基于地名本体的加权语义相关度算法研究
2019-10-09索俊锋郑海晨
索俊锋,郑海晨
(西北民族大学 土木工程学院,甘肃 兰州 730124)
信息检索已逐渐成为人们获取信息的最主要方式之一.在用户提交的查询中,和位置相关的查询占有较大的比重[1].然而,目前大多数搜索引擎在查询时把地理位置当作关键词、主题词进行简单字面匹配,缺乏一定的推理能力,没有考虑到地理位置的特殊性,导致用户的需求常常难以满足.网页中地理位置信息通常是以地名的形式出现,人们习惯使用地名而不是地理坐标来描述空间信息,以此作为获取信息的地理参考.地名知识反映人们对客观世界地理命名实体的描述,缺乏统一的地名知识形式化表达方法.在实际使用时经常出现一地多名、一名多地、一名多义等多源异构性问题[1],直接导致了地名知识难以共享和集成.而地名本体能够为业界提供地名的形式化定义以及语义上的共同理解,可以为语义地名引擎提供知识库以及规则库.专业搜索首要解决的问题是如何高效准确地在海量信息资源中发掘其特定领域或特定主题的网络信息,然而信息资源异构性的存在,尤其是语义异构性的存在,使得传统以字符串匹配为基础的信息检索系统难以满足用户对信息和知识的深层次需求,因此,加强基于概念匹配的信息检索系统的研究就显得尤为重要.此问题的核心和关键点是如何计算目标网络资源的主题相关度[2].语义相关度计算是对信息进行智能化处理的核心技术之一,可以用来迅速定位与查询密切相关的信息,一直是自然语言处理领域的研究热点[3].然而,现有的相关度算法基本上在字符层次上计算主题相关度,未能全面考虑词语语义,处理概念或语义的能力相对不足,结果是主题相关度判断不准确,导致获取主题信息的准确性较低,难以满足用户的需求.
针对以上存在的问题,本文简要回顾了语义相关度理论和定义,以兰州市地名本体为例研究了领域本体的构建方法,基于protégé本体平台构建了中国西北地名本体.在传统词语间本体关联度计算模型的基础上,引入地名本体相关度计算模型,提出了一种加权语义相关度计算模型.该模型考虑词语所在的语境和语义等信息.根据资源对象的语义关系、概念匹配以及有关推理机制来引导用户的查询和检索反馈,其根本特点在信息检索过程中的检索匹配不是基于字面的机械匹配,而是基于知识单元的、面向语义的匹配,可以有效抽取利用网页中的地理位置信息来满足不同用户位置相关的查询需求,从而大大提高信息检索反馈的相关性和准确度[4,5],并以中国西北地名本体的片段为例,详细阐述了基于地名本体相关度计算过程,表明本文提出的语义相关度综合模型在语义检索应用中可以达到更好的检索效果.
1 研究现状
语义相似度和相关度既有联系又有区别[4,6].语义相似度是指两个概念间的相似程度,通常指两个概念本身之间具有某些共同特性[7].语义相关度是指两个词语的关联程度[8],这两个词可以是同义词、近义词、反义词,也可以是具有包含关系(如“森林”和“植被”)、层次关系(如“国家”和“省”“市”等)、关联关系等的两个词语.相关是对两个有关系的对象关系的定性分析,如兰州市和定西市,存在相接关系;相关度就是对相关性的定量分析,用一个数值表示两个对象间的关联程度的大小,这个数值介于0~1之间.语义相关度计算已广泛应用在信息检索、文本分类、词义消歧,基于实例的机器翻译、智能问答、自动摘要、拼写纠正、意见挖掘、词汇选择、复合名词解释和信息系统关键词分类等自然语言处理领域[3,9,10].国内外许多学者提出了大量语义相关度算法,这些算法大致分为4类:基于路径、基于信息内容、基于特征以及混合算法[4,7,8,11-14].基于路径的模型主要依据概念之间的距离、深度计算相似度,计算模型简单但考虑因素过于单一,难以详细说明领域的范围或在概念空间中的尺度,仅能计算语义距离[15];基于特征的方法考虑了概念共同拥有的特征,忽略了二者在本体树种的层次结构且特征的计算相对复杂[16].由于复合特征(特征匹配与否)可能很多,因此基于特征的模型不能很好度量语义相似性[15].基于信息量的方法通过统计概念及其下义词在语料库中出现的频率来表征概念的信息量.概念出现的次数越高,信息量则越少,忽略了概念的层次信息,且不同语料库的计算结果可能不同[6].近年来,为了得到更为精确的结果,综合考虑多种影响因素,但在算法性能以及效率方面难以达到平衡.吕欢欢[17]提出了一种综合概念关系类型,强度、信息量、节点密度等多个因素的计算模型,概念相似度准确性得到了一定提高,然而计算太复杂.
