基于局部加权距离和的多维指标融合计算方法
2019-09-11首照宇
曾 情, 首照宇, 赵 晖, 张 彤
(1.桂林电子科技大学 信息与通信学院,广西 桂林 541004;2.桂林电子科技大学 机电工程学院,广西 桂林 541004)
理论教学评估体系具有多元评价主体和多维评价指标复杂的特点,建立一个科学有效的评估体系首先需要处理好多元主体和多维指标之间的关系,而评价指标的衡量界限是非常模糊和难以量化的。为了解决理论教学评估中多维指标权重分配的难题,学者们提出了很多指标融合计算的方法,目前常见的主要有AHP法[1]、Dijkstra法[2-4]、粗糙集法[5-8]和信息熵法[9-11]等单一的方法及简单的融合赋权法[12-19]等。文献[1]采用AHP建立关于资源分配的层次结构模型,构造资源分配矩阵,从而确定各资源的权重分配系数,但由于构造的矩阵具有较大的主观性,其判断结果是粗糙的。文献[5]基于改进的粗糙集条件信息熵计算各指标的权重,构建了指标体系下的改进的粗糙集-云模型,但所得到的权重只重视不同指标的表现情况,忽视了指标本身重要性的排序,其评价结果往往不太理想。文献[12]利用模糊数学原理提出了一种新的主客观赋权方法,采用线性组合法和乘法合成归一法对新提出的主客观权重进行融合,但乘法融合赋权具有较强的“倍增效应”,极易导致融合权重大的越大,小的越小。文献[16]根据评价指标体系,利用G1赋权法和Gini赋权法构造了基于客观修正主观的组合赋权方法,确定了评价指标的组合权重。文献[19]利用云模型、改进层次分析法与熵权法对膨胀土胀缩等级进行评价,根据胀缩性等级分类标准生成每个评价标准的云数字特征,建立各评价因子的云模型,计算指标融合权重值。
以上这些传统的指标融合计算方法只注重评价指标融合的科学性,而未考虑评价过程中不合理数据的处理。鉴于此,提出一种基于加权距离和的多维指标融合计算方法,使评价指标融合更合理的同时还利用局部加权距离和的思想对评价数据进行清洗过滤,检测并剔除可能对最终评价结果产生较大影响的不合理数据,将更科学的指标融合权重和更合理的评价数据进行全面融合,使评价结果科学化。
1 相关理论及定义
