基于中智模糊关联规则生成的大数据挖掘分析算法
2019-10-21梁凡赵丽
梁 凡 赵 丽
1(南宁职业技术学院信息工程学院 广西 南宁 530008)2(山西大学软件学院 山西 太原 030013)
0 引 言
随着数据库系统的大量建设与互联网技术的广泛应用,采用大数据挖掘技术对海量数据中蕴含的潜在价值进行分析逐步受到世界各国的高度重视,如商业、科技、健康、智能电网等[1]。大数据分析技术作为有效手段之一,可发现不同项目间潜在的未观察到的关联。关联规则挖掘[2]作为大数据分析中的一类技术,指采用某种算法发现不同项目间可能存在的关联或联系[3]。例如,文献[4]提出一种多尺度关联规则挖掘算法,实现了多尺度数据集之间知识的跨尺度推导,算法具有较高的覆盖率、精确度和较低的支持度估计误差。文献[5]针对动车组运维数据的数据量巨大、价值密度低的特点,提出了基于近似最小完美Hash函数的关联规则挖掘算法,算例结果表明,挖掘出的规则可以有效地指导动车组修程修制优化,从而达到提高动车组运维效率的目的。类似研究见文献[6-8]。但上述文献均建立在经典的布尔型关联规则基础上,即输出结果是0-1型的二进制数据。当应用经典的布尔型关联规则进行数据库定量分析时,会引入硬化数据“尖锐边界”问题。换言之,经典布尔型关联规则仅通过硬性的离散化划分策略可能破坏了不同项数据间存在的内在联系。针对传统布尔型关联规则挖掘算法存在的这一缺点,文献[9]提出一种顾及模糊属性的空间关联规则挖掘方法,结合模糊集理论,采用隶属度函数将模糊空间数据转化为由隶属度表征的模糊数值,进而将模糊空间属性化为模糊集合,最终提取出模糊关联规则。类似地,文献[10]提出一种基于时间衰减模型的模糊会话关联规则挖掘算法,同样基于模糊理论进行关联规则的模糊化挖掘。然而,现有的模糊关联规则挖掘方法在量化语言学术语时过多依赖于人工或专家经验进行划分,很少考虑到规则本身存在的不确定性,故导致很难以最优方式生成关联规则。
为解决现有关联规则挖掘方法中存在的缺点,提出了一种新型的中智关联规则挖掘算法,主要创新点为:
