基于机器学习的无人船目标识别系统研究
2019-09-10
(1.上海海洋大学 工程学院,上海 201306; 2.钰清(上海)信息科技有限公司,上海 201306)
在海洋战略的引领之下,大水域环保和无人船自动驾驶都成为新的研究方向。面对大水域中的垃圾处理问题,当下主要是人工清理,效率不高且危险系数高。若要开发垃圾自动回收装置和无人船自动驾驶装置,首要任务是识别出水面目标物。近年来,水面目标识别的研究也在逐步发展。庄佳园等人提出了嵌入式雷达图像采集处理系统的体系结构[1];曾文静采用改进的Mean-shift图像分割方法[2]对目标进行检测等。以上各研究都起到很好的推动作用,为了面对多目标物的检测,孟庆昕提出小样本分类器算法提高了在复杂水域环境下基于雷达被动目标检测的准确性[3],米禹丰采用卫星遥感技术对水面船舶目标进行识别检测[4]。但是对于比较小的目标物,雷达很难准确确定其类型,而遥感很难准确定位目标物。相比之下,视觉图像信息包含更多的信息,有助于多种目标物的识别。谢娜娜采用视频流的方法对船舶旗帜进行目标识别[5],马忠丽提出机器视觉识别出海岛、礁石和船只[6],识别类型比较单一,算法很难推广,尤其是在高反光性的水面,高反面具有镜面效应,前景易被识别成障碍物。文欣雨提出基于Canny算子和SVM的瓶盖缺陷检测系统研究[7],在缺陷识别方面做出很大的贡献,对水面目标检测也有很大借鉴意义。金琳提出面向光照鲁棒的目标识别的方法可以对于高反光的水面进行很好的预处理[8],对水面目标识别的研究起着一定推动作用,但是并未在预处理图像之后提出比较好的目标识别算法。随着人工智能的发展,机器视觉技术开始应用在各个领域。目标描述则是目标识别和跟踪的基础,准确有效的目标描述将是识别算法的第一步。为使目标表示更加准确,特征提取方法也获得了较大发展。常见的局部特征描述算子有HAAR-LIKE特征等。 HAAR-LIKE特征最早由Papageorgiou等人提出[9],然后经Viola提出积分图像法快速计算特征个数,最后Lienhart用对角特征对HAAR特征进行拓展[10]。而在训练器方面,Freund和Schapire提出了一个实际可用的自适应Boosting算法AdaBoost(Adaptive Boosting),为基于图像的特征识别奠定了基础[11]。随后Viola改进了AdaBoost算法[12],使得算法的速度加快。但是这些方法在水面目标识别的方面应用较少,本文借助机器视觉算法的优势,采用基于OpenCV(Open Source Computer Vision Library)框架的HAAR级联分类器进行机器学习[13],以常见的水面障碍物作为训练样本,根据毕校伟的水面无人船框架[14]设计开发无人船实验平台,将学习的结果进行实验验证,可以很好地识别出目标物体。本文还通过利用水面镜像特点,采用相位相关度法求出水岸线,避免了把岸上目标物也当成识别对象的问题。可以对船载垃圾自动清理装置和自动航行系统等的设计有很好的理论基础和数据支撑。
1 基于机器学习的目标识别原理
基于OpenCV进行机器学习环境搭建,然后利用OpenCV库在Qt[15]编译软件上建立视觉处理框架进行样本训练和结果验证。
1.1 HAAR-LIKE特征原理
HAAR-LIKE特征(也称HAAR特征)是计算机视觉领域比较常见的一种算子。HAAR特征单元在样本图片中进行遍历,计算出特定图像面积内的特征值个数。Lienhart.R在文章中指出具体特征值个数计算法[10]。假设一张24×24大小的训练样本图片,根据特征值个数计算法共有115984种HAAR特征用于特征训练。在得到样本图片的特征数量之后,为了提高训练过程中的训练速度,Viola等提出了积分图计算方法[12]。HAAR-LIKE特征都是矩形特征,在建立积分坐标系后,可以很快地计算出积分值,即计算出每个特征所有灰度值之和。
1.2 HAAR特征级联分类器原理
级联分类器是由若干个强分类器级联,而强分类器由若干个弱分类器组成。AdaBoost算法可以通过一系列弱分类器的线性组合得到一个强分类器,HAAR特征级联分类器中的AdaBoost算法是Viola改进后的一种AdaBoost算法,用viola表示,加入积分计算和级联的概念,使得算法的效率得以提高,效率提升效果如表,采用MIT+CMU测试集进行测试,以Rowley-Baluja-Kanade做比对,简称RBK。得出不同误识别情况下的识别率的大小,见表1。可以看出在改进算法后识别率得以提升。训练时需要正负样本同时参与训练,正样本为目标识别物,负样本为非目标识别物。

