基于长短期记忆的车辆行为动态识别网络
2019-09-04卫星乐越韩江洪陆阳
卫星 乐越 韩江洪 陆阳

摘 要:高级辅助驾驶装置采用机器视觉技术实时处理摄录的行车前方车辆视频,动态识别并预估其姿态和行为。针对该类识别算法精度低、延迟大的问题,提出一种基于长短期记忆(LSTM)的车辆行为动态识别深度学习算法。首先,提取车辆行为视频中的关键帧;其次,引入双卷积网络并行对关键帧的特征信息进行分析,再利用LSTM网络对提取出的特性信息进行序列建模;最后,通过输出的预测得分判断出车辆行为类别。实验结果表明,所提算法识别准确率可达95.6%,对于单个视频的识别时间只要1.72s;基于自建数据集,改进的双卷积算法相比普通卷积网络在准确率上提高8.02%,与传统车辆行为识别算法相比准确率提高6.36%。
其中改进的双卷积网络算法相比普通卷积网络在准确率上提高8.02%,基于本文摘要中不能出现“本文”字样,请调整语句描述。英文摘要处作相应修改。请参照现在的改过的PDF文档英文摘要进行修改,而不是原修改稿数据集,与传统车辆行为识别算法相比准确率提高6.36%。
同基于本文数据集的传统车辆行为识别算法相比准确率提高6.36%
关键词:车辆行为;长短期记忆网络;高级辅助驾驶;深度学习;卷积神经网络
Abstract:In the advanced assisted driving device, machine vision technology was used to process the video of vehicles in front in real time to dynamically recognize and predict the posture and behavior of vehicle. Concerning low precision and large delay of this kind of recognition algorithm, a deep learning algorithm for vehicle behavior dynamic recognition based on Long Short-Term Memory (LSTM) was proposed. Firstly, the key frames in vehicle behavior video were extracted. Secondly, a dual convolutional network was introduced to analyze the feature information of key frames in parallel, and then LSTM network was used to sequence the extracted characteristic information. Finally, the output predicted score was used to determine the behavior type of vehicle. The experimental results show that the proposed algorithm has an accuracy of 95.6%, and the recognition