基于视频分段的空时双通道卷积神经网络的行为识别
2019-09-04王萍庞文浩
王萍 庞文浩

摘 要:针对原始空时双通道卷积神经网络(CNN)模型对长时段复杂视频中行为识别率低的问题,提出了一种基于视频分段的空时双通道卷积神经网络的行为识别方法。首先将视频分成多个等长不重叠的分段,对每个分段随机采样得到代表视频静态特征的帧图像和代表运动特征的堆叠光流图像;然后将这两种图像分别输入到空域和时域卷积神经网络进行特征提取,再在两个通道分别融合各视频分段特征得到空域和时域的类别预测特征;最后集成双通道的预测特征得到视频行为识别结果。通过实验讨论了多种数据增强方法和迁移学习方案以解决训练样本不足导致的过拟合问题,分析了不同分段数、预训练网络、分段特征融合方案和双通道集成策略对行为识别性能的影响。实验结果显示所提模型在UCF101数据集上的行为识别准确率达到91.80%,比原始的双通道模型提高了3.8个百分点;同时在HMDB51数据集上的行为识别准确率也比原模型提高,达到61.39%,这表明所提模型能够更好地学习和表达长时段复杂视频中人体行为特征。
关键词:双通道卷积神经网络;行为识别;视频分段;迁移学习;特征融合
Abstract: Aiming at the issue that original spatial-temporal two-stream Convolutional Neural Network (CNN) model has low accuracy for action recognition in long and complex videos, a two-stream CNN for action recognition based on video segmentation was proposed. Firstly, a video was split into multiple non-overlapping segments with same length. For each segment, one frame image was sampled randomly to represent its static features and stacked optical flow images were calculated to represent its motion features. Secondly, these two patterns of images were input into the spatial CNN and temporal CNN for feature extraction, respectively. And the classification prediction features of spatial and temporal domains for action recognition were obtained by merging all segment features in two streams respectively. Finally, the two-steam predictive features were integrated to obtain the action recognition results for the video. In series of experiments, some data augmentation techniques and transfer learning methods were discussed to solve the problem of over-fitting caused by the lack of training samples. The effects of various factors including the number of segments, network architectures, feature fusion schemes based on segmentation and two-stream integration strategy on the performance of action recognition were analyzed. The experimental