在语义相关度计算中涉及本体,通常采用通用本体,如WordNet[18]、知识百科Wikipedia[19]、知网HowNet[10,20]等,其中WordNet可以被看作一种树状的本体,其本体结构采用上下位关系作为主要关系连接概念节点,采用基于本体边[21]和基于距离[4,22]进行语义相关度计算.通用本体难以应用于专业领域,领域本体常用于行业语义相关度计算[7].近年来,更多的学者开始重视面向领域知识本体在文本处理技术中的应用[7,23-25],挖掘本体概念关系,提高信息自动化处理的效率.陈小红等[7]基于地学领域本体,综合考虑本体层级信息量、拓扑结构,提出了加入约束条件下的相关度算法;卢艳平[3]基于儒学领域本体,提出了一个考虑语义距离、层次深度、公共祖先集及本体之间基本关系的相关度计算模型,并将其应用于图书馆古典文学检索系统.Shrutilipi Bhattachearjee,etc[26]提出了一个基于土地覆被本体计算空间土地覆被烈性之间语义相似度的方法.程刚[27]针对基于字面和空间数据的地名匹配方法存在的不足,面向规范地名提出一种综合了地名专名字面相似度和地名通名语义相似度两种因素的复合相似度匹配算法模型.
尽管学者们基于不同领域本体提出了不同的语义相关度算法,但是针对地名本体的语义相关度算法鲜有报道.基于此,本文提出基于地名本体的综合语义相关度算法在与位置相关的信息检索中有十分重要的现实意义.
2 理论基础
2.1 本体和地名本体
本体(Ontology)来源于哲学领域,随后引入到信息科学领域.Gruber[28]认为:本体就是概念化的明确规范化说明.该定义包含四层含义:概念模型、明确、形式化和共享.地理本体(Geo-Ontology)是空间信息科学中具体应用领域里共享的一个概念化的知识系统的形式化和显示的说明规范[29].
地名本体是关于地理位置的本体,是一种特殊的地理本体,也是一种面向地名的领域本体.与一般地理本体比较,地名本体主要表达的是人类常识性的地理信息需求,而不是反映整个地理空间世界[30].本文采用五元组数据结构表示地名本体:DO=

图1 兰州市地名本体对象表达
2.2 相关定义
定义1 路径长度[32]:概念结点ti与tj之间的路径长度Len(ti,tj)是指从概念结点ti到达tj的路径上经过的边的条数.
定义2 语义深度:任意概念结点t的深度是指由结点t到根结点R之间的路径长度,Dep(t) =Len(t,R),根结点的深度Dep(R)=0.同样距离的两个概念,其相似度随着他们所处层次的综合增加而增加,随着他们之间层次差的增加而减小[33].