表1 不同识别个数下的识别率对比
Step1:给出样本(x1,y1),(x2,y2),…,(xN,yN)正样本l个,负样本m个,定义正样本的响应值为1,负样本的响应值为0。
Step2:为样本初始化权值,第i个样本的权值为w1,i。
(1)
Step3:迭代循环t=1,…,T。
① 归一化权值:
(2)
② 为每一个特征j,训练一个分类器hj,即hj只能用于特征j,而该特征j的基于权值的误差εj为
(3)
③ 在所有误差中最小的那个误差εt所对应的分类器作为此次迭代得到的弱分类器ht。
④ 更新权值:
(4)
式中,
(5)
Step4:得到最终的强分类器:

(6)
式中,
(7)
AdaBoost算法的流程主要是首先取正负样本进行HAAR-LIKE特征采集,然后用AdaBoost算法对特征值进行筛选,直到达到自己预设的阈值,如果达到则建立强分类器,否则继续训练。
训练时会带来两个问题:① 在实际运行过程中非目标障碍物的数量会远大于目标障碍物,分类器会把大量时间用来剔除非目标障碍物,导致效率低;② 在不断提高每一个强分类器的识别率的过程中,也会造成虚警率上升。
为了解决以上问题引入了级联分类器的概念,级联分类器实际上就是多个强分类器级联的结果。强分类器只会把它认为正确的样本传递给下一级,认为错误的直接丢弃。
2 基于OpenCV的样本机器学习
2.1 无人船目标识别样本准备
HAAR特征级联分类器训练时需要正负样本若干,正样本和负样本的比值决定着强分类器训练时的初始权值,这两个变量会直接决定最后机器学习的准确率、虚警率和机器学习时间。主要采用了633张泡沫样本、512张塑料瓶样本和757张电浮标样本,都处理成统一背景,样本图片大小则采用4种不同尺寸进行研究;而负样本的数量则是根据不同正样本数量来确定,以便来控制不同初始权重比。
2.2 HAAR级联分类器训练
样本准备好之后开始进行样本训练,本文采用HAAR级联分类器对正负样本训练。首先初始化权值,然后为所有目标正负样本的每一个HAAR特征训练一个弱分类器,训练时会采用不同阈值进行训练,每一次训练后会根据式(3)计算出误差结果εj,取εj最小的情况下对应的阈值,建立弱分类器。对于训练样本的每一个小区域来说,如果误差εj越小,则计算出权值wi+1,j减少,否则权值增加,更新后的权值会用于下一个HAAR特征的弱分类器训练,一直到训练完所有HAAR特征为止。而对于每一个弱分类器来说,误差εj越小,则计算出强分类中的比例系数αi增加,如式(6)可知,所有HAAR特征弱分类器与对应的比例系数的乘积做累加,然后将累加结果作为符号函数的阈值建立HAAR特征强分类器C(x)。当强分类器都被建立之后,对所有强分类器进行级联进而建立级联分类器,自此目标样本的训练完成。
在训练时有两个参数minHitRate和maxFalseAlarmRate,分别为最小识别率和最大虚警率,此两个参数需要提前设定,设定值的大小直接影响最后训练的识别率和虚警率的大小。
由于级联分类器是由各个强分类器级联而成,识别率和虚警率都是所有层级的乘积。一般训练时级数设置太少导致虚警值过高,太多导致识别率下降,本文的层级设为10级。分析了预设最大识别率分别为:0.99,0.991,0.992,0.993,0.994,0.995,0.996,0.997,0.998,0.999的情况下,最终的理想识别率。经乘积运算分析可得,在级数设为10级时,每一训练层级的预设识别率最低在0.995以上,才能保证最终有0.95以上的识别率,所以minHitRate小值设为0.995;同理可以分析出maxFalseAlarmRate对级数不是很敏感,只是设置大于0.6之后虚警率才有明显上升,所以maxFalseAlarmRate的最大值设置为0.5。此时既可以满足级联后对虚警率低的要求,又不会因为过小致每一级强分类器训练失败。