time of a single video is only 1.72s. The improved dual convolutional network algorithm improves the accuracy by 8.02% compared with ordinary convolutional network and increases by 6.36% compared with traditional vehicle behavior recognition algorithm based on a self-built dataset.
Key words: vehicle behavior; Long Short-Term Memory (LSTM) network; advanced assisted driving; deep learning; Convolutional Neural Network (CNN)
0 引言
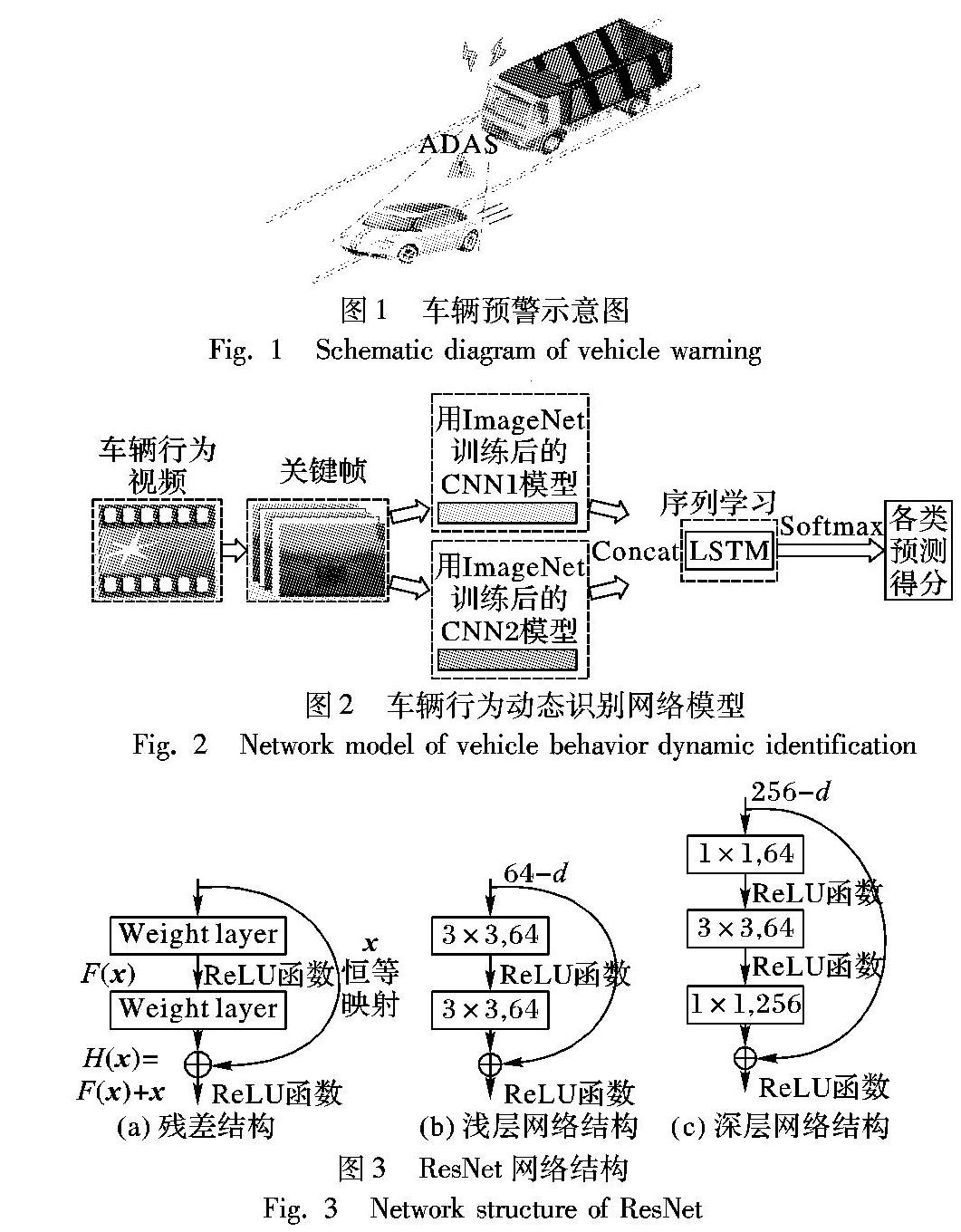
隨着智能汽车行业的蓬勃发展,无人驾驶技术的运用在各个领域中所占的比重也越来越大。其中,高级辅助驾驶系统(Advanced Driving Assistant System, ADAS)是以与未来科技互连的无人驾驶技术为基础,通过应用感知技术探测车辆周围行驶环境,依据获得的车辆行为信息执行相应操作从而保障驾驶员的人身安全[1]。对前方行驶车辆的行为姿态分析是ADAS技术的重要手段之一,功能的主要实现是通过安装在车辆内的前置摄像头对前方车辆进行拍摄,对其直行、左转、右转、变道、掉头等动态姿态行为进行识别,从而对驾驶员进行预警和提示(如图1)。
目前,在车辆行为识别领域,已经有许多基于传统机器视觉算法的研究。如:2012年,Kasper等[2]使用贝叶斯网络对高速公路场景中车辆典型行为进行分类;2014年Gadepally等[3]等使用隐马尔可夫模型(Hidden Markov Model, HMM)对车辆行为进行分析;2018年,黄鑫等[4]使用视觉背景提取(Visual Background extractor, ViBe)算法得到车辆的前景图像,利用金字塔光流法(Lucas-Kanada, L-K)和均值漂移算法,再通过运动特征熵和运动特征标量到聚类中心的欧氏距离这两种方法判断车辆有无异常行为;黄慧玲等[5]提出一种基于车辆行为识别的汽车前方碰撞预警方法,通过梯度方向直方图(Histograms of Oriented Gradients, HOG)和支持向量机(Support Vector Machine, SVM)来训练检索前方车辆,再结合卡尔曼滤波对车辆跟踪,最后使用HMM算法对车辆行为进行建模,识别前方车辆行为。但是,很多传统算法的视频都是在路口高位定点拍摄,更加适合对背景相对固定的车辆行为进行识别,并且传统算法的检测和识别精度无法达到实际需求。近些年,深度学习已经在各个领域取得重大进展,解决了许多传统技术无法解决的难题。在视频识别和分类这一任务上,Donahue等[6]在2015年提出了采用长短期记忆(Long Short-Term Memory, LSTM)网络来解决视频流时序分类这一难题。LSTM由Hochreiter等[7]在1997年提出,是一种时间递归神经网络。