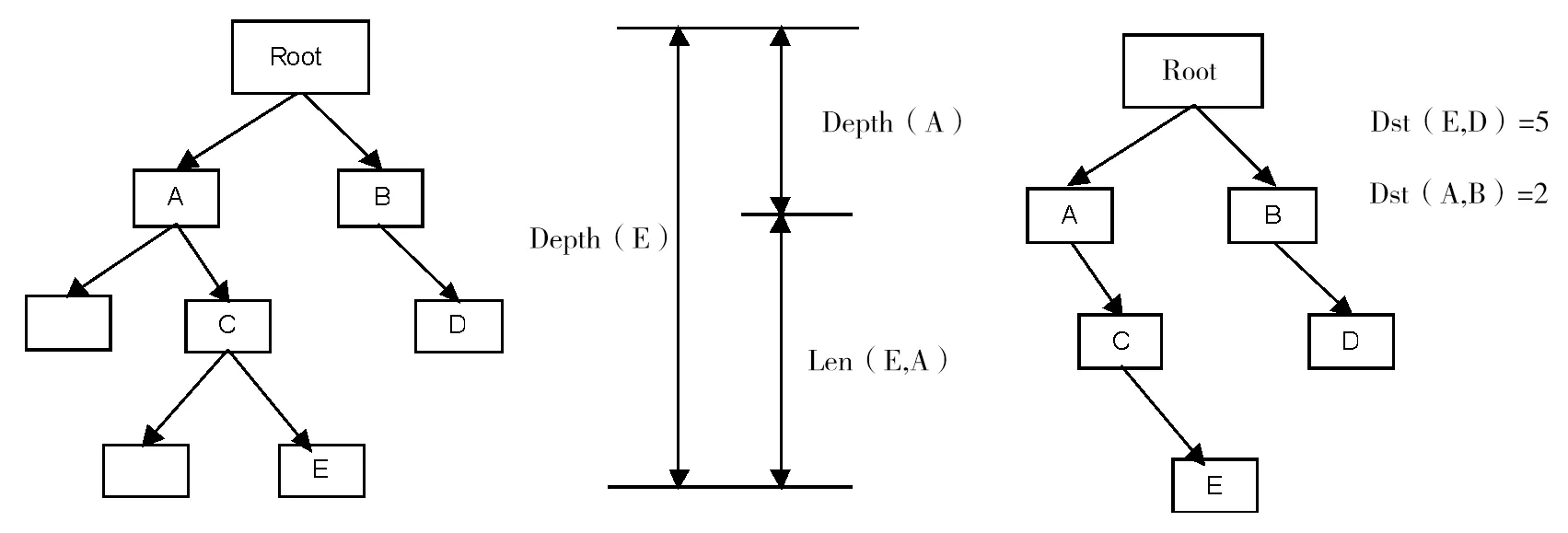
图2 语义距离示意图
定义3 语义距离:本体中任意两个概念节点ti与tj之间的最短路径,即从概念节点ti到概念ti与tj最近父节点p的距离与概念节点tj到概念ti与tj最近父节点p的距离之和,记为Dist(ti,tj).特殊情况下,当两个节点不能联通时为无穷大[3],它是用来量化两个概念间的相关或相似程度.图2所示为语义距离概念间的树结构图.按照上述定义可得:Dep(A)=1,Dep(E)=3,Len(E,A)=2,Dist(E,D)=5.
3 基于地名本体语义检索相关度的计算模型
基于本体的语义检索是在传统检索的基础上,引入本体推理机制,从而达到语义检索的目的.本文在分析经典检索模型的基础上,提出基于空间本体的语义检索相关度的计算模型.
3.1 本体关联度
两个术语ti与tj之间的本体关联度[32]指属于同一个领域本体的两个术语ti与tj之间的语义关联程度,记为Ocd(ti,tj),可以利用它们之间的语义距离来计算.词语间语义距离与它们之间的路径以及术语在本体树中的位置有关.词语间本体关联度[32]的计算公式为:
(1)
式中,Distmax是本体结构中最大的语义距离;β是调节参数.
3.2 地名本体语义相关度计算模型
地名本体语义计算模型可以表达为:
(2)
式中Dist(ti,tj)为本体ti和tj间的语义距离,Wk为语义距离关系链中的任意一段的权值.上式实际上是语义距离关系链中各段权值以10为底的对数的积.
语义距离Dist(ti,tj)可用下式来表示:
Dist(ti,tj)=mink∈(1,2,…,m){Len(ti,Pij)+Len(Pij,tj)}
其中,Pij为ti和tj的父节点.语义距离是ti,tj间存在m条关系链中最短的一条.
3.3 基于地名本体语义检索相关度的综合模型
语义检索是在传统全文检索的基础上,另外增加了基于本体推理过程的检索.所以,其相关度的值应该是两者综合后的结果,可以通过一个系数ω调整两者的比重,生成一个加权相关度,其公式为:
ωCorr(ti,tj)=ω×Ocd(ti,tj)+(1-ω)×Corr(ti,tj)
(3)
式中,ωCorr(ti,tj)为加权相关度,由关联度和相关度综合影响.
