SADBN及其在滚动轴承故障分类识别中的应用
2019-08-19程军圣
杨 宇, 罗 鹏, 甘 磊, 程军圣
(湖南大学 汽车车身先进设计制造国家重点实验室, 长沙 410082)
传统的智能诊断方法过于依赖提取的特征值以及专家诊断经验知识,在面对如何实现大型化、高速化、复杂化装备系统准确、快速、便捷的在线监测与实时故障诊断这类问题时,传统的智能诊断方法就显得有点力不从心[1-2]。因此,迫切需要研究新的方法来满足工程实际的需求。
Hinton等[3]在《Science》上提出深度学习理论,由此开启了机器学习在学术界和工业界的浪潮。深度学习的宗旨在于构建深层次的网络结构模型,学习数据中隐含的特征,获取数据丰富的内在信息。相较于传统的智能诊断方法,深度学习方法有以下三大优势[4-6]:① 能够针对不同的诊断对象以及故障类型自适应地提取数据中的特征参数;② 具有深层学习能力,能够较好地建立起信号与设备之间复杂的非线性映射关系;③ 能够不用单独去选择和设计专门的分类器,建立的深度学习模型能够根据前期自适应提取的特征参数对设备状况进行模式识别,给出相应的识别结果或者维修建议。
深度信念网络(Deep Belief Network,DBN)作为一种深度学习网络的典型代表[7],通过组合低层特征形成更加抽象的高层表示,以发现数据分布式特征表示,是一种可以直接从低层原始信号出发,逐层贪婪学习得到高层特定特征的学习网络。DBN以受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)为基本结构单元,通过多个RBM堆叠而成。RBM网络结构具有如下性质[8]:当给定可见层神经元的状态时,各隐层神经元的激活条件独立;反之当给定隐层神经元的状态时,可见层神经元的激活也条件独立。这种网络中的神经元是随机神经元,其输出只有两种状态(未激活和激活),状态的取值根据概率法则决定。RBM由两层对称连接且无自反馈的随机神经网络构成,其层间全连接,层内无连接,具有强大的无监督学习能力,能够学习数据中复杂的规则。
