基于ICEEMDAN-ELM的管道声信号识别方法研究
2019-08-27别锋锋都腾飞庞明军
别锋锋,都腾飞,庞明军,谷 晟
(江苏省绿色过程装备重点实验室,江苏 常州 213164)
管道阻塞是一种常见故障状态,近年来,声波检测法被广泛应用于对管道阻塞的判别。但由于传感器采集的声信号具有非线性、非平稳的特征,同时处理多通道信号往往存在分解尺度不同的问题[1-2]。如何从非线性,非平稳的信号中提取故障特征是状态识别的关键。对于声信号中有用信息的提取,国内外学者进行了大量的研究分析,提出了很多方法。主要有短时傅里叶变换、小波分析、经验模态分解、局部均值分解[3-5]等。1998年Huang[6-7]等提出的经验模态分解(EMD,Empirical Mode Decomposition),克服了小波分析小波基的选择问题,可以根据信号的特征自适应选择基底来对信号进行多分辨率分析,但该方法不足之处在于分解的固有模态函数(IMF,Intrinsic Mode Function)会产生模态混叠的情况。为降低模态混叠的影响,Wu等[8]又在EMD基础上提出了集合经验模态分解(EEMD,Ensemble Empirical Mode Decomposition),该方法利用加入辅助白噪声来降低模态混叠影响。YEH等[9]又对EEMD做了改进,提出了互补集合经验分解法(CEEMD,Complete Ensemble Empirical Mode Decomposition),采用正、负成对的形式加入辅助噪声,通过正、负抵消重构信号中的辅助噪声,降低模态混叠影响,并且可以减少加入的噪声集合次数,提高计算效率。完全集合经验模态分解(CEEMDAN,Complete EEMD with Adaptive Noise)算法[10]克服了EEMD算法存在的不足,该方法将自适应的白噪声添加到EEMD算法分解的每一阶段,各个模态函数分量通过计算唯一的余量信号获取,使其分解过程既具有完整性,又能抑制噪声成分。本文采用进一步优化的分解方法[11]ICEEMDAN(Improved Complete EEMD with Adaptive Noise)。该方法极大地抑制了初始分解过程引起的虚假分量和模态混叠问题,具有更好的分解结果。
