基于智能手机使用数据的用户行为提取与分析
2019-10-09刘新帅曹永春杨津达满正行纪金水
刘新帅,林 强,曹永春,杨津达,满正行,纪金水
(西北民族大学 数学与计算机科学学院,甘肃 兰州 730030)
0 引言
随着无线通信和微电子技术的发展,智能手机(Smartphone)应运而生,且日渐普及.智能手机这一搭载独立操作系统和内存,支持软件、应用自行安装,并可通过移动通讯网络实现无线网络接入的移动计算平台,为人们的日常生活、学习和工作提供了诸多便利,已经成为不可或缺的“个人移动助手”.2018年9月,市场研究机构Newzoo发布的《2018年全球移动市场报告(Newzoo Global Mobile Market Report 2018)》[1]预测,2018年全球智能手机用户将达到33亿,其中中国将拥有7.83亿用户量,成为最大的智能手机市场.
支持应用开发是智能手机与传统手机一大主要区别,这归因于其搭载的操作系统,主要包括苹果的iOS和谷歌的Android.特别是Android操作系统以其代码开源的优势,占据了智能手机市场的半壁江山.在2018年8月全球操作系统市场份额报告中[2],Android占有41.66%的市场份额,位居第一.
除了基本的通讯功能以外,智能手机同时承载了信息获取和传输、娱乐、消费、电子支付等移动计算功能,成为推动“信息物理融合系统(Cyber-physical System,CPS)”付诸实现的重要技术推动力.智能手机与人之间存在的固定绑定关系,使得其成为记录人在物理世界中真实行为的有效工具.
应用程序APP是除硬件配置之外智能手机吸引用户的最主要方面,种类繁多、功能各异的APP为用户提供了信息交互、网上购物和移动支付等方面的便利.综合个人APP使用的全部历史信息,应用合理的数据挖掘技术,便可发现和识别隐藏在数据中的用户生活习惯、兴趣爱好、职业种类及消费水平等个性化行为,以便提供个性化建议和提醒,在提升用户使用体验的同时一定程度上可减轻或消除手机使用的负面影响.
以用户个性化行为的理解为目标,本文研究基于数据挖掘技术的智能手机APP使用模式提取,以发现APP使用模式背后的用户行为特征.首先,基于Android平台,应用传感器端口监测技术,实时监测并收集智能手机APP的基本状态信息,包括APP的启动时间和持续时长.其次,应用去噪技术对APP状态数据进行预处理,进而形式化定义APP事务为二元组.再次,应用关联规则挖掘技术,挖掘并提取个人历史APP事务中隐含的模式关联.最后,应用真实的个人数据集,测试并验证所提提出方法的有效性.实验结果表明,本文提出的方法在APP事务关联的提取中具有较好的性能.
1 国内外研究现状
1.1 基于智能手机传感器的用户行为研究
从数据感知的角度讲,智能手机是融合类型各异传感器的综合感知平台.利用手机传感器开展用户行为分析研究,是国内外学者关注的重要研究分支.Jennifer R等人[3]研究用手机加速度传感器识别简单活动,包括走、上下楼梯、跑等;Lee等人[4]综合考虑手机存储容量和计算能力的前提下,研究基于手机加速度传感器的人体活动识别,提出基于隐马尔可夫模型(Hidden Markov Models,HMMS)的两阶段识别模型,即先通过上层HMMS模型识别活动序列,再通过下层HMMS模型识别用户的具体活动;Yan等人[5]研究并提出了基于传感器的自适应活动识别模型A3R,用于简单活动如上下楼、随意行走等活动的识别.Zhang等人[6]利用手机加速度传感器识别6种简单活动,该工作首先将活动进行分级分类,先判别其是静止的还是非静止的,然后再分别进行具体活动的识别.
