基于改进EAST 算法的电厂电气设备铭牌文字检测
2019-10-19孟健曾宪文高桂革
孟健,曾宪文,高桂革
(1.上海电机学院电子信息学院,上海201306;2.上海电机学院电气学院,上海201306)
0 引言
目前,电厂设备巡检主要依靠人工巡检,这种方法存在作业环境恶劣、劳动强度大、重复性高的问题,巡检机器人可以减少工作人员在高危环境下巡检作业的危险,提高巡检的质量和效率。巡检机器人装有视觉检测设备,在巡检过程中可以检测电厂电气设备铭牌文字,协助机器人进行场景理解[1]。
从场景中检测文字用来进行场景理解已经成为了计算机视觉任务的研究热点,主要分为传统方法和基于深度学习的方法。传统的文字检测算法依靠人工设计特征。文献[4]利用文字的局部对称性设计了不同特征检测文字区域。文献[5]采用关键点检测进行笔画提取,设计出一种快速的文字检测系统。但是在进行低分辨率和畸变图像的检测时,这些传统方法的准确性和适应性不如深度学习方法。文献[6]首次提出使用MSER(Maximally Stable Extremal Regions)搜索候选文字区域,然后使用深度卷积网络作为特征分类器删减错误的候选文字区域。文献[7]提出利用FCN(Fully Convolutional Network)生成热点图,然后利用投影进行文字方向估计。文献[8]将文本检测和文本识别整合在同一个网络中共同训练,共享卷积层,以提高整体性能。文献[9]提出一种新的文本检测器TextField 检测不规则文本。文献[10]提出一种端到端的文本检测方法,省去不必要的中间步骤,直接预测文本区域。但是这些方法都是在公共数据集上训练和测试,对于电厂环境下电气设备铭牌文字检测的准确率并不高,文中基于文献[10]提出一种改进EAST(Efficient and Accurate Scene Text Detector)算法的电厂电气设备铭牌文字检测方法,运用更深的网络进行特征提取和多尺度训练提高算法对不同尺度图像的泛化能力,然后运用平衡权重策略改进损失函数解决文字尺度不平衡的问题,环境适应性更强。
1 铭牌文字检测算法设计
1.1 EAST算法简介
EAST 算法是一种快速而准确的文本检测算法,该算法省去了不必要的中间步骤,直接预测文本区域。
(1)EAST 算法网络结构
EAST 算法的网络结构如图1 所示。
由图1 可知该网络分为特征提取分支、特征合并分支和输出层三个部分。
特征提取分支从VGG-16 网络的四组卷积层Conv1~Conv4 提取四组特征图f1、f2、f3、f4,其尺寸分别是输入图像尺寸的1/4、1/8、1/16、1/32。
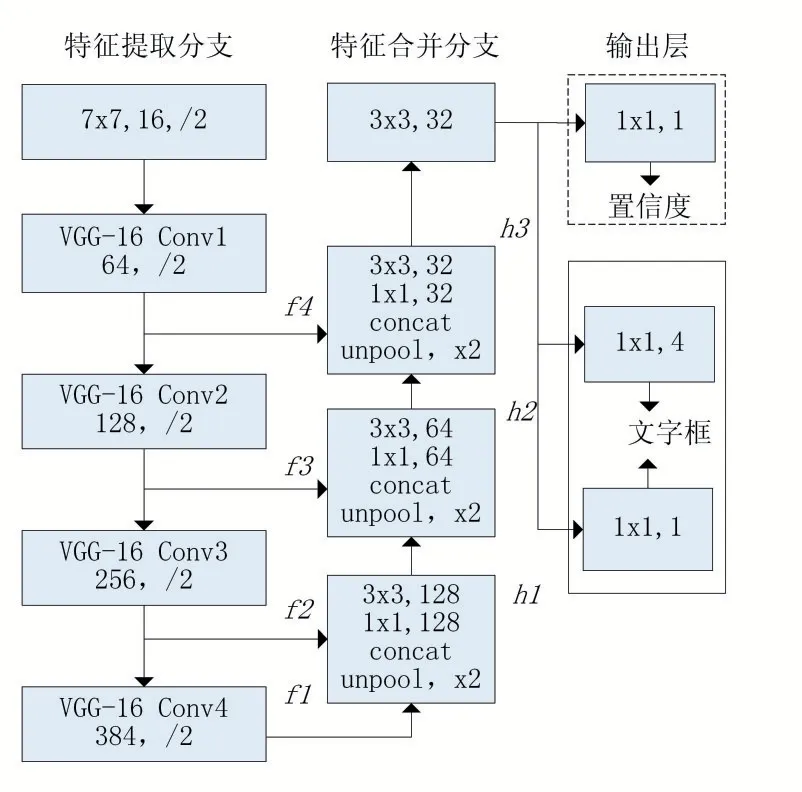
图1 EAST算法网络结构
特征合并分支逐层合并生成的四组特征图,合并过程中首先需要通过unpool 操作统一特征图的尺度,再通过concat 操作串联特征图,然后通过1×1 卷积层减少通道数量和计算量,最后利用3×3 卷积层将局部信息融合产生该合并阶段的输出。在最后一个合并阶段之后,使用3×3 的卷积核融合所有的特征并将其送到输出层。
输出层分为三个部分:置信度、文字区域和文字区域旋转角度。置信度由一个1×1 卷积核生成,其取值范围在[0,1]之间,表示该像素是文字像素的置信度,文字区域由四个1×1 卷积核生成,每个卷积核的值分别表示当前像素到包围文字的最小矩形框的上边界距离d1、右边界距离d2、下边界距离d3、左边界距离d4,文字区域旋转角度由一个1×1 卷积核生成,表示包围文字的最小矩形框的旋转角度。
(2)损失函数
原算法的损失函数定义如式(1):