4 实验和结果
4.1 实验数据
实验所用的地名本体是中国西北地名本体的片段.该本体共包含3级,包括要素类:中国西北(1个)、省级类(5个)、毗邻省级类(7个)、市级类(其中甘肃省包含14个,青海省包含8个,陕西省包含10个,宁夏回族自治区包含5个,新疆维吾尔族自治区包含23个).对象属性主要包括两类,在protégé本体平台上人工构建完成,如图3所示,从中可以看出:

图3 地名本体局部关系图
1)地名本体主要通过“包含”(contain)和“相接”(touch)两种空间拓扑关系建立.其中“甘肃省”类和“兰州市”类通过“contain”属性关联,“甘肃省”类和“四川省”类通过“touch”属性关联,两者的语义距离是相同的,都是直接的二元关系,但应用于不同的场景中,两种关系的关联程度却表现不同.比如,在空间语义搜索应用中,可以认为“甘肃省”类和“兰州市”类的“contain”关系比“甘肃省”类和“四川省”类通过“touch”关系更相关.因为当用户搜索与甘肃有关的地理专题数据时,通过语义推理搜索到兰州的数据也满足用户的需求,因为兰州在甘肃的范围内,四川不在甘肃省范围内,所以从这层含义上讲,“contain”关系的相关性就比“touch”关系要强.甘肃省包含兰州市(或天水市、嘉峪关市)比甘肃省与四川省接壤具有更高的相关度,可以通过关系路径的权值反映这种关联程度的强弱.
