特征选择与Logistic回归相结合的担保圈风险识别方法
2019-08-13赵文欣内蒙古大学计算机学院呼和浩特0002
刘 亚 ,李 华,2,郑 冰,3,赵文欣(内蒙古大学计算机学院,呼和浩特0002)
2(内蒙古大学图书与信息技术部,呼和浩特010021)
3(内蒙古建筑职业技术学院,呼和浩特010021)
E-mail:cslihua@imu.edu.cn
1 背景
随着DT(Data Technology,数据技术)时代的到来,大数据技术在金融领域应用广泛.互联网金融的出现,使得每年产生过数十PB的金融数据,而数据内容有着大规模、异质多元、组织结构松散的特点,给金融机构有效获取信息和知识带来了挑战.在银行风险管控方面,通过监管部门的现场监测,各种可疑金融交易(Suspicious Financial Transaction)行为[1]和企业信贷风险层出不穷,如洗钱担保圈、资金空转行为、规避监管的套利行为等.针对此类问题,目前行之有效的解决方法是结合各种数据分析技术,对银行交易数据、客户数据、信用数据、资产数据等信息挖掘分析,识别欺诈交易、反洗钱以及信贷风险等异常行为.面对海量的银行数据,传统的分析方式需要发生重大的改变,并建立与之相应的新的识别或预测模型.
担保圈是指多家企业通过相互担保或连环担保连接到一起而形成的以担保关系为链条的特殊利益体[2],其形态是由两个或两个以上法人客户以保证担保关系为纽带而形成的网络结构[2].其主要类型有互保、联保、循环保、担保链、集团内部担保圈以及混合担保圈[3].近年来受担保圈内企业经营不善、资金链断裂的影响,信贷风险在我国部分区域大量暴露,较大程度地冲击了银行信贷资产安全,严重地影响了银行和企业的正常运营,加剧了地方金融的不稳定,影响了区域经济的健康发展[4].由于担保圈的存在影响面较广,究其根本是圈内存在“高危”客户,即破产风险较高、偿债能力较弱的群体,这些客户容易发生违约行为.因此,在已知存在担保圈的情况下,如何识别担保圈是否存在风险,是本文研究的主要问题.
由于银行业务繁杂,包含的特征变量较多,若想通过数据分析建立异常识别精度较高的模型,其关键因素是选取具有代表性的特征变量,才能较好的反映出客户各种行为.利用选择出的新特征子集采用一定的方法建立风险识别模型,实现担保圈风险的识别,降低担保圈的“多米诺”效应给银行带来的危害[5].
本文的主要贡献如下:
1)提出一种 CSAFS(Clustering and Statistical Analysis Based on Feature Selection)特征选择算法,该算法采用特征聚类+主成分提取的思想,避免了传统聚类分析阈值K的问题,既能解决变量间的多重共线性问题[6],又能选择出覆盖全部或者大部分原始数据信息的、无冗余的新特征子集.
2)将CSAFS特征选择算法和Logistic回归相结合应用到识别担保圈风险的问题中,利用人工智能算法解决金融问题,避免了传统人工搭建模型的时间开销,提高了担保圈风险识别的准确率.通过ROC曲线对模型进行了效果评估,担保圈风险识别的准确率达到了95.6%,具有一定的实用性.
2 相关工作
本文主要是结合特征选取和Logistic回归方法建模进行担保圈的风险识别.在相关工作的研究中,将从特征选择、Logistic回归、担保圈风险识别三个方面进行描述.
2.1 特征选择
特征选择也称特征子集选择或属性选择.是数据挖掘技术中一种常用的数据预处理技巧[7].在特征选择方法的研究中[8-12],多数采用先聚类后选择的思想,但聚类条件和特征选择的依据不同.文献[10]提出一种将稀疏 K-means和分层聚类相结合的特征选择算法,该算法分为特征聚类和特征选择两个阶段,通过聚类将原始特征集划分成各个簇,利用 Lasso型惩罚因子在簇中进行特征选择.文献[11]提出了一种无监督特征选择方法,该方法结合最大信息系数和仿射传播进行特征聚类,在特征选择时,以每个簇中选取质心作为选择依据,该方法对不同分类器的分类问题进行了验证.文献[12]针对无监督特征选择问题,提出了一种密集子图发现方法,在获取非冗余特征集的基础上,以规范化的互信息为度量指标进行特征聚类,以方差为评价指标从每个簇中选择具有代表性的特征.
由此可见,特征选取方法存在两个问题:一是在样本聚类时需要预先设定阈值 K,而K值得选择决定特征选取的好坏;二是如何从每个簇群选取代表性特征,这个非常困难.