李晶等人[7]研究应用智能手机内置传感器获取的用户室内移动数据,构建面向用户行为识别的分类模型,并对不同分类模型的准确度进行了对比.为了提高行为活动识别的准确度,朱响斌等人[8]先利用降维技术对实验数据集进行特征约简得到最优实验特征子集,再利用随机森林集成分类器完成了人类行为的识别.李文洋[9]提出了一种基于谱聚类和隐马尔可夫模型(Spectral clustering and Hidden Markov Models,SC-HMM)的日常行为识别算法,胡龙[10]研究基于支持向量机的用户行为分类算法,邱慧玲[11]提出了基于三阶层连续隐马尔可夫模型(Three-Stage Continuous Hidden Markov Model,TSCHMM)的人类行为识别算法.
上述研究基于传感器数据识别人的活动或行为,属于细粒度活动的范畴.本文研究基于手机APP使用情况的用户行为理解,属于粗粒度行为的范畴,因而与上述工作的研究目标有所不同.
1.2 基于智能手机使用数据的用户行为研究
在智能手机的绝大多数应用中,用户使用手机是通过操作APP实现的.APP与业务类型的绑定关系为用户行为的理解提供了数据记录途径,因而成为极具潜力的研究分支.Wu等人[12]研究并开发了一个实验数据收集平台,可记录和分析现实生活中智能手机的用户操作行为,数据经由Internet连接定期上传至服务器予以存储,同时提供图表展示、日志查询和实时日志模式分析等功能.Chittaranjan等人[13]针对智能手机使用情况,提出了基于机器学习方法的用户性格特征分类方法.Tseng等人[14]通过挖掘智能手机的使用日志,探索用户使用智能手机的模式,以发现用户真实的APP使用行为.针对智能手机使用数据,Sarker等人[15]提出了一种基于用户接受、拒绝或错过电话呼叫事件的个性化行为发现方法,在其后续的研究工作中又提出了基于行为的时间分割技术[16]和用户行为关联规则挖掘技术[17].
针对APP事务及其关联,本文研究基于智能手机使用情况的行为捕获与分析,从宏观层面理解用户的手机使用行为,以便支撑行为习惯和特征的提取.
2 数据收集与关联规则提取
本文研究基于手机APP使用情况的用户行为捕获与分析,本部分首先介绍APP状态数据的收集方法,基于此描述APP数据的预处理和形式化,然后给出本文提出的APP事务关联规则挖掘方法.
2.1 APP数据收集
APP数据的收集本质上是对APP运行状态的数字化记录,借助于移动开发平台的应用程序端口监测予以实现.具体而言,本文研究基于开源Android平台的APP运行状态数据实时感知,应用Android studio工具中的UsageStatsManager类,对运行在Android智能手机平台上的应用程序进行监听并记录其状态数据.
为做到完整记录APP的运行状态以真实反映用户的使用行为,数据采样频率是一个需要慎重选择的重要参数.这是因为采样频率设置太大、持续时间较短的APP不能被有效记录;相反,采样频率设置太小,存储空间开销会明显上升.
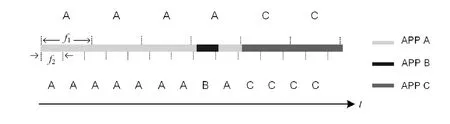
图1 基于固定频率的APP状态数据采样机制
如图1所示,较大的采样频率f1导致持续时间较短的APP B未被记录,较小的采样频率f2使得最终记录的APP运行状态数量明显增加.
鉴于此,本文提出基于界标窗口模型(Landmark Window Model)的APP运行状态数据收集机制.如图2所示,每当APP开始运行时,将开启一个界标窗口(Landmark window),这个窗口一直向前延续直到当前APP停止运行.APP停止运行意味着新的APP开始运行,或者系统进入“桌面”状态(桌面也可以看作一种APP状态).很显然,基于界标窗口模型的数据收集机制克服了固定频率方式存在的问题,真实记录了各个APP的运行状态.
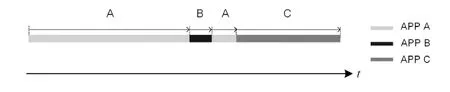
图2 基于界标窗口模型的APP状态数据采样机制
应用基于界标窗口模型的采集机制,每一个APP运行数据可表示为三元组A=(N,TS,TE),其中:N代表APP的名称,如QQ、铁路12306等,TS和TE分别代表该APP执行开始和结束的时间,如PM 11∶31和PM 11∶45.