神经网络作为一种人工智能的方法,目前已广泛应用于故障诊断领域。通过自组织和自适应的学习,神经网络可以达到良好的分类效果。但是神经网络算法容易造成过拟合的问题,实际训练过程中需要大量的训练样本。极限学习机(ELM)由于其结构简单,方便使用,近年来已有很大的应用,除了解决了神经网络易产生过拟合的问题外,ELM只需要设置隐藏层节点的数量、输入权重和隐藏元素的偏差,便可获得全局最优解[12]。因此,它在模式识别领域得到了广泛应用和发展。
本文将ICEEMDAN、声压级和ELM算法相结合来分析和识别堵塞管道的声信号脉冲响应信号。首先,通过ICEEMDAN信号预处理得到若干个IMF分量。其次,综合相关系数和方差贡献率作为相关判据,筛选出表征管道阻塞信息的IMF分量,计算IMF分量的声压级构造特征向量,然后输入ELM进行分类与识别。
本文第一部分将介绍ICEEMDAN算法、ELM算法以及IMF的选取原则。第二部分将介绍基于ICEEMDAN声压级的特征提取方法和基于ELM的模式识别方法。第三部分是实验分析,第四部分是结论。
1 信号特征提取与识别理论
1.1 ICEEMDAN算法
EEMD算法在每次分解的开始阶段,都存在一个局部均值和一个IMF分量,而真正模态分量是混合原信号和噪声信号的平均模态分量,其中包含着一些残余的噪声。另一方面,在CEEMDAN算法分解过程中使用上一个模态分量分解后的残差来计算下一个模态,每一阶模态计算都是连续的。而Colominas提出的ICEEMDAN算法在此基础上进行了改进。
CEEMDAN方法在分解过程中加入的是高斯白噪声,而ICEEMDAN方法加入的是一种特殊的白噪声Ek(w(i)),即高斯白噪声经过EMD分解过后的第k个IMF分量,对每个模态分量计算信号加噪声的局部均值,并将分解得到的IMF定义为残差信号与局部均值的差值。ICEEMDAN分解方法大大减少了IMF分量中的残余噪声,改进了传统方法在分解重构的早期阶段容易产生虚假分量和模态混叠的不足。
定义操作符Ek(·)表示EMD分解后的第k个模态分量,M(·)表示信号的局部均值。那么E1(x)=x-M(x)。操作符表示取均值,具体的分解过程如下:
第一步:构造x(i)=x+α0E1(w(i)),其中,w(i)表示被添加的第i个白噪声,α0表示噪声标准差。计算x(i)的局部均值M(x(i)),取均值得到第一个残差分量
第二步:计算第一模态分量IMF1值
第三步:计算第二模态分量IMF2值r2,式中
1.2 ELM算法
使用极限学习机ELM对管道声信号进行模式识别。极限学习机ELM是在单隐层前馈网络SLFN的基础上发展起来的,而单隐层前馈网络SLFN是具有一层隐含层的特殊BP神经网络[13]。ELM的体系结构如图1所示。
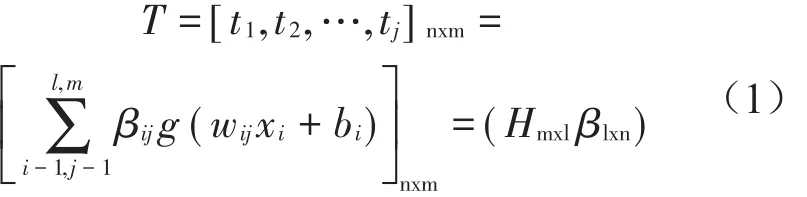
式中:wij和bi是输入层和隐含层的权重和阈值,g(x)是隐含层神经元的激活函数,文中选用sigmoid函数。βij是隐含层和输出层间的权值,H表示隐含层的输出矩阵。对输入层向量首先进行一个线性化的计算得到wijxi+bi,然后通过激活函数g(x)计算出隐含层的输出矩阵H,H=g(wijxi+bj),再将H乘以隐含层和输出层间的权值βij得到输出向量T。极限学习机在计算过程中具有以下几个优点:

图1 极限学习机(ELM)结构图
(1)隐含层和输入层间的权值wij和阈值bi是随机产生的,并在计算过程中保持不变。
(2)隐含层和输出层间的连接权值βij不是通过迭代计算的方式而是通过解方程组的方式一次计算完成的,因此模型的泛化能力较强,求解速度很快。
其中,误差函数可由下式得出
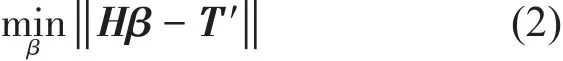
上式的解为β^=H+T′。T′是T的转置矩阵,H+是隐含层输出矩阵的Moore-Penrose广义逆。
具体的ELM计算步骤如下:
第一步为随机产生隐含层和输入层的连接权值wij和阈值bi;
第二步为选一个无限可微的激活函数g(x),本文用的是sigmoid函数;
第三步为计算隐含层的输出矩阵H,H=g(wijxi+bj);
第四步为求解隐含层和输出层的连接权值β^。
1.3 IMF的选取原则
信号处理的过程中,相关性[14]是一个非常重要的概念。通过将分解后的固有模态函数与原信号做相关性分析,寻找出与原信号相关程度大的部分,从而将信号的虚假分量剔除,提高对处理后的时频分析信号特征提取的准确率。相关系数的具体计算方式如下:
首先计算原信号和各个IMF分量的自相关函数,计算公式如下
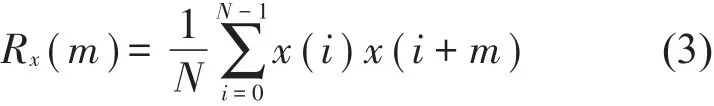
将自相关函数进行归一化,求各个IMF分量的自相关函数RIMF1(m)、RIMF2(m)…RIMFn(m)与原信号的自相关函数Rx(m)的相关系数,相关系数的定义为
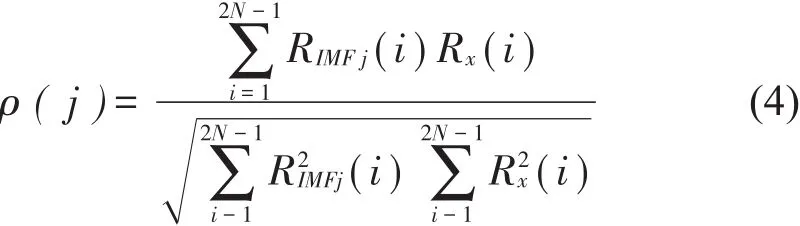
式中:N为信号采样点数;j代表第j个IMF分量。
因子分析法的统计意义表明,方差贡献率可以确定因子的相对重要性[15],高的因子方差贡献率说明该因子与原信号间的相互影响越大。通过计算各个IMF分量和原信号的方差贡献率,筛选出影响因子较大的分量。对于采样时间t内采集的声信号(含有k个数据点),定义各个IMF分量fi与原始信号的方差贡献率计算公式如下
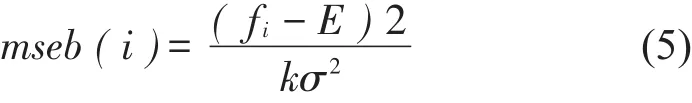
相关系数和方差贡献率都是表示两组信号相关性的指标,一般来说当指标数值大于0.3时就认为有较强的相关性,IMF分量真实有效,可以予以保留。通过计算相关系数和方差贡献率,综合考虑选取包含原始信号特征的IMF分量。
2 基于ICEEMDAN的声信号管道阻塞特征处理与模式识别
2.1 声压级
声压表示声波通过某种介质时,由于振动而产生压强的改变量。定义声压p为声波在媒介中存在于某点的压强pf与介质在平衡状静压pref的差值

由于某点的实际声压p为瞬时声压,而有效声压的计算公式为[13]

上式中的T表示信号的周期。有效声压Pe单位为帕斯卡(Pa),仪器仪表测得的声压和我们通常所指的声压都是有效声压。声压级是通过仪表仪器来反映人耳对声音强弱的主观判断,符号为SPL,其定义为

其中:Pe表示有效声压,Pref表示参考声压,声压级的单位是分贝(dB)。
2.2 基于ICEEMDAN声压级的管道声信号特征提取与模式识别
本文提出了一种基于ICEEMDAN分解和声压级(SPL)相结合的信号处理方法。针对管道声信号的特征处理识别方法流程如下:
(1)对多通道采集的声脉冲响应信号进行ICEEMDAN分解,得到多组不同分解尺度的IMF分量;