本研究用AHP确定主观权重系数,用信息熵确定客观权重系数,采用离差最大化的思想将主客观权重系数进行融合,得到多维指标融合权重系数。将指标融合权重系数与经过局部加权距离和处理后的评价数据进行再次融合,输出最终评价值。
1.1 多维指标融合
1)主观权重系数获取方法:AHP。根据评价指标体系的内容,考虑本层次的各个因素对上一层次指标因素的影响程度,利用1~9标度法将同层次的因素进行两两比较,构造n阶判断矩阵C,归一化处理后导出主观权重系数
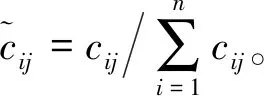
2)客观权重系数获取方法:信息熵。假设有n个评价指标及m个评价对象,评审专家对指标进行评分,经过规范化得到数据矩阵A=(aij)m×n,若第j项属性指标下的第i个评价对象指标值权重为
第j项指标的熵值为
则属性指标j的权重系数
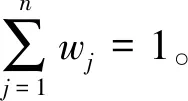
3)主客观权重融合方法离差最大化。假设有l种具体的赋权方式对n个属性指标计算权重系数。设第k种赋权方式计算出的权重向量值为
Wk=(w1k,w2k,…,wnk)T,k=1,2,…,l,
其中,
记融合赋权
Wc=(wc1,wc2,…,wcn)T,
令Wc=ψ1W1+ψ2W2+…+ψlWl。其中,ψk≥0,且
令分块矩阵
Wb=(W1,W2,…,Wl),Φ=(ψ1,ψ2,…,ψl)T,
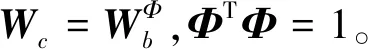
(1)
若令
为n维行向量,则目标函数J(Wc)可表示为J(Wc)=B1Wc,将J(Wc)记为F(Φ),离差最大化的指标融合赋权即可转化为最优化问题,记为如下模型:
maxF(Φ)=B1WΦ,ΦTΦ=1,Φ≥0。
(2)
1.2 相关定义
为了更好地描述基于局部加权距离和的数据处理方法,对方法中使用的相关定义概述如下。
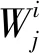
(3)

(4)
(5)
其中d(xi,xj)为对象xj到xi的欧氏距离。