2)尽管“兰州市”“天水市”“嘉峪关市”类在同一层次,但是由于兰州市是甘肃的省会城市,从语义搜索的角度来看,兰州市包含的信息更丰富.如果要体现兰州作为省会,地位略高于天水,就可以赋予“甘肃—兰州”的“contain”关系略高于“甘肃—天水”的“contain”关系,这可以通过赋予不同的权值来实现.
3)上述本体关系图表现了本体的传递性,即由西北包含甘肃省,甘肃省包含兰州市,可以推出西北包含兰州市.但是本例中,西北与甘肃的关联程度比西北与兰州市的关联程度高,这是基于语义距离的观点得出的,即西北与甘肃的语义距离为1,而西北与兰州的语义距离为2,关联程度与语义距离成反比.
4.2 实验结果
根据以上分析,本实验中的本体关系权值经多次实验选取如表1所示参数.
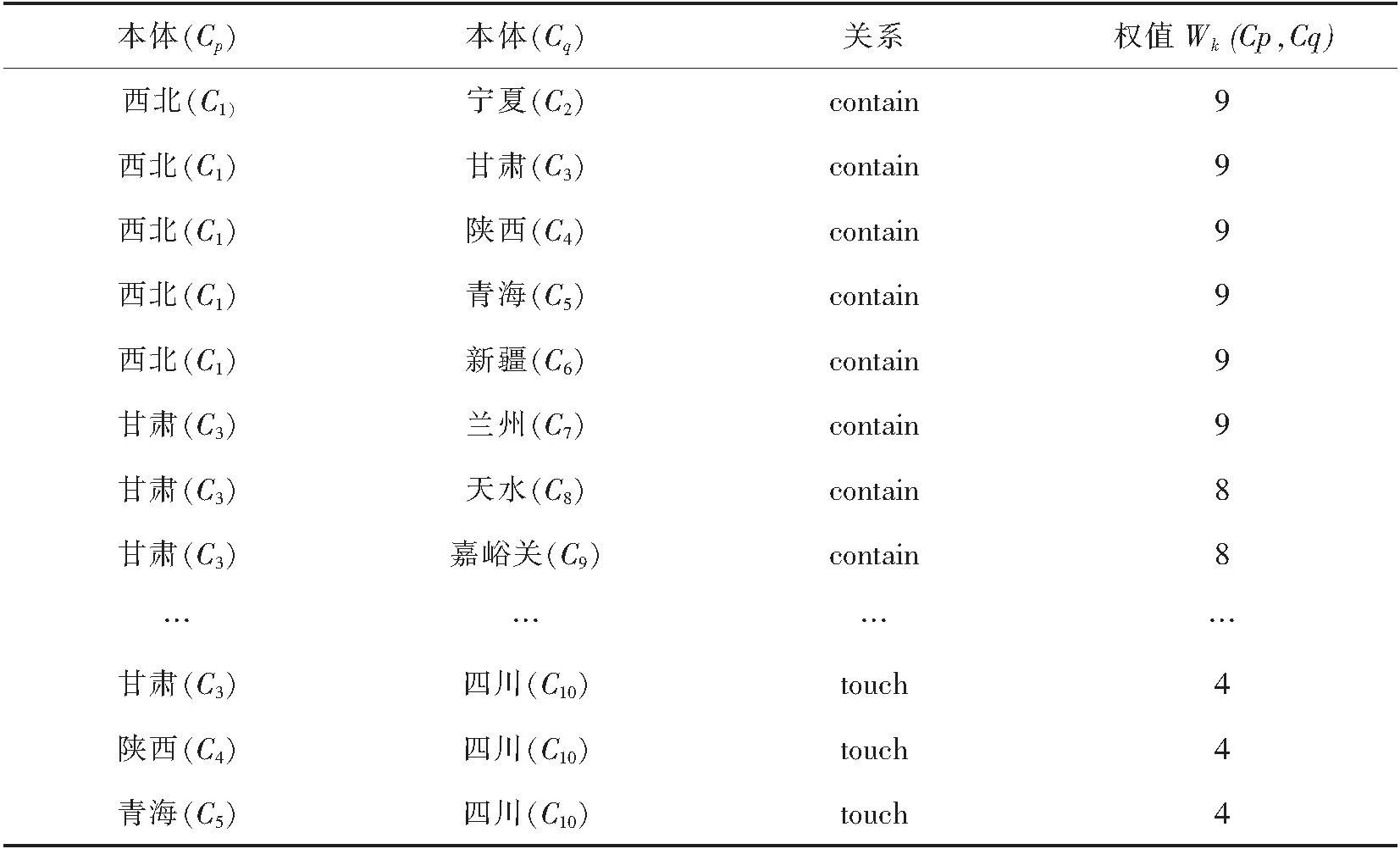
表1 空间本体间关系和权值
实验中为了选取合理的参数,在EXCEL中编程,按照提出的加权语义相关度算法和表1的本体关系权值,以表2所列参数进行了多次实验,实验结果如图4所示.由图可知,不同实验参数对于实验结果变化趋势影响不大,惟一受影响的是实验1和实验3在C1-C10和C3-C10加权本体相关度数值发生了变化,说明参数w的选取一定程度上会影响实验结果,但是不影响加权本体相关度数值变化的趋势.

表2 实验序号和参数选取对应表
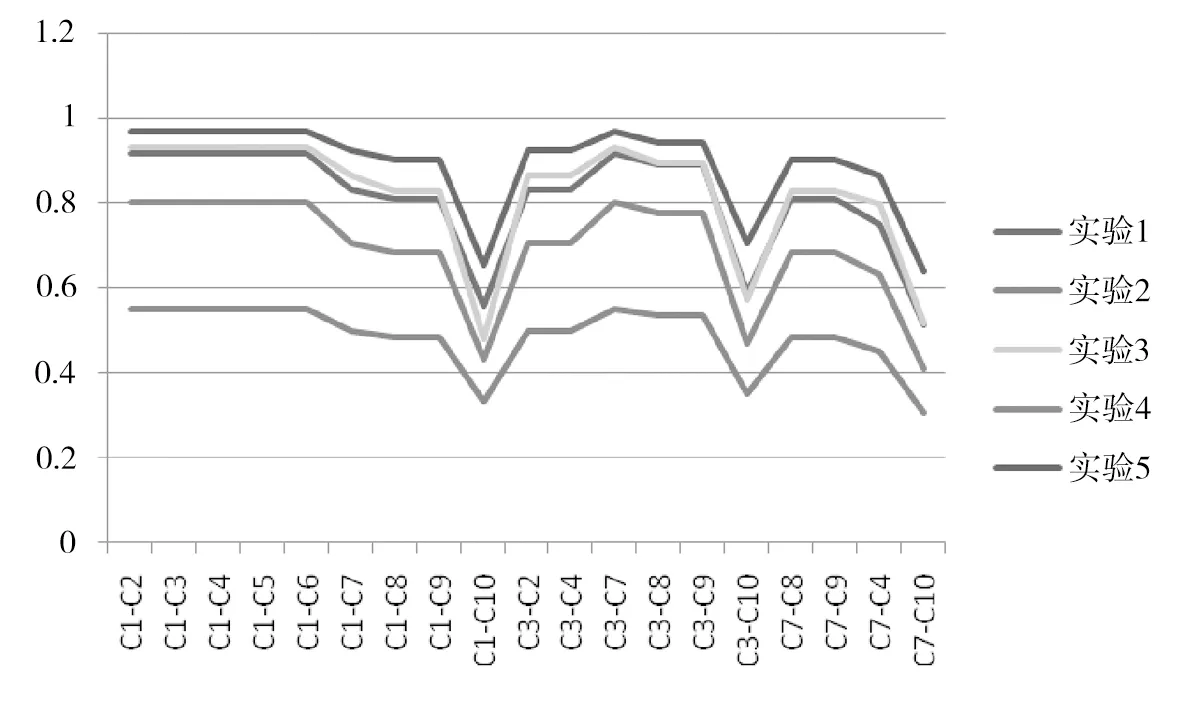
图4 不同参数计算的实验结果
为了说明加权本体相关度的具体计算过程和分析实验结果,选取参数β=1,w=0.5实例,计算出本体与其他相关联本体间的相关度值,如表3所示.