其中,Lcls表示置信度的分类损失,Lreg表示该文字区域及文字区域旋转角度的回归损失。
分类损失的定义如式(2):

其中,Y*表示置信度真实值,表示置信度预测值。β是正负样本的平衡因子,定义如式(3):

回归损失的定义如式(4):

其中,Lgeo表示文字区域损失,Lθ表示文字区域旋转角度损失。

式(5)中R* Y*表示文字区域真实值,表示文字区域预测值。式(6)中θ*Y*表示文字区域旋转角度真实值表示文字区域旋转角度预测值。
1.2 改进EAST算法
(1)网络结构优化
原EAST 算法使用图像分类任务中的VGG-16 网络作为特征提取网络,由于网络的深度只有16 层,使用该网络检测的文字准确率不够高。
图像分类领域的研究表明,深层的神经网络能够提取更多的特征,提高检测的准确率[11]。文献[12]中的ResNet-50 网络将网络深度增加到50 层,并加入跳跃连接(Shortcut Connection)防止网络深度增加时出现梯度消失,在图像分类任务中该网络的表现优于VGG-16网络。为了提高电厂电气设备铭牌文字检测的准确性,文中引入ResNet-50 网络替代原算法中的VGG-16网络提取图像特征。改进EAST 算法的ResNet-50 特征提取分支参数如表1 所示,其中第一列表示该网络由五组卷积层Conv1~Conv5 组成,第二列表示每组卷积层包含的隐藏层层数,第三列表示每个隐藏层的卷积核结构,该结构由卷积核的数量长度、宽度表示,如Conv1 隐藏层的卷积核结构64×7×7 表示64 个长为7、宽为7 的卷积核。

表1 ResNet-50 特征提取分支
改进EAST 算法的网络架构如图2 所示。从图中可知,改进后的网络架构运用ResNet-50 网络代替VGG-16 网络提取特征,并取出Conv2~Conv5 的四组特征图f1、f2、f3、f4输入到特征合并分支,特征图尺寸分别是输入图像尺寸的1/4、1/8、1/16、1/32。
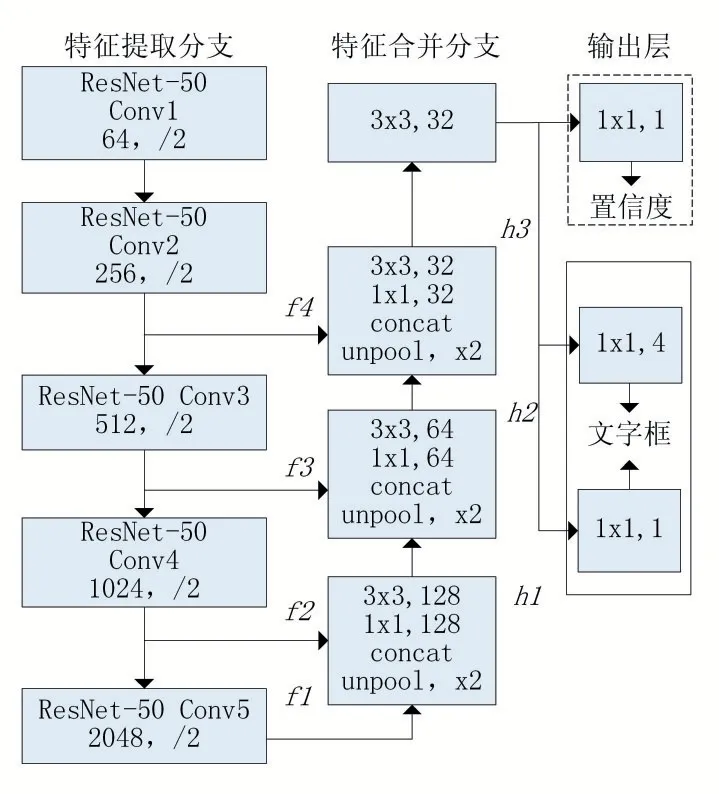
图2 改进EAST网络架构
(2)多尺度训练
实际电厂环境中铭牌文字受到拍摄距离的影响,不同尺度图像上的铭牌文字尺度差异大。在训练阶段,原EAST 算法使用固定尺度的图像进行训练,因此对于不同尺度的铭牌文字图像,该算法的泛化能力不高。文中采用多尺度训练方法,在训练阶段为每张图像设置224×224、512×512、720×720 三种不同的尺度,然后每张图像随机选择其中一种尺度组成多尺度图像训练集。实验证明多尺度训练能够提高算法对不同尺度图像铭牌文字检测的泛化能力。
(3)损失函数优化
EAST 算法使用交叉熵损失函数作为分类损失函数,但是该函数的收敛速度慢,训练过程消耗大量时间,因此为了加快收敛速度,文中引入图像分割任务中常用的Dice 系数损失函数作为分类损失函数[13],用来表示分数图预测值和真实值的相似度,如公式(7)所示。

