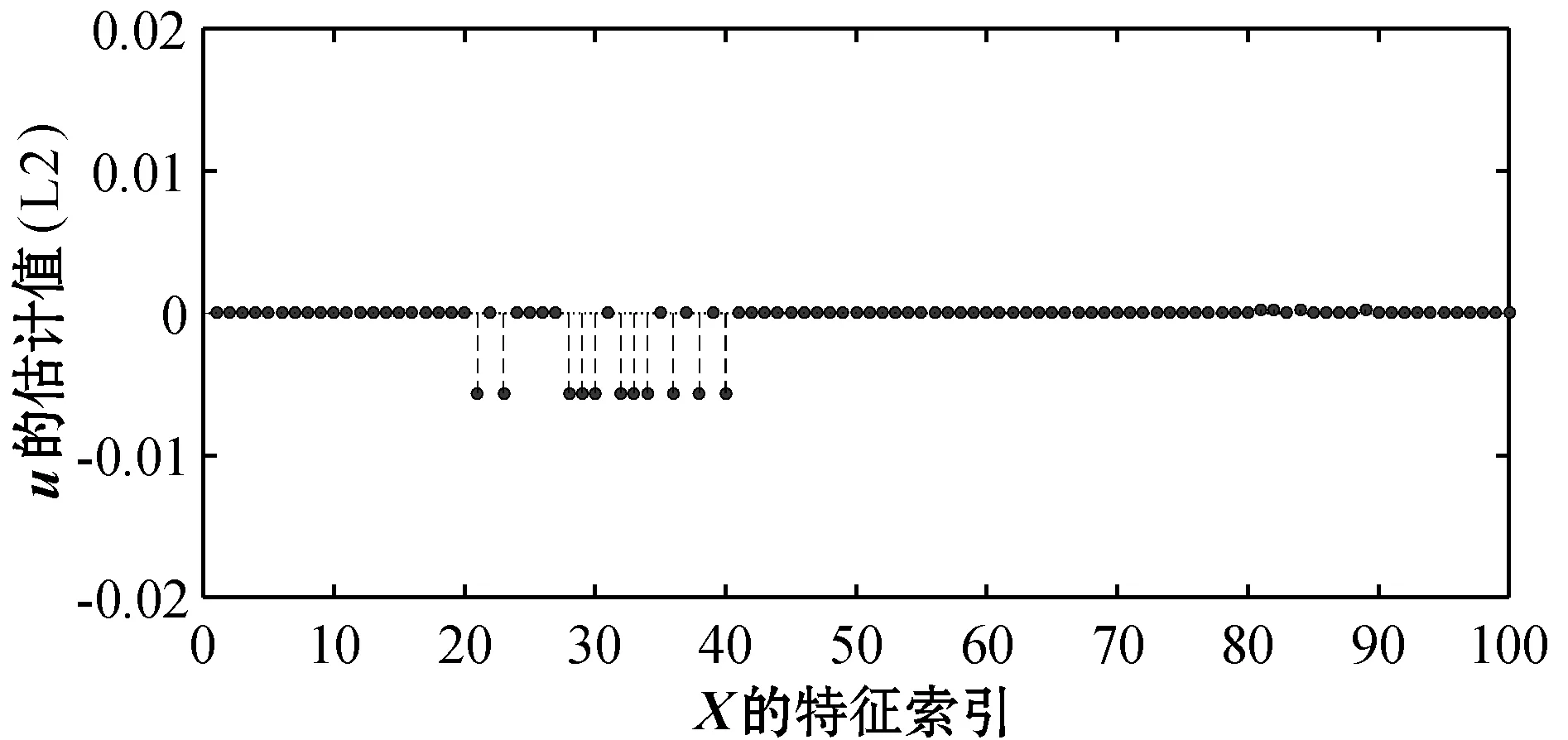
图2 l2惩罚下的典型向量u
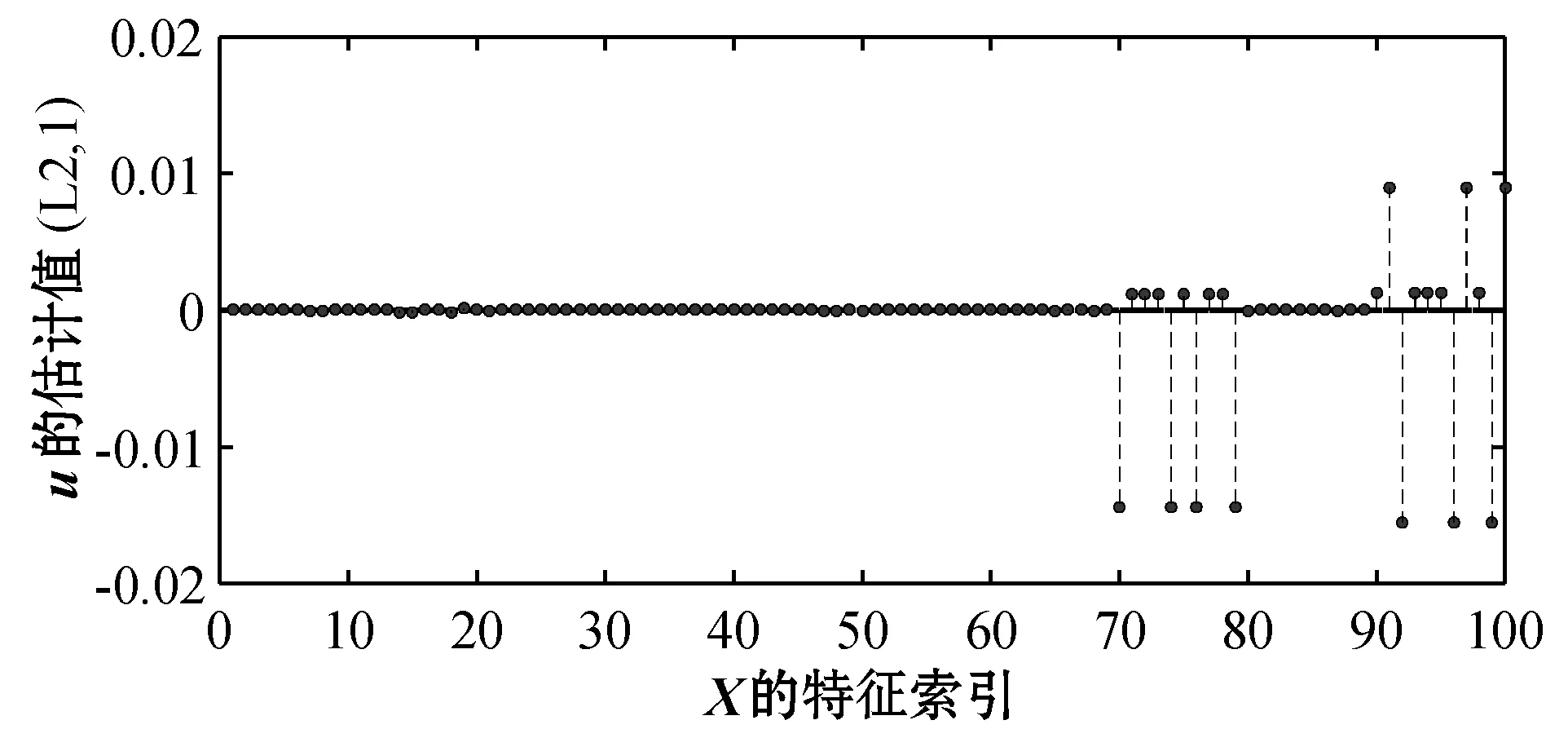
图3 随机分组后l2,1惩罚下的典型向量u

图4 随机分组l2,1惩罚下u的位置还原图

图5 随机分组后l1,2惩罚下的典型向量u

图8 l2惩罚下的典型向量v

图9 随机分组后l2,1惩罚下的典型向量v
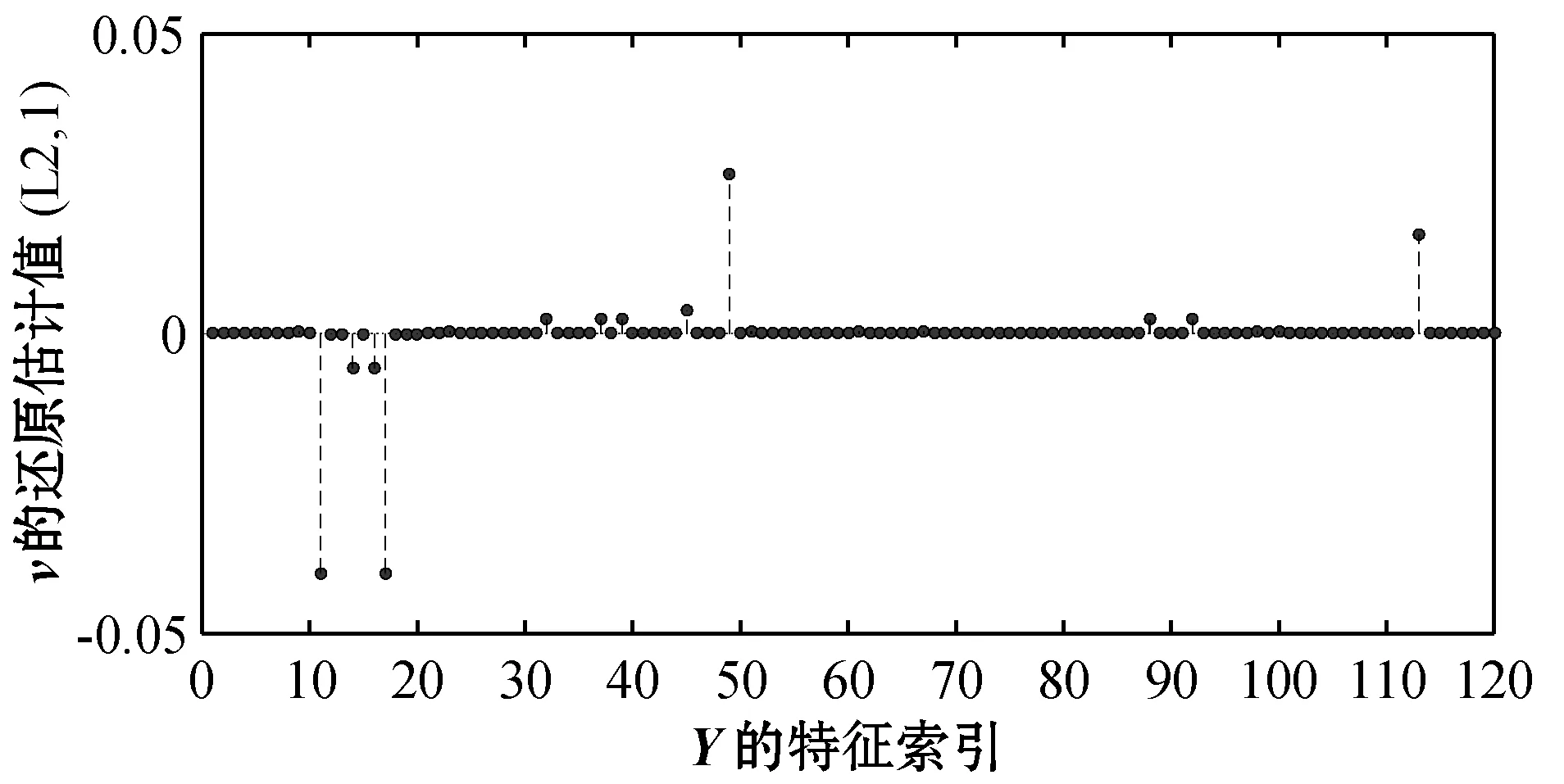