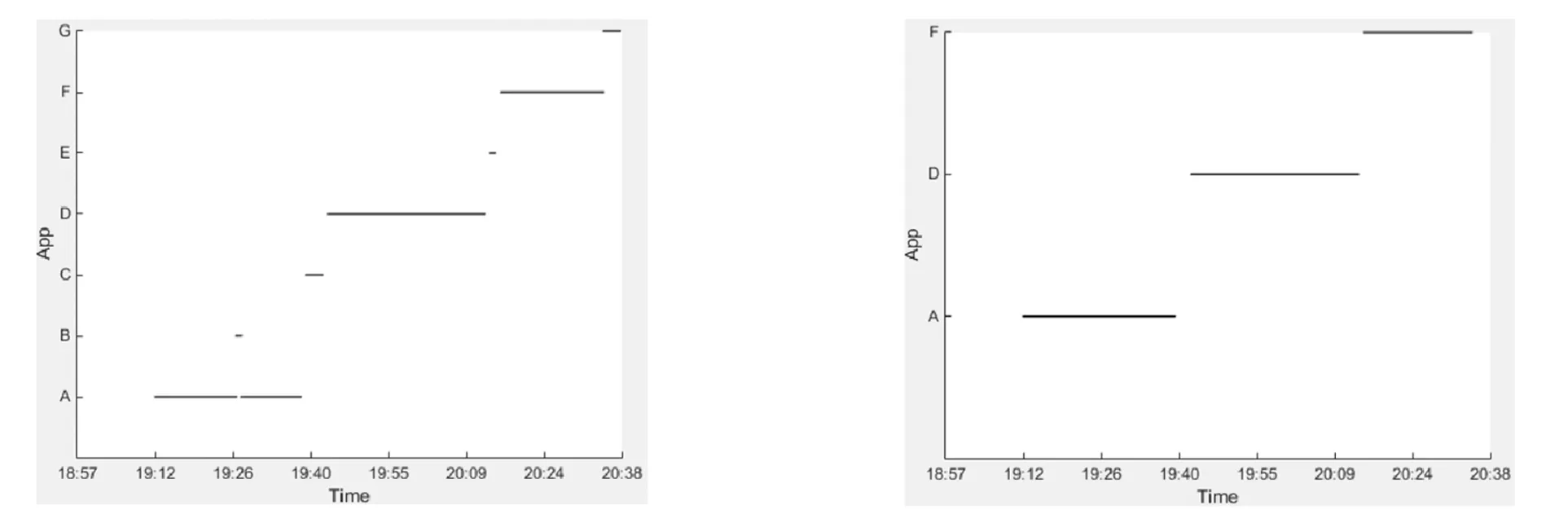
a.预处理前的数据 b.预处理后的数据
图3数据预处理
2.2 APP数据预处理
本文研究APP使用模式的提取,以进一步研究个体的使用习惯和行为.因此,那些仅仅是短程切换而非真正使用的APP产生的数据记录不仅不是模式提取关注的对象,反而可能会为模式挖掘带来负面影响.例如,图3a中的APP B、C和E的持续时间明显偏短,它们可能代表从当前APP短程切换至另一个APP后很快切换回来(如APP B所示),也可能是从一个APP切换至另一个APP之间行为习惯上的过渡(如APP C和E所示).此外,为了进一步提取宏观层面的APP使用关联,而不仅仅是APP之间的前后依赖关系,需要对原始APP三元组数据进行映射处理.
2.2.1 短程数据的移除处理
设定时间阈值Tthr,给定APP三元组序列A= {A1,A2,…,Ai-1},是否将第i个APP记入A,取决于Ai=(N,TS,TE)的持续时间TE-TS是否大于阈值Tthr.若TE-TS>Tthr,则Ai记入序列A,此时A= {A1,A2,…,Ai-1,Ai};否则,Ai被识别为短程数据,不记入序列A.
应用上述短程数据移除规则,可将图3a所示原始数据中的APP B、C和G移除掉,获得如图3b所示的处理后数据.