式中|·|表示曼哈顿距离(L1 norm),Y*表示真实值,表示预测值。Dice 损失函数的取值范围为[0,1]。因为损失函数的值越小训练的效果越好,所以Ls为0 代表相似度高,Ls为1 代表相似度低。
图3 为改进EAST 算法和EAST 算法训练过程中的损失值曲线。图中可以看出两种算法在20000 次迭代前的损失值比较接近,经过80000 次迭代后,改进EAST 算法的损失值收敛到0.12 左右,EAST 算法的损失值收敛到0.25 左右。因此改进EAST 算法的收敛速度比EAST 的算法更快。
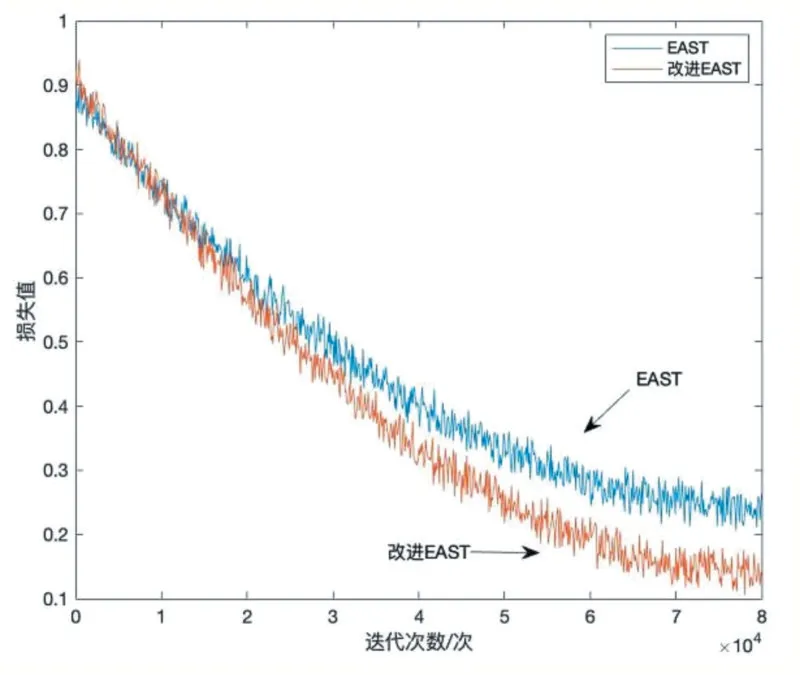
图3 损失值曲线
由于实际图像中文字尺度变化较大,尺度大文字在回归损失中的权重较大,导致尺度小的文字难以检测。因此文中运用平衡权重策略对文字区域损失Lgeo进行改进,使不同尺度的文字在Lgeo中的权重保持一致。具体来讲,对于一张包含N 个文字区域的图像,图像中任一像素p 满足公式(8):

