基于对抗样本防御的人脸安全识别方法∗
2019-09-12李晓东
黄 横 韩 青 李晓东
北京电子科技学院,北京市 100070
引言
现在主流的自动人脸识别技术主要可以分为三类。 第一类为集合特征法,这类代表方法有模板匹配法[1]、弹性图匹配法[2]等。 第二类是基于子空间的方法,这类代表方法有主成分分析[3]、线性判别分析[4]、独立分量分析[5]等。 第三类为基于学习的方法,这类代表方法有基于神经网络人脸识别方法[6]、基于稀疏表示人脸识别方法[7]等。 2014 年,Szegedy 等人首次提出深度神经网络并不是完美的,在计算机视觉领域应用时尽管效果很好,但是却很容易被微小,人类肉眼难以察觉的向量扰动,即这种向量增加到图像上,图像很难被看出有明显差异,但是深度神经网络对这类图片会得到错误结果[8]。 这种微小难以察觉却能扰动深度神经网络的向量被称为对抗扰动,而增加了对抗扰动的图片被称为对抗样本。 并且进一步发现,这种对抗扰动生成的对抗样本甚至可以欺骗多个深度神经网络模型。自此以后,出现了多样化的对抗攻击研究。 2017年,Su 等人提出了一种一个像素攻击的对抗样本生成方法[9], Sarkar 等人提出了UPSET 和ANGRI 两个深度神经网络攻击算法[10]。 一个像素攻击方法中尽量少的改变图像中像素点而实现对目标模型的攻击,利用差分算法对图像像素进行迭代生成子图像,尽可能少的改变图像像素个数,一般为1,3,5 个图像像素的改变,原则上像素改变的个数越多,攻击效果越好,但是为了保持扰动不被察觉,尽量少改变图像像素。Moosavi-Dezfooli 等人提出一种不针对具体图像的算法——通用对抗扰动[11]。 该方法为白盒攻击,生成一个通用扰动向量,这个通用扰动向量对数据集上大量照片有效,可以实现错误分类[12]。 Moosavi-Dezfooli 还证明该方法不仅对ResNet 网络攻击有效,还具有很好的泛化能力,在跨模型与跨数据集情况下依然具有很好效果。在防御对抗扰动方面主要有三种方法。 第一种针对目标模型改变训练过程或者训练数据集,第二种为针对目标模型修改其网络,第三种增加一个新网络作为检测器检测图像是否加有扰动[13][14][15][16]。 该论文目的为实现能够防御来自一个像素攻击和通用扰动攻击的人脸安全识别,利用其产生的对抗样本对人脸识别模型进行微调(fine-tuning)训练以提升对抗样本防御能力。
1 人脸图像数据集收集
现有的facenet[17]模型大多是利用西方人脸图像构成的数据集来训练生成。 西方人的长相实际上和东方人是有很大区别的,所以为了使模型更适合国内使用,在原来利用西方人脸图像构成的数据集训练的基础上,增加一些东方人的图像数据进行训练,提高模型在东方人数据上识别的准确率。 另外还采用对数据集中人脸图像数据做随机变换来提高整个模型的性能。
为了提高模型在国内实际应用效果,需要采集大量东方人脸图像数据来对模型做训练。 采集的过程主要利用爬虫的方式,从网上爬取大量人脸图片。 然后将不适合作为训练的人脸图像过滤掉。 人脸有遮挡,有阴影,或者表情太夸张等等问题的图片都是不适合作为训练数据。

图1 合适图片与不合适图片示意图
如图1,上面一行图片为不合适作为数据集的图片,不合适图片的问题依次为脸部有异物遮挡,照片不够正面,脸上有饰品(眼镜),侧脸照片并且光照太强,妆容太重,表情太夸张等等。过滤掉不合适的图片,最后得到新的100 类的图片,每类设定20 张图片。 不够20 张图片的将现有图片采用随机裁剪,翻转等技术构建新的图片,最后得到20 张图片。 faces94 数据集有152个类,每个类有20 张图片。 将这些数据与faces94 数据集合并形成一个新的数据集newfaces94,这个新的数据集有252 个类,每个类中20 张图片。
2 对抗样本生成
2.1 一个像素攻击法生成扰动
利用一个像素攻击方法来生成对抗样本。该攻击办法主要利用差分进化算法,对测试集图像的每个像素迭代修改生成子图像,然后测试每个子图像的攻击效果,将攻击效果最好的子图像作为为对抗样本。 这个方法可以以最小程度的改变图像,生成可用的对抗样本,在最好情况下可以只修改一个像素就达到很好的攻击效果。另外与其他攻击方式不同的是一个像素攻击法利用改变的像素的数量衡量攻击的强度,控制像素的修改个数保持扰动足够小而不被察觉,而其他攻击方式则是控制整个图像修改的幅度。 一个像素攻击法中的对抗样本生成实际上是一种包含限制条件的优化问题。 设输入图像为X=(x1,...,xn)。f为一个分类器,v(x)=(v1,...,vn)为对抗扰动向量,f表示类别标签,ft(X) 表示图像X 属于类别t 的概率,d 为最大修改器限制。对抗样本生成转为包含限制条件的优化问题:

对于单像素攻击,将d 设置为1。 这种方法的优点是可以高概率找到全局最优解,不用计算梯度,降低了计算量。 并且属于半黑盒攻击,只需要得到黑盒的类别概率而无需知道网络的内部参数。 根据一个像素攻击法针对Faces94 数据集生成对抗扰动样本。 缺点是需要为每一个图像生成特定的对抗样本,在数据集上没有泛化能力。
2.2 生成通用扰动
通用扰动具有以下的三个特点。 第一是生成通用扰动与图片无关,在数据集上具有很好的泛化性。 第二是范数很小,所以加上这个通用扰动对图片本身的结构的改变并不是很大,扰动对于图像是不可知的。 第三是对于同一个数据集生成的通用扰动跨模型有效,即在模型A 上生成的通用扰动对于模型B 在一定程度上也是有效的。 通用扰动并不是唯一的,即对于一个深度神经网络模型可以生成多个不同的通用扰动。
记μ 是图片空间Rd中的分布,采样获得图片集X={x1,x2,…,xm},是分类器函数,扰动向量v∈Rd。v满足以下约束:
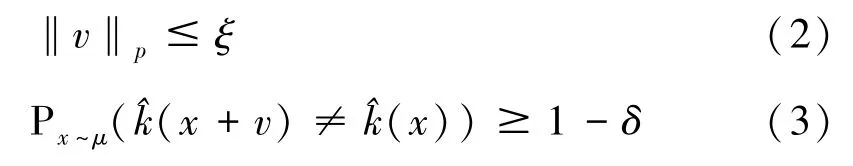
上述公式中ξ 控制扰动的范数,δ 用来量化愚弄率。 整个生成算法是基于v=0 的初始情况下进行迭代,最后生成对抗攻击效果最好的v。在迭代计算的整个过程中,如果当前的v 不是一个有效扰动,则使得
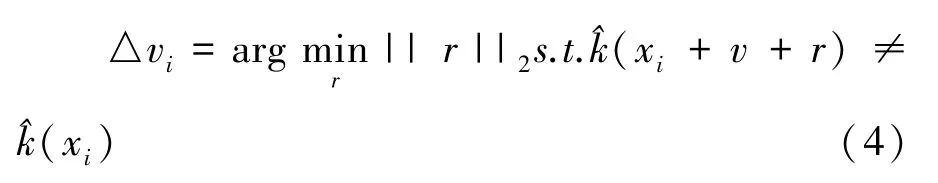
再记投影操作为:
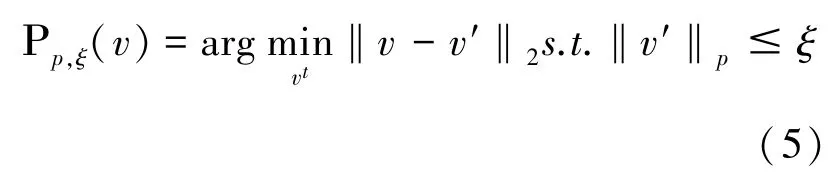
则v的更新法则为:

记Xv={x1+v,x2+v,...,xm+v},则迭代停止条件为:

根据扰动生成的算法,生成1 个通用扰动。然后将通用扰动加在测试集上的图片生成对抗样本后再验证。
2.3 生成扰动数据集
在Faces94 数据集上生成对抗扰动样本,Faces94 数据集上包括152 个类,每个类20 张图片,共有3040 张图片。 将Faces94 数据集分为两个数据集,一个为干净测试集d1(没有增加扰动),另一个为扰动测试集d2。 两个数据集都包含152 个类。d1中每个类包含10 张人脸图像,d2中每个类有10 张人脸图像。 利用上述的两种方式针对中科院自动化所基于facenet 结构在Webface 数据集上预训练好的模型20181108-102900在d2上分别生成的对抗样本构成新的扰动测试集d2′。 另外由于生成的通用扰动是跨模型的,所以再增加一个利用其他模型生成的通用扰动生成的对抗样本对模型进行测试。 最后得到的扰动测试集为三个集合,分别为一个像素攻击方法生成的扰动数据集d2-1′, 针对模型20181108-102900 的通用扰动方法生成的扰动数据集d2-2-1′, 以及针对其他深度神经网络模型生成的通用扰动形成的扰动数据集d2-2-2′。
使用20181108-102900 模型对以上数据集进行测试,结果发现其对于d′2-1的识别成功率只有87.53%,对于d′2-2-1的识别成功率为96.97%,而对于d1与d′2-2-2均有100%的识别成功率,说明通用扰动的泛化性弱。
根据上述生成对抗样本的方法,将new-Faces94 中的人脸图像数据划分成训练集,验证集,测试集,比例为8 ∶1 ∶1。 训练集、验证集、测试集的每个类分别包含16、2、2 张图片。 在训练集、验证集、测试集上生成对应的对抗样本。 将对抗样本分别加入对应的数据集中。 训练集最终有152 个类,每个类64 张图片;验证集最终有152 个类,每个类8 张图片;测试集最终有152个类,每个类8 张图片。 将其投入对20180408-102900 的训练测试。
3 模型介绍
3.1 facenet 架构
本文使用的facenet 人脸识别算法不同于常规的网络结构,具体的结构设计图如图2 所示。