2.2.2 基于时间轴的APP数据投影
前述APP运行状态的三元组(N,TS,TE)记录反映了APP运行的时空状态,其中N为空间域、TS和TE为时间域.很显然,同一周期中空间域相同的多个三元组记录在时间域上将不同,不同周期中空间域相同的三元组记录的时间域很难完全对齐.这些问题的存在为APP关联规则的挖掘带来巨大挑战,不利于用户行为模式的提取.
鉴于此,本文提出基于时间轴的APP三元组投影机制,将APP三元组转换为二元组表示,以解决不同周期中APP运行记录无法对齐和同一周期中APP运行记录重复的问题.
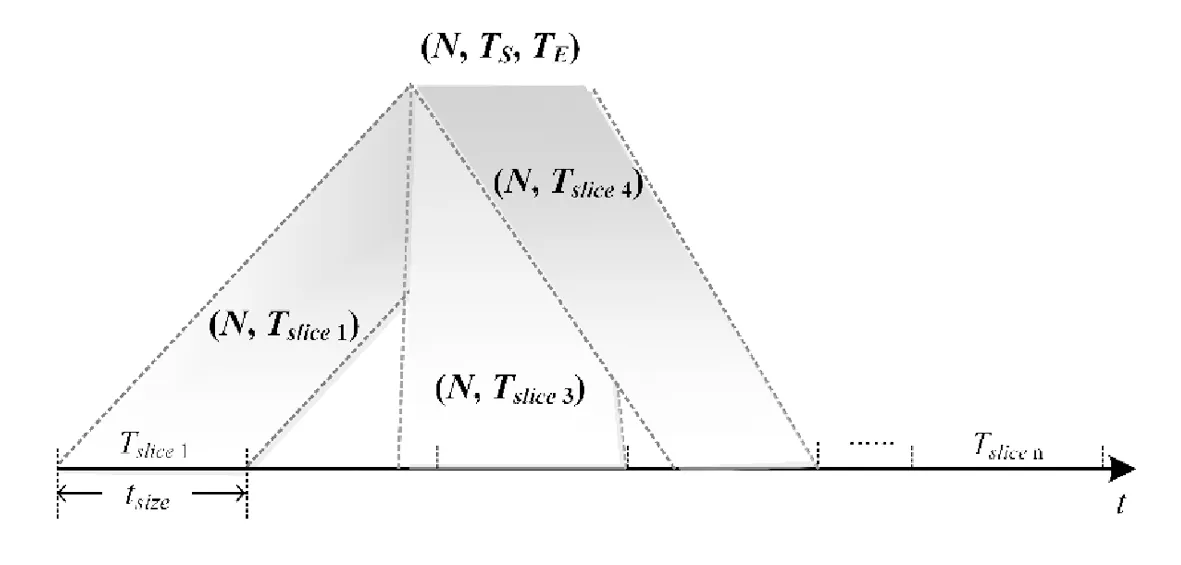
图4 基于时间轴的APP三元组投影
图4将时间轴划分为一系列固定长度(tsize)的时间片,并对时间片序列进行编码(Tslice1-Tslicen);然后,基于如下规则将三元组投影到时间轴:
1)若TS和TE正好与某个时间片的开始时间和结束时间严格对应,则将该三元组的时间域用投影所在的时间片编码替换,产生对应的二元组.如图4所示,投影到第一个时间片Tslice1的三元组被表示为(N,Tslice1).
2)若TS或TE处于某个时间片的内部,且跨越部分的距离不超过时间片长度的1/3,则做缩减投影处理.如图4所示,投影到第三个时间片Tslice3中的三元组有部分跨越到第二个时间片Tslice2,但跨越距离不超过tsize/3,所以将投影结果缩减并表示为(N,Tslice3).
3)若TS或TE处于某个时间片的内部,且TE-TS>tsize/2,则做扩展投影处理.如图4所示,投影到第四个时间片Tslice4中的三元组虽然尚未充满整个时间片,但其跨越距离超过tsize/2,所以将投影结果扩展并表示为(N,Tslice4).
经过上述预处理步骤,原始APP运行状态数据将表示为由APP名和投影所在的时间片构成的二元组(N,Tslice),其中不含持续时间很短的短程数据.本文将该二元组称为APP事务.本文定义APP事务如下:
定义1.APP事务是APP运行状态的时空二元组(N,T),其中N代表APP的名称、T代表APP投影所在的时间片.