由于存在梯度消失和梯度爆炸等问题,标准的循环网络在长序列上的学习效果不佳。相比之下,LSTM使用记忆单元来访问、修改、存储内部状态,能够更好地探寻长序列之间的联系,因此在自然语言、语音、动作姿态等序列领域有惊人的表现[8-9]。Graves[10]于2013年对LSTM进行了改良和推广,使其能更好地学习序列特征。2017年,曹晋其等[11]采用卷积神经网络(Convolutional Neural Network, CNN)和LSTM相结合的方式对人体行为进行识别,利用图像中的RGB数据识别视频人体动作,使用现有的CNN模型从图像中提取特征,并采用长短记忆递归神经网络进行训练分类;同时,采用双卷积和关键帧选取的方法,可以大幅度提高人体行为分类的正确率[12-14]。目前,尚未有利用LSTM网络解决类似于车辆行为动态识别方面的研究。
综上所述,针对传统车辆行为识别算法准确率较低和实用性差等问题,为了有效检测前方车辆并对其运动状态进行理解和识别,本文提出了一种基于长短期记忆的车辆行为动态识别网络,该模型对于车辆行为的动态识别非常有效,且模型收敛的速度很快。
1 网络结构
本文网络模型如图2所示,主要训练过程如下:
第一步 对输入的解帧后的视频流进行关键帧提取,并依据关键帧数量和关键帧所在子视频中的位置因素等进行对比实验。
第二步 使用双CNN模型提取出关键帧中的车辆特征,其中双CNN模型参数是由ImageNet数据集[15]训练得到。根据分类结果与车辆和环境特征的多元性及特殊性,提出的双网络结构将分别专注于常规特征以及细微特征变化。双CNN模型的选择对最终的动态行为分类结果起着至关重要的作用,本文会在稍后的实验中进行讨论。
第三步 将双CNN模型提取出的车辆行为特征融合后输入到LSTM网络框架中,进而分析序列间特征得到各类车辆行为预判得分,最终得到视频车辆的行为分类。
2 视频帧提取
3 双卷积特征提取
3.1 ResNet基本原理
根据万能近似定理(Universal Approximation Theorem,UAT),当单层的前馈网络有足够大的容量的时候,它可以表示任何函数;但是,由于单层网络在结构上过于庞大,容易造成过拟合等现象。在卷积神经网络中,随着层数的增多,可以提取不同level的特征,从而使得整个网络表达的特征更加丰富,并且,越深的神经网络提取出的特征会越抽象,更加具有语义信息,但是,神经网络深度的提升不能单单通过层与层的简单堆叠来实现,并且由于存在梯度消失等问题,深层神经网络往往难以训练,因此需要构建结构合理的多层网络来更好地提取图像的信息特征。
深度残差网络(deep Residual Network, ResNet)在2015年被提出[16],在ImageNet分类任务上获得比赛第一名,因为它独有的特性,可以允许网络尽可能地深。ResNet中引入了残差网络结构(图3(a)所示),相比其他卷积网络增加了網络层数和深度,不仅能有效避免梯度弥散或梯度爆炸,同时也能很好地解决网络的退化问题。其核心思想是引入一个恒等快捷连接,将原始所需要学习的函数H(x)转换成F(x)+x(如式(2)),这两种表达的效果相同,但是优化的难度却并不相同,假设F(x)的优化会比H(x)简单得多。为了方便计算,达到更好优化训练的效果,可以把式(1)转换为学习一个残差函数,如式(3)所示:
当F(x)=0,构成了一个恒等映射H(x)=x,同时可以更方便拟合残差。用σ表示非线性函数ReLU(Rectified Linear Unit请补充ReLU的英文全称),W1,W2,Wa,Wb表示权重,F(x)和H(x)分别表示为:
当输入输出两者维度不同,需要给x执行一个线性映射来匹配维度:
ResNet使用两种残差单元,如图3(b)、(c)所示,图3(b)对应的是浅层网络,而图3(c)对应的是深层网络。对于短路连接这种方式,当输入和输出的维度相同时,可以直接将输入加到输出上。当维度不一致时(通常是维度会增加一倍)就不能直接相加。第一种方法是使用补零法来增加维度,进行下采样,使用步长为2的池化层,这种方式不会增加额外的参数。第二种方法是采用新的映射,通过1×1的卷积来增加维度,较为方便稳定。本文使用的是第二种方法。
3.2 双提取机制
本文对于视频的特征提取,设计双深度卷积网络来对视频帧中的车辆特征进行学习和提取。图2中的CNN1和CNN2分别使用ResNet-50和改进的ResNet-34网络模型,网络结构如表1所示。为了保持精度同时减少相应的计算量,本文的CNN1网络(ResNet-50)采用图2(c)所示的残差结构,结构中的中间3×3的卷积层首先在一个降维1×1卷积层下减少了计算,然后在另一个1×1的卷积层下做了还原。由于在车辆行为检测过程中,视频帧中的转向灯、红绿灯等特征(车辆变道转向等行为)不明显,因此,考虑对ResNet-34网络模型进行相应改进来作为本实验的CNN2网络模型。实验中,针对图像中相对较小的特征,本文采用扩大卷积核的方式来增大感受野从而获取更多的细节特征,具体做法是将ResNet-34前5层卷积核大小由原始的7×7与3×3的组合改为7×7,6到15层卷积核将原来的3×3改为5×5。
请补充这个的名称,是统计项吗?也请补充名称,没有数值或空白,也需说明一下,否则无法理解。表格的规范是按照列名来补充相关数据项
这是何意?需明确。
回复:可以看清每列,但是排版需要把线去掉。建议把这一行删除,因为这个表描述网络参数,核心内容已经表达。
此外,在两个CNN训练完成后,用1×1×512的卷积网络来代替CNN1和CNN2中的全连接层及之后softmax层,用卷积提取的方式使两个卷积网络输出为1×1×512维度特征;然后再使用首尾相接的融合方法对CNN1和CNN2的输出进行融合,作为LSTM神经网络的输入。
4 基于LSTM序列
车辆行为视频的连续关键帧是随着时间进行演变的过程,针对这一特性本文选择LSTM网络框架对车辆行为进行建模。LSTM相比循环神经网络(Recurrent Neural Network, RNN),其算法中加入了一个判断信息筛选的“处理器”记忆单元,如图4所示。每个单元中设置了三扇门,分别为输入门It、输出门QtOt是Q,还是O,公式中是O,请明确。和遗忘门Ft,它们分别对应着车辆运动姿态数据序列的写入、读取和先前状态的重置操作。假设xt表示在时间t下的输入,Wi,Wf,Wo,Wc表示权重矩阵;bi,bf,bo,bc是偏置向量,σ表示为logistic sigmoid函数,Ht为单元t时刻的输出。Ct表示记忆单元在t时刻的状态,则LSTM单元在t时刻的更新过程如下:
为了抓取车辆动态行为的语义信息,提高结果的分类准确率,决定采用一种双层深度LSTM表示模型,可以挖掘更深层的序列之间的特征。网络模型如图5所示,把本文第3章介绍的双卷积网络所提取出m个特征值按序输入双层结构的LSTM序列模型中,每个记忆单元学习当时输入的车辆特征,并通过单元的遗忘门以及其前后状态对车辆行为状态进行分析。采用many to one(即多对一)的输入输出方式,每个输入都是1×1×1024的向量,在經过双层的LSTM网络后,输出为1×1×6(6对应着直行、左转、右转、左变道、右变道、掉头)的分类向量并将其通过softmax函数,最后得出车辆行为类别的预测得分。
5 实验及结果分析
5.1 数据集
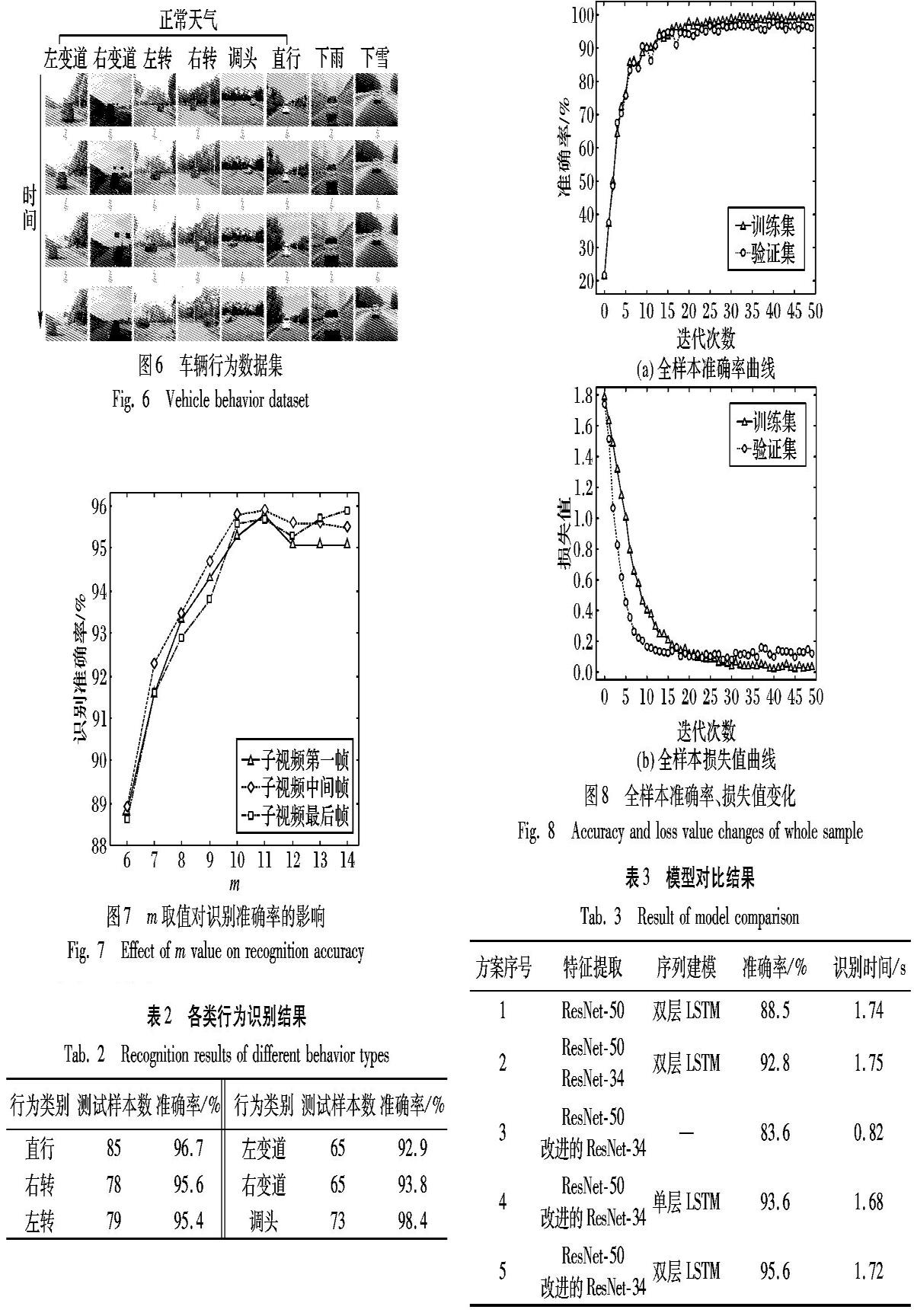
本文用于特征提取的双卷积网络使用ImageNet数据集进行训练,ImageNet数据集有1400多万幅图片,涵盖2万多个类别。本文把数据集中的卡车、轿车标签统一换成了车辆标签。本文使用合作项目中的大量视频数据以及自行搭建的车载实验平台所采集的视频数据来训练LSTM网络模型。车辆视频数据归分为6个类,分别为直行、左变道、右变道、调头、左转、右转,每个类中有300多个视频,视频集中包含白天、傍晚、阴天、雨天等多种不同天气环境及不同路况下拍摄的数据。视频拍摄过程中将摄像头固定于车辆前玻璃正前方,对车辆正前方目标车辆的行驶行为进行拍摄,数据采集真实可靠。在本文实验中,车辆数据如图6所示,将数据集中的2218个视频随机分为训练集、验证集和测试集,其中训练集视频数量为1330,验证集视频数量为443,测试集视频数量为445。
5.2 网络环境配置及训练
实验使用的服务器基于Ubuntu 16.04,64位操作系统,使用的深度学习框架是tensorflow,GPU为GeForce GTX 1080Ti。首先用ImageNet数据集对双卷积网络进行训练,然后在用训练好的双卷积网络对关键帧进行特征提取以便于训练LSTM神经网络。每个关键帧都降采样到224×224大小,LSTM网络隐含层的维度为1024。在训练LSTM神经网络中,本文使用Adam优化器中的随机梯度下降算法来学习参数,学习率设置为10-5,训练的批处理大小Batch为12,权重衰减(decay)为0.0001,数据集迭代次数为50。
5.3 结果分析
5.3.1 m取值不同关键帧的实验结果
由图7可知,在车右转这一类车辆行为中,在提取数据帧方式相同的情况下,m值由6到10之间,识别正确率迅速上升并达到峰值,之后开始趋于稳定,当m取值大于12时,准确率开始略微下降;针对3种不同的子序列取帧方式,识别的正确率随着m值变化的总体趋势相同,差距较小。综合而言,选取子视频的中间帧,识别效果最优,整体识别最好。
5.3.2 行为识别结果
本实验将拆分出来的训练集用于训练模型,验证集用于评估模型,预测车辆行为识别结果的好坏,并验证模型选择的合理性及模型参数的最优性。最后采用已经训练好的网络模型及权重参数,预测测试集中的视频数据最后采用已经训练好的网络模型来预测测试集中的视频数据,得出测试车辆不同行为的准确率,不同车辆行为类别在数据测试集上的准确率如表2所示。
由表2可知,在各种天气环境及不同路况,当车辆行为是直行、左转、右转以及调头的准确率较高,可以达到95%以上;而左变道、右变道准确率略低,仅有93%左右。