1) 针对传统布尔型挖掘算法硬性关联规则处理导致数据间联系被破坏的风险,将模糊理论引入关联规则挖掘模型中,从而提升数据间潜在联系的挖掘成功率。
2) 针对传统模糊关联规则挖掘算法存在的语言学术语量化预处理过度依赖人工经验的缺点,基于中智集合理论对传统模糊关联规则挖掘算法进行改进。不仅考虑了不同项间的隶属度函数,并且综合考虑关联规则自身不确定性以及项间的非隶属度函数,可更有效地实现关联规则的模糊化处理并发现所有可能存在的关联规则,有助于提升数据挖掘准确性。
1 关联规则挖掘模型相关知识
为便于后续分析,首先给出关于关联规则挖掘模型的基本术语与相关定义,随后建立基于模糊化的关联规则挖掘模型。
1.1 关联规则挖掘模型
令集合|D|为从一个给定数据集中挖掘得到的关联规则集合,相关定义如下:
1)I={i1,i2, …,im}表示所有可能的数据集合,其中元素称为项目(item)。
2) 资料库T表示来源于数据集I中进一步挖掘分析的数据集,满足T⊆I。
3) 对于给定的项目集X⊆I以及一个给定的资料库T,则T包含X当且仅当X⊆T。
4) 定义表示σX项集X的支持度(support frequency),其含义为项集X在整个数据集中出现的频率,公式如下:
(1)
5) 对于项集X、Y,X∩Y的可信度定义为同时包含X、Y的支持度与包含X的支持度之比:
(2)
6) 关联规则:一个形如X⟹Y的蕴含式,其中X⊆I、Y⊆I且X∩Y=φ。关联规则成立的条件是:① 资料库T中至少有s%的项包含X∪Y,即具有最小支持度s;② 在资料库T中包含X的项中最少有c%同时也包含Y,即具有最小可信度c。
关联规则挖掘问题本质上就是确定不同项集见支持度和可信度分别大于用户给定的最小支持度和最小可信度的关联规则(即强规则),具体包含以下两个子问题:
子问题1:找出资料库T中具有用户定义的最小支持度的项目集,并将其定义为频繁项目集,反之则成为非频繁项目集。
子问题2:利用频繁项目集生成关联规则。
1.2 模糊关联规则