图10 随机分组后l2,1惩罚下v的位置还原图

图11 随机分组后l1,2惩罚下的典型向量v
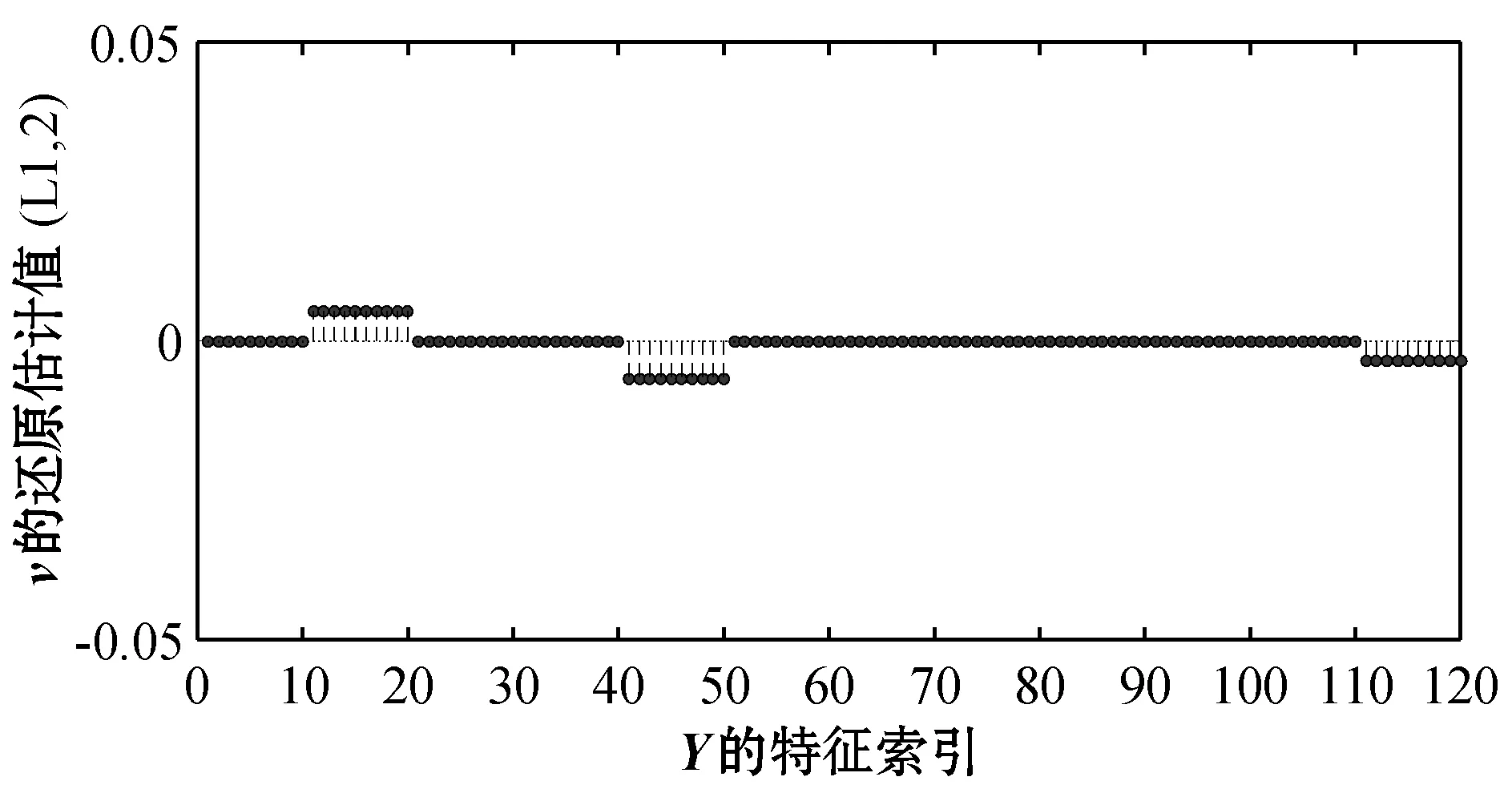
图12 随机分组后l1,2惩罚下v的位置还原图
从图2、图4与图1的对比中可以看出,基于l2范数和基于l2,1范数的特征选择的方法估计出的u的非零坐标位置与真实位置存在较大差异。具体的,在图1中可以看到20 表2给出了三种方法的典型变量的AUC(ROC曲线下方的面积),一般来说,AUC越大表明模型的预测性能越好。