DBN无需人工特征提取过程,从而避免了传统特征提取过程所带来的复杂性和不确定性,增强了识别过程的智能性,典型的双隐层DBN诊断流程,如图1所示。
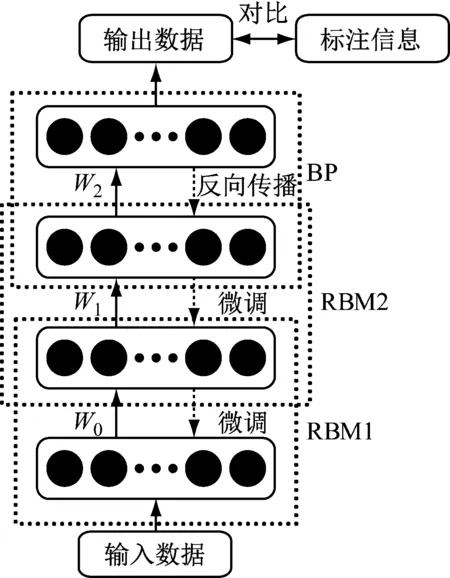
图1 双隐层DBN诊断流程
正是因为DBN的诸多优点,其在故障诊断领域也得以应用。Tamilselva等[9]利用DBN理论对飞机发动机结构健康状况进行识别;李巍华等[10]利用DBN可以从低层逐步学习到高层抽样的特点,直接从原始数据出发,对轴承故障进行了识别,由于无需进行特征提取,因而减少了人为参与因素,增强了故障诊断的智能性。但是DBN仍处于发展初期,在实际应用中基本上都是依靠经验来确定其网络结构。这样不仅可能对诊断结果带入人为影响误差,也不利于网络结构的自身优化,造成计算成本较高,诊断速度较慢,无法满足实时诊断的实际需求。
基于此,本文针对深度学习网络结构及模型参数的选择往往依赖经验这一缺陷,提出了一种新的深度信念网络——结构自适应深度信念网络(Structure Adaptive Deep Belief Network,SADBN),当诊断对象确定后,该网络可以排除人为因素的干扰,充分利用网络优势,自适应地选取最优深度网络结构,从而可以有效提高诊断精度及诊断效率,满足实时诊断的需求。
1 结构自适应深度信念网络(SADBN)
针对不同的诊断对象,DBN将面临网络结构选择的困难,包括网络深度、各层节点数如何选定等等。与此同时,深度学习网络的相关参数,例如:迭代次数的确定等等,同样也是较为棘手的问题。为解决上述问题,本文提出了结构自适应深度信念网络法。
1.1 结构自适应深度信念网络法