关联规则挖掘作为数据挖掘的主要任务,其生成的关联规则表征了不同属性的项集间的联系。对于传统布尔型关联规则挖掘而言,其项目集的划分往往采用精确截断区间划分的方式。但此种方法存在过于硬化处理的弊端,如10.1和9.9在事实上是两个非常接近的数值,但在[1, 10)、[10, 20)的划分方式下则会分属于两个不同的项目集合,显然会导致与实际结果不符的情况。因此,模糊关联规则进一步地运用模糊理论对关联规则进行了改进,从而克服了传统布尔型关联规则生成算法对数据过于硬化的处理缺陷。
模糊关联规则挖掘的基本原理为:设资料库T={ti|i=1, 2, …,n},项目集合I={i1,i2, …,im},项目集合的每个元素ii对应一个模糊集合Lj={l1,l2, …,l|Lf|}(j=1, 2, …,m)。定义模糊项目集合为项目集合I中所有项目对应的模糊集所有成的集合,而模糊集的隶属度函数可由专家进行人为定义,记为fjk,下标满足:1≤j≤m,1≤k≤|Lf|,其实际意义为表征了项目元素ij隶属于资料库T的程度。例如,f12为项目i1所对应的模糊集合中第2个模糊项目的隶属度函数。故根据给出的模糊集隶属度函数,可将原资料库集合转换为模糊资料库T={t′1,t′2,…,t′n},且t′i= (f11,…,f1|L1|,…,fm1, …,fm|Lm|),i={1, 2, …,n}。与传统布尔型关联规则相比,模糊关联规则通过引入对数据的模糊化处理实现了划分边界的柔性过渡。
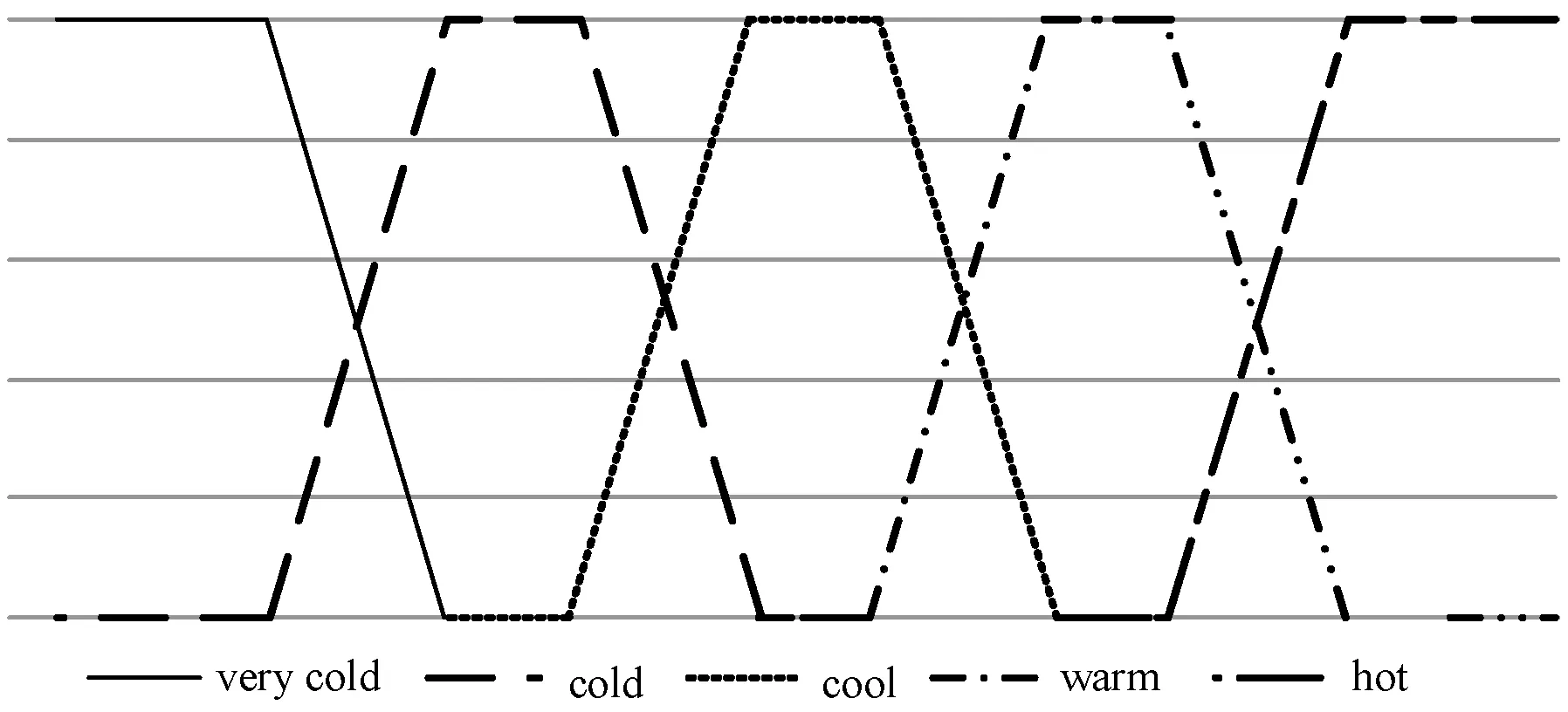
为更清晰地说明本文所提模糊关联规则生成方法,本文以温度相关的数据挖掘为例进行说明。在进行数据挖掘过程前,本文需对数据项进行预处理。其主要内容记为将语言学术语转换为具有量化的数值,并定义每个语言学术语对应的量化数值范围,此过程可基于专家知识进行。例如,表征温度的语言学术语{very cold,cold,cool,warm,hot}。进一步地,不同的表征温度的语言学术语的模糊化隶属度函数可按如表1所示的数据资料库进行计算,图1为响应的隶属度函数曲线。
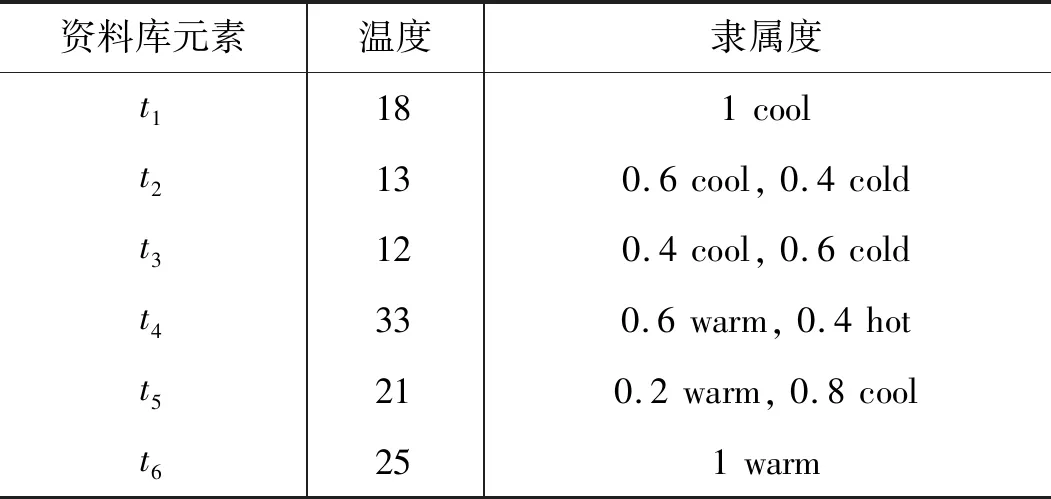
表1 数据库事务的隶属度函数

图1 表征温度的语言术语