实验将数据集按比例随机抽取,进行多次交叉验证,行为识别准确率结果如图8(a),损失函数趋势曲线如图8(b)。
由图8(a)可见,在整个训练过程中,训练集和验证集准确率一直处于上升的趋势,数据经过10次迭代后,验证集与训练集准确率相差较大,经过20次迭代后基本趋于稳定。由此说明,前期10次迭代过程存在一定的过拟合,但在后期的迭代中进行了一定的修正,从而致使识别率逐步提高。由图8(b)可知,损失值在迭代到10次之前,验证集的损失值下降幅度比训练集大,之后训练集损失值继续缓慢下降,验证集损失值趋于稳定。
方案序号特征提取序列建模准确率/%识别时间此处原为识别速度,单位是s,是否应该为识别时间,这样更恰当些,请明确。正文中的其他处是否也可以这样修改
从表3中可以看出,检测车辆行为的准确率在各种模型方案下显示不同。通过对比方案1和方案2,可以看出多一个卷积网络进行特征提取,准确率提高了4.3个百分点,但是对于单个视频行为识别速度相近。再对ResNet-34网络进行2.2节中所述的改进后,准确率又在原来基础上提高了2.8个百分点。实验过程中发现,对ResNet-34网络进行改进后,直行、左变道、右变道的识别准确率上升更为明显,说明采用双卷积网络泛化能力强,性能更高,能提取更为细微的特征。方案3、方案4和方案5,都保持了特征提取部分网络不变,但是方案3不使用LSTM网络的,这种情况下准确率明显降低很多,但是识别速度提高了一倍单个视频的识别时间减少了一半若改为识别时间,此处应为识别时间减少了一半,请确认。方案4使用了单层的LSTM网络来做序列间的特征学习,准确率比方案5使用双层深度LSTM网络的低2个百分点,但是网络权重也小了20%左右。
为了证明本文网络模型在车辆行为识别上的优势,基于本文视频流数据集,与现有的一些车辆行为识别的算法进行对比实验。
从表4中可以看出,针对视频中车辆特征检测这一角度,本文提出的车辆特征检测方法可以有效地解决传统方法的某些问题,比传统的方法更加满足实际中的需求,且双卷积网络结构检测性能更强,更能发现细小的特征。
本文算法双卷积网络不同条件很强
由表5所示,在直行、右转、左转、掉头这几个车辆行为识别中,相比传统车辆行为识别算法,本文提出的识别网络在各个类别中准确率均是最高,且平均准确率相比次好的文献[4]中的模型提高了6.36%,获得了更好的分类效果。
6 结语
针对视频中前方的车辆行为研究这一问题,提出了基于长短期记忆的车辆行为动态识别网络算法。在车辆行为识别网络设计中,采用双卷积网络模型对视频中车辆特征进行检测和提取。针对车辆运动状态这一时序问题,使用LSTM网络进行序列特征深度挖掘,最终得到行为分类结果。通过对比传统机器视觉的车辆行为分析研究,本文提出的算法不需要基于先验知识建立车辆姿态模型,同时可以自适应地学习姿态特征,并且不受外界因素影响,对于车辆后方拍摄视角准确率更能满足实际需求,但是,本文的研究不能实时有效地识别前方多台车辆的行为,所以下一步的研究重点主要是在保证准确率的情况下同时识别前方多辆车的动态行为。
参考文献 (References)
[1] 陈放.高级驾驶辅助系统ADAS浅谈[J].各界,2018(1):188-191.(CHEN F. A dissertation on advanced driver assistance system[J].All Circles, 2018(1): 188-191.)