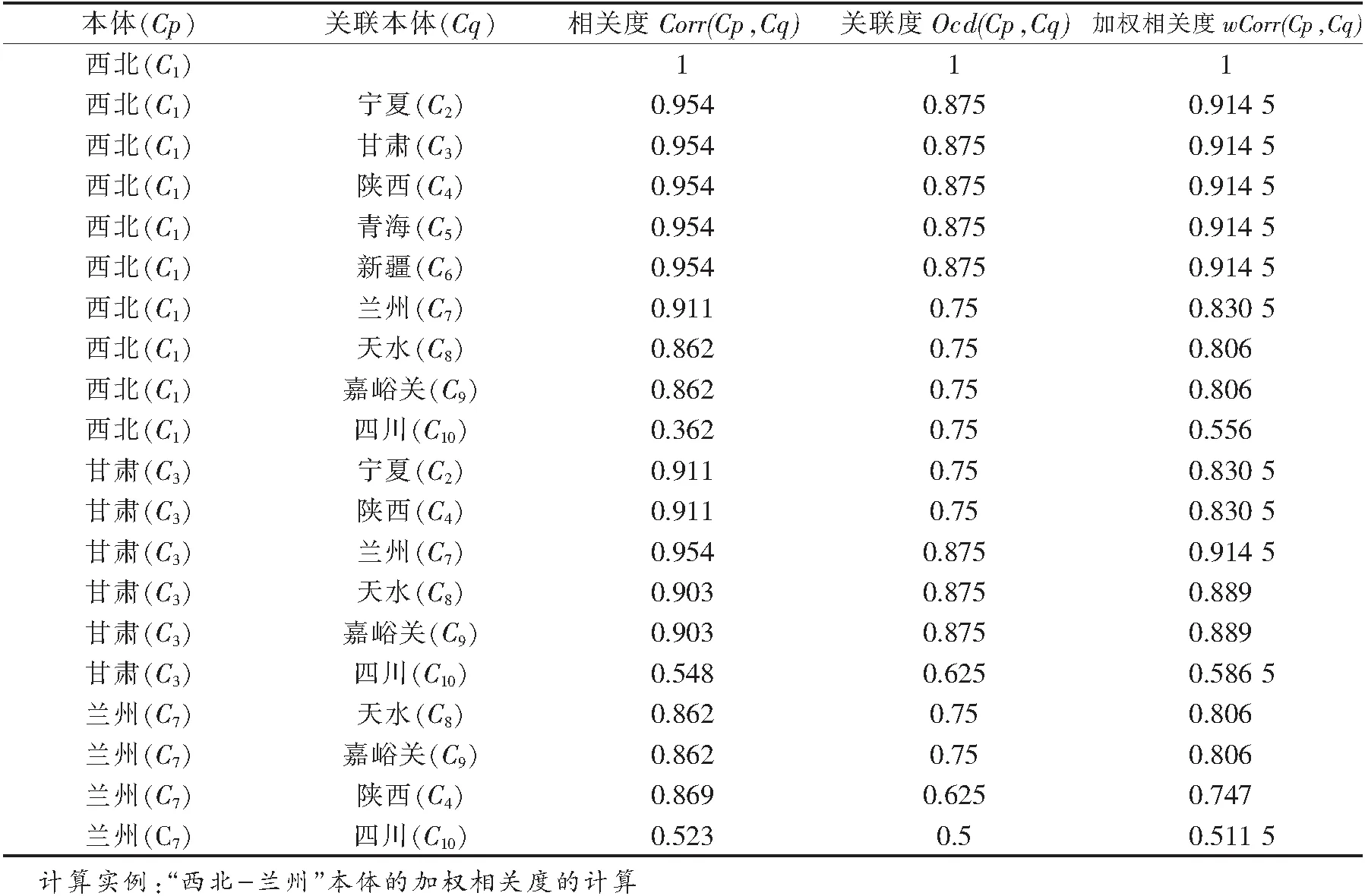
表3 本体类与其他相关联本体间的相关度值
Dist(西北,兰州)=2; Distmax= 4
wCorr(西北,兰州)=0.5×0.911+0.5×0.75=0.8305
分析表2可以得出以下结果:
1)“西北”本体和“宁夏”“甘肃”“陕西”“青海”“新疆”本体间的相关度与“甘肃”本体与“兰州”本体的相关度相同,并且最高.表现出它们是直接的二元关系,具有最短的语义距离,权值也最高.