(2)计算各IMF分量和原信号的相关系数xg和方差贡献率mseb,筛选出含有管道特征信息的主要IMF分量;
(3)计算各IMF分量的声压级(S1,S2,S3…)并作为管道声信号检测的特征值;
(4)构造特征向量T=[S1,S2,S3…] ;
(5)将一部分特征向量用于训练ELM分类器,然后将剩余的测试数据输入到ELM以识别阻塞状态。整个流程如图2所示。
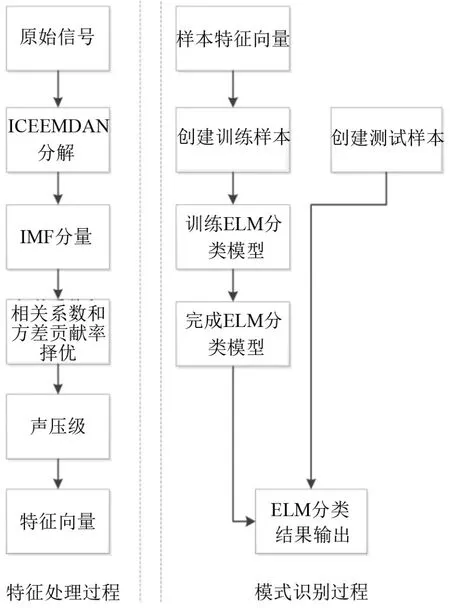
图2 声信号的特征提取与模式识别图
3 实验与结果分析
3.1 实验装置
实验装置包括4个拾音器、扬声器、MARC8声卡、功率放大器和Win MLS测试软件。如图3所示,4个拾音器集成在一个电路板上和扬声器连接在一起。拾音器的灵敏度为1 V/Pa、1 kHz。扬声器发出声信号后被拾音器接收,转换为电信号。
该实验装置如图4所示,声卡控制扬声器输出大小。MARC8声卡能够在50 Hz~18000 Hz的频率范围内发射声能,通过扬声器系统测试软件WinMLS产生最大长度为14阶的伪随机序列,拾音器有4个通道接收返回信号。两者通过采集卡和放大器与计算机相连。实验时通过一个螺栓将传感器固定在管道内。
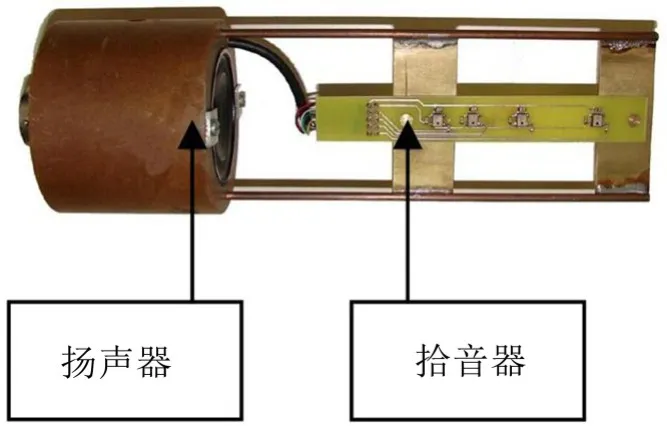
图3 管道声信号传感器装置图

图4 管道声信号实验装置图
实验采样频率为44100 Hz。管道的材质为黏土,长度为15 m,障碍物设置在距离扬声器5 m的地方,如图5所示。
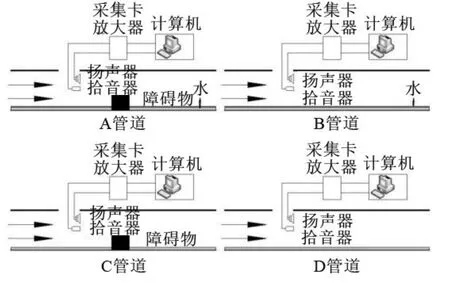
图5 实验管道工况设置示意图
为模拟实际运行中的管道状态,一共设置4种不同的工况。A、B管道模拟管内有流体运行情况,A管道在距离扬声器5 m的地方设置了障碍物模拟管道阻塞的情形,管道内通水。将B管道和A管道作对比,通水但不设置障碍物。C、D管道模拟管道内无流体空载时的情形,C管道在距离扬声器5 m的地方设置障碍物模拟管道阻塞,D管道只为空管。当管道中存在流体和堵塞情况时,拾音器接受到的返回信号会有变化,通过区分比较采集的返回信号可以分析和辨别管道的状态。
3.2 实验结果
实验中通过设置A、B、C、D 4类不同状态的管道,采集相关的原始信号的时域波形如图6所示。