图2 Facenet 整体结构设计图
如图2 所示,facenet 和常规的深度神经网络结构是两种概念。 facenet 中可以用各种深度神经网络。 对于facenet 来说,可以将深度神经网络结构看作是一个黑盒子,即不用管具体采用何种神经网络,作用都是一样的。 不同的是这些神经网络都需要将softmax 层去掉。 设输入图像为x,则通过上述图中的Deep Architecture 得到结果f(x)。 然后再经过L2 对f(x) 进行归一化。然 后 再 利 用 Triplet loss ( anchor, positive,negative)对这个模型训练,端对端的学习将一个图像变换到欧式空间上。 对于每一个人脸图像可以得到一个128 维的数据作为其特征数据。在实际应用中,训练得到完整的模型以后可以将这个模型用作特征提取器。
3.2 Deep Architecture 结构
本文使用的预训练好的模型20181108-102900 中Deep Architecture 采用的具体神经网络为Inception resnet v1 网络。 Inception resnet v1网络结构如图3 所示,但用在facenet 结构中时需要将softmax 层移除。
4 模型微调
将训练集图像数据作为训练数据,对原始预训练好的模型进行fine-tuning。 在微调训练开始之前需要重新设置学习率。 并且学习率要设置为随着迭代次数的增加而变小。 相对于原来的初始的学习率将学习率降低设置为0.01。 考虑到GPU 性能问题将batch_size 值设置为90。

图3 Inception resnet v1 网络结构图
预训练好的模型之中没有softmax 层,所以不需要对softmax 层做调整。 因为训练集数据不够多,所以为了防止过拟合现象,增加了一个验证集。 过拟合(over-fitting),一般是指在机器学习或者深度过程中由于训练数据集较小,学习效果太好,导致模型学习到一些无用特征。 这样的模型在测试集上表现很差。 在每个迭代期的最后通过计算在验证集上的识别准确率来判断是否需要提前停止训练。 如果在验证集上分类准确率以及饱和,将停止训练。

图4 验证集上识别率
每一个epoch 结束表示使用训练集中的全部样本训练一次完成,实际上为一次迭代过程。在实际fine-tuning 中,采取提前终止的方式防止过拟合问题。 在每一个epoch 结束时,计算模型在验证集的识别准确率,将截止目前最好的验证集识别准确率记录下来,在连续20 个epoch 都没有更新最好记录时,判定识别效果不再提升,停止迭代。 从图4 中可以看出准确率最好为98.78%,在迭代次数为80 时训练完成以后停止迭代。 这个新的模型为20181108-102900。
5 实验结果
因为所用模型没有softmax 层所以没有办法直接用于人脸识别分类测试,而是用于特征提取器。 利用原始模型和新的人脸安全识别模型在验证集上分别训练生成SVM 分类器1,分类器2后在测试集上检验分类器的识别效果。 这个测试集数据由四部分组成,分别为测试集1 干净图像,测试集2 第一种攻击生成的对抗样本,测试集3 第二种攻击生成的通用扰动形成的对抗样本,测试集4 第二种攻击生成的另一种通用扰动形成的对抗样本。 在以上四个测试集上检验分类器人脸识别的效果。 测试结果如表1 所示:

表1 人脸识别准确率
从表中数据可以看出,经过fine-tuning 后得到的模型20181108-102900 在正常图像上的识别效果很好,与原模型的效果相比人脸识别准确率在新构建的含有东方人脸图像数据的数据集中没有下降。 在第一种攻击方法生成的对抗样本数据集上,人脸识别准确率为94.65%,与正常数据集上识别准确率相比有所下降,但与未fine-tuning 的识别模型在此类数据集上的识别正确率相比很大提高。 而模型20181108 -102900 在通用扰动形成的对抗样本上识别的准确率与在普通数据集上识别的准确率保持一致。通用扰动不能再成功影响这个模型。 从这些数据可以看出模型20181108-102900 与原始模型相比在人脸识别方面对东方人脸的人脸识别准确率更高,识别效果更好,对于对抗样本攻击的防御能力进一步提高扰动,实现人脸安全识别。
6 结论
本文首先介绍了基于同态加密的人脸安全识别方案中所用到的深度神经网络模型结构facenet 以及其设计原理。 在本文中还分析了几种主流对抗扰动的原理,并根据基于facenet 结构的人脸识别模型生成对应对抗样本,然后利用对抗样本对该模型进行验证。 为了进一步防御对抗样本,对原始模型进行fine-funing,最后得到人脸安全识别模型20181108-102900。 通过实验数据分析模型20181108-102900 对于东方人脸识别适应性更好,在防御对抗样本攻击方面能力显著提高,识别准确率和安全性都更高。 在人脸识别模型层级上,防御第三方利用对抗样本攻击人脸识别模型,生成了人脸安全识别模型,实现人脸安全识别。
