大数据背景下数据分析类岗位的招聘特征挖掘
2019-10-19韦婷婷方宏宇宋世领骆威张建桃熊俊涛
韦婷婷,方宏宇,宋世领,骆威,张建桃,熊俊涛
(华南农业大学数学与信息学院,广州510642)
0 引言
随着大数据应用于各行各业,数据分析相关岗位的需求也越来越大。根据数联寻英发布的《大数据人才报告》显示,国内近几年大数据人才需求量巨大,众多大型企业的招聘名单里半数以上岗位都从属于数据分析类[1]。但是,目前学校这方面的人才培养,还满足不了社会的需要。作为人才培养的摇篮,高校应根据大数据发展对人才的需求特征,进行有针对性的培养计划。此外,目前针对数据分析岗位需求特征的研究比较少,仅有的少数研究对特征的分类则采用人工分类的方式,缺乏客观性[2],也难以为求职者提供有效的相关信息。为此,本文从各大主流招聘网站上爬取招聘信息,通过相关的数据挖掘技术实现了以下特征分析:基于TF-IDF 算法的各福利待遇权重计算;基于Kmeans 算法的数据分析岗位需求特征聚类分析;基于统计学知识的工作经验薪资统计图、需求特征词云图、数据分析岗位全国热力图。本文的研究成果将有助于高校相关专业有针对性地培养适应市场需求的人才,并为求职者的能力构建及就业选择提供参考依据。
1 数据获取与研究方法
1.1 数据获取
本文调研了国内多家招聘网站,综合考虑了数据抓取难度、数据量以及网站权威性等方面,最终选择拉勾网、智联招聘、猎聘网、前程无忧四个招聘网站作为本实验的数据源,部分示例数据如图1 所示。

图1 部分抓取数据
1.2 研究思路与方法
本文根据抓取数据各字段不同特点选取不同的分析方法。本文的研究思路主要分为以下六个步骤,如图2 所示。第一,选取数据源并实现招聘数据的抓取。第二,从抓取的网络文本集中选取结构化字段,直接进行词频统计。第三,实现以成段文本形式出现的福利待遇和职位描述字段的数据预处理。第四,统计福利待遇各关键词词频并计算其TF-IDF 值。第五,统计职位描述各关键词词频并实现职位描述字段各关键词的K-means 聚类分析。第六,以可视化的方式展示上述各实验结果并加以分析。
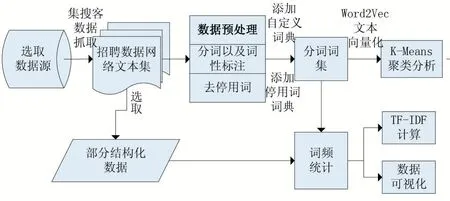
图2 实验流程设计
2 实验设计与实现
2.1 数据预处理
本文从各个数据字段中选取城市、薪资、工作经验、学历要求、福利待遇、职位描述字段进行数据预处理[3],具体流程如图3 所示。为防止专业短语在分词中被分解,本文抽取了相关的大量关键词短语添加到词库中,提高分析的准确性。

图3 数据预处理步骤
2.2 福利待遇TF-IDF权重计算
本文选择TF-IDF 算法计算某关键词对一个文件系统的重要程度[4]。其中TF 值代表词频,通常会做归一化处理。对于某一关键词ti来说其TF 值计算如公式(1)所示。

在上式中ni,j是某关键字词在文件集合中的出现频次,而分母nk,j则是在文件集合中进行中文分词后,所有词出现次数的总和[5]。IDF 值代表反文档频率,其计算公式如公式(2)所示。