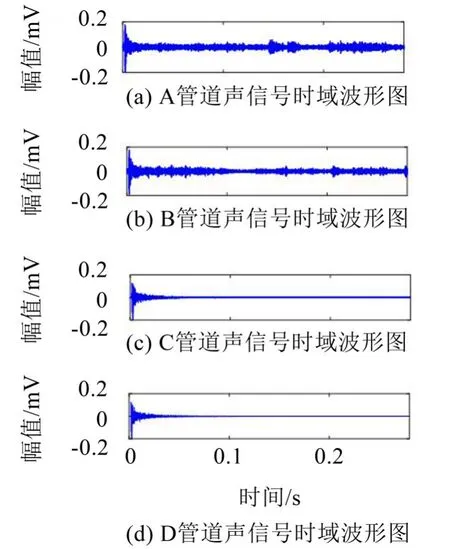
图64 类信号时域波形图
A、C管道内有障碍物模拟管道阻塞情况,A、B管中有水,C、D管中无水。从图6可以看出,4类工况下的脉冲波形表征极为相似,仅从时域图上很难做出区分。
基于以上情况,开展对所采集的实验声信号特征提取就显得十分必要,本文提取管道声信号声压级(SPL)进行分析。首先对多通道采集的声信号进行ICEEMDAN分解,分解得到11个IMF分量和一个残差余量,图7展示了A管道声信号通过ICEEMDAN分解得到的IMF分量(前8阶)。
若对IMF直接进行分析,很难得出原信号相关的有效特征。通过综合比较相关系数和方差贡献率这两个参数可以筛选出IMF中的有效分量。将各个IMF分量的相关系数和方差贡献率绘制成图8。
图8反映了各种情况下IMF分量与原信号的相关系数和方差贡献率的关系,保留数值大于0.3的IMF分量。相关系数分析保留分量IMF4~IMF7。方差贡献率分量分析中保留分量IMF5~IMF7,综合考虑选取IMF4~IMF7分量,其余的IMF分量予以剔除。表1展示了4种工况下IMF分量的声压级分布。
本文使用极限学习机ELM进行故障分类的识别。实验所采样的ABCD 4种工况下的声脉冲信号每类分为12组数据,共48组数据。在4类数据中每组分别随机选取8组共32组数据作为训练样本,其余16组作为测试样本。先对随机选取的训练样本数据进行ICEEMDAN分解,根据相干系数和方差贡献率,筛选出分量IMF4~IMF7,计算各个分类的声压级SPL,图9给出了48组数据的IMF分量的声压级特征值分布,将4个IMF分量特征值构成特征向量T=[S1,S2,S3…] ,归一化后将特征向量T输入ELM进行训练,对12组测试样本同样计算出特征向量进行验证。
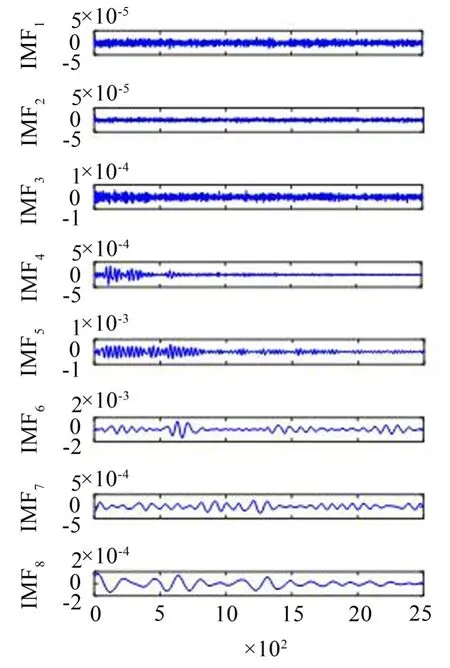
图7 管道声信号的ICEEMDAN分解
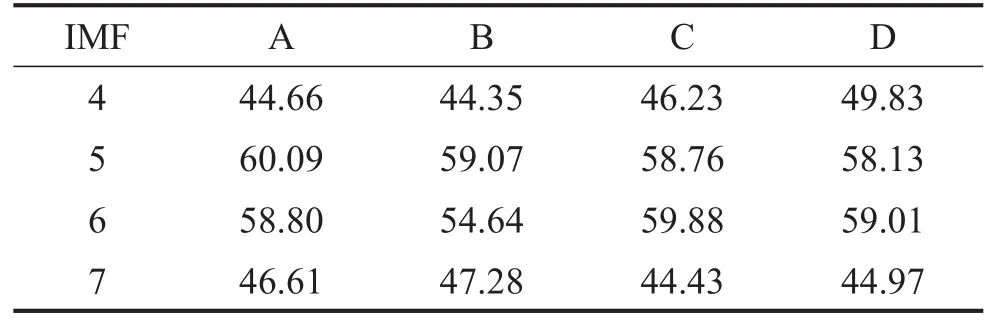
表14 类管道声信号在IMF4~IMF7分量的声压级/dB