定义3消除因子。消除因子用近邻距离加权和来表示。对于任意自然数k,定义对象Xi的k最近邻距离加权和为对象xi的k最近邻距离加权求和,用F(xi)表示,计算方法为
(6)
定义4判决准则。数据对象xi的判决阈值T由其k最近邻距离加权和F(xi)的均值和标准差来确定,计算方法为
T=δmean(F(xi))+mδstd(F(xi))。
(7)
其中:m为常数;δmean()为均值函数;δstd()为标准差函数。均值反映样本实例的总体情况,而标准差能反映样本的偏离程度。当数据对象xi的k最近邻距离加权和F(xi)>T时,则将其判别为不合理数据对象。
2 基于局部加权距离和的多维指标融合计算模型
基于局部加权距离和的多维指标融合计算模型如图1所示。评价数据经过DPLWD方法处理,剔除可能对综合评价产生较大影响的不合理数据对象,然后利用离差最大化将AHP得到的主观权重与信息熵得到的客观权重进行指标融合赋权,再将处理后的数据与指标融合权重进行评价过程的融合计算,最后导出最终评价值。
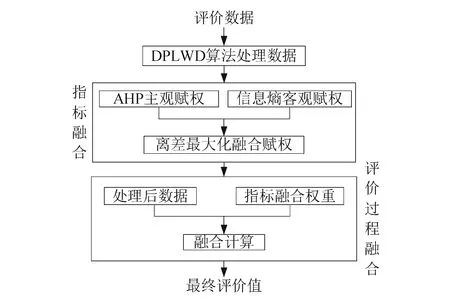
图1 基于局部加权距离和的多维指标融合计算模型
2.1 DPLWD方法及验证
2.1.1 DPLWD方法描述
基于局部加权距离和的数据处理(data processing based on local weighted distance,简称DPLWD)方法主要实现对数据集中不合理数据对象进行检测并剔除。其大致过程为:对于从高校评价体系中得到的数据集D,包含N个数据对象,即D={x1,x2,…,xN}。假设每个对象x包含n个属性。根据初始设置的最近邻个数k及距离矩阵确定各数据点k最近邻集合,利用式(3)计算近邻距离权值w,根据式(5)、(6)对数据集对象加权求和得到消除因子F(xi),通过式(7)计算出判决阈值来判定最终的不合理数据,剔除不合理数据集,并得到最终数据集D′。
DPLWD方法具体流程如伪代码方法1所示。
方法1基于局部加权距离和的数据处理方法。
输入:数据集D,最近邻个数k,阈值调整系数m。
输出:剔除后数据集D′。
初始化参数k,m
计算得到数据集D的距离矩阵M
for eachxi∈Ddo