DBN的网络结构单元为RBM,需要确定DBN最优网络结构,其实就是确定构建DBN的RBM结构最优及DBN网络深度最优。因此,结构自适应深度信念网络法的首要工作就是在研究清楚RBM运行机理的基础上,寻找能够有效反映RBM性能的指标,从而对构建的RBM性能优劣进行有效判定,以此获取最优RBM结构,然后逐层增加构建DBN的RBM个数或者增加DBN的网络层数,综合评定来获取最优DBN网络结构。
RBM可以视为一个无向图模型,如图2所示,其中v代表可见层,表示观测数据,h为隐层,可以当作特征提取器,W为两层之间的链接权重。RBM中的可见层和隐层单元可以为任意的指数族单元,即可见单元和隐单元可以为任意的指数族分布,如softmax单元、高斯单元和泊松单元等等。为方便讨论,我们经常假设所有的可见单元和隐单元均为二值变量,即对任意的i和j都有vi∈{0,1},hj∈{0,1}。

图2 RBM结构
如果一个RBM有n个可见单元和m个隐单元,用向量v和h分别表示可见单元和隐单元的状态。其中vi表示第i个可见单元的状态,hj表示第j个隐单元的状态。对于一组给定的状态(v,h),RBM作为一个系统所具备的能量定义为:
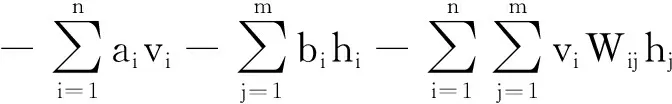
(1)
式中:θ={Wij,ai,bj}是RBM的实参数,Wij表示可见单元与隐单元之间的连接权重,ai表示可见单元i的偏置,bj表示隐单元j的偏置。基于上述能量函数,我们可以得到(v,h) 的联合概率分布:
(2)
式中:Z(θ)为归一化因子,也称为配分函数。
对于工程实际应用,我们最关心的是由RBM所定义的关于观测数据v的分布P(v|θ),也就是联合概率分布P(v,h|θ)的边际分布,也称为似然函数,其数学表现形式为:
(3)
在此,我们可以找到评判一个RBM是否优劣的性能指标,即在训练数据上的似然度L(θ),其表达式如下:
(4)