训练时,A类管道的信号设置为1,B类管道的信号设置为2,C类管道的信号设置为3,D类管道的信号设置为4。图10展示了根据单次随机样本抽取的测试集识别准确率,识别率为100%。
为了进一步分析ELM的性能,文中随机采样了10次样本数据,同时使用BP神经网络和SVM进行对比试验。表2给出了10次预测的准确率和计算时间。
如图11所示,极限学习机ELM具有较高的预测准确率,SVM次之,BP神经网络的预测准确率最差。
图12给出了3种方法的预测计算时间,在计算机性能相同时,BP神经网络由于要反复迭代需要较长的计算时间。
SVM由于应用核函数,计算时间次之,而ELM由于连接权值w和隐含层阈值b在训练时是随机选择的,并且在训练过程中可以保持不变,这种方法可以大大减少参数的计算量,因此在3种方法中具有较快的计算速度,再一次证明了ELM在识别准确率和计算时间上的优越性能。

图8 各阶IMF相关系数和方差贡献率变化趋势
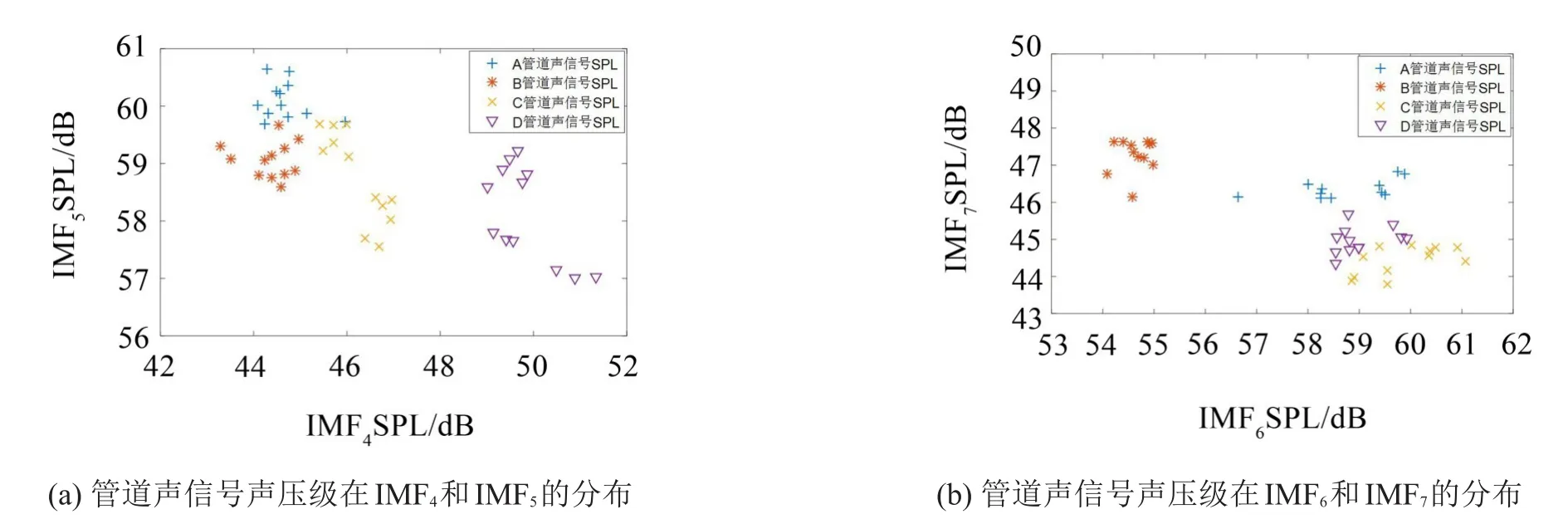
图9 4类管道声信号声压级分布
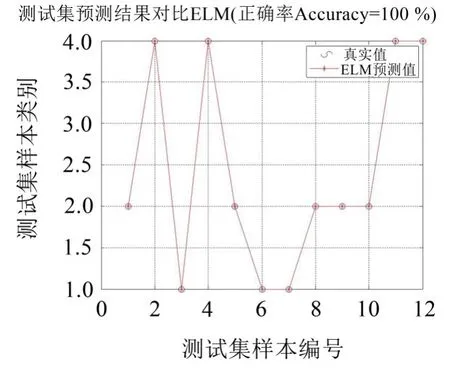
图10 极限学习机ELM识别图
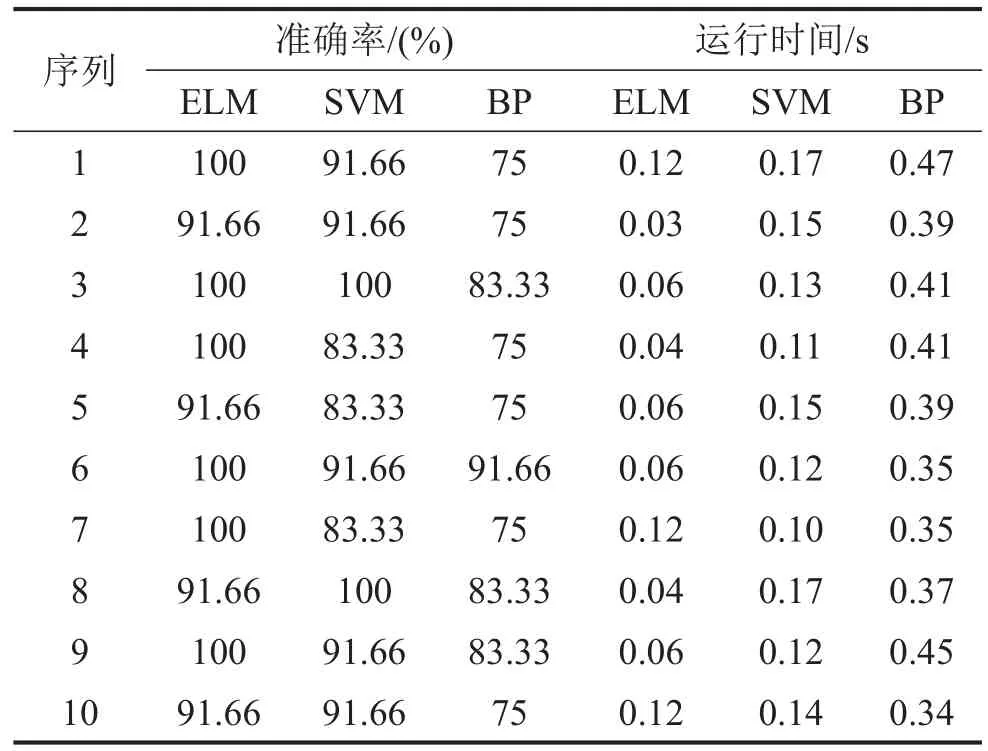
表2 基于ELM、SVM、BP的分类结果
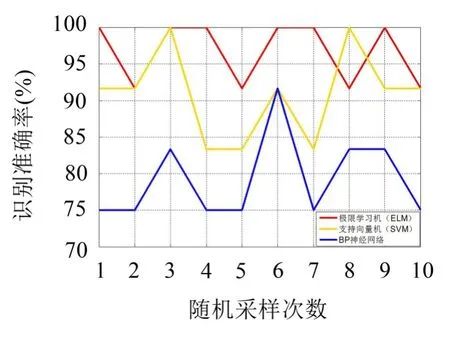
图11 基于ELM、SVM、BP分类准确率识别
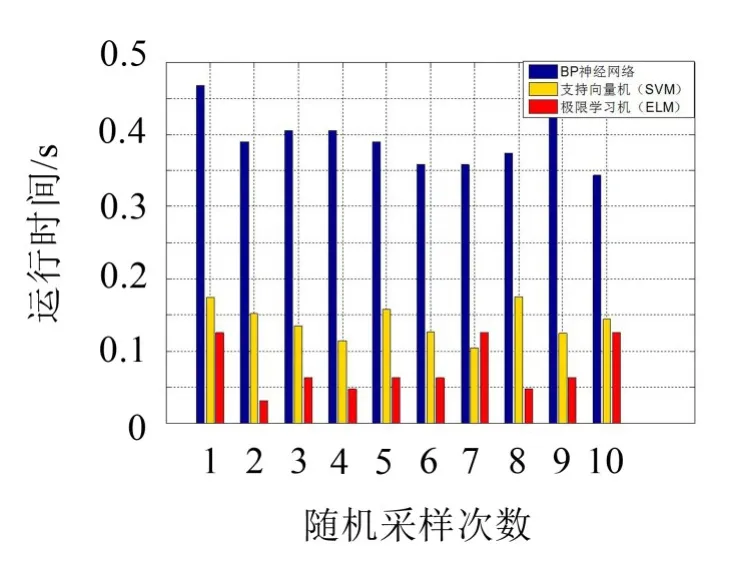
图12 基于ELM、SVM、BP分类计算时间
4 结语
对不同状态的管道声脉冲信号进行特征提取与模式识别,具体结论如下:
(1)基于ICEEMDAN分解的方法由于是基于信号的自适应分解,适用于非平稳和非线性的管道声信号的处理。
(2)理论和实验分析证明,本文所提出的基于相干系数和方差贡献率来判断IMF分量和原信号相关性,并以声压级作为声信号处理的特征值,从而提取出特征向量的方法切实可行。
(3)给出了一种ELM分类器来对管道阻塞状态进行模式识别的方法,并通过与BP神经网络和SVM对比分析,证明了ELM在识别准确性和耗时方面的良好效果,突出了ELM在模式识别中的优势。