[2] KASPER D, WEIDL G, DANG T, et al. Object-oriented Bayesian networks for detection of lane change maneuvers[J]. IEEE Intelligent Transportation Systems Magazine, 2012, 4(3): 19-31.
[3] GADEPALLY V, KRISHNAMURTHY A, OZGUNER U. A framework for estimating driver decisions near intersections [J]. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(2): 637-646.
[4] 黄鑫,肖世德,宋波.监控视频中的车辆异常行为检测[J].计算机系统应用,2018,27(2):125-131.(HUANG X, XIAO S D, SONG B. Detection of vehicles abnormal behaviors in surveillance video[J]. Computer Systems and Applications, 2018, 27(2): 125-131.)
[5] 黄慧玲,杨明,王春香,等.基于前方车辆行为识别的碰撞预警系统[J].华中科技大学学报(自然科学版),2015,43(s1):117-121.(HUANG H L, YANG M, WANG C X, et al. Collision warning system based on forward vehicle behavior recognition[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2015, 43(s1): 117-121.)
[6] DONAHUE J, HENDRICKS L A, ROHRBACH M, et al. Long-term recurrent convolutional networks for visual recognition and description[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 2625-2634.
[7] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[8] 殷昊,李寿山,贡正仙,等.基于多通道LSTM的不平衡情绪分类方法[J].中文信息学报,2018,32(1):139-145.(YIN H, LI S S, GONG Z X, et al. Imbalanced emotion classification based on multi-channel LSTM[J]. Journal of Chinese Information Processing, 2018,32(1):139-145.)
[9] 郑毅,李凤,张丽,等.基于长短时记忆网络的人体姿态检测方法[J].计算机应用,2018,38(6):1568-1574.(ZHENG Y, LI F, ZHANG L, et al. Pose detection and classification with LSTM network[J]. Journal of Computer Applications, 2018, 38(6): 1568-1574.)
[10] GRAVES A. Supervised Sequence Labelling with Recurrent Neural Networks[M]. Berlin: Springer, 2012:385.
[11] 曹晋其,蒋兴浩,孙錟锋.基于训练图CNN特征的视频人体动作识别算法[J].计算机工程,2017,43(11):234-238.(CAO J Q, JIANG X H, SUN T F. Video human action recognition algorithm based on trained image CNN features[J]. Computer Engineering, 2017, 43(11): 234-238.)
[12] SIMONYAN K, ZISSERMAN A. Two-stream convolutional net-works for action recognition in videos[C]// Proceedings of the 2014 International Conference on Neural Information Processing Systems. Montréal: [s.n.], 2014: 568-576.
[13] NG J.Y, MATTHEW H, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video classification[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 4694-4702.
[14] CHEN H F, CHEN J, HU R M, et al. Action recognition with temporal scale-invariant deep learning framework[J]. China Communications, 2017, 14(2): 163-172.
[15] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 248-255.
[16] HE K M, ZHANG X Y, REN S Q, et. al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 770-778.