2.3 基于相位相关性法的水岸线识别
很多情况下岸上也会存在目标物,但是并不希望该系统识别,否则会造成计算量增大甚至实验失败,所以需要计算出河岸线来排除河岸线以上的障碍物,提高识别的效率。由于水岸各种各样,采用机器学习来识别,样本过于巨大,而且不具有普遍性,识别度不高。本文通过对水面和岸上的特征进行分析。观察水的镜面性可以在水域形成岸上物体的倒影,即使在水质并不是很清的情况下,也会有很明显的倒影轮廓,所以本文利用这种特性来识别出河岸线。假设一张原始图片设为f1(x,y),然后对其180°翻转得出其翻转图片设为f2(x,y),由于倒影与岸上实物有很高的轮廓重合度,所以可以假设f1(x,y)是f2(x,y)平移得来的结果,其两者关系可以如式(8)表示:
f1(x,y)=f2(x-x0,y-y0)
(8)
根据相位相关性法[17],平移量可以直接由其互功率谱的相位直接算出。由式(9)、式(10)和式(11)可以分别算出f1(x,y)和f2(x,y)的傅里叶变换[18]和互功率谱:
(9)
(10)
(11)
其中F*是F的共轭复数。对互功率谱求其傅里叶逆变换得:
(12)
由式(12)可以看出,在(x0,y0)处出现了单位冲击响应函数,理论上说在(x0,y0)处不为0,其他地方都为0。理想条件下只需要找出不为零的位置,即是原图像和翻转图像的偏移处,但是实际情况下很难出现只有一处不为0的地方,所以实际实验时是寻找最大值即为偏移处。
当求出来偏移位置的时候,便可以分析出岸边的大致位置。如图1所示,设实验摄像头在计算机界面上显示高度为H,偏移量为y0,河岸线的高度为h,根据式(13)便可得出河岸线位置。
(13)
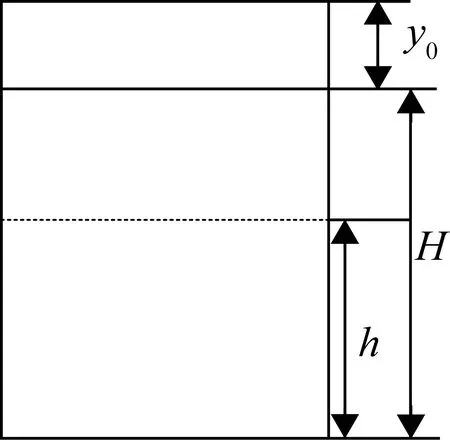
图1 偏差与河岸线关系分析图
将上述理论转化成C++语言在Qt上进行了编程实验,并且输出x0和y0的值。本实验基于无人船平台完成。无人船采用无线通信模式,主要由AP基站、上位机控制、无人船三大部分组成。AP基站的建设采用TP-LINK TL-AP450GP全向无线AP,可以在半径450 m进行通信,船载摄像头采用海康C3W高清摄像头,监视范围为120°,安装高度为20 cm,此外还有GPS、电子罗盘等辅助感知设备。该无人船装置是通过无线模块,由PC端的上位机控制系统传输指令给主控芯片STM32,根据系统控制要求,通过驱动电机来控制无人船运动,并可在PC端远程监控航行信息,远程控制其航向航速。实验船如图2所示,实验摄像头的输出画面大小为764×428,得出偏移量x0=0,y0=11.0259;最终的结果如图3所示。当识别出水岸线之后,在目标识别过程中,只需识别目标区域的最低端在水岸线以下的目标,以上目标自动过滤,提高了无人船的识别准确度和效率。
3 不同参数下的识别率和训练时间的测量
前面分析了HAAR级联分类器进行目标识别时,不仅级联级数大小、虚警值和识别率的设定值会影响机器学习的学习时间和准确度,而且正负样本的尺寸和比例也会影响机器学习的学习时间和准确度,下面进行具体分析。
3.1 不同样本尺寸的识别率和训练时间测量
训练时间是实际操作中一个很值得关注的因素,时间过短导致识别率降低,如果时间过长会因为不稳定因素导致训练失败。正负训练样本的尺寸大小不同,特征点的个数也不相同。本实验以泡沫作为目标识别物,分别选取20×20,24×24,30×30,40×40,50×50五种尺寸,取正样本633个,负样本1899个。如表2所示,根据Lienhart的特征值计算法[10]分别计算出各个尺寸的特征点个数,实验得出不同训练样本尺寸下的训练时间和识别率。