2)“西北”本体和“兰州”本体的相关度高于“西北”本体和“天水”“嘉峪关”本体的相关度,这是因为兰州实验假定了兰州作为省会,地位略高于天水、嘉峪关的假设,赋予“西北—兰州”较高的权值,而天水和嘉峪关都是地级市,赋予相同的权值.
3)“西北”本体和“四川”本体的相关度相对较低.这是因为在本实验中,基于空间本体的“包含”关系比“相接”关系更重要的观点,而赋予“西北—四川”本体相对较低的权值.
4)本体树枝叶越茂盛,层次越向下,本体相关度就越小,这一点可以从表3的“兰州”本体与其他本体的相关度值和“西北”本体与其他本体的相关度值看出来.“甘肃—天水”本体的相关度(0.903)高于“兰州—天水”本体的相关度(0.862).
5)“兰州—天水”本体的相关度(0.862)小于“兰州—陕西”本体的相关度(0.868),这是因为本实验将“西北—甘肃”和“甘肃—兰州”的权值都设置成9不尽合理,需要对合理的权值设置做进一步的研究.但是经过加权相关度计算,“兰州—天水”本体的加权相关度(0.806)大于“兰州—陕西”本体的加权相关度(0.7465),因为兰州和天水市都属于甘肃省,二者之间的关系紧密度要大于兰州与陕西省的关系.从“兰州—陕西”本体的加权相关度(0.7465)和“兰州—四川”本体的加权相关度(0.662)来分析,陕西省相比较四川省与兰州市的拓扑关系紧密,这是因为陕西省和兰州市同属于西北,而四川省与兰州市只是在甘肃省这个节点上有邻接关系.这一结论充分验证了经加权相关度计算后的结果与实际行政区划本体在地域空间上的一致性,因而计算结果更合理也更准确.
基于上述分析结果,在应用到空间语义检索场景中,当用户输入“西北”这个主题词时,如果直接匹配到“西北”这个本体,则语义相关度为1,即完全相关;如果通过推理匹配到了与“西北”本体相关的其他本体,则匹配到“宁夏”“甘肃”“陕西”“青海”“新疆”本体的结果排在前面,接着是“兰州”“天水”“嘉峪关”本体,最后才是“四川”本体.
通过分析可知,面向特定的应用,赋予本体关系不同的权值,计算得到的相关度符合预期效果.
5 结束语
语义相关度计算是自然语言处理中的重要课题[19].本文基于地理本体的概念层次树所提供的丰富的语义信息,探讨了基于地名本体的空间数据语义加权相关度算法,不仅考虑了字符串的匹配,同时考虑了空间本体语义关系的相关性和关联性,使语义检索相关度计算更具有合理性和准确性.通过地名本体实例加以验证,按本算法获取的相关度值能较好地体现地名本体树中不同概念对的重要程度,进行相关度值按从大到小的排列顺序的语义检索结果符合实际情况,从而验证了该算法在地理信息语义检索应用中可以达到良好的效果,为相关度计算提供了一种新思路.
本算法是基于地理信息系统的空间拓扑理论,并按照本体树自上而下提出的,考虑了各种空间拓扑关系在不同语义检索应用中重要程度有所不同,从而通过地名本体关系设置不同的权值来体现不同拓扑关系的重要程度.要说明的是,本体树中本体关系的权值对相关度的计算影响较大,如果权值设置不合理,使相关度计算结果与实际情况不相符合,如本例中将“西北—甘肃”和“甘肃—兰州”的权值都设置成9不尽合理.如果在查询“甘肃”,按照重要性来讲,则优先匹配到“兰州”,而不是“西北”,如果综合考虑空间距离要素和信息量等因子,基于地名本体的相关度计算结果将更趋完善,这也是本算法研究进一步努力的方向.