results show that the accuracy of action recognition of the proposed model on dataset UCF101 reaches 91.80%, which is 3.8% higher than that of original two-stream CNN model; and the accuracy of the proposed model on dataset HMDB51 is improved to 61.39%, which is higher than that of the original model. It shows that the proposed model can better learn and express the action features in long and complex videos.
Key words: two-stream Convolutional Neural Network (CNN); action recognition; video segmentation; transfer learning; feature fusion
0 引言
人類从外界获取信息时,视觉信息占各种器官获取信息总量的80%[1],这些信息对于了解事物本质具有重要的意义。随着移动互联网和电子技术的飞速发展,手机等视频采集设备大量普及,互联网短视频应用也如雨后春笋般出现,极大降低了视频拍摄和分享的成本,这使得网络视频资源爆炸式增长。这些资源丰富了人们的生活,但由于其数量庞大、种类繁多、内容庞杂,如何对这些视频数据进行智能分析、理解、识别成为急需面对的挑战。
人體行为识别是计算机视觉[2]领域一个重要的研究方向,其主要内容是利用计算机模拟人脑分析和识别视频中的人体行为,通常包括人的个体动作、人与人之间以及人与外界环境之间的交互行为。空时双通道神经网络可以从空域和时域两个角度表征视频的特征,相比其他神经网络模型在人体行为识别上更有优势。本文基于视频分段利用空时双通道神经网络提取空域的帧图像特征和时域的运动特征,并将各分段的空域和时域的识别结果进行融合,最后得到整段视频的行为识别分类。
1 相关工作
在传统的基于人工设计特征的行为识别方法中,早期的基于人体几何或者运动信息的特征仅适用于简单场景下的人体简单动作识别,而在背景相对复杂的情况下基于时空兴趣点的方法效果较好。这些方法首先获取视频中的时空兴趣点或稠密采样点,并根据这些点周围的时空块计算局部特征,再利用经典的特征袋(Bag of Features, BoF)、VLAD(Vector of Locally Aggregated Descriptors)或FV(Fisher Vector)等特征编码方法最终形成描述视频动作的特征向量。目前在基于局部特征的方法中,基于稠密轨迹(Dense Trajectory, DT)的行为识别方法在很多公开的真实场景行为数据库中得到了较好的识别结果,它们通过跟踪视频每一帧内的稠密采样点获取稠密轨迹,再计算轨迹特征描述视频中行为。如:Cai等[3]用多视角超向量(Multi-View Super Vector, MVSV)作为全局描述符来编码稠密轨迹特征;Wang等[4]使用FV编码改进的稠密轨迹(improved Dense Trajectory, iDT)特征;Peng等[5]使用视觉词袋模型(Bag of Visual Words, BoVW)编码空时兴趣点或改进的稠密轨迹特征;Wang等[6]基于稠密轨迹特征提出了一种视频的多级表示模型MoFAP(Motion Features, Atoms, and Phrases),可以分级地表示视觉信息。稠密轨迹能够以更广的覆盖面和更细的颗粒度提取行为特征,但通常存在大量轨迹冗余而限制了识别效果。
随着深度学习尤其是卷积神经网络(Convolutional Neural Network, CNN)在语音和图像识别等领域的成功运用,近年来出现了多种基于深度学习框架的人体行为识别方法,当训练样本足够多时可通过深度网络学习到具有一定语义的特征,更适合于目标和行为的识别。Karpathy等[7]训练深度网络DeepNet,利用慢融合模型对视频中不同图像帧特征进行融合,然而该模型无法提取视频的运动信息,因此效果并不理想。Tran等[8]为了利用视频中的时域特性,将二维卷积推广到三维卷积,使用3D-CNN(3-Dimensional Convolutional Neural Network)深度网络学习空时特征,该网络在避免处理光流的情况下获得了视频的运动特征,但时域信息提取能力有限,对长时段复杂的人体行为识别效果提升并不明显。Varol等[9]在定长时间的视频块内使用三维空时卷积特征,进一步提升了行为识别效果。