2.3 APP事务关联的提取
APP之间的关联本质上是APP之间的时空依赖关系,蕴含着用户的使用习惯和使用行为.数据挖掘领域常见的事务关联挖掘算法有Apriori[18]和FP-Growth[19].鉴于Apriori结构简单,同时对于规模较小的数据集有着良好的性能.因此,本文选用Apriori算法作为APP事务关联规则的提取算法.
假定suppthr代表支持度阈值,对于给定的APP事务A=(N,T),A的支持度定义为support(A)=number(A) /number(Allsamples);称A为频繁事务,support(A)≥suppthr.其中:number(A)代表数据集中包含A的记录的条数,number(Allsamples)代表数据集中记录的总数量.类似地,定义两个APP事务A和B的支持为support(A→B)=number(AB)/number(Allsamples),反映了事务A和B同时发生的概率.
不同于支持度,置信度是另一个反映两个或以上事务同时发生概率的度量指标.对于两个APP事务A和B,定义当A发生的前提下B发生的概率为置信度confidence(A→B)=number(AB)/number(A),即A、B同时存在的记录占A存在的记录的比重.
在给定的支持度阈值suppthr的前提下,Apriori算法不断计算支持度和置信度值,在满足条件的前提下遍历数据集以查找k-频繁事务,直到条件不满足为止.
3 实验及结果
应用收集自5位智能手机用户的真实数据集,本部分验证并呈现本文提出方法在APP关联规则挖掘应用中的有效性.
3.1 实验设计
表1给出了本文实验数据的概貌,包括数据集名、记录总数和APP总数.其中,记录总数与采样周期一一对应,即一个采样周期产生一条APP记录,而一条APP记录可能包含多个APP事务,APP总数代表一个数据集中所包含的APP类型总量.
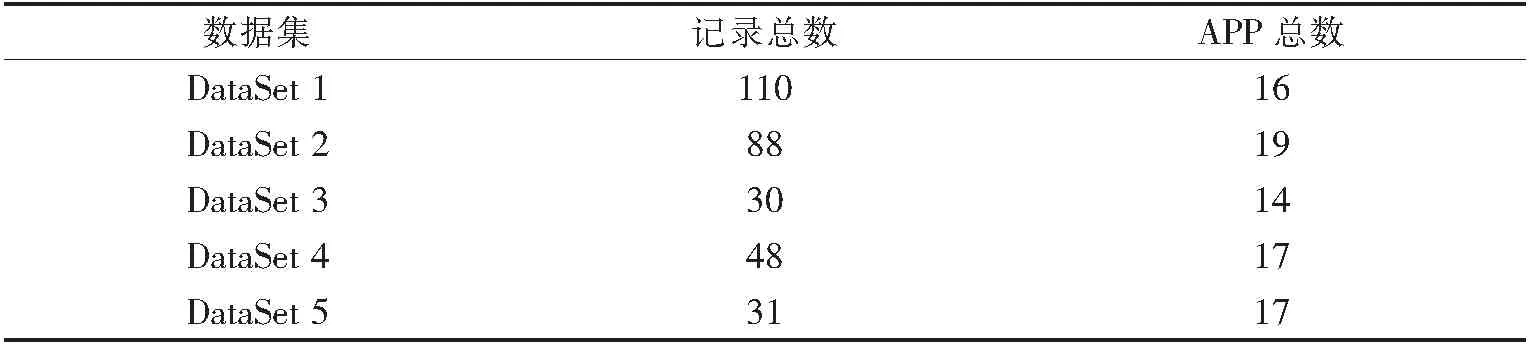
表1 本文实验数据
表2给出了本文实验中预定义参数的取值,这些值较强关联于所选用的实验数据.因此,实验数据不同,取值可能略有差异.

表2 预定义参数的取值
表2中时间片大小tsize设定为15分钟,将一天当中的9∶00-24∶00作为一个周期,即自9∶00开始每隔15分钟作为一个时间片,如T1(9∶00-9∶15)、T2(9∶15-9∶30)……T60(23∶45-24∶00).