从表中可以看出基于l1,2范数特征选择的方法估计出的u和v的AUC明显大于基于l2范数和基于l2,1范数的特征选择方法估计出的u和v的AUC。 表2 三种方法估计的典型向量的AUC 实验结果表明,本文提出的基于l1,2范数典型相关分析的特征选择的方法不仅能够估计出两模态数据间精确的相关系数,而且在去掉不相关特征的同时能够准确识别出两模态数据中所有重要的特征。 本文提出了一种无先验组内稀疏典型相关的特征选择方法。通过将数据特征随机分成互不相交的组并尽可能地让每组包含相同数目的特征,以l1.2范数作为正则项惩罚CCA,对组内信息应用l1范数,组间信息应用l2范数,实现了关联特征的选择。模拟数据的实验表明,基于随机分组的组内稀疏特征选择模型选择的特征更加全面,漏选的特征更少,适用于某些恶性传染病或者肿瘤疾病的特征选择。 本文的方法对于两模态数据取得较好的效果,现实生活中也存在三模态甚至更多模态的数据,所以需扩展本文的模型至三模态甚至更高模态的模型,实现特征选择将是下一步研究的重点。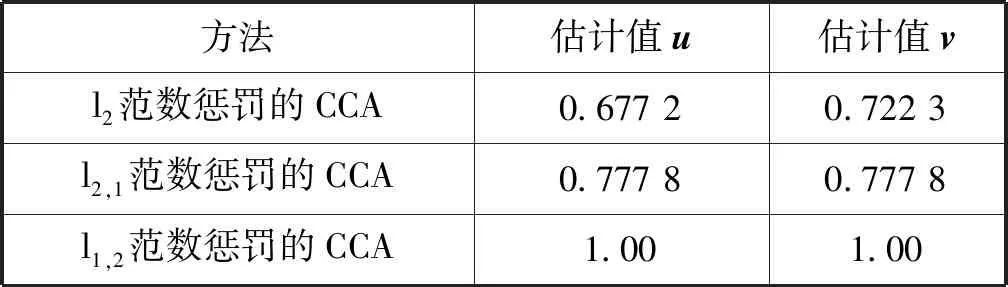
3 结 语