Simonyan等[10]首先提出了使用两个数据流(Two-stream)的卷积神经网络进行视频行为识别,空域网络的输入数据流是静态帧图像,时域网络的输入数据流是表征帧间运动的光流,每个数据流都使用深度卷积神经网络进行特征提取和动作预测,最后融合两个数据流的结果进行最终动作的识别。该模型取得了与改进稠密轨迹法相似的识别性能。Ng等[11]将长短期记忆(Long-Short Term Memory, LSTM)网络加入到原始双通道模型中,用来加强时域信息的联系。最初双通道模型中使用的卷积网络层数较浅,Wang等[12]提出采用在图像分类任务中性能更好的预训练深度网络模型如VGGNet、GoogLeNet,增强了对视频运动特征的学习和建模能力。将手工特征和深度学习相结合也是一种研究趋势,Wang等[13]利用双通道神经网络学习卷积特征图,并利用轨迹约束获得深度卷积特征描述子(Trajectory-pooled Deep-convolutional Descriptors, TDD),之后用FV编码得到视频级表示。
2 基于视频分段的空时双通道行为识别
2.1 整体框架
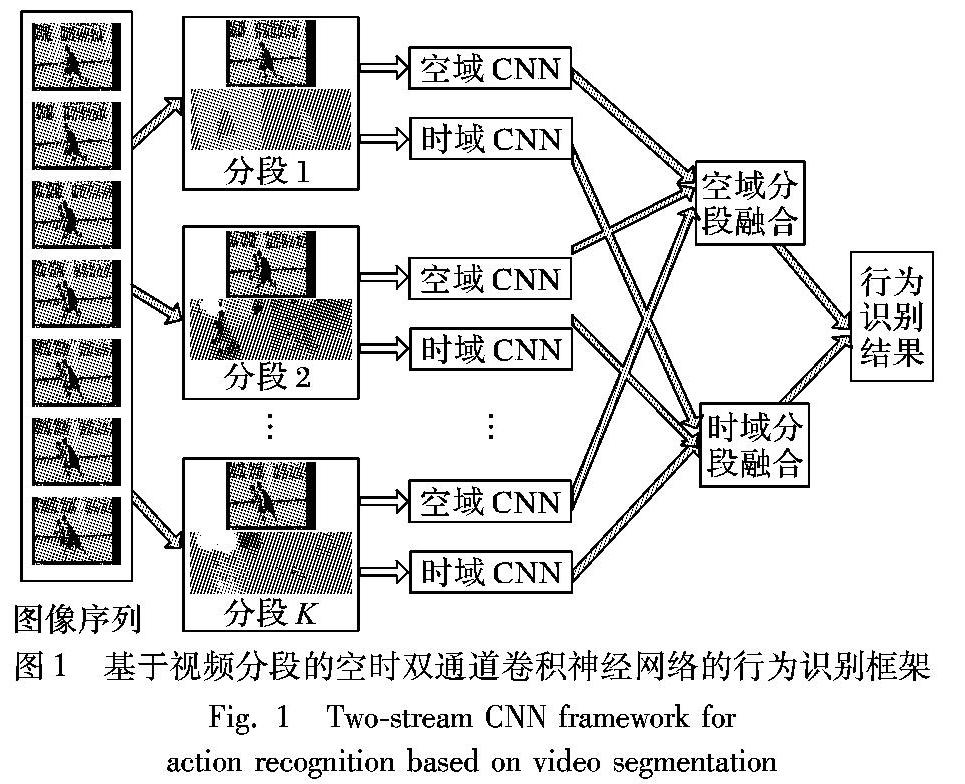
最初的双通道方法从视频中随机采样单帧进行行为识别,对于复杂行为或持续时间较长的视频,视角变换和背景扰动会导致仅利用单帧图像无法有效表达视频的类别信息。为了对长时段复杂视频建立有效的识别模型,本文基于视频分段应用空时双通道神经网络,整体框架如图1所示。先将视频分成多个等长不重叠的分段,对每个分段通过随机采样得到静态帧图像和包含运动信息的堆叠光流图像,分别输入到空域和时域CNN进行特征提取;然后在各自通道内将各个分段的网络输出预测特征进行融合;最后集成融合两个通道的预测特征得到最终的行为识别结果。
其中:Ti表示视频第i个分段的随机采样,空域中是RGB帧图像,时域中是堆叠光流图像;F(Ti;W)表示参数为W的卷积神经网络对Ti的特征提取,其输出为对应类别数目维度的特征向量;分段融合函数g表示对K个分段特征以某种方法进行融合,得到空域或者时域的特征;输出函数H表示对识别结果进行类别分类,一般采用Softmax函数得到每个行为类别的概率值。此外,每个视频分段的空域网络结构完全相同,共享网络权值;时域网络结构亦如此。
2.2 空域网络数据预处理
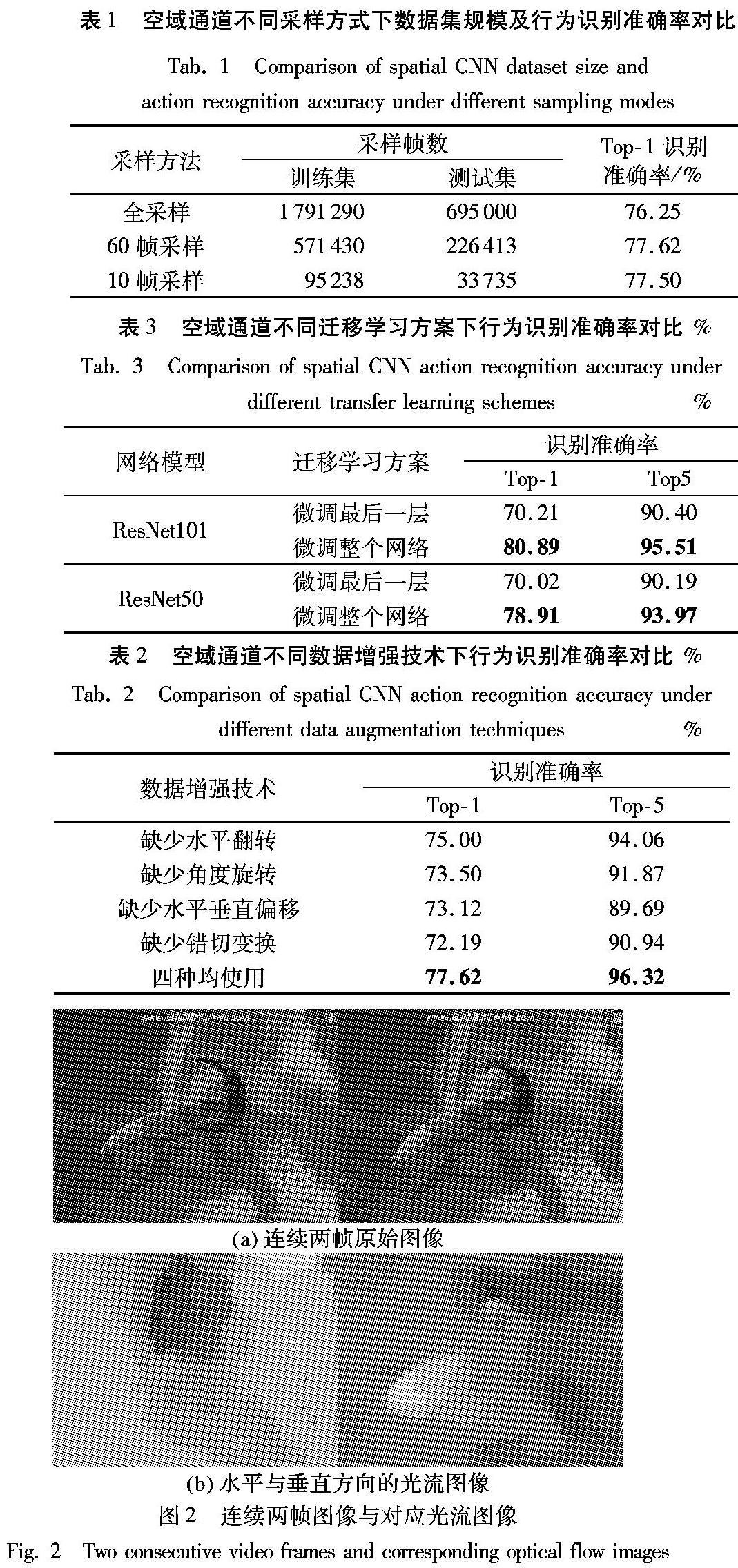
空域网络是对视频中采样得到的静态RGB帧图像进行识别,为了测试不同采样方式对行为识别性能的影响,使用UCF101数据集的Split1训练/测试分割方案,测试Top-1行为识别准确率(即网络输出中最大概率的类别是正确的识别结果)。表1列出了三种采样策略的识别性能,在网络训练过程中,采用了GoogLeNet卷积神经网络的改进版本InceptionV3模型[14]。可以看到,采样帧数增加并未提升识别性能,反而增加了数据冗余,增大了计算复杂度,因此,对视频进行密集采样并不可取,本文实验中对于K个等长的视频分段,每个分段随机采样1帧图像。
为了防止学习建模中的过拟合问题[15],通常会采用数据增强技术,这不仅能扩增输入数据的规模、增加样本的差异性,还能增强网络模型的泛化能力。在空域网络中,本文对视频帧使用水平翻转、角度旋转、平移变换、错切变换等数据增强方法,并在InceptionV3网络模型上测试了这些方法对行为识别性能的影响。表2列出了5种情况下的Top-1和Top-5识别准确率。可以看到,缺少任一种数据增强技术,识别准确率均有下降,这说明了数据增强方法的有效性,因此本文实验中采用全部4种数据增强技术。
2.3 时域网络数据预处理