基于此,本文提出的CSAFS特征选择算法有效避免了确定K值问题,并采用提取主成分的方法进行最优特征子集选择,选择出的主成分可以覆盖全部或者大部分(85%以上)原始数据的信息,能够有效的反映出客户的行为信息.
2.2 Logistic回归
针对银行业务中出现的异常可疑行为,利用数据挖掘方法,从已有的数据出发寻找规律,建立识别模型,从而达到对未来的数据进行预测的目的.而基于数据挖掘方法的识别预测问题,目前国际上广泛采用的方法包括神经网络、决策树和Logistic回归.相较于其他两种方法,神经网络的“黑盒”性质,不太适用于银行风险识别,无法解释结论的由来.而Logistic回归在金融领域、流行病研究[13]和预测地质灾害[14]等应用较广.
在应用Logistic回归方法上[15-19],文献[15]以新浪微博为例,从发布用户、接受用户、微博内容三个方面进行特征提取,结合SVM分类器进行用户去重、垃圾用户滤除,将提取的特征输入到预测算法中,建立逻辑回归模型,实现对微博转发预测,与传统同类预测模型进行对比试验,验证本文方法的正确性与有效性.文献[16]通过建立五种数据挖掘分类模型(Logistic模型、线性判别分析法、K-means算法、分类树法和核密度分类方法等)与五种神经网络模型(包括专家杂合系统、多层感知器、径向基函数网络、模糊自适应共振和学习向量化子等)分别对澳大利亚与德国的两组财务数据样本进行了两类不同模式的分析,经其研究发现,Logistic模型在这10种分析方法中的判别准确率最高,分别达到了87.25%与76.3%.文献[17]是在国内企业财务预警研究中,采用Logistic回归模型有效预测出财务危机.
Logistic回归模型在一定程度上较好的实现了风险的识别和预警,但仍然存在一定的局限性:
1)在建立评估模型时需要设立许多假设条件,比如变量间相互独立、不存在多重共线性问题以及目标变量是二分类等等.
2)使用Logistic回归方法进行识别预警是进行研究是合适的,这就要求达到一定规模的数据量.但在有限的数据且数据维度较高的情况下,基于Logistic模型的统计分析方法的实际应用效果不好.
基于此,本文在进行Logistic回归前,对数据进行特征选择,对于大规模的数据量也可以很好的进行模型训练,提高了模型的识别精度.
2.3 担保圈风险识别
应用大数据技术实现银行的风险控制,主要体现在客户信用评估[20]以及违约风险概率的计算[21,22]等方面,从国内学者对于担保圈的研究情况看,由于受到数据可得性的限制,郎咸平等[23]、吕江林[24]、杜权[25]以及吉玉雪[4]等人针对担保圈产生的原因、担保圈风险识别及传染机制等方面进行理论分析.在应用大数据分析技术方面,文献[3]基于Spark大数据计算平台,开发出担保圈识别与管理系统,,可快捷完成图构建和最大连通图查找,在大量信贷数据中快速识别担保圈,具有基本的担保圈管理功能.但没有对担保圈进行进一步的分割,查找担保圈中关键客户.文献[26]描述了在银行业现实数据情况下,基于大数据的客户关联关系族谱及风险预警模型构建方法,主要从知识图谱算法来进行客户关联关系的描述.文献[27]从商业银行视角出发,将矩阵识别与担保圈网络的脆弱性分析结合,提出了一种改进的脆弱性分析模型,测度了风险阈值的合理边界.并以2016年某省经济开发区内所有信贷企业的担保圈关系图,进行风险识别和预警,提出风险化解措施.实证结果与该省商业银行信贷监测结果一致.
基于此,本文提出一种CSAFS特征选择算法与Logistic回归相结合的担保圈风险识别方法,实现了担保圈风险的识别,这不仅加快了数据计算的速度,并利用数据说话,科学有效.避免了传统的经济理论分析带来的不确定性问题.
3 担保圈风险识别算法描述
本文提出的CSAFS特征选择算法和Logistic回归算法相结合的担保圈风险识别方法,该方法主要分为三个阶段:
1)通过遍历数据集,识别出数据中所有的企业信贷担保圈.对担保圈中相关企业的贷款和资产等数据进行归一化处理.
2)采用CSAFS算法,对样本数据进行特征选择.
3)将最优特征子集作为输入项进行Logistic回归,建立风险识别模型,定位高风险客户.
下面给出文中用到的相关符号的表示方法说明及算法具体描述.
3.1 相关符号说明
本文在算法设计时涉及到多种公式运算,其中使用到的符号说明如表1所示.