其中|D|表示文本系统中文件的总数;|{j:ti∈di}|代表包含关键词的文件数目[6]。最后再计算该关键词的TF-IDF 值:tfidfi,j=tfi,j×idfi。
本文将福利待遇字段内容预处理后作为词频统计的输入,再根据词频统计结果计算各关键词的TF-IDF值并选择权重值前30 的关键词分析。此处将每个网站福利待遇字段内容存为一个文件,四个网站的福利待遇文件构成文件系统。
2.3 职位描述K-means聚类
根据相似性原理科学分类[7],K-means 算法较人工分类更具客观性。本文利用K-means 算法对数据分析岗位需求词典进行聚类分析,由于在实现K-means 算法之前需要将文本进行向量化处理,选取了Word2Vec模型实现文本向量化,再根据生成各关键词对应的向量值进行聚类。
K-means 算法以各关键词对应向量间的距离作为判断其相似性的标准,本文采用欧氏距离计算向量间的距离,其计算公式如公式(3)所示。
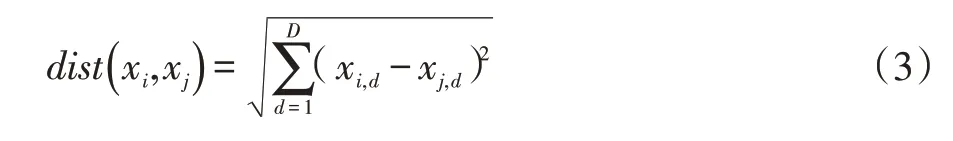
在K-means 的计算过程要通过多次迭代动态地确定分类中心Centerk,每次聚类结束后要调整所有数据对象的mean 值并确定下次分类的中心。定义第K 个类的类簇中心Centerk的方程如公式(4)所示。

其中Ck代表第k 个类簇,|Ck|代表第k 个类簇中所有数据对象的总数。K-means 算法停止迭代的方式有两种,一种为设定迭代次数T,当达到设定迭代次数时停止迭代。另一种是采用误差平方和准则函数,此数学模型如公式(5)所示。
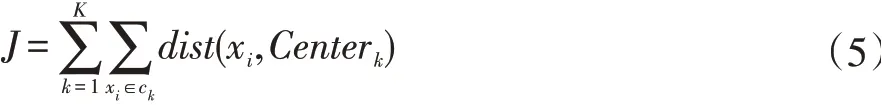
其中K 的值代表的是类簇个数,此方法首先要设定δ值再计算,直到ΔJ<δ时终止迭代,此时得到的聚类结果为最终结果。最后根据聚类分析结果将职位描述高频关键词进行分类。
3 实验结果与分析
3.1 可视化结果分析
(1)数据分析岗位全国热力图
本文选取“城市”(工作地点)字段制作了数据分析岗位全国热力图,探究数据分析岗位需求量的地域因素以及其全国分布情况,如图4 所示。
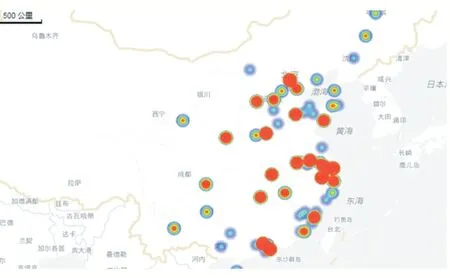
图4 数据分析岗位全国热力图
热力图中颜色越深,点越密集代表数据分析岗位的需求量越大。从图4 可以看出数据分析行业作为新兴行业并没有在全国广泛分布,岗位主要分布在东南沿海地区其中上海、北京、深圳、广州需求量最大,而杭州、南京、合肥、厦门、天津、福州等城市次之。内陆地区重庆、成都、石家庄等城市数据分析岗位需求人数较多,而我国东北地区和西北地区数据分析岗位需求量较少。
(2)工作经验与薪资关系分析
本文将工作经验字段与薪资字段结合分析二者之间关系,两者之间的统计图如下图5 所示。由图中可知数据分析岗位对应届毕业生以及从业经验1 年以下的应聘者需求量很少,而且工资水平主要在6 千元到1万元之间。而需求的高峰主要集中在经验1-3 年和经验3-5 年的从业者,并且月薪水平在1 万5 千元以上的占比很大。经验1-3 年的人群中月薪在1 万5 千元以上的占比接近一半,而在经验3-5 年的人群中月薪在1 万5 千元以上的占比已明显超过一半,可见工作经验在3-5 年的数据分析从业者最容易找到高薪工作。经验5-10 年的需求量已明显减少,但高薪资的占比依然很高。