视频中的运动信息对于行为识别至关重要,光流是一种简单实用的表达图像序列运动信息的方式,被广泛用于提取行为运动特征。Horn等[16]基于两个基本假设推导了图像序列光流的计算公式,本文使用该方法计算水平和垂直两方向的光流。因光流数值接近0且有正有负,为了能够作为时域网络通道的输入,需要对其进行线性变换,最终将两个方向的光流保存为两张灰度图像,如图2所示。为了有效提取视频的运动信息,本文采用10个连续帧的水平和垂直光流堆叠形成20个密集光流图像。
空域和时域中通常会采用预先在ImageNet上训练的CNN,这些网络的输入是RGB图像,因此第一个卷积层的通道数为3,但时域网络输入20个光流图像,与第一个卷积层的通道数不匹配,这里采用跨模态交叉预训练的方法,将第一个卷积层的3个通道的权值取平均,再将其复制20份作为时域网络第一个卷积层20个通道的权值;而时域网络其他层的权值与空域对应层的权值参数相同。
2.4 迁移学习
机器学习方法需要有足够的训练样本才能学习到一个好的分类模型,但实际中针对目标任务的现有样本往往规模较小,而人为标注大量样本不仅费时费力,还会受标注者主观因素的影响。迁移学习方法能够使用预训练模型解决目标任务数据不足的问题,对于新目标任务,使用时需要将预训练网络模型中最后一个用于分类的全连接层替换成新的针对目标任务类别数目的全连接层。本文采用在ImageNet上预训练的残差網络模型ResNet50/101对UCF101数据集进行行为识别,迁移学习时需要将最后一个全连接层设置为对应的101类输出。
实验中对比了两种迁移学习方案:一种是仅对卷积神经网络的最后一个分类层进行权值更新;另一种是微调整个网络更新所有权值。两种方案的识别准确率如表3所示。可以看到,采用微调整个网络的方案可以获得更好的识别性能,Top-1及Top-5准确率均高于仅微调最后一层的方案,因此本文实验中采用微调整个网络的迁移学习方案。
2.5 单通道分段特征融合
基于视频分段的空时双通道模型包含独立的空域和时域卷积神经网络,两个网络在结构上除了第一层的输入通道数不同,其他层参数完全相同。单通道分段融合是指在单个通道中将各个视频分段的网络输出通过某种方式融合,得到该通道的行为识别结果。本文设计了基于最大值、均值和方差三种分段特征融合方案。
迁移学习后网络最后一个全连接层输出的特征向量其维度对应于类别数目,越大特征值对应的类别可能性越大。最大值分段特征融合指取所有分段对应类别输出特征值中的最大值作为该类别的特征输出,这是一种对每个类别取最有可能模式的融合策略。均值分段特征融合指取所有分段对应类别输出特征值的平均值,这种策略平等看待每个分段中的行为信息。基于方差的分段特征融合策略是根据分段输出特征的方差对分段的重要性进行区分,方差较大,对应输出特征离散程度较大,说明有可显著识别的行为类别,这样的特征对视频的行为识别贡献度应该高,因此给该分段赋予较大权重;反之,分段输出特征的方差小,说明输出特征离散程度小,其对行为识别辨识度低,重要性低,融合时权重也较小。
2.6 双通道特征集成
双通道模型中的空域和时域两个CNN彼此独立,在各自通道对分段特征融合后,还需融合空域和时域的识别结果。本文基于集成学习[17]的思想,讨论试凑集成和方差集成两种空时特征集成方案,以实现识别性能的进一步提升。
试凑集成的方法通过设置加权系数θspatial和θtemporal对分段融合后的空域和时域特征进行加权求和得到双通道输出特征,最终以最大特征值对应类别为识别结果。一般来说,时域中的运动信息对行为识别更为重要,因此可设置较大权重。方差集成的方法以融合后的空域和时域特征向量的方差作为加权系数,对两个通道的重要性进行区分。
3 结果分析
3.1 基本参数设置
本文实验在Linux系统下基于PyTorch0.3.0深度学习框架进行。双通道网络的基本参数设置如表4所示,包括初始学习速率、Batch-size大小以及动量。本文采用预训练的网络模型对UCF101数据集进行行为识别,使用较小的学习速率将有利于网络的训练。空域网络的初始学习速率设置为0.0005;时域网络由于其输入数据为光流图像,与RGB图像存在一定差异,设置相对较大的初始学习速率将有利于网络的快速收敛,实验中设置为0.01。优化时学习速率采用自适应方法,根据学习结果自动更新学习速率。从内存容量、使用率以及收敛速度等方面考虑将Batch-size设置为32。为了有效加速网络的收敛,动量的设置遵循传统双通道行为识别方法[10],设置为0.9。空域和时域网络训练时均采用交叉熵损失函数作为优化目标函数,优化方法为随机梯度下降算法。