根据距离矩阵M,得到数据点xi的k近邻距离集合Nk(xi)
根据式(3)计算数据点xi到邻域内其它点的权值向量w
根据式(5)计算数据点xi到邻域内某点xj的加权距离f(xij)
根据式(6)计算数据点xi的消除因子F(xi)
end for
根据式(7)计算判决阈值T。
for eachxi∈Ddo
ifF(xi)>Cthen
剔除数据点xi
end if
end for
return 剔除后数据集D′
2.1.2 DPLWD方法验证
1)仿真数据集实验与分析。
为了验证该方法可行性,采用可视化的二维和三维数据集进行验证实验,验证结果如图2、图3所示。
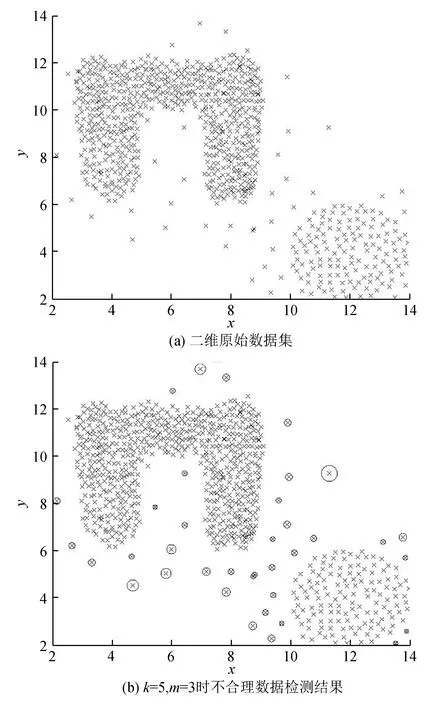
图2 二维数据集验证
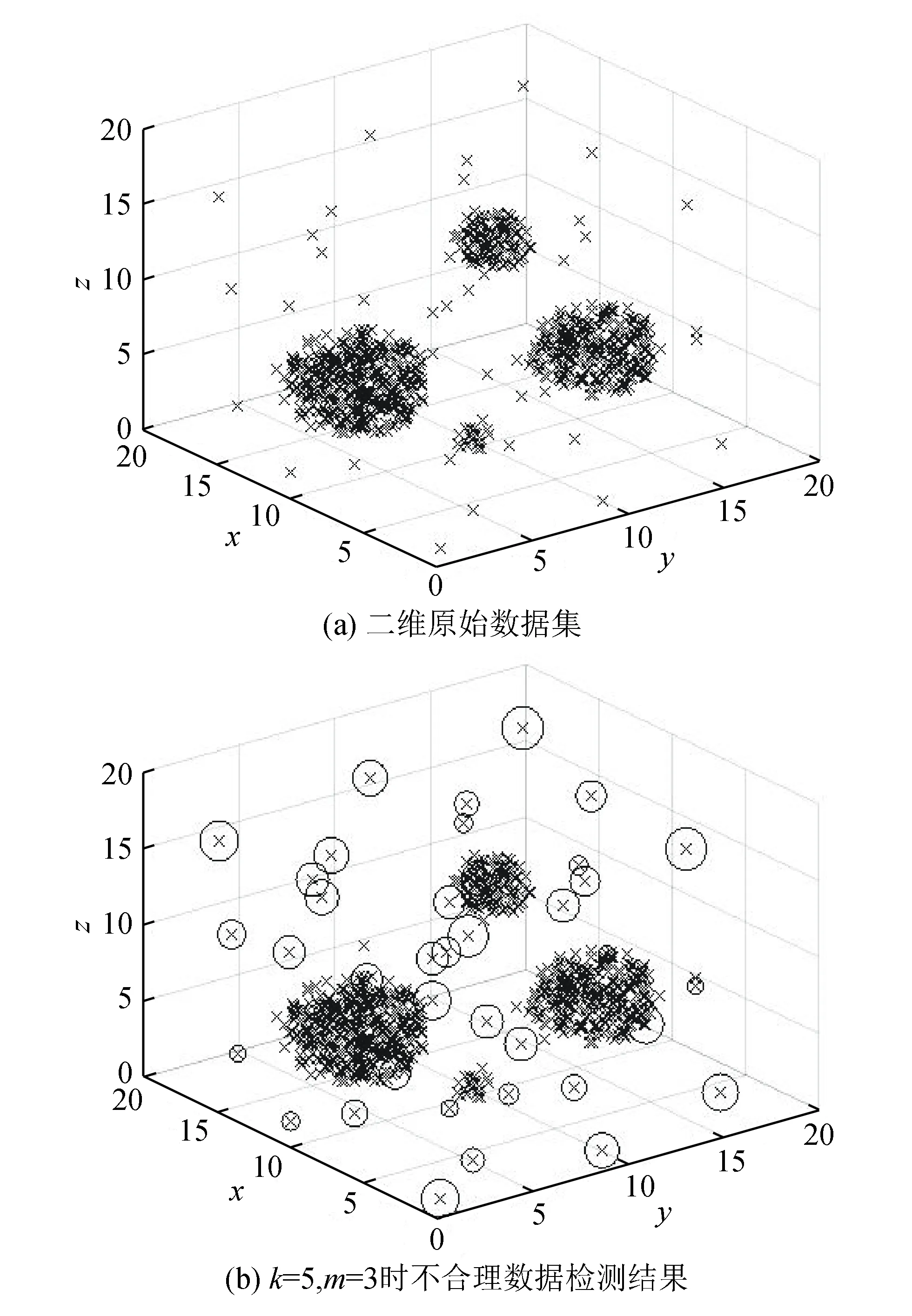
图3 三维数据集验证
图2为包含1000个数据点的二维数据集,且有2个密度分布不均匀的簇。图3为包含860个数据点的三维数据集。
从图2(b)、图3(b)可看出,不合理数据对象点已经被圆圈标记出,且在数据集中圆圈的半径代表了不合理的程度,半径越大,不合理程度越大,越有可能是不合理数据点。在图2(a)中数据集有2个密度差异较大的簇,且簇的分布不规则,运用DPLWD方法能将被簇包围的不合理数据点检测出,在图3(b)中的三维数据集中同样也具有较好的检测效果。
2)真实数据集实验与分析。
通过真实数据集实验来对比验证DPLWD方法的性能优势。表1为来自于UCI机器学习库的13个真实数据集,他们具有不同的规模大小和维度。本实验环境为Matlab R2016a、Intel CPU 2.5 GHz、内存8 G。DPLWD方法只需确定k最近邻距离个数,利用人工干预的方法确定最佳的k值,并与经典的LOF方法[22]、ABOD方法[23]和SVM检测方法[24]在运行时间、精确度和召回率曲线下的面积(area under the precision-recall curve,简称AUCPR)等性能指标进行对比,结果如表2、表3所示。
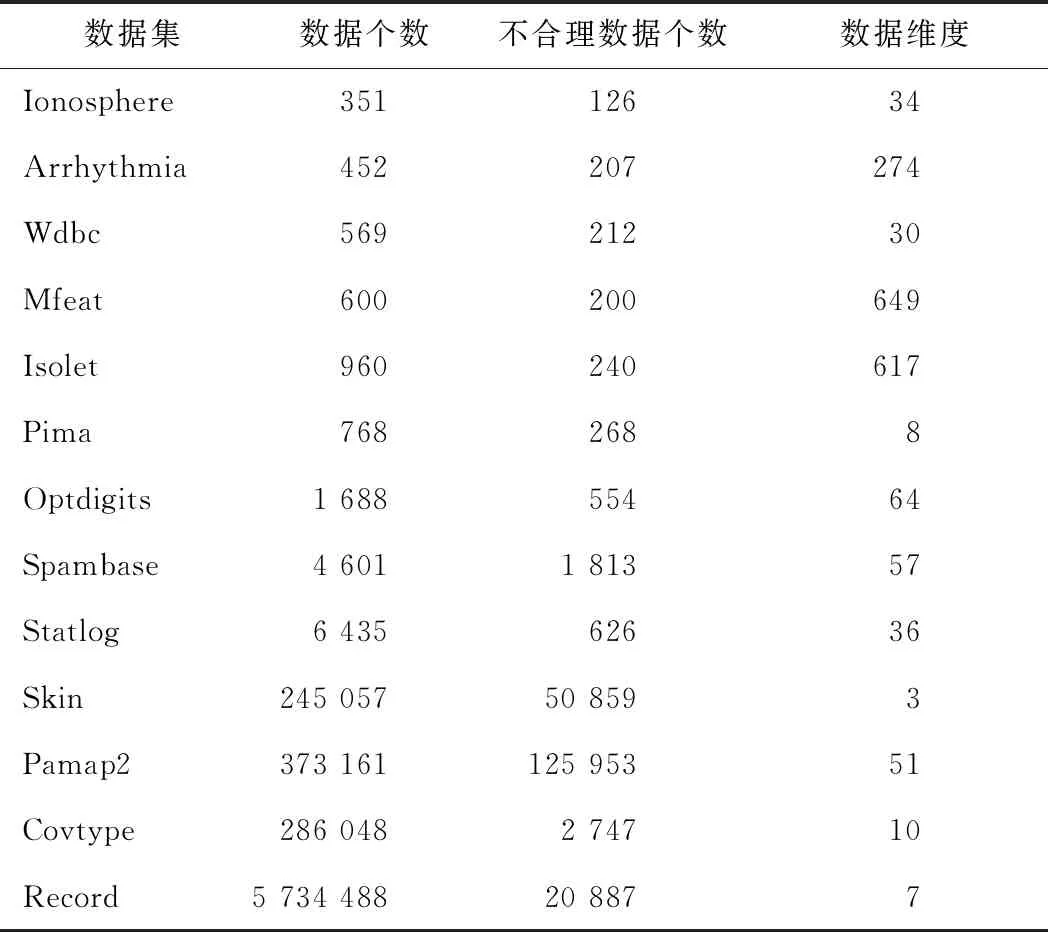