其中,S 表示图像中所有文字像素的个数,Sp 表示包含像素p 的文字区域中文字像素的个数,p∈T 表示p是文字像素。当文字尺度较大时,权值会受到抑制,当文字尺度较小时,权值会变大,因此不同尺度的文字区域权重得到平衡。改进后的Lgeo如公式(9)所示:
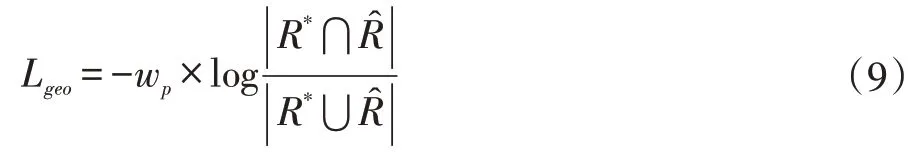
2 实验验证结果与分析
本实验在Ubuntu 系统上进行,使用的显卡为NVIDIA GTX 1080 Ti,内存为8G。
2.1 数据集
某电厂电气设备铭牌文字编码采用KKS 编码规范,语言为英文[14]。为了提高算法的泛化能力,本实验使用两个公开的标准数据集ICDAR2015 和COCOText 数据集预训练[15-16],这两个数据集图像是在室外随机拍摄的,包含水平和倾斜的英文文字,存在环境光的干扰,和该电厂场景类似。另外本实验采集了3000 张该电厂电气设备铭牌文字图像构成铭牌数据集,并且根据实验要求使用绿色方框对铭牌区域中的英文编码进行标注,如图4 所示。

图4 标注图片数据
2.2 模型训练
为了获得比较高的泛化能力,实验在ICDAR2015和COCO-Text 数据集上先进行训练获得预训练权重。为了加快训练速度,实验使用随机梯度下降法SGD(Stochastic Gradient Descent)进行优化,批训练数量为20,默认的动量为0.9,权重衰减系数为0.0005,初始学习速度为0.001,每20000 次迭代以后学习速度衰减为原来的十分之一,学习速度到0.000001 后不再衰减。
2.3 实验结果与分析
为了评估改进前后的算法对电气设备铭牌检测的有效性,实验使用准确率(precision)、检出率(recall)、F值(F-measure)评价算法的有效性。具体定义如公式(10)所示:

其中,TP、FP、FN 分别表示正确预测的文字区域数、错误预测的文字区域数和漏检的文字区域数。
(1)同场景对比改进前后检测效果
使用2000 张铭牌数据集图像对原EAST 算法和结合网络结构优化、多尺度训练和损失函数优化的EAST 算法进行训练,然后将训练好的模型在1000 张铭牌数据集图像(包含2065 个铭牌文字目标)进行测试。改进前后算法的效果对比如表2 所示。

表2 两种算法效果对比
从表2 可以看出改进EAST 算法在检测准确率上提高了6.1%,检出率上提高了7.7%,F 值提高了4.2%。图5 为实际电厂环境下的检测结果对比,图(b)可以看出改进EAST 算法能够准确检测出较多的英文和数字,而图(a)中EAST 算法容易出现漏检。实验证明改进EAST 算法性能优于EAST 算法。

图5 实际检测结果对比
(2)不同置信度阈值检测效果对比
检测的准确率和检出率与置信度阈值的选择有关,实验基于改进EAST 算法研究了置信度阈值对检测效果的影响。图6 展示了5 种置信度阈值下改进EAST 算法检测的准确率和检出率。

图6 不同置信度阈值对比
从图6 可以看出随着置信度阈值的增加,改进EAST 算法检测的准确率得到提高,但是由于高置信度情况下不考虑许多低置信度文字区域,检出率在不断降低。为了同时保证检测的准确率和检出率,使用综合指标F 值来选择置信度阈值,从图中可以看出置信度阈值为0.3 时F 值最大,因此置信度阈值选择0.3。
(3)不同优化方法检测效果对比
表3 列出了不同优化方法对检测效果的影响。由于增加了网络深度后能够提取更多的特征,方法2 比方法1 准确率提高了2.1%。由于多尺度训练增加了网络对不同尺寸图像的鲁棒性,方法3 比方法2 准确率提高了1.2%。方法3 和方法5 对比后发现,优化损失函数后的方法准确率提高了2.8%。实验证明三种优化方法均能提高算法的有效性。

表3 不同优化方法效果对比
(4)多场景检测效果
如图7 所示,实验测试了多场景下改进EAST 算法的检测效果。图7(a)、(b)、(c)、(d)分别展示了金属反光、透视、文字倾斜角度大、文字磨损条件下改进EAST 算法的检测效果。实验表明改进后的算法有较好的环境适应性。

图7 多场景检测结果
3 结语
本文提出一种基于改进EAST 算法的电厂电气设备铭牌文字检测方法,运用更深的网络进行特征提取,同时结合多尺度训练提高算法对不同尺度图像的泛化能力,然后运用平衡权重策略改进损失函数解决文字尺度不平衡的问题。实验验证了文中提出的算法具有检测准确性高、环境适应性强的优点,能够有效提高电气设备铭牌文字检测精度,具有一定的工程应用价值。