UCF101数据集中,训练集包含9537个视频,测试集包含3783个视频。每个轮回的训练共需要300次迭代,每次迭代时随机选取32个视频作为训练样本,每个样本采用前述数据增强方法后被裁剪为网络输入的尺寸224×224,并且进行归一化操作。每个轮回的训练完成后对测试集进行测试,以检验学习模型的性能,测试时遵循THUMOS13挑战机制[18]。
3.2 不同分段数目下行为识别性能分析
为了对长时段视频进行有效建模,本文将视频分成K个等长的分段:分段数目较少时,会导致行为信息提取不足、训练模型过于简单;而分段数目较多又会导致数据冗余,增加计算量。表5给出了采用ResNet50/101网络时在不同视频分段数目下的空域通道行为识别性能。可以看到,当视频分成3个分段时,其行为识别性能较好,因此后续实验中将视频分段数目设置为3。
从表6~7中可以看到,相比其他网络结构,ResNet101在空域通道和时域通道均取得了最高的行为识别准确率,Top-1准确率分别达到了82.24%和83.48%。此外也看到ResNet18/50/101等3种残差网络的识别性能随着网络深度的增加而提高,这说明了卷积神经网络的深度对行为识别的重要性。
3.4 不同分段融合方案下行为识别性能分析
实验中将每个视频分为3个等长的分段,空域通道输出的101维特征向量代表输入分段的空域行为识别结果,如前所述,对3个分段的101维特征融合后经过Softmax函数后即可得到整个空域通道的行为识别结果。对时域通道亦如此。表8和表9给出了几种网络结构在不同分段融合方案下的行為识别性能。实验中先对ResNet18残差网络在空时双通道中均采用了基于均值、最大值以及方差的分段融合方案。可以看到,基于均值的方案都取得了较佳的识别性能,而基于最大值的方案总体性能较差,这可能是因为视频分段内容的差异会导致判别误差较大,因此对ResNet50和ResNet101网络结构不再采用基于最大值的分段融合方案。可以看到,随着网络深度的增加,基于均值的融合方案识别性能仍是较好,而且考虑到均值融合方案的计算更简单,因此基于各分段输出特征的平均值更适合作为分段融合方案。
3.5 不同集成策略下行为识别性能分析
试凑集成策略通过设置加权系数θspatial和θtemporal对分段融合后的空域和时域特征进行加权求和,得到最终的双通道输出特征。本文在ResNet101网络结构上采用多种权重比例进行空时双通道的集成,行为识别性能如表10所示。可以看到,当空域与时域的权重比例不断减小时,识别准确率逐步上升,这说明了相对于空域通道提取的静态特征,时域通道提取的运动特征对行为识别有着更重要的作用。当权重比例为1∶3时,识别性能最好,此时单独空域通道的Top-1准确率是82.24%,单独时域通道的Top-1准确率是83.48%,而集成后Top-1准确率达到了91.72%,这说明了集成双通道特征可以有效提升行为识别性能。
是使用分段融合后的空域和时域特征向量的方差作为两通道的加权系数,对空时两个学习器进行集成。表11列出了在ResNet101网络结构上采用基于方差的集成方法的行为识别性能,其中Top-1准确率仅为79.81%,性能出现了下降,这说明采用所有101个类别输出值的离散程度来对空域或时域进行重要性打分的评价标准不合理,其结果会受到非预测类别输出值的干扰。为了减少这种干扰,考虑到通常卷积神经网络输出的较大特征值对分类更具意义,因此采用空时双通道输出的最大5个特征值的方差作为集成时的加权系数,可以看到Top-1识别准确率达到86.93%,比采用101类方差集成的性能有所提升,但与前述基于试凑方式获得的最好性能仍有差距。
3.6 与现有方法对比
表12列出了本文方法与一些基于传统手工设计特征以及基于深度学习的方法在UCF101行为识别数据集上的性能对比。表中前4种基于稠密轨迹使用不同的特征编码方法得到视频级表示,可以看到基于手工特征的方法识别准确率最高达到88.3%。表中后7种方法为基于深度学习的方法,最早应用深度学习的DeepNet网络识别准确率仅有63.3%,三维卷积神经网络3D-CNN的准确率是85.2%,性能都低于最好的手工特征方法。原始双通道模型的识别准确率是88%,加入LSTM循环神经网络后准确率是88.6%,使用深层卷积神经网络的准确率达到90.9%。文献[13]结合深度特征和轨迹特征,识别准确率是90.3%。本文在对长时段视频运动信息建模时采用了基于视频分段的空时双通道模型,取得了91.8%的识别准确率,相比原始的双通道方法,准确率提升了3.8个百分点。这说明基于深度学习的方法随着多种网络模型及学习策略的应用,可以取得比传统方法更好的识别性能。