为了获取似然度L(θ),首先就得确定关于观测数据v的分布P(v|θ),从而就得计算归一化因子Z(θ)。通过RBM的结构可知,获取Z(θ)需要计算2n+m次,其中n代表样本长度,Z(θ)将会因计算次数过大而难以获取。所以,理论上我们可以通过似然度L(θ)来判定RBM的性能优劣,但是由于工程实际的限定,导致该方法很难实现。
由表达式(2)可知,因为Z(θ)难以获取,则联合概率分布P(v,h|θ)也难以获取。为解决这一问题,研究者一般通过一些采样方法(如Gibbs采样)获取P(v,h|θ)的近似值,其过程中将会涉及到可见层的重构问题。在此,我们可得到评判一个RBM是否优劣的第二个性能指标,即重构误差。但是重构误差在收敛速度以及逼近精度方面存在缺陷,而熵误差与重构误差相比较而言能够加快网络收敛速度和逼近的精度,能够使得网络的泛化能力得到加强。在此,我们引入了熵误差函数,其表达式如下:
(5)
式中:D=(d1,d2,…,dl)T为网络期望的输出,O=(o1,o2,…,ol)T为网络输出,l为样本个数。
结构自适应深度信念网络法的核心思想就是在深度学习过程中,得到每个网络结构单元RBM的熵误差函数越小越好,即得到的实际输出O最大可能接近目标输出D,如此来获得最优深度网络结构。
结构自适应深度信念网络法的规则如下:
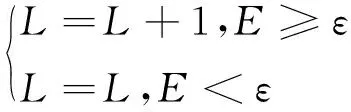
(6)
式中:ε为熵误差函数逼近精度预设值(一般取95%以上),L为隐含层数。在使用熵误差函数对网络层数进行选择时,其规则如下:当熵误差下降至所设定的阈值时,保留原有的网络结构,否则网络层数增加一层。
熵误差具体计算过程如下:
E=0;//初始化熵误差
For allv(t),t∈{1,2,…,T} do;//对每个训练样本v(t)进行以下计算。
h~P(·|v(t)),v~P(·|h);//对隐层采样,对可见层采样。
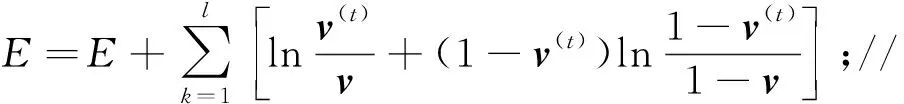