实验评价指标为挖掘所得关联规则的客观性,因为客观性较难量化定义,且每个数据集仅代表个人的APP运行记录,不同数据集之间的可比性较小.因此,本文通过邀请用户对实验结果进行应证评分,实现关联规则的客观性评价.具体而言,若用户认为本文实验结果正确反映了其80%以上的行为特征和关联,则该规则为客观的,否则,该规则为不客观的.
3.2 实验结果
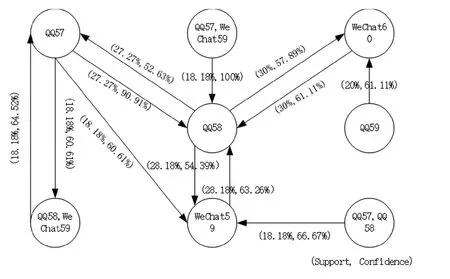
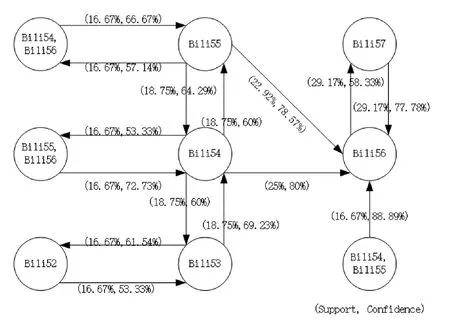
利用经典关联规则算法Apriori算法,对用户的APP事务集进行关联规则挖掘,设置关联规则的最小支持度为15%,最小置信度设置为50%,得出的DataSet 1和4的APP事务间的关联规则如图5所示.
a.DataSet 1的关联规则
b.DataSet 4的关联规则
由图5所示的DataSet1和DataSet 4的APP事务之间的关联规则可以看出,DataSet 1的最大频繁项集为(QQ57,QQ58,WeChat59),可推断该用户经常使用“QQ”和“微信”这两种社交类APP聊天和浏览新闻.此外,根据频繁APP所在的时间片,可以看出该用户经常在晚上23∶00-23∶45之间使用QQ和微信,可进一步得知用户在这个时间段内先使用QQ后使用微信这一使用行为模式.类似DataSet4的最大频繁项集为(Bili54,Bili55,Bili56),可以得知该用户经常在晚上22∶15-23∶00之间使用“哔哩哔哩视频”APP观看视频、学习等.
用户1至用户5所得APP事务间的关联规则见表3.