3.7 HMDB51数据集行为识别性能分析
基于视频分段的空时双通道卷积神经网络的行为识别方法在公开数据集UCF101上取得了不错的性能,为了进一步检验算法的性能,基于ResNet101网络模型在HMDB51数据集上进行了实验。该数据集包含51个行为类别共6766个视频,每个类别至少包含101个视频。HMDB51是目前数据集里最复杂的,识别率最低的。使用该数据集学习分类模型时同样有3种训练/测试分割方案,训练集有3570个样本,测试集有1530个样本,实验仍然在Split1训练/测试方案上进行。视频分段采用基于均值的融合方式,空域和时域通道的Top-1行为识别准确率分别为49.41%和45.22%。当双通道采用试凑方式集成,空时权重比例系数为1∶2时,双通道融合后Top-1准确率达到61.39%,比最初的空时双通道网络模型的行为识别准确率58%也有提高。HMDB51数据集上识别准确率较低主要是因为与UCF101数据集相比,HMDB51存在大量类间差别较小的行为,比如面部吃和喝的运动、说话和微笑等等,此外视频的规模和质量也对模型的学习及表达存在一定限制。
4 结语
本文实现了一种基于视频分段的空时双通道卷积神经网络的人体行为识别方法,主要基于残差网络模型在UCF101数据集上进行了识别分类的训练和测试。为了解决因数据集样本不足造成的过拟合问题,实验讨论分析了多种数据增强方法对空域网络识别准确率的影响;同时因为在采用ImageNet上预训练网络模型对目标数据集分类识别时需要调整网络,从而讨论分析了两种迁移学习方案,实验显示全局微调网络比仅微调最后一层可获得较大性能的提升。对基于分段的空时双通道模型,通过实验讨论分析了不同视频分段数目、预训练网络结构、分段特征融合方法、空时特征集成策略等环节对识别性能的影响,证明了融合双通道内各个视频分段的卷积神经网络输出特征的方法能够捕获视频中的行为运动特征,提高了行为识别准确率。
參考文献 (References)
[1] 单言虎,张彰,黄凯奇.人的视觉行为识别研究回顾、现状及展望[J].计算机研究与发展,2016,53(1):93-112.(SHAN Y H, ZHANG Z, HUANG K Q. Review, current situation and prospect of human visual behavior recognition [J]. Journal of Computer Research and Development, 2016, 53 (1): 93-112.)
[2] FORSYTH D A. Computer Vision: A Modern Approach[M]. 2nd ed. Englewood Cliffs, NJ: Prentice Hall, 2011: 1-2.
[3] CAI Z, WANG L, PENG X, et al. Multi-view super vector for action recognition[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 596-603.
[4] WANG H, SCHMID C. Action recognition with improved trajectories[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2014: 3551-3558.
[5] PENG X, WANG L, WANG X, et al. Bag of visual words and fusion methods for action recognition: comprehensive study and good practice [J]. Computer Vision and Image Understanding, 2016, 150: 109-125.
[6] WANG L, QIAO Y, TANG X. MoFAP: a multi-level representation for action recognition[J]. International Journal of Computer Vision, 2016, 119 (3): 254-271.