End for,ReturnE;//停止迭代,返回总误差。
1.2 结构自适应深度信念网络设计步骤
基于结构自适应深度信念网络法,我们可得到SADBN的设计步骤如下:
步骤1 构建一个深度为2及隐层节点数为0的初始化DBN模型,设置深度增加步长为1,节点数增加步长为5,并将训练样本数据带入网络中进行训练,计算获取深度单层熵误差。
步骤2 对获取的熵误差进行分析:
(1) 若熵误差值随着迭代次数的增加能够较快下降且平稳趋于设定阈值,保留此网络结构;
(2) 若熵误差到迭代终止时仍未达到设定阈值,保持网络深度不变,增加隐层节点数,而后若熵误差值随着迭代次数的增加能够较快下降且平稳趋于设定阈值,保留此网络结构,反之则增加网络深度;
(3) 若熵误差值随着迭代次数的增加呈现不平稳现象,保持网络深度不变,增加隐层节点数,而后若熵误差值随着迭代次数的增加能够较快下降且平稳趋于设定阈值,保留此网络结构,反之则增加网络深度;
步骤3 挑选出符合以上要求的网络结构,将测试数据带入网络得出相关的识别率,同时引入计算时间作为参考,综合择优获得最优诊断模型。
SADBN基本设计流程如图3所示。
结构自适应深度信念网络法:① 解决了深度网络结构选择依靠经验的问题;② 能够自适应给出深度网络结构优选范围,方便、快捷地实现深度诊断网络的构建。
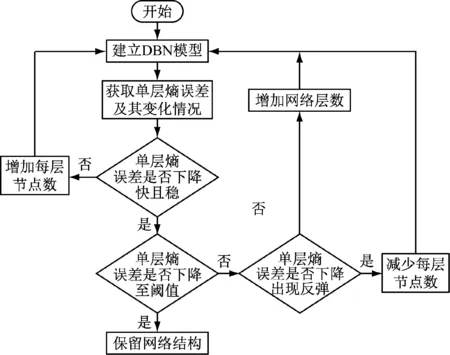
图3 SADBN基本设计流程
2 基于SADBN的滚动轴承故障诊断方法
为了验证SADBN的有效性,采用美国西储大学轴承测试中心的实验数据,使用电机驱动端测点数据,在轴承的内圈、外圈和滚动体上人为设置尺寸为0.18 mm的故障,基准转速为1 796 r/min,采样频率为12 kHz,采样时间为10 s。训练和测试数据集的具体情况,如表1所示。
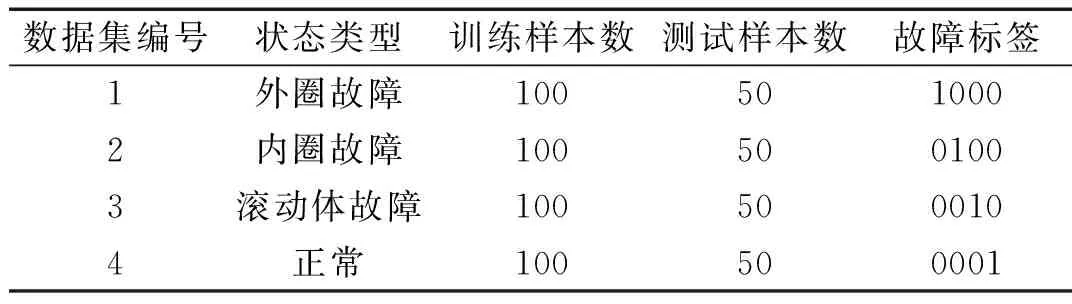
表1 数据集