将语言学术语{very cold,cold,cool,warm,hot}添加到候选集中,并计算这些项集的支持度,从而实现每个语言学术语的量化特征值,从而生成模糊候选集。依据2.1节中支持度的定义,本文可计算出单项集和多项集的支持度。同样以温度的单一指标和双重指标为例,支持度如表2和表3所示。后续内容中,将包含k个项目的项集表示为k-项集,并记集合L中的k-项集为Lk。
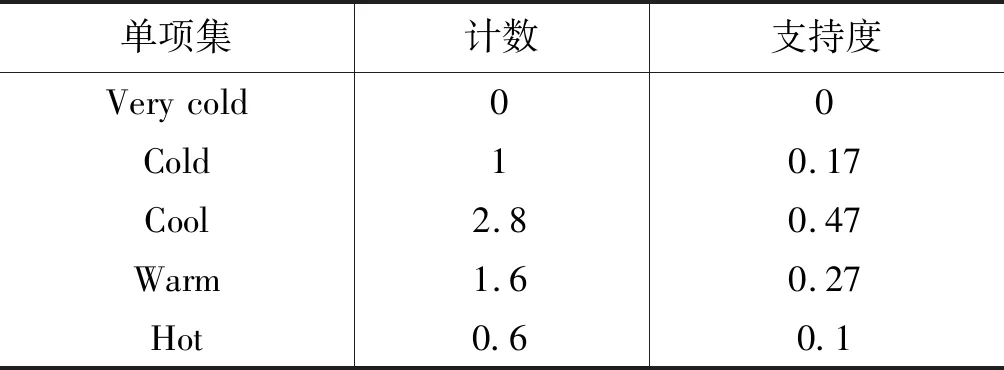
表2 单一项集的支持度

表3 两项集的支持度
2 中智模糊化关联规则挖掘模型
在经典的模糊关联规则模型中,隶属度函数的选择仍存在过于依赖人工经验的缺陷,即隶属度函数同样存在“硬化”的不足。此外,经典的模糊关联规则模型并未考虑到数据集自身存在的不确定性。上述两点将导致最后的挖掘结果可能因模糊隶属度函数的选择不同而出现偏差。中智学作为模糊理论的进一步发展,是模糊结合论、并行相容性集合论和直觉集合论的概括总结。因此,基于中智集合理论提出针对经典模糊关联规则挖掘的改进算法,其进一步将数据元素的不确定性考虑在内,有效克服了传统模糊理论的缺点。为此,首先给出中智集合的基本定理和运算规则,随后进一步建立基于中智模糊的关联规则挖掘模型[12-13]。
2.1 中智集合理论基本概念
中智集合理论中,设集合X为空间上的全集,而集合A是集合X的一个子集。而元素x∈X进一步表示为x(t,i,f),其中t、i、f分别表示元素x的真实性、不确定性和非真实性概率,且有t=T(x)、i=I(x)、f=F(x)成立。T、I、F分别为元素x的真隶属度、不确定性隶属度和非隶属度集合。根据文献[11]定义,其为|-0, 1+|的标准和非标准实数子集,其中|-0, 1+|表示非标准单位区间,-0=0-ε,1+=1+ε,其中“0”、“1”表示集合边界的标准值,而“ε”则表示不确定度(即非标准部分)且为无穷小正数。故T、I、F的上确界和下确界以及对应的模糊集合的上确界和下确界分别表示为:
SupT=tsupInfT=tinf
(3)
SupI=isupInfI=Iinf
(4)
SupF=fsupInfF=finf
(5)
nsup=tsup+isup+fsup
