基于链路内在相关性的IP网络拥塞链路丢包率推断算法
2019-09-19韩建萍张建国
韩建萍,张建国
(1.太原理工大学 a.新型传感器与智能控制教育部重点实验室,b.物理与光电工程学院,太原 030024;2.山西能源学院,山西 晋中 030600)
在IP网络中,网络链路丢包率推理是基于主动探测获得的端到端(end-to-end,E2E)路径丢包率数据以及路径通过的链路信息进行推理的研究[1]。链路丢包率推理方法分为以下三类:
1) 采用多播路由发送多播探测包,利用包与包之间的强时间相关性,推测出拥塞的链路[2-3]。此类推理方法只能应用于支持多播的网络中。如果需要采用单播模拟多播,部署成本和计算成本较高。
2) 在假设链路发生拥塞的概率相等、发生拥塞的链路个数较少等条件下,对链路丢包率进行推理[4-5]。此类方法涉及的假设条件需要基于经验分析或理论论证,否则假设条件是否成立是此种推理方法是否可行的争论点。
3) 基于路径的多次探测结果,求取路径的均值、方差值,用于链路丢包率的推理[6-8]。此类方法需要多次发送探测包,容易造成网络拥塞。
通过对已有研究分析可知,方式1)主要集中解决多播网络中的链路丢包率推理问题,方式3)的多次探测方式,对网络数据包的正常发送和接收产生一定的影响。本文采用方式2)中的链路丢包率推理算法。但是,已有的方式2)的研究中,需要假设子链路或通过率较高的路径中的链路作为不丢包链路、或者假设共享数目最多的链路为丢包链路,这种假设缺少有效的推理和证明。为解决此问题,本文提出了基于链路内在相关性的IP网络拥塞链路丢包率推断算法(LICA)。首先,对探测路径中网络链路的相关性进行了分析,基于变形的高斯约旦消元法,将探测矩阵划分为多个独立的子集;其次,针对每个独立子集,建立基于贝叶斯网络的链路拥塞推理模型,并基于每条链路的拥塞贡献率推理链路拥塞概率排序集合;最后,基于代数模型推理求解化简后的非奇异矩阵的唯一解,从而得到拥塞链路的丢包率。在性能分析部分,通过与相关算法比较,验证了本文算法的性能优势。
1 问题描述
假设探测得到的路径集合为P={P1,P2,…,Pi},包含的网络链路集合为L={l1,l2,…,lj}.基于代数模型将网络拓扑和其上的探测定义为路由矩阵A.该路由矩阵包括M行、N列,其中,M行代表M个探测路径,N列代表N个网络链路。矩阵元素Aij=0表示探测路径Pi没有经过网络链路lj.矩阵元素Aij=1表示探测路径Pi经过网络链路lj.以图1的网络拓扑为例,如果存在表1中所示的探测路径P1,P2,P3,P4,P5,P6,可以得到图2所示的路由矩阵A.
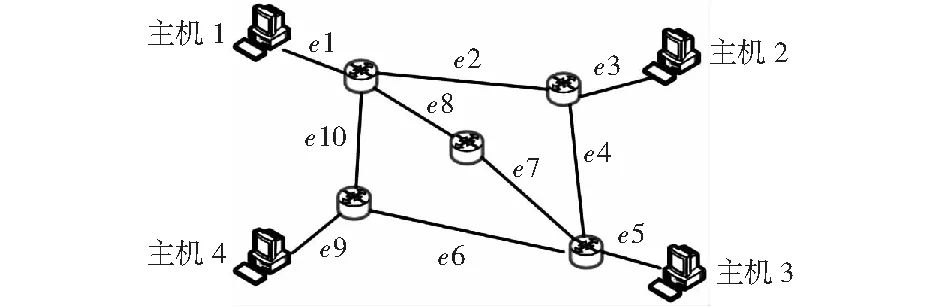
图1 网络拓扑举例Fig.1 Example of network topology

路径通过的链路通过率P1:H1→H2e1→e2→e30.77P2:H1→H3e1→e8→e7→e51.0P3:H1→H4e1→e10→e90.85P4:H2→H3e3→e4→e50.61P5:H2→H4e3→e4→e6→e90.39P6:H3→H4e5→e6→e90.59

在IP网络的性能管理中,路径的通过率等于该路径所通过的链路的通过率乘积,如公式(1)所示,其中,使用Pri表示探测路径Pi的通过率,使用lrj表示网络链路lj的通过率。对公式(1)的两边取对数后,公式(1)变为公式(2)。对于所有的探测路径P和网络链路L构成的集合,公式(2)可变为公式(3)。如果令Yi=lgPri,Xj=lglrj,则公式(3)可简化为公式(4)。由于探测路径由网络链路组成,矩阵A属于列不满秩的矩阵,所以,矩阵A不存在唯一解,不能在已知路径通过率、路径与链路关系的条件下,计算出每条链路的通过率。
(1)
(2)
{lgPr1,lgPr2,…,lgPrM}=
(3)
Y=AX.
(4)
2 网络链路丢包率推理算法
2.1 网络模型化简