四种状态的样本采样时间为1 s时的时域振动信号,如图4所示。
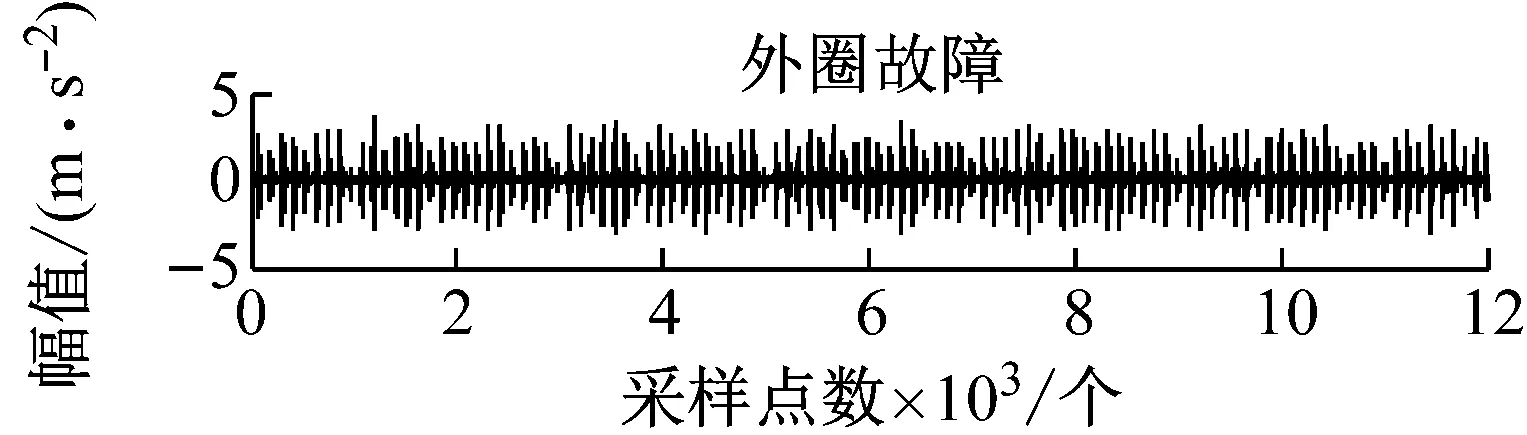
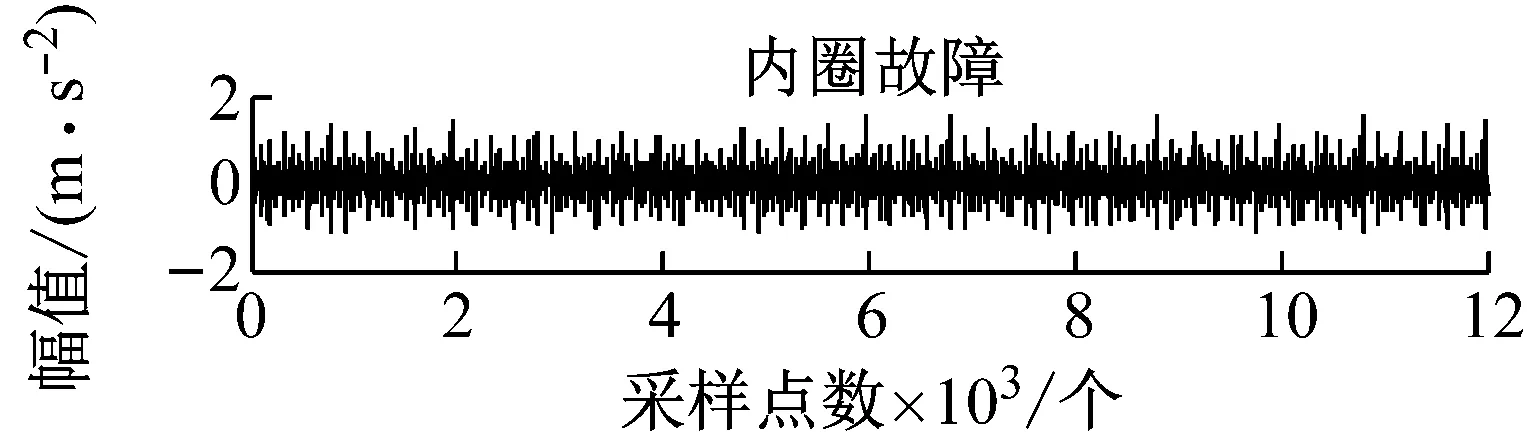
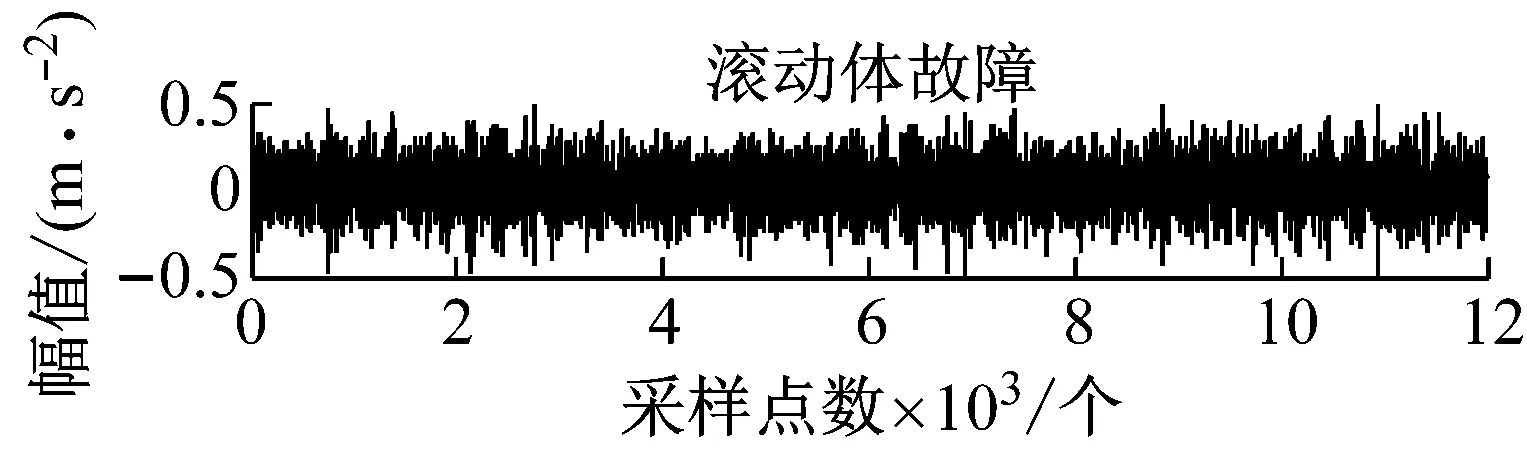
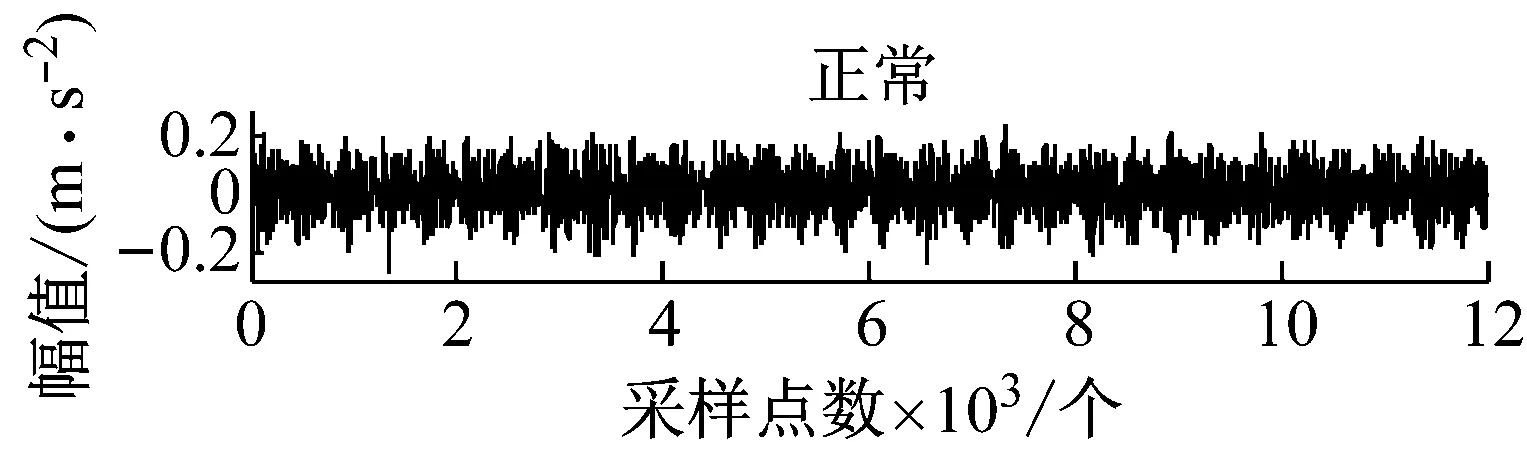
图4 滚动轴承不同工作状态下的实验振动信号
传统的滚动轴承故障诊断需要对原始实验信号进行一系列的预处理,比如降噪、信号分解等等,然后提取能够反映故障信息的时域、频域或者时频域单个或者多个特征值,将其输入设计好的分类器进行状态识别。而本文提出的方法相对于传统方法则更加的简捷、高效,有较强的工程应用性。以下为运用本文方法现实滚动轴承故障分类识别的过程:
步骤1 随机构造一个深度信念网络,隐层数分别为2~6层,每层的节点数分别为5~300,计算各层的熵误差,结果如表2和3所示。

表2 不同节点数、不同深度的轴承深度信念网络训练熵误差

表3 不同节点数、不同深度的轴承深度信念网络训练熵误差
步骤2 通过表2与表3我们可以发现当节点数取30以下以及150以上时,网络熵误差出现较大幅度的波动,这将可能给诊断系统精度带来不利影响,同时也不符合结构自适应深度信念网络法的要求。而当各隐层节点数取30~150时,各层熵误差较小且随着网络深度的增加变化较为平稳。因此,我们初步选取各隐层节点数优选范围为30~150。
步骤3 我们可获得不同优选隐层节点数下的熵误差随迭代次数的变化趋势图,限于文章篇幅,我们将网络深度为2、隐层节点数取30~150时熵误差随迭代次数的变化趋势图画出,结果如图5所示。
步骤4 基于深度学习网络的特点以及结构自适应深度信念网络法的要求,熵误差随着迭代次数的增加应该在尽可能少的迭代次数下达到较小的误差值,同时保持稳定性。基于上图所示结果,当迭代次数为50次时,不同网络深度下各优选隐层节点数对应的熵误差值,如表4所示。