从实验结果可以得知,不同的用户(数据集)拥有不同的APP使用行为,有些用户喜欢使用社交类软件,如用户1、2和5;有些用户喜欢看视频软件,如用户2和4;还有些用户喜欢浏览网页,如用户3.此外,虽然用户1、2和5都经常使用微信APP,但他们运行微信APP的时间段不同,所以有着不完全相同的行为习惯.
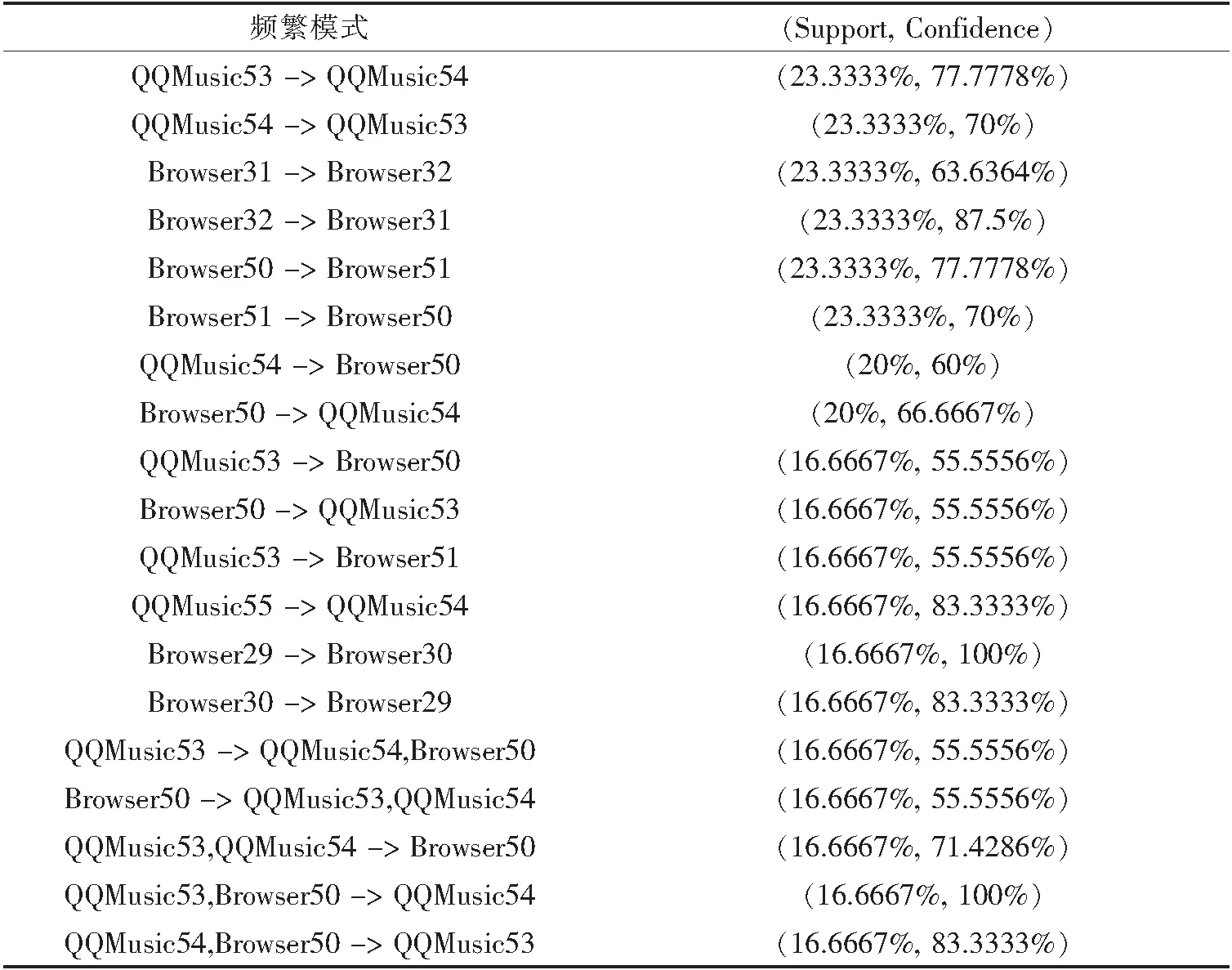
表3 DataSet1的APP事务间的关联规则
如前所述,为验证挖掘所得的关联规则的客观性,实验结束后,邀请5位用户对实验结果进行应证评分,见表4.

表4 用户应证评分表
由表4可知,所有数据集上的关联规则均符合定义的80%的客观性,即本文提出的基于数据挖掘的用户行为挖掘结果较好反映了用户的APP使用行为.其中,DataSet 1的评分值达到95%,说明挖掘所得的行为模式很好体现了用户的使用习惯;而DataSet5的评分值81%,其主要原因是该数据集包含的APP记录数太少,数据量不能较好支撑关联规则的提取.
4 总结与展望
为了发现用户的APP使用习惯和模式,本文研究并提出了基于数据挖掘技术的智能手机APP使用模式提取技术.首先,基于Android平台开发了智能手机APP状态数据的收集平台;其次,提出并实现了面向APP去噪的预处理技术;再次,应用关联规则挖掘技术,提出并实现了个人历史APP事务模式的挖掘和提取;最后,应用包含5个数据集的真实个人APP数据,测试并验证了本文提出方法的有效性,实验结果表明,本文提出的方法在APP事务关联的提取中具有较好的性能和客观性.
未来可以在以下几个方面进一步拓展:首先,收集大量数据,进一步完善和提升本文提出的APP关联挖掘方法;其次,完整实现面向APP使用模式提取的数据收集与挖掘系统;最后,结合智能推荐系统,将模式挖掘与辅助提醒集成到系统中并应用于实践.