表1 实验数据集
从表2可看出,DPLWD方法的运行时间明显少于LOF、ABOD和SVM三种方法的运行时间。在数据集Pima、Skin、Covtype和Record中,它们是低维的数据集对象,且属于数值型的数据集,相比于LOF、ABOD和SVM方法,DPLWD方法有更大优势。在大规模数据集Record上,LOF和SVM两种方法出现了计算NP问题。随着维度的增加,如Mfeat和Isolet达到数百维时,DPLWD方法同样能表现出好的效果,且当数据集规模较小时,本方法有明显优势,随着维度的增加,同样能够表现出较好的效果。
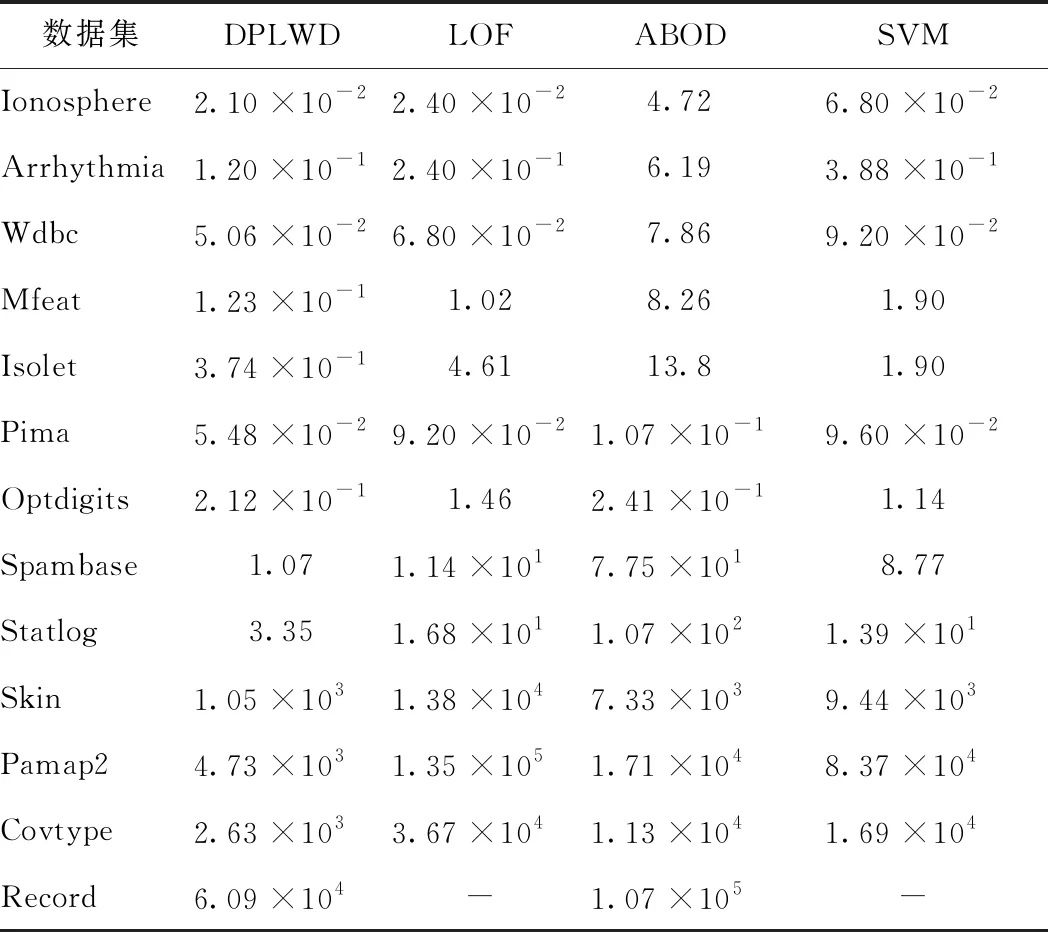
表2 数据集实验运行时间 s

表3 精确度-召回率曲线下面积(AUCPR)
表3为各方法得到的AUCPR值,AUCPR值反映了分类的好坏,AUCPR值越大,表明分类结果越好。从表3可看出,在运用DPLWD方法时,有8个数据集的AUCPR值大于其他3种方法,同时该方法的AUCPR均值也大于另外3种方法,表明DPLWD方法具有明显优势。
通过实验验证了DPLWD方法具有2个特点:1)对于小规模的样本数据集,DPLWD有着更高的精确度;2)在保证精确度的情况下,DPLWD方法有更短的运行时间。
综合以上实验数据分析可知,DPLWD方法更加适用于大规模多维数据集以及密度分布不均匀的空间模型数据集,能有效地剔除不合理数据对象。
3 实例分析
为了分析基于局部加权距离和的多维指标融合计算方法的实际效果,选取某高校理论教学评价指标体系的数据。该评价指标体系包含了多元评价主体校领导、中层干部、督导和同行,每个评价主体都对应着不同的一级评价指标和二级评价指标,如同行对应的一级评价指标为教学态度、教学内容、教学组织和听课效果,其中每项一级评价指标下还分别对应详细的二级评价指标。