根据表4结果我们可以发现当网络深度取2和3,隐层节点数取40~100时的网络结构能够较好的满足步骤4中所提出的要求。因此,我们可以得到进一步缩小范围后的优选网络结构。
步骤5我们得到各优选网络结构对应的诊断时间如表5所示,其中字母B代表程序运行时间。基于计算成本择优,毋庸置疑,最终的优选网络结构为40-40。
我们将网络结构为40-40时的熵误差随迭代次数变化趋势进行进一步分析可发现,如图6所示,当迭代次数取200的时候,熵误差值基本保持平稳。基于计算成本择优法,我们可知当网络结构确定下来后,影响计算成本的因素还剩下样本容量M,迭代次数K。前面针对实验数据我们就已经确定了样本容量M,即训练集和测试集样本数,在此,我们进一步确定了迭代次数K为200。自此,针对轴承四类工作状态的结构自适应深度信念网络及相关参数就确定下来了。
将样本信号导入构建的结构自适应深度信念网络模型后可以得到各层网络的学习数据,可以看出经过40-40结构的深度学习网络后,样本特征数据变得更加鲜明了,结果如图7、图8和图9所示。
为与传统的智能诊断方法比较,本文选取特征提取结合支持向量机(Support Vector Machine, SVM)的方法进行滚动轴承故障的分类识别。选取C-SVC支持向量机模型,同时选用RBF核函数,惩罚参数为2,核函数参数为0.02。首先通过对400个数据样本提取6个常用的旋转机械故障特征,分别为:均方值、峰值指标、波形指标、脉冲指标、裕度指标、小波熵,然后将提取的多样本特征值构成特征矩阵导入建立的模型中学习训练,而后对200个诊断对象进行模式识别。诊断结果显示200个诊断对象中正确识别192个,诊断精度为96%。
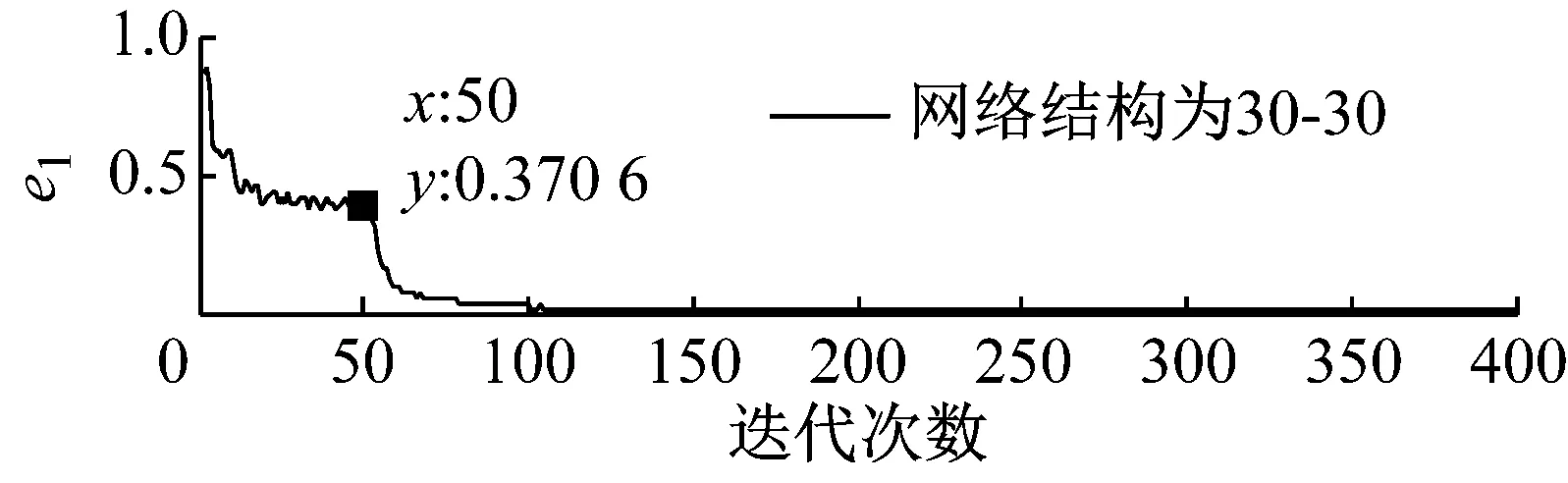