(6)
ninf=tinf+iinf+finf
(7)
-0≤SupT+SupI+SupF≤3+
(8)
进一步,文献[14]定义了单值中智集合的概念,以克服经典中智集合理论中对真隶属度、不确定性隶属度和非隶属度集合定义过于抽象不适合应用于实际工程中的缺陷。设X为论域,而集合X上的单值中智集合A具有如下形式:
A={
(9)
式中:TA(x):X→[0,1],IA(x):X→[0,1],FA(x):X→[0,1],从而对于所有x∈X,都有0≤TA(x)+IA(x)+FA(x)≤3 。区间TA(x)、IA(x)和FA(x)分别表示单值真隶属度、不确定隶属度和假隶属度函数。进一步将式(9)简记为A=(a,b,c),其中a,b,c∈[0, 1],且有a+b+c≤3。
2.2 中智集合的基本运算
1) 交集运算:对两个单值中智集合A=
2) 并集运算:对两个单值中智集合A=
3) 包含运算:中智集合A包含于另一个中智集合B,可表示为A⊆B,当且仅当对于所有x∈X,有TA(x)≤TB(x) 、IA(x)≤IB(x)且FA(x)≥FB(x)。
2.3 中智模糊化关联规则模型
提出的基于中智模糊化关联规则生成模型为:X→Y,其中X∩Y=∅,X、Y均为中智集合。本文目标为找到频繁集和相应的支持度,以及其相应的关联规则生成准则。结合2.2节中的模糊化关联规则定义,本文将中智集合添加到集合I中,集合I为所有可能的数据集(即项集)。具体操作为I=N∪M,其中N是中智集,M是经典项集。关联规则的一般形式为:
X→YX⊆I,Y⊆I,X∩Y=∅
上述中智模糊关联规则生成流程如图2所示。
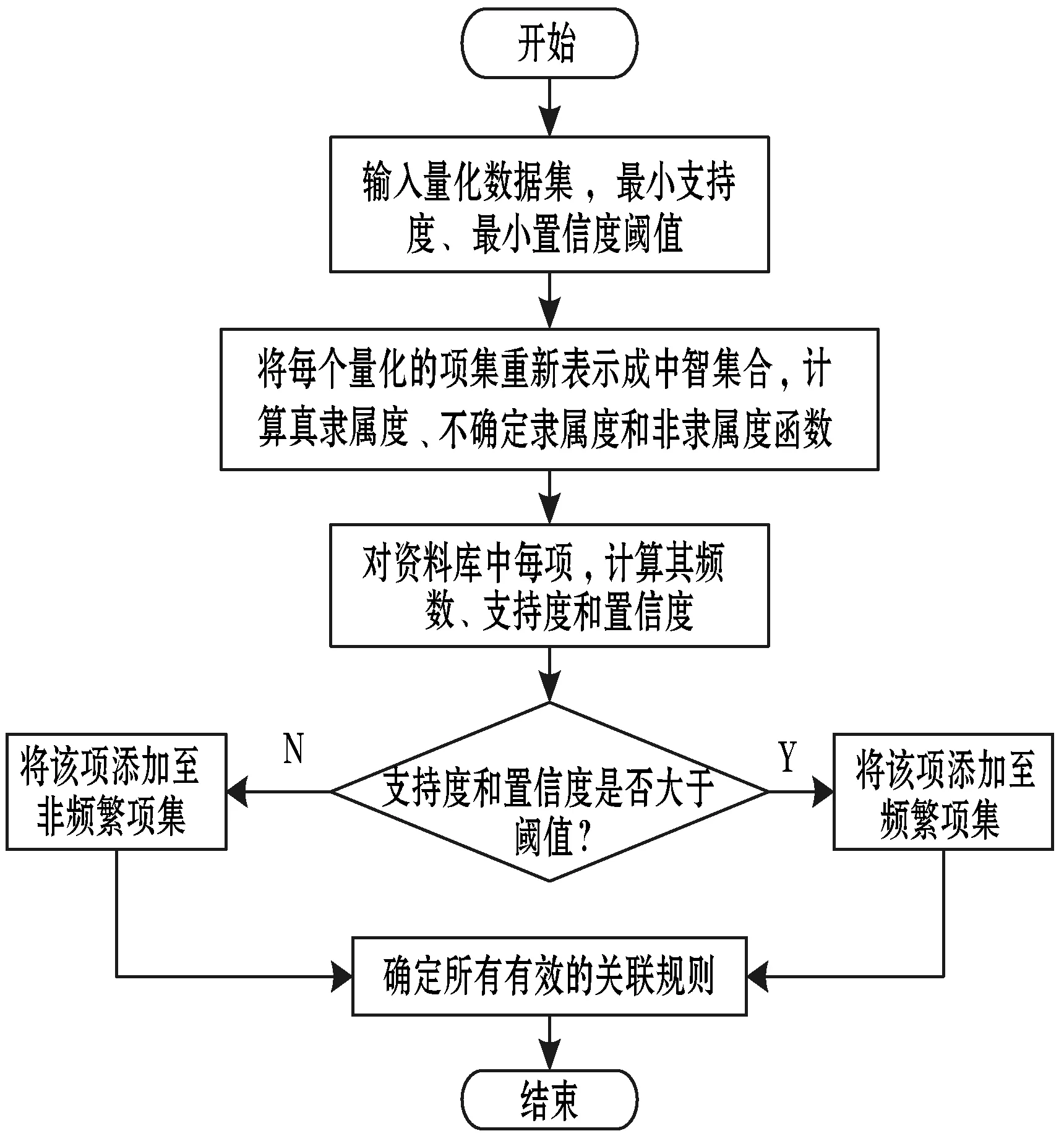
图2 中智模糊关联规则生成流程
同样以温度相关的关联规则挖掘为例说明本文的中智模糊关联规则建模流程。
Step1设置温度相关的语言学术语{very cold,cold,cool,warm,hot}的量化数值范围如表4所示。
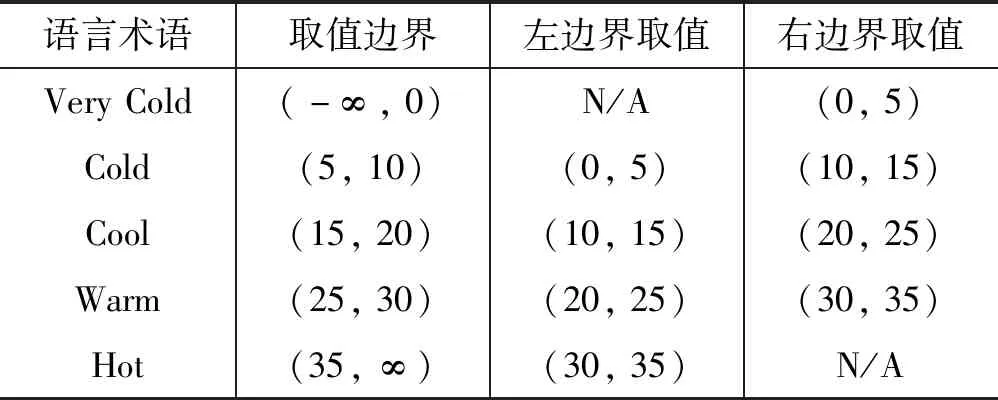
表4 语言术语的量化数值范围