(5)
(6)
2.2 链路拥塞推理模型构建


图3 基于贝叶斯网的链路拥塞推理模型Fig.3 Link congestion reasoning model based on Bayesian network
节点xi发生拥塞的概率p(xi)可以通过经验积累或多次探测后求解两种方式获得[6]。因为基于贝叶斯网的链路拥塞推理模型中的独立链路序列都已发生拥塞,而且已计算出其通过率,所以,节点yj发生拥塞的概率p(yj)的取值为p(yj)=1.使用pro(xi)表示至少有一个独立链路序列发生拥塞是由当前链路xi发生拥塞而产生的概率,计算方法见公式(7),其中,p(yj)表示节点yj发生拥塞的概率,p(xi|yj)表示节点yj发生拥塞是由于节点xi发生拥塞导致的概率,∏yj∈Nxi(1-p(xi|yj)p(yj))表示与当前链路xi相关联的所有独立链路序列的集合都不在集合Nxi中,其中Nxi表示所有独立链路序列中包含当前链路xi的集合。根据贝叶斯公式,公式(7)中p(xi|yj)的计算方法如公式(8)所示。由节点yj的定义可知,节点yj代表的独立链路序列是发生拥塞的链路序列,p(yj)=1,所以,公式(7)可以简化为公式(9).
pro(xi)=1-∏yj∈Nxi(1-p(xi|yj)p(yj)).
(7)
(8)
pro(xi)=1-∏yj∈Nxi(1-p(xi|yj)) .
(9)
2.3 链路拥塞概率排序
(10)
2.4 链路丢包率推理
(11)
2.5 算法步骤及伪代码
本文提出的基于链路内在相关性的IP网络拥塞链路丢包率推断算法伪代码如下。
输入:路径集合P={P1,P2,…,Pi},链路集合L={l1,l2,…,lj},路由矩阵A,路径通过率Yi,
输出:链路通过率Xj





1) 计算公式(8)求解p(xi|yj);
2) 使用{x1,x2,…,xu}、{y1,y2,…,yv}、p(xi|yj)建立推理模型;
3) 计算公式(10)求解CCR(xi);


3 性能分析
3.1 实验环境
本文使用网络拓扑产生工具Brite生成Waxman,Barabasi-Albert,Hierarchical三种幂率网络拓扑[9]。其中,Waxman网络拓扑的特点是端到端路径经过较多的链路。 Barabasi-Albert网络拓扑的特点是端到端路径经过较少的链路。Hierarchical网络拓扑采用分级的层次型网络特性。网络拓扑的网络节点个数设置为500,每种实验数据采用20次实验结果的平均值。采用文献[10]中提出的LLRD1模型实现链路的丢包模型。LLRD1模型中的正常链路取值服从[0,0.05)的均匀分布、拥塞链路取值服从[0.05,0.15]的均匀分布。
通过对已有研究分析可知,算法LABLA[5],算法NTSPA[8]与本文解决的问题相同,并且是已知算法中性能较好的算法。为了分析算法性能,本文从链路通过率绝对误差ELPRA(Link pass rate absolute error,LPRAE)(公式12)、拥塞链路检测率RCLD(congestion linkdetection rate,CLDR)(公式13)、拥塞链路误判率RCLFP(congestion linkfalse positive rate,CLFPR)(公式14)三个方面对算法进行分析。评估的公式中,α表示链路的真实通过率,β表示算法推理出的链路的通过率,ζ表示真实的拥塞链路,ψ表示算法推理出的拥塞链路。
ELPAA=|α-β| .
(12)
(13)
(14)
3.2 性能分析
3.2.1链路通过率绝对误差
为了分析链路通过率绝对误差的分布情况,本文将3种算法求解的误差值与特定的误差取值进行比较,以结果值占比RRV(Result-value ratio,RVR)来衡量各个区间误差值的分布情况。其中RRV表示各个结果值出现次数占总的结果值出现次数的比例,如公式(15)所示,其中,μ表示某个结果值出现的次数,υ表示所有结果值出现的次数。
(15)
图4中显示了三种算法的链路通过率绝对误差的结果值占比,X轴表示链路通过率绝对误差均值,Y轴表示链路通过率绝对误差的结果值占比(%)。三种算法的链路通过率绝对误差<0.005的结果值占比都大于98%,三种算法的链路通过率绝对误差<0.05的结果值占比都约为99%,说明3种算法的链路通过率绝对误差效果都较好。

图4 链路通过率绝对误差的结果值占比Fig.4 Comparison of theresult value ratio of the link pass rate absolute error
3.2.2拥塞链路检测率
图5中显示了网络拥塞率从5%增加到15%时,3种算法的拥塞链路检测率。其中,X轴表示网络拥塞率,Y轴表示拥塞链路检测率。由图可知,随着网络拥塞概率的增加,三种算法的拥塞链路检测率都在降低,但是算法NTSPA降低较多,算法LICA的拥塞链路检测率比较稳定。算法LICA的拥塞链路检测率约为96.3%,算法LABLA和算法NTSPA的拥塞链路检测率约为94.7%和91.5%,所以,在拥塞链路检测率方面,本文算法LICA取得了较高的检测率。

图5 拥塞链路检测率比较Fig.5 Comparison of congestion link detection rates
3.2.3拥塞链路误判率
图6中显示了网络拥塞率从5%增加到15%时,3种算法的拥塞链路误判率。其中,X轴表示网络拥塞率,Y轴表示拥塞链路误判率。由图可知,随着网络拥塞概率的增加,3种算法的拥塞链路误判率都在增加,但是算法LICA的拥塞链路误判率比较稳定。算法LICA的拥塞链路误判率约为3.5%,算法LABLA和算法NTSPA的拥塞链路误判率分别为4.6%和5.5%,所以,在拥塞链路误判率方面,本文算法LICA取得了较低的误判率。

图6 拥塞链路误判率比较Fig.6 Comparison of congestion link error rates
4 结束语
通过对网络链路丢包率推理的已有研究分析可知,已有研究通过假设来选择不丢包链路,并且网络拓扑比较复杂。为解决此问题,本文提出了基于链路内在相关性的IP网络拥塞链路丢包率推断算法。通过性能分析可知,相比算法LABLA和算法NTSPA,本文算法取得了较好的拥塞链路推理效果。下一步研究中,将优化本文的网络模型和推理算法,用于解决多域环境下的链路丢包率推理问题。