[7] KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Rec-ognition. Washington, DC: IEEE Computer Society, 2014: 1725-1732.
[8] TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]// Proceedings of the 2014 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 4489-4497.
[9] VAROL G, LAPTEV I, SCHMID C. Long-term temporal convolutions for action recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510-1517.
[10] SIMONYAN K, ZISSERMAN A. Two-stream convolutional net-works for action recognition in videos[C]// Proceedings of the 2014 Conference on Neural Information Processing Systems. New York: Curran Associates, 2014: 568-576.
[11] NG Y H, HAUSKNECHT M, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video classification[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 4694-4702.
[12] WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition [C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 22-36.
[13] WANG L, QIAO Y, TANG X. Action recognition with trajectory-pooled deep-convolutional descriptors[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 4305-4314.
[14] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 2818-2826.
[15] MURPHY K P. Machine Learning: A Probabilistic Perspective [M]. Cambridge: MIT Press, 2012: 22.
[16] HORN B K P, SCHUNCK B G. Determining optical flow [J]. Artificial Intelligence, 1981, 17 (1/2/3): 185-203.
[17] 周志華.机器学习[M].北京:清华大学出版社,2016:171-173.(ZHOU Z H. Machine Learning [M]. Beijing: Tsinghua University Press, 2016: 171-173.)
[18] JIANG Y G, LIU J, ZAMIR A, et.al. Competition track evaluation setup, the first international workshop on action recognition with a large number of classes [EB/OL]. [2018-05-20]. http://www.crcv.ucf.edu/ICCV13-Action-Workshop/index.files/Competition_Track_Evaluation.pdf.