Step2基于表4中量化的语言术语范围,定义温度的真隶属度、不确定隶属度和非隶属度函数。式(10)-式(14)为真隶属度函数,式(15)-式(19)为不确定隶属度函数,式(20)-式(24)为非隶属度函数。
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
图3为这些变量的真隶属度、不确定隶属度、非隶属度函数以及中智模糊化隶属度函数。
(a) 真隶属度函数

(b) 不确定隶属度函数
(c) 非隶属度函数
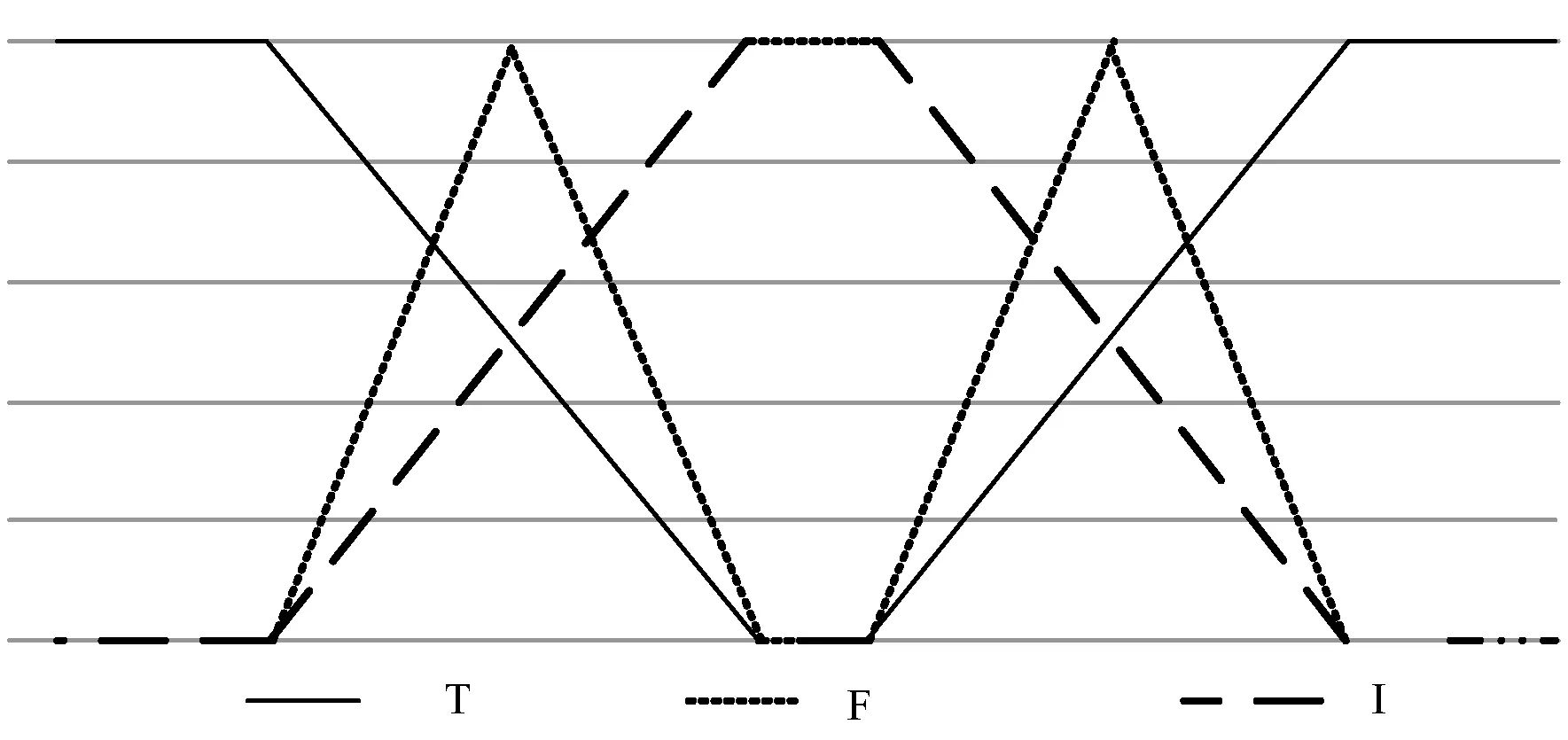
(d) 中智模糊化隶属度函数图3 隶属度函数波形
Step3基于隶属度函数数值,不同的项集被划分至不同的温度集合中,如表5所示。

表5 不同数据库事务的隶属度函数
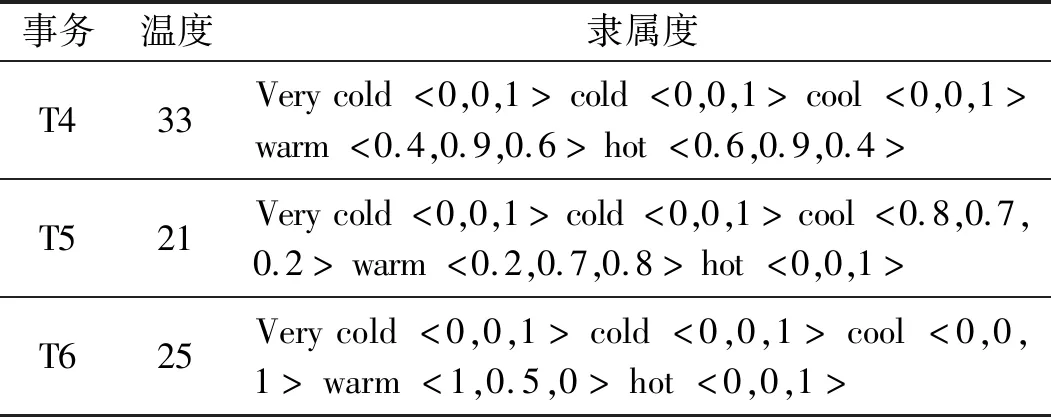
续表5
Step4计算资料库中每个元素的语言学术语集合{very cold, cold, cool, warm, hot}。由于真隶属度、假隶属度和不确定隶属度是独立的函数,所以语言学术语的集合可以扩展到{Tvery-cold,Tcold,Tcool,Twarm,Thot,Fvery-cold,Fcold,Fcool,Fwarm,Fhot,Ivery-cold,Icold,Icool,Iwarm,Ihot}。其中,Fwarm表示不温暖,而Iwarm表示不确定是否温暖。
Step5使用表5中给出的隶属度函数,分别计算单项集和两项集的频数和支持度,如表6、表7所示。
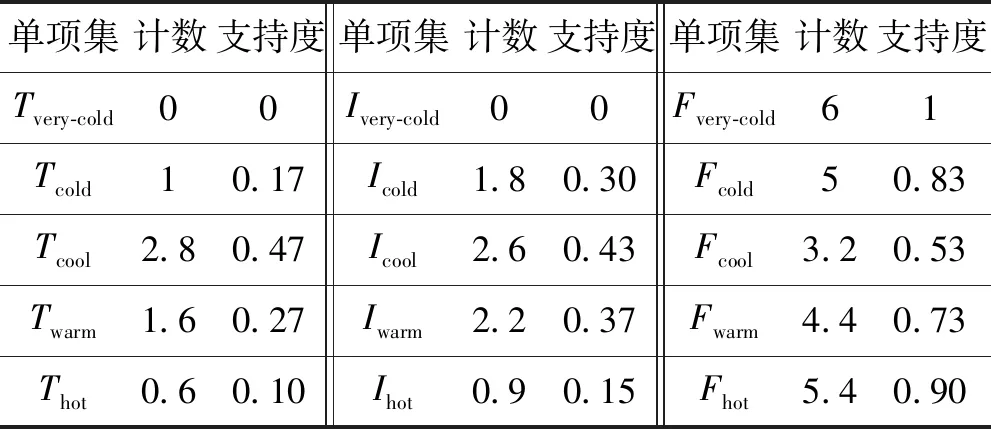
表6 单项集中智集的支持度

续表7
3 实 验
为说明所提方法的实际运行效果,在同样的实验条件下(计算机配置为Intel Core i5 CPU, 10 GB RAM, Windows 10 64位 旗舰版),并将其与文献[15]所提布尔型关联规则挖掘算法以及文献[16]所提传统模糊关联规则挖掘算法进行对比。实验程序统一采用VB.net进行编程。
3.1 实验数据预处理