图2 无人船实物图

图3 水岸线识别结果

表2 训练样本尺寸大小与识别率和训练时间的关系
由此可以看出随着正样本的尺寸增加,特征点的个数增加,识别率和训练时间都增加。由于水岸线的识别降低了运算量,进而也提高了识别率,由表2可以看出50×50尺寸时识别率达91.98%,效果好于利用Henriques提出的KCF目标跟踪算法[19]进行同样实验得出87.56%的识别率。
3.2 不同正负样本比例的训练时间测量
不同正负样本比例下正负样本的数量不同,机器学习的时间也不同。本实验以泡沫、塑料瓶和电浮标为样本,采用40×40大小的图像,计算不同正负样本比例下的具体训练时间如表3所示,训练时间趋势变化如图4所示,具体的识别结果如图5所示。
由图4可知,随着比例的增大,训练时间不断增加,这跟负样本的数目增加有关,且训练的时间增加。电浮标的训练时间最长,泡沫次之,塑料瓶最短,主要原因是训练数量不同,训练时间与样本数量大致成正比。
3.3 不同正负样本比例的识别率测量
由式(1)可知,样本初始权值取决于正负样本的比例。需要注意的是负样本的个数过少,会导致训练过程中程序陷入死循环最终训练失败,与此相反,如果负样本过多,会导致在训练后期没有正样本参与训练,训练的精确度不高。因此,本实验将负样本与正样本的比例设定为:1.8,2.2,2.6,3.0,3.4,3.8,4.2,4.6,5.0,5.4,5.8,6.2;分别求出3种目标识别物的识别率和虚警率,实验结果如图6所示。共有8条曲线,分别表示塑料瓶、泡沫及电浮标的识别率和虚警率,此外还有识别率和虚警率的理论值。

表3 不同正负样本比例下的训练时间

图4 3种目标物在不同正负样本比例的训练时间比较

图5 障碍物识别结果示意图
经分析可知:
① 真实的识别率比理论值低,虚警率比理论值高。
② 正负样本的比例在3.0~4.2之间时,识别率比较高,虚警率比较低。
③ 不同的目标识别率不同。塑料瓶的识别率最高,泡沫次之,电浮标最差,主要原因是塑料瓶的结构更规矩,复杂度也不高。
④ 不同的目标识别物的虚警率不同。电浮标的虚警率最低,泡沫次之,塑料瓶最差,主要原因是电浮标虽然结构复杂,但是和周围环境的相似度很低,背景不易被识别成目标物,而塑料瓶的两端都是透明的,和周围环境的相似度过高。

图6 3种目标物的识别率与虚警率比较
所提出的在不同样本正负比例和不同目标的情况下提高识别率和降低虚警率,但是经过不同组的对比实验得知此算法仍有很大改进空间,首先应该在样本的种类和更复杂的目标物进行训练,这样更能够提高算法的鲁棒性。
4 结束语
本文设计无人船作为实验平台采集实验样本,采用OpenCV视觉处理框架,运用HAAR级联分类器进行机器学习,分别对泡沫、塑料瓶和浮标三种水上目标物进行了识别。
在识别训练过程中:① 级联分类器的级数、最小识别率和最大虚警值的设定都会影响机器学习的时间和识别率,经分析得出在10级级联训练时,最小识别率设为0.995,最大虚警值需设为0.5以下;② 正负样本的尺寸和比例会影响机器学习的时间和准确度,随着尺寸大小的变化训练时间接近指数增长,随着训练数目等比例增加,训练时间也接近比例增长,正负样本比值在3.0~4.2之间为最佳比例范围,此时识别率较高虚警率较低。另外在无人船自动行驶时,利用水面的镜面特性,采用基于相位相关性法的水岸线识别算法求出水岸线,准确识别出河岸线,提高了水中目标物的识别效率。并且以上算法皆具有很强的可移植性,只要有足够多类型的样本训练空间,便可以准确地判断出水面的目标物。
所设计的基于机器学习的无人船目标识别系统,为无人船自动巡航和避障系统、船载自动垃圾回收装置、河流水质污染监测无人船等设计提供了解决方案。当然本文只是在最适设定范围内有效性较好,若遇到更复杂的环境,希望能针对特征的提取对水面目标要更有针对性,更好地去观察并提取相似特征,此外也要更深度地降低水面的镜面性所带来的影响。