图5 工作经验薪资统计图
3.2 福利待遇统计结果分析
计算福利待遇字段各关键词的TF-IDF 值如表1所示,此处选取权重排行前三十的关键词展示。
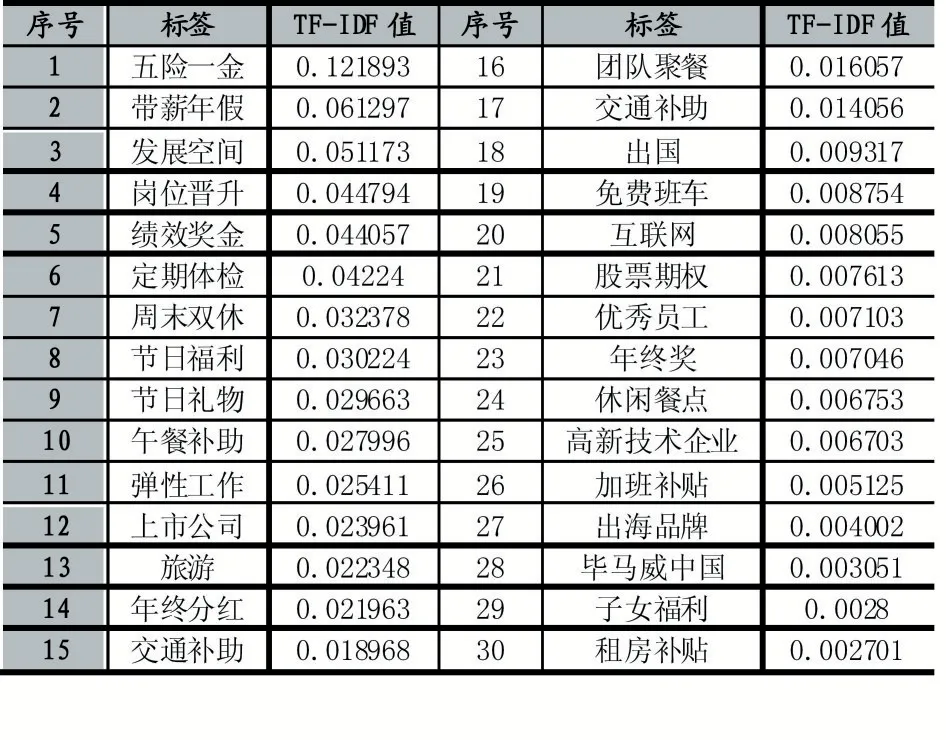
表1 福利待遇权重统计表
从总体上看,五险一金的权重远远高于其他福利待遇,带薪年假和发展空间位于第二和第三,说明数据分析类岗位也都普遍提供这三种福利。通过进一步深入分析发现:人数规模较大的企业,通常还提供绩效奖金、午餐补助等福利待遇;有些注重员工发展的企业则提供发展空间、岗位晋升、出国进修等待遇;另外还有一些企业提供了人文关怀待遇,例如定期体检、弹性工作、节日福利和外出旅游等。综合而言,上市公司、互联网、高新技术企业所提供的福利待遇更为全面。
3.3 K-means聚类结果分析
(1)职位描述需求词云图
基于“职位描述”字段制作职位描述需求词云图,如图6 所示。

图6 职位描述需求词云图
(2)职位描述聚类分析结果
基于词频统计结果,将高频关键词作为K-means算法的输入,探究数据分析岗位需求类型的划分。本文通过经验调参方式将K-means 聚类的类别数定为5类,并展示每类的前15 个关键词,如图7 所示。

图7 聚类分析结果
综合上述两图可知,第一类关键词的主题可概括为业务能力,尤其是与需求分析以及数据分析相关的业务能力。其中分析报告,产品运营和需求分析权重较高。第二类主题较明确,可概括为专业及学历方面的需求,其中本科学历,统计学和数学专业权重较高。第三类主题为技能需求,其中SQL、Python、SAS、SPSS、Excel 权重较高。第四类主题为个人素质,其中学习能力,逻辑思维能力和沟通能力最为重要,此外还应具备团队合作能力。第五类主题较模糊,主要与招聘岗位所在公司领域有关,其中互联网公司数据分析人才需求量最大,在银行以及通信行业也有一定的岗位需求。
3.4 总体结论
通过上述分析结果,总体结论如下:在工作地点上,北京、上海、广州、深圳等一线城市或东南沿海发达城市的数据分析岗位需求量大,行业发展较成熟;在工作经验方面,求职者经验1 年以下从业者需求量很少,对工作1-5 年的从业者需求量较大薪资也较高,可以看出行业内急需经验丰富的数据分析人才;福利待遇方面,基本与公司实力相匹配;求职者能力要求方面,主要包括业务能力、职业技能、个人素质三方面。此外,数据分析类岗位普遍要求数学和统计学相关专业。
4 结语
大数据如今备受企业关注,高校人才培养应该与时俱进,以市场需求为基准,设置合理的专业,注重产学研结合,加强学生的项目经历,才能提升学生的就业竞争力。另外,相关专业的求职者也应进行一定的能力储备,才能进入福利待遇较好的企业就业。