股票交易市场的历史数据来源于2012年9月至2017年9月期间埃及股票市场。数据包含每只股票的开盘价、收盘价、最高价、最低价和成交量。本文以开盘价(openprice)与收盘价(closeprice)的差值比率定义股票的变化率(pricechangerate):
(25)
并定义股票成交比例如下:
(26)
此外,数据属性项包含季度、月度、股票变化率、成交率、指标变化率,表8表示了预处理后的部分数据。

表8 预处理后部分数据
根据上述语言学术语,基于单值中智集合定义对上述数据进行模糊化处理。本文将变化率模糊化处理为{“high up”,“high low”,“no change”,“low down”,“high down “},而对于成交量,模糊化处理为{“low”, “medium”, “high”},其对应的隶属度函数波形分别如图3、图4所示。
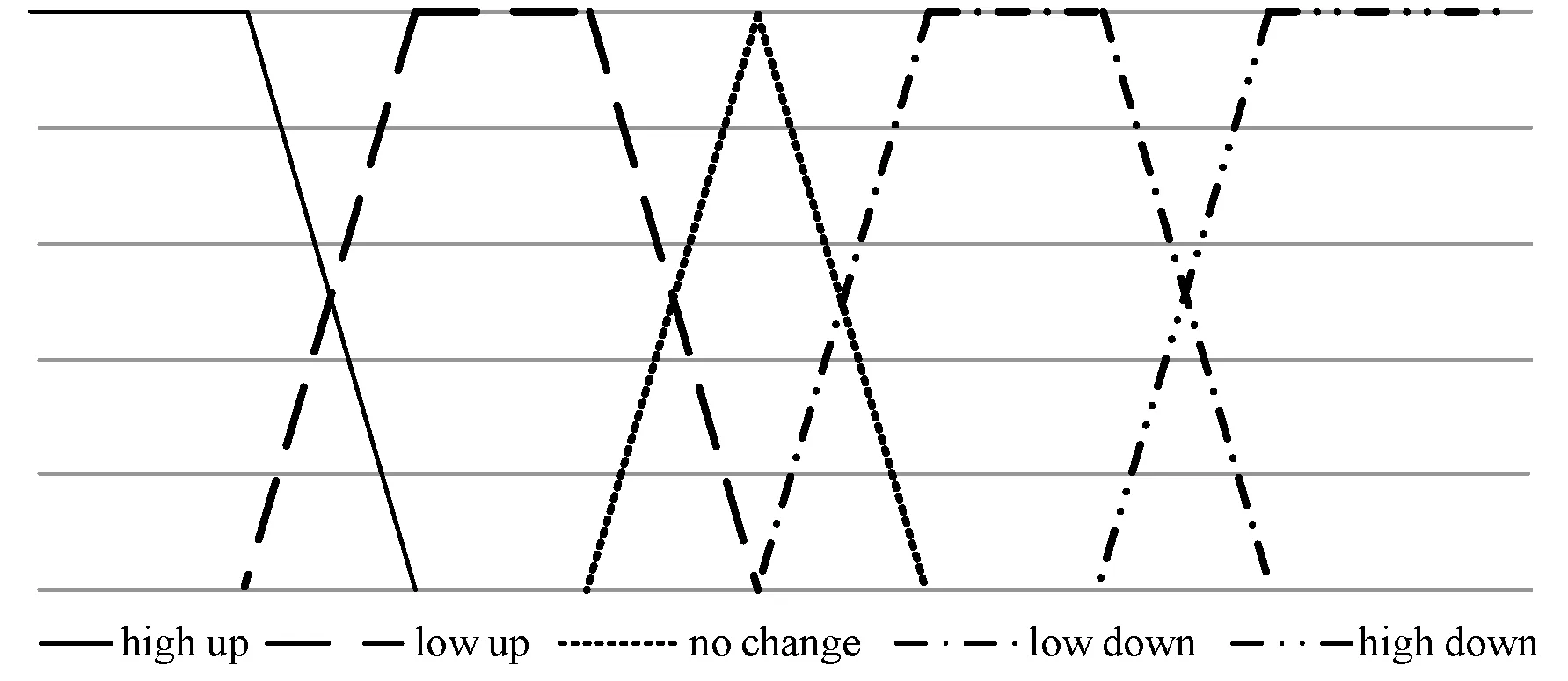
图3 变化率真隶属度函数
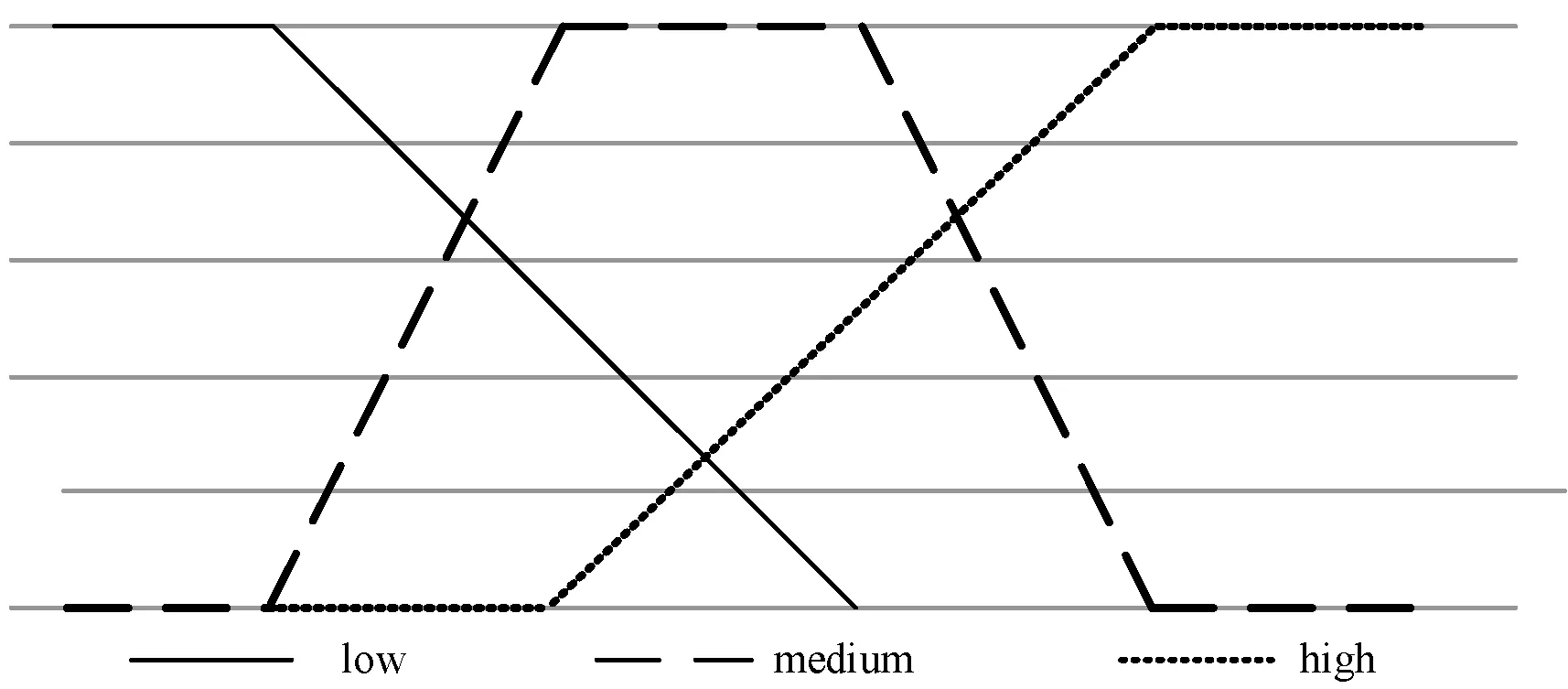
图4 成交量的真隶属度函数
3.2 实验结果
3.2.1生成关联项数量分析
基准实验中,设最小支持度为0.02,对比分析不同关联规则挖掘方法下生成的关联项数量。如表9所示,由于所提中智模糊化算法考虑了不确定性和非隶属度函数,故在关联项的数量上,应用所提中智模糊关联规则生成的关联项较布尔型算法布尔型算法提升了270%,而较文献[16]提出的传统模糊算法提升了142.9%。由此可见,本文方法能够显著挖掘出更多的潜在关联规则。

表9 关联项生成数量
3.2.2最小支持度对关联规则生成数量的影响
本节研究了最小支持度对不同挖掘算法所生成的关联规则的影响。图5、图6和图7分别为文献[15]提出的布尔型关联挖掘算法、文献[16]提出的模糊关联挖掘算法和本文所提中智模糊关联规则挖掘算法所生成的关联规则数量随项集数量的变化趋势。横向比较图5-图7,可发现随着最小值尺度阈值的升高,关联规则生成数量均处于下降状态,且随着项目集合的增多,二者下降速率均逐渐加快。