选取该评价指标体系下某教师一学期的所有被听课评价数据共412条,校领导、中层干部、督导和同行4个评价主体的评价数据分别为43、89、138、142条。将一条评价数据看作一个四维数据点,通过运行DPLWD方法,检测出该教师本学期被听课评价数据中存在13个不合理数据对象,其中,校领导、中层干部、督导和同行4个评价主体的不合理评价数据分别为1、2、4、6条。特别是第223个数据点的4个评价指标评分分别为50、50、60、60分,该评价数据明显偏离了其他合理数据点。为了避免不合理评价数据对象对融合计算结果产生较大影响,对检测得到的13条不合理评价数据进行了剔除,以保证评价指标与评价过程融合更加科学合理。
邀请专家担任测评者,利用AHP构造判断矩阵确定专家主观权重,利用信息熵对专家的评分向量进行处理,确定专家客观权重。将主客观权重利用离差最大化的思想由式(2)构成最优化模型进行评价指标融合计算,解出最优的多维指标融合赋权向量,其中校领导、中层干部、督导和同行4个评价主体对应的4个一级评价指标的融合权重向量分别为
(0.229,0.332,0.319,0.120)T,
(0.341,0.382,0.154,0.123)T,
(0.077,0.363,0.159,0.401)T,
(0.215,0.221,0.308,0.256)T。
校领导、中层干部、督导和同行4个评价主体的融合权重向量为(0.1,0.2,0.3,0.4)T,将剔除了不合理数据对象的399条理论教学评价数据与多维指标融合权重进行再次融合计算,可得该教师的最终评分为87.822 3分。未剔除不合理评价数据之前该教师的综合评分为87.309 7分,相比剔除不合理评分数据之后进行融合计算的教师评分低了0.512 6分,一定程度上低估了该教师的教学水平。因此,本方法所获得的教师综合评分更加客观合理,能反映出该教师的真实水平。
4 结束语
提出的基于局部加权距离和的多维指标融合计算方法不仅实现了评价指标融合,还实现了评价指标与评价过程融合,使评价结果更精确科学,且对DPLWD方法在仿真数据集上进行验证实验,都能达到预期的数据处理效果。在真实数据集上与经典LOF、ABOD和SVM方法进行对比分析,表明了该方法有较短的运行时间和较好AUCPR值。为快速得出更加合理的融合计算结果,今后将对k值的自适应性进行研究,并在时间复杂度上进行优化,使多维指标融合计算更科学、高效。