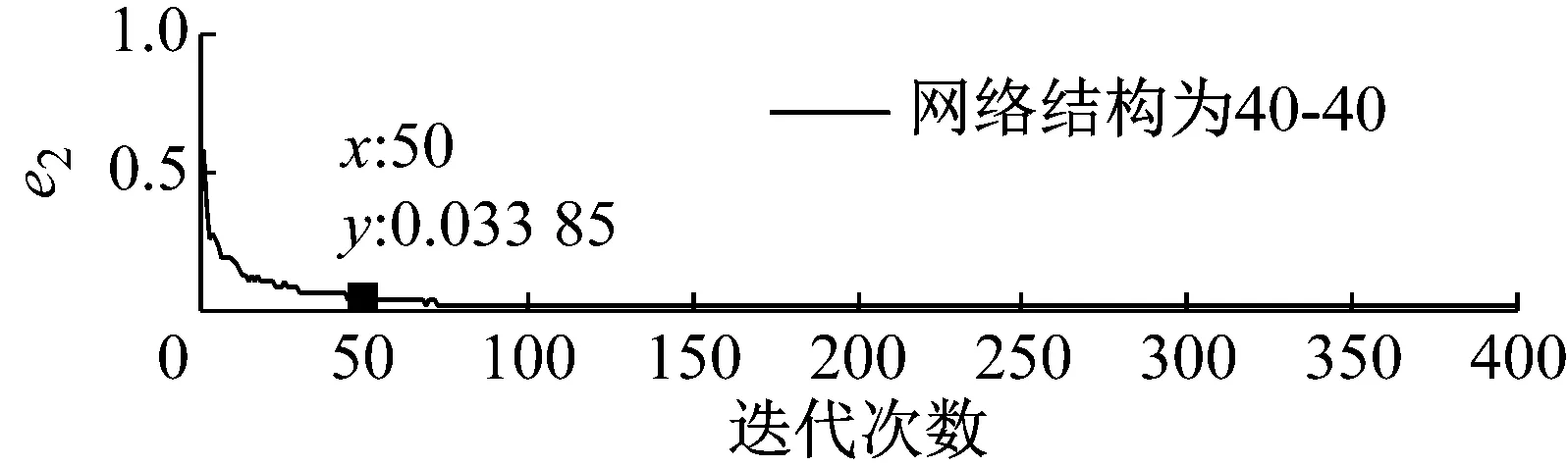
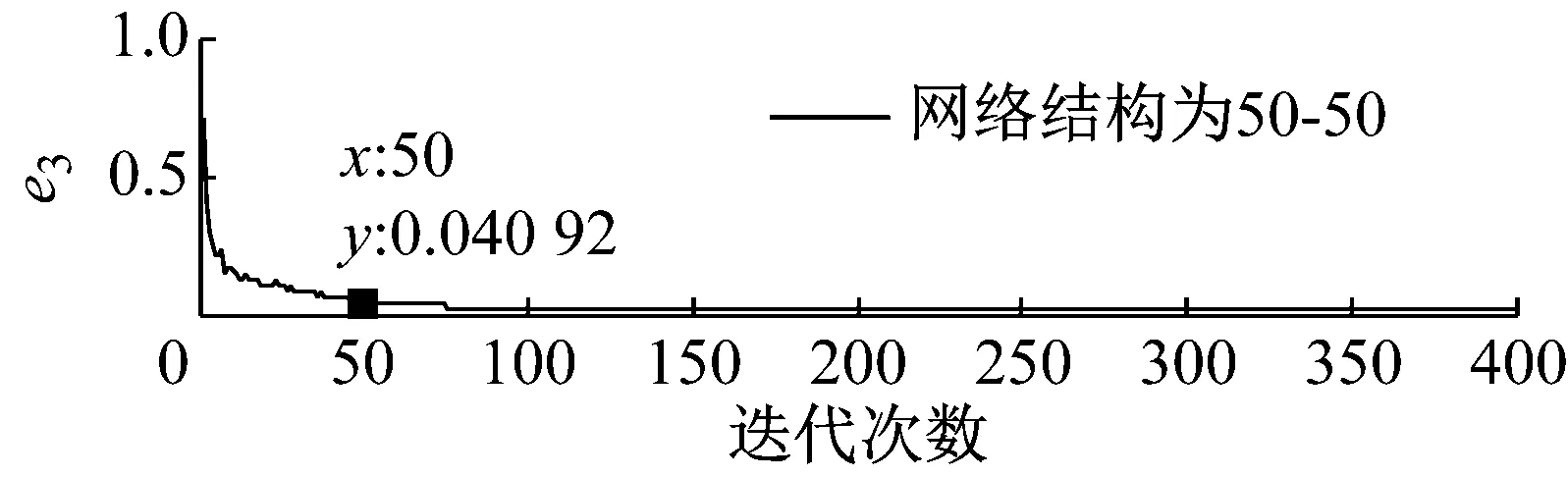
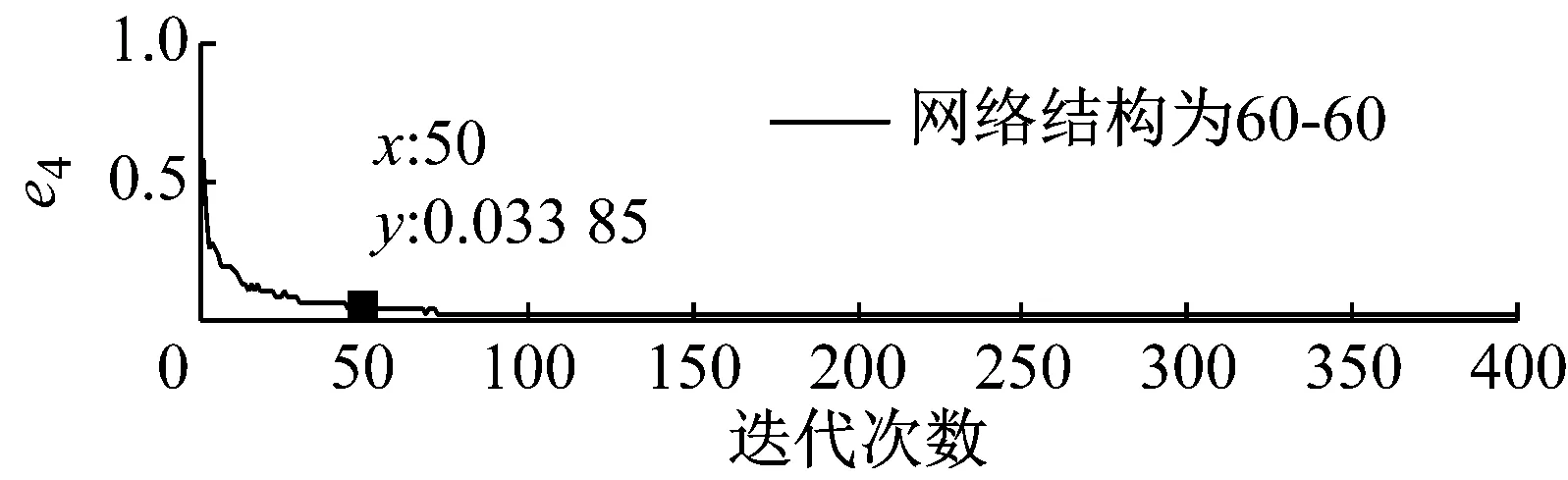
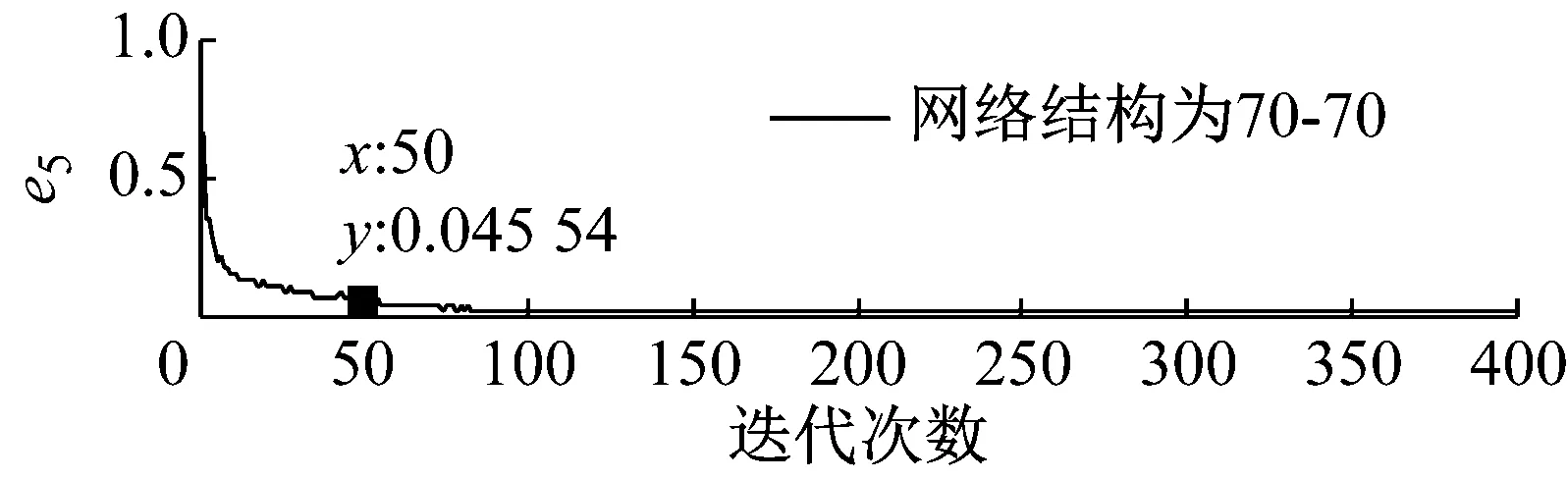
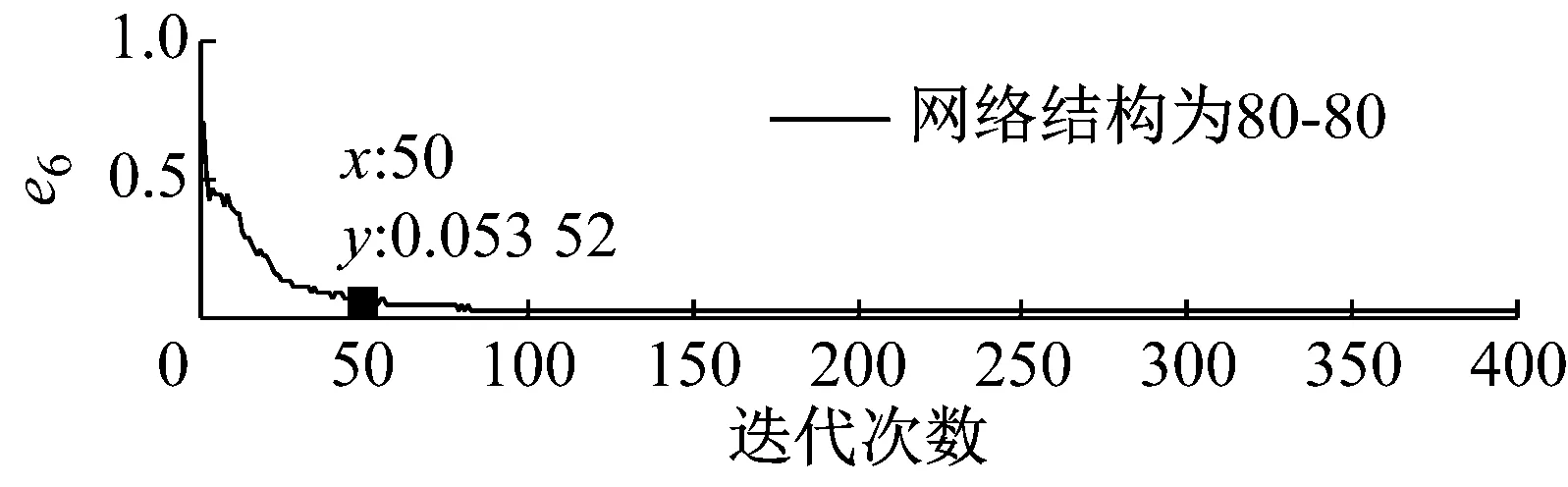
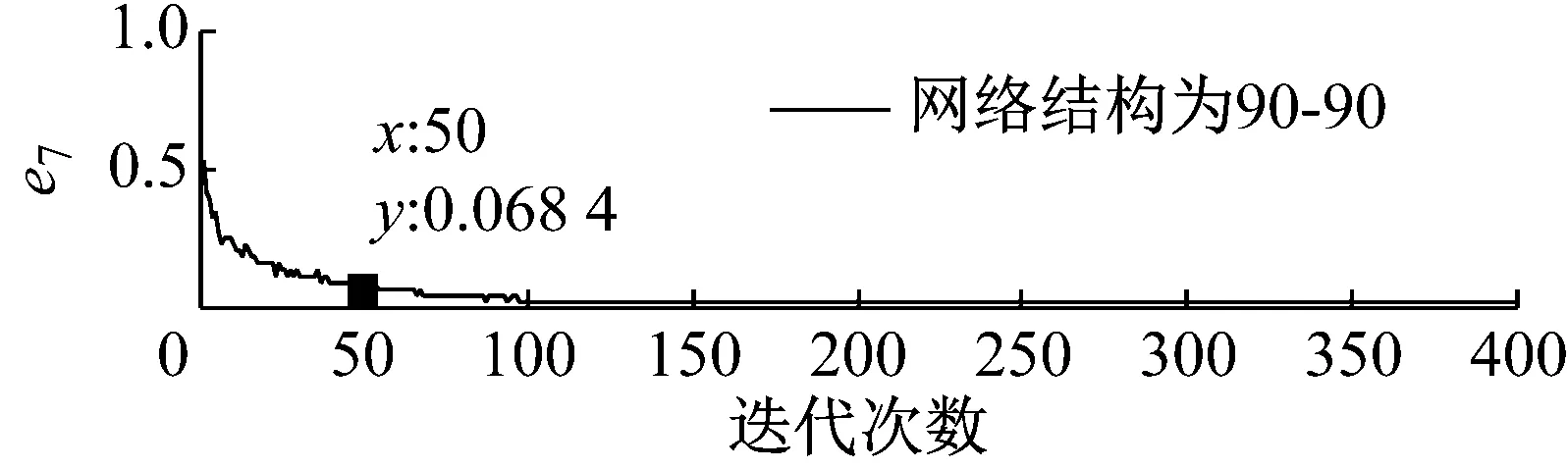


图5 不同隐层节点数下熵误差随迭代次数的变化趋势图
传统DBN方法的网络结构一般取决于样本长度,迭代次数选择100,样本容量选择100,网络结构取为60-60-60,其他参数同本文方法。三种方法的诊断结果,如表6所示。

表4 不同隐层节点数、不同网络深度下的熵误差

表5 各优选网络结构对应的诊断时间

图6 网络结构为40-40时熵误差随迭代次数的变化趋势图
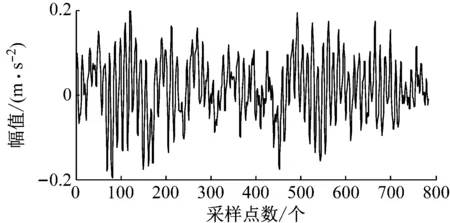
图7 原始数据波形
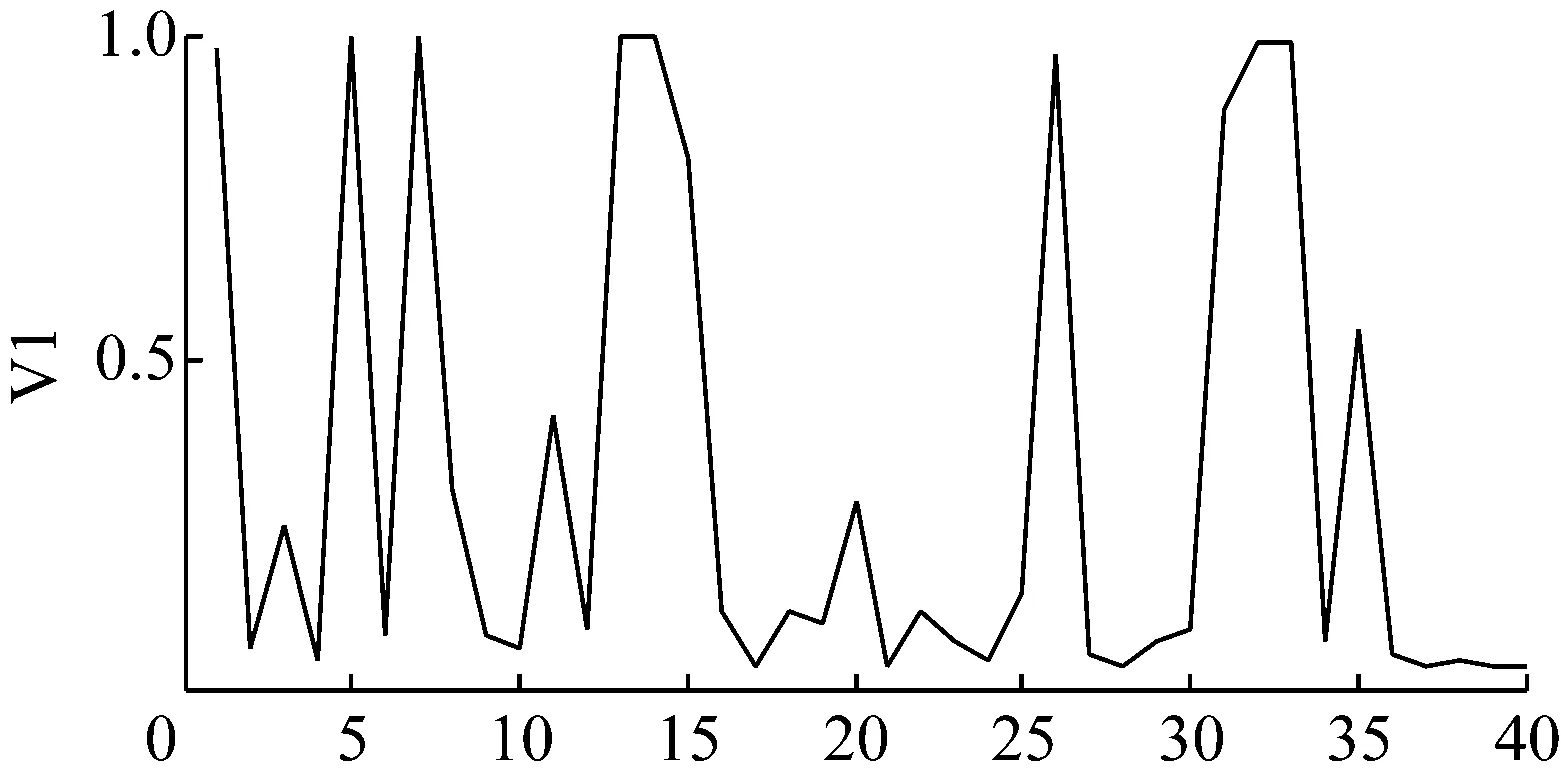
图8 第一层网络学习得到的数据波形
3 结 论
本文在DBN的基础上提出了结构自适应深度信念网络即SADBN,相较于传统的智能诊断方法及原始DBN方法,SADBN网络可以排除人为因素的干扰,充分利用网络优势,自适应地确定最优深度网络结构和网络特征参数,从而有效提高了诊断效率,为滚动轴承在线故障诊断提供了新的思路。
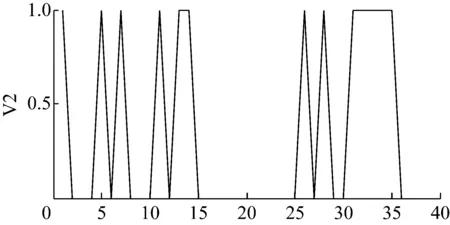
图9 第二层网络学习得到的数据波形

诊断方法特征参数选取网络结构诊断时间/s识别率/%常用特征+SVM人为选取-15.746 596DBN自动人为选取33.006 0100SADBN自动自适应11.857 0100