而纵向比较可知,当最小支持度阈值设置较小且项目集合数量较低时,中智模糊关联规则挖掘算法的性能与文献[16]提出的模糊关联规则生成算法的性能相近,而文献[15]提出的布尔型挖掘算法由于生成关联数量较少,性能则较差。但当项目集合增多时,由于中智集合考虑了更多的隶属度函数,使得挖掘到的关联规则数量远大于文献[16]提出的模糊关联规则挖掘算法。

图5 文献[15]提出的布尔型关联规则生成数量随项集数量变化趋势
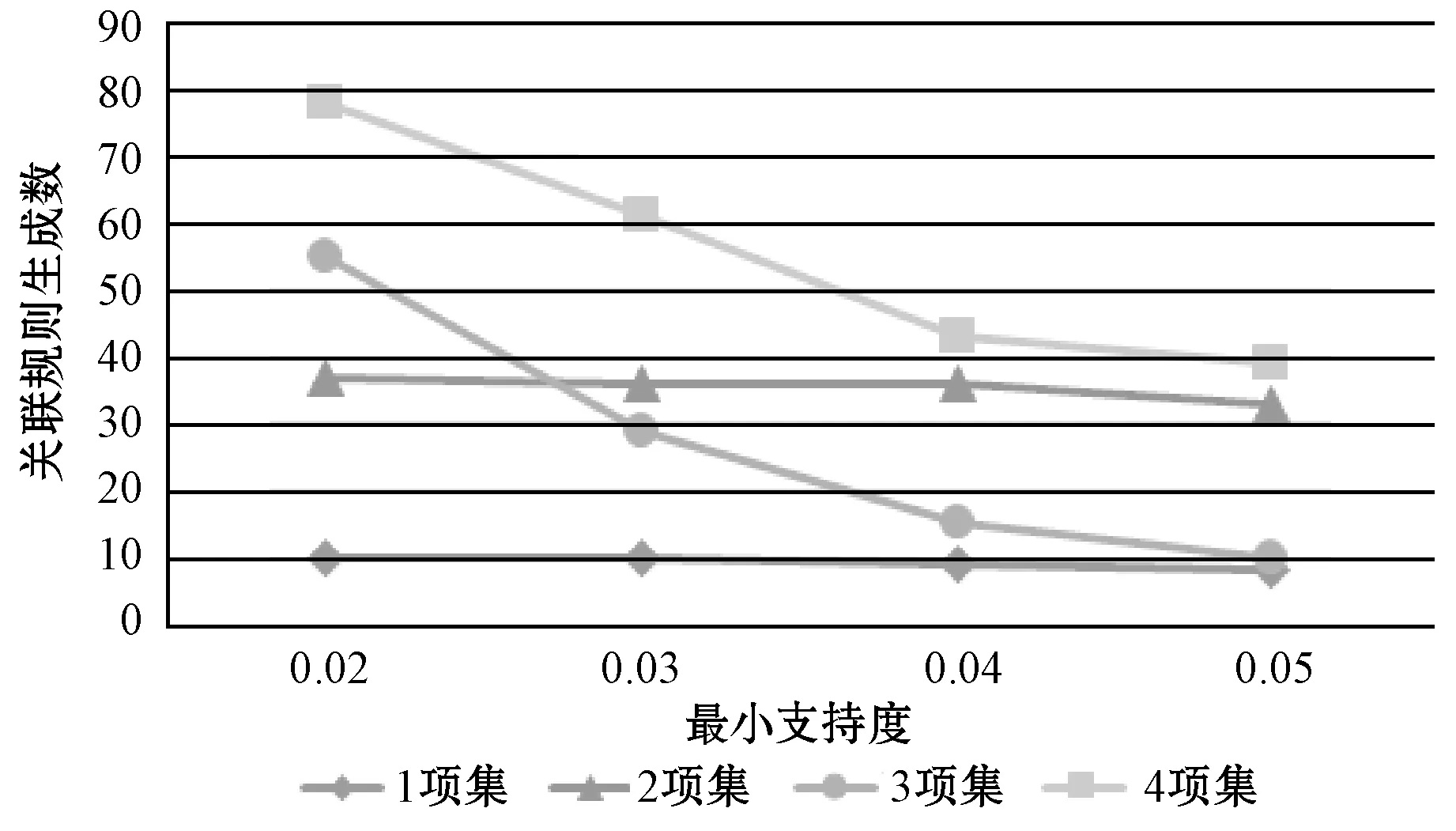
图6 文献[16]提出的模糊关联规则生成数量随项集数量变化趋势
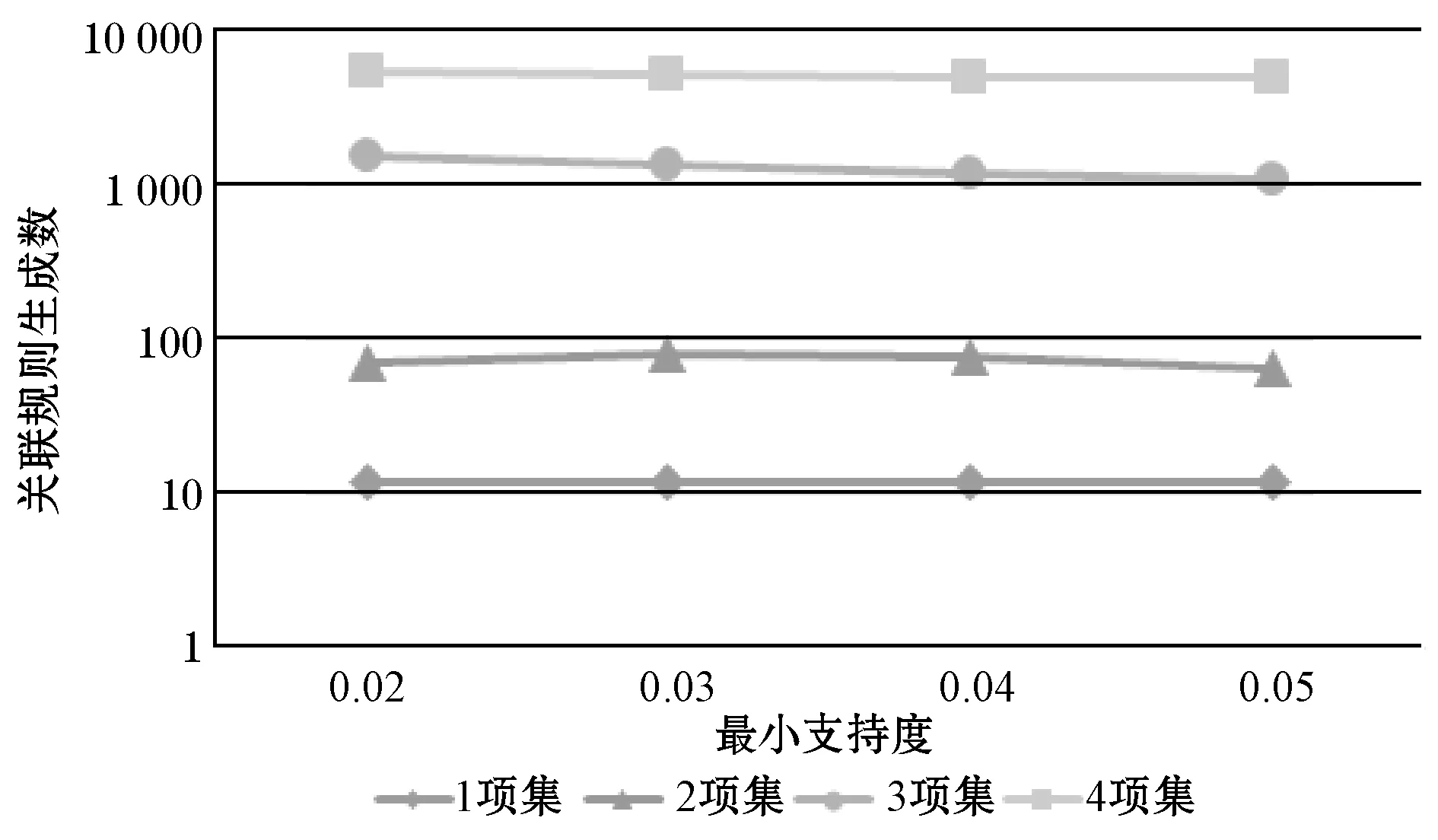
图7 中智模糊化关联规则生成数量随项集数量变化趋势
然而,中智模糊化方法虽然显著增大了关联规则数量,但过多的关联规则数量可能给用户带来信息误导的风险。因此,本文进一步研究最小支持度对本文所提中智模糊关联规则挖掘算法的性能算法。图8为最小支持度阈值从0.5到0.9变化时采用中智模糊关联规则生成算法所产生的关联规则数量与支持度和项集数量的变化趋势。

图8 中智规则数量随最小支持度变化关系
对比图7和图8可知,当采用本文所提中智模糊关联挖掘算法时,最小支持度大于50%时能够有效滤除过多生成的关联规则,得到和传统模糊关联规则挖掘算法相近的性能。
综上可得:1) 本文算法能够得到用户感兴趣的强关联、有价值的数据信息;2) 本文算法在挖掘得到的关联规则上的可信度要强于其他两种对比算法;3) 在算法中考虑更多的隶属度函数,有助于增加挖掘到的关联规则数量。
4 结 语
针对传统布尔型关联规则挖掘算法存在的硬化数据“尖锐边界”问题以及传统模糊关联规则挖掘算法未考虑关联规则的不确定性与非真实性问题,提出一种新型中智关联规则挖掘算法。通过实例分析表明,相比其他两种对比算法,本文算法在相同支持度时能够挖掘更多数量的关联规则,在多项集关联规则生成数量与可信度上具有明显优势,有助于提高数据挖掘的准确性。此外,算法考虑了更多的隶属度函数,有助于增加挖掘到的关联规则数量。后续研究工作中,将继续深入研究模糊边界设定值对生成关联规则数量的影响以及算法普适性研究。