表1 符号及其含义Table 1 Smbols and their meanings
3.2 CSAFS 算法描述
由于银行业务繁杂,包含的特征变量较多,如果通过数据分析建立异常识别精度较高的模型,其关键因素是选取具有代表性的特征变量,才能较好的反映出客户各种行为.因此本文提出了一种特征选择算法CSAFS,该算法主要分为三个阶段:
3.2.1 计算特征的相关系数rjk
假设数据集D包含n个特征,即特征集Q={x1,x2,…,xn},每个特征由m条数据构成,则数据集D是个n*m维的矩阵.记特征 xj的取值为 x1j,x2j,…,xmj(j=1,2,…,n),则可以用两个变量指标xj和 xk的样本相关系数rjk作为它们的相似性度量(j,k=1,2,…,n),也即:为平均度量(j=1,2,…n),(1)式中的rjk具有如下性质:

1)|rjk|≤ 1,对于一切j和k;并且|rjk|越接近 1,xk和 xk相关性越强;|rjk|越接近0,xj和 xk相关性越弱;
2)rjk=rkj,对于一切j和k,特别的rjj=1,也即相关系数矩阵F是n×n维对称矩阵.
3.2.2 特征聚类
将相关系数转换成距离,即特征xj和xk的距离为:

即相似度越高,特征间距离越近.
将每个数据点作为一个簇,应用公式(3)解出所有的距离构成矩阵F.在进行聚类时,本文选择平均距离法D(C1,C2)来度量两个簇间的距离.平均距离法原理图如图1所示.

其中,C表示簇,n1和n2分别表示簇C1、簇C2中变量的个数.
通过公式(4)计算,在进行特征聚类时,通过遍历距离矩阵F,找到距离小于D(C1,C2)的所有的类簇合并成一类.按照此方法可以将源数据集分为w个新类簇,分别为C1、C2…Cw,(w <n).
3.2.3 最优特征子集选择
假设簇C1中包含i个特征,对i个样本中的x进行标准化为珓x,构成i维矩阵,即X=[珓x1,珓x2,珓x3,…,珓xI]T,然后计算X的协方差矩阵∑,即计算各维度两两之间的协方差,这样各协方差∑ij组成了一个i×i的矩阵,称为协方差矩阵.∑是个对称矩阵.矩阵内的元素∑ij为:

其中cov(珓xI,珓xj)是珓xI和珓xj的协方差,E是期望.协方差矩阵∑的前i个较大的特征值λ1≥λ2≥…≥λI≥0,就是前i个主成分对应的方差,λi对应的特征向量ui就是主成分yi的关于珓xi的系数,而珓x是经过x标准化变换后的值.根据特征向量值与x值则可以求出Logistic回归模型的自变量的y值.即主成分y的求解为:
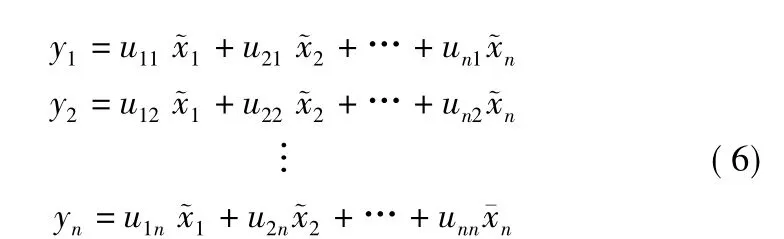

即:
其中y1是第一主成分,y2是第二主成分,…,yn是第n主成分.特征值λ的大小反映了各个主成分的影响力.求解公式:

计算出各个主成分对应的方差(信息)贡献率bj,bj用来反映信息量的大小,即

最终要选择几个主成分,即累计方差贡献率αm,确定主成分个数.即 y1、y2、…、ym,m 的确定是通过方差(信息)累计贡献率αm来确定的.即:

通常当累计贡献率大于85%,就认为能足够反映原始变量的信息了.
通过公式(5)~公式(9)计算,按照特征值的大小对所有类簇主成分的特征值λ进行排序,选取特征值>1,且累计方差贡献率达到85%的主因子构成最优特征子集Qbest.
CSAFS算法的具体描述如下:
输入:某银行信贷担保数据集D和原始特征集Q
输出:最优特征子集Qbest
步骤1.对数据集D进行归一化处理;
步骤2.通过公式(1)-公式(2),计算 Q={x1,x2,…,xn}中任意两个特征间的相关系数 rjk(j、k=1,2,…,n);
步骤3.通过公式(3),将相关系数转换成距离 djk(j、k=1,2,…,n),存入距离矩阵F;
步骤4.重复步骤2-3,遍历特征集 Q={x1,x2,…,xn},计算出所有的特征间距离构成距离矩阵F;
步骤5.通过公式(4),计算出F的平均距离D;
步骤6.比较 djk与 D,如果 djk<D,则 Ck(k=1,2,…,w,w <n);
步骤7.重复步骤5-6,遍历F,将源数据集分为w个新类簇,分别为 C1,C2,…,Cw;
步骤8.通过公式(5-9)对簇 Ck(k=1、2、…、w)进行主成分提取,求出对应的∑、λ、bj、αp和 y,如果 λ >1 且αp>0.85,则 y 为最优特征;
步骤9.重复步骤8,遍历所有的簇 C1,C2,…,Cw,求解出最优子集Qbest.
3.3 Logistic回归算法描述
通过CSAFS算法选择出最优特征子集Qbest,在训练模型阶段,最优特征作为自变量进行Logistic回归.
Logistic回归分析模型可表述为:

其中,xi(i=1,2,3,…,n)代表的是最优特征子集 Qbest的特征,α 为常数项.ci(i=1,2,3,…,n)是各影响因素的权重.P表示违约概率,0≤p≤1.如果Logistic回归值p越接近1,则表明该行为风险性较高;如果Logistic回归值p越接近0,则表明该行为风险性较低.
以银行信贷风险为例,假定Y表示贷款客户/企业违约与否事件,取1或0;X1,X2,…,Xn是影响Y的自变量,则Y与X的关系可表示:


通常设违约临界值P定为0.5,若计算所得P<0.5,则表示违约风险较低;若P>0.5,则说明违约风险较高,在银行信贷方面,通常以0.5为参考值,来判断企业是否存在违约风险,决定是否向贷款人发放贷款.
3.4 担保圈风险识别算法时间复杂度分析
担保圈风险识别算法的时间开销主要两个部分:特征选择阶段和Logistic回归阶段.
在CSAFS特征选择算法中,计算特征间相关系数的时间复杂度为O(n);特征聚类的时间复杂度为O(n2);进行特征选取的时间复杂度为O(w),则CSAFS算法的时间复杂度为O(n+n2+w),由于n>w,所以该算法的时间复杂度为O(n2).
在Logistic回归阶段,算法主要进行构造sigmoid函数,循环次数为I,计算数据集梯度,最终sigmoid函数求解分类.其时间复杂度O(n*C*I),n代表样本数量,C代表单个样本计算量(取决于梯度计算公式),I为迭代次数,取决于收敛速度.
综上所述,担保圈风险识别算法的时间复杂度O(n2+n*C*I).
4 实验与分析
其中,P表示违约概率,即Y=1的情形,(1-P)表示没有违约的概率,即Y=0的情形,进一步化简得:
本次研究使用的数据集是某商业银行五年内的信贷数据集.通过采集30家授信企业的担保数据,使用深度优先算法识别出26个担保圈(层级为2),涉及到273家企业.通过采集26个担保圈内所有企业的信贷、资产和交易等数据,经过数据过滤,一共包含21个自变量和一个表示违约标识的特征.即特征集Q={x1,x2,…,x22}.通常情况下,企业的净资本、负债、担保或被担保的金额、担保企业的数量等因素关系着整个担保圈是否稳定,如果一家影响度较高的企业发生违约,那么极有可能会出现“多米诺效应”[27].所以需要计算出圈内每个企业的担保金额占总担保额的比例A1(%)以及被担保数量占总担保数量的比例A2(%),将A1和A2作为新的类簇进行主成分分析.
由于对于该样本数据来说,存在样本分布不平衡是关键问题,在划分数据时,本文主要充分抽样法,将原数据的70%作为训练集用于训练分类器,30%作为测试集用于评估分类器性能.两个数据集中阴性和阳性数据比例接近,约等于为3∶1.
实验数据集以.csv格式保存在本地,实验软硬件环境如下:操作系统为 Windows 10,CPU为 Intel(R)Core(TM)2 Duo CPU E7300@2.93 GHz,内存为 8 GB,主要实验平台为SPSS和jupyter notebook,语言为python 3.
4.1 建立模型
通过CSAFS算法进行特征选取,求出9个主因子构成了新特征子集Qbest.
通过分析,将各自变量带入Logistic回归模型,通过SPSS进行回归分析得到模型的分析结果如表2所示.
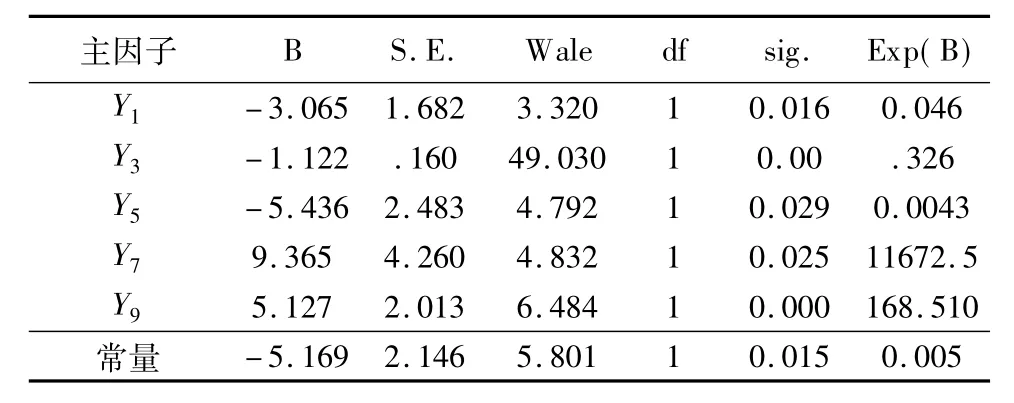
表2 Logistics回归估计结果Table 2 Table of Logistics regression estimation result
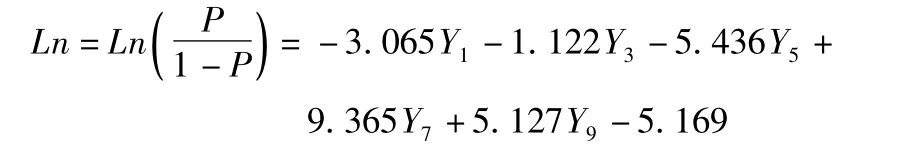
4.2 模型检验
针对上述Logistic回归模型,本文利用某样本数据进行检验,样本包含91组数据,其中标识为0(正常)的数据69组,标识为1(违约)的22组.检验结果如表3所示.
由表2可知,B代表回归系数,表示自变量和因变量的相关,通过 B 和 sig.(sig.<0.05)的值可以看出,主成分 Y1、Y3、Y5、Y7、Y9对担保圈是否存在风险具有显著性影响,表明自变量可以有效预测因变量的变异.则最终得到的Logistic模型表达式为:

表3 模型检验结果Table 3 Table of Model checking results
从表3可知,该模型对样本的识别准确率达到了95.6%,说明该模型能够较好地实现担保圈的风险识别.
为了进一步对模型进行评估,本文采用准确性指标ROC曲线下面积(ROC_AUC)对模型进行效果评估.相比于其他评价指标,ROC曲线不受正负样本分布变化的影响,具有一定的稳定性.通常情况下ROC曲线在对角线x=y的左上方,才具有一定的预测价值.ROC_AUC取值范围为[0,1],取值越大,代表模型整体准确性越好.AUC值为ROC曲线所覆盖的区域面积,一般而言,若AUC 取值在(0.5,1]之间,AUC越大,分类器分类效果越好[29].
ROC曲线主要是通过真阳率(True Positive Rate,TPR)和假阳率(False Positive Rate,FPR)两个指标进行绘制.ROC空间将FPR定义为X轴,TPR定义为Y轴.这两个值由前面的AUC四个值计算得到,公式如下:

其中,TP(true positive)为真正类;FP(false positive)为假正类;TN(true negative)为真负类;FN(false negative)为假负类.
感受性曲线(ROC)示意如图2所示.
由图2可知AUC值为ROC曲线所覆盖的区域面积,当AUC值大于0.5,具有一定的预测价值,由此证明该模型识别效果较好.

图2 感受性曲线(ROC)示意图Fig.2 Graph of receiver operating characteristic
针对模型的拟合情况进行了进一步的检验,检验结果如表4所示.

表4 模型拟合检验Table 4 Table of model fitting test
由表4可知,该模型的-2倍对数似然值比较理想,CoX&Snell和 Nagelkerke均接近于l,表明模型总体拟合效果较好.
4.3 方法评估
为了验证本文方法的有效性,本文从两个角度进行验证,验证CSAFS算法的有效性以及担保圈风险识别方法的有效性.
4.3.1 CSAFS 算法的有效性验证
由于CSAFS算法可以解决特征间的多重共线性问题,所以通过对特征间进行多重共线性诊断来验证CSAFS算法的有效性.首先对原始特征集(包含21个特征)进行相关性分析,求出特征间的相关系数矩阵,存在3个特征间的相关系数超过了0.9,表明原始特征集中存在多重共线性问题.
由上文知,通过CSAFS算法选取出最优特征子集作为自变量进行 logistics回归,最终确定主成分 Y1、Y3、Y5、Y7、Y9对担保圈是否存在风险具有显著性影响.针对主成分间是否多重共线性问题,本文将通过特征间的容忍度(Tolerance)和方差膨胀系数(Variance inflation factor,VIF)两个诊断指标来诊断.VIF的取值大于1,是容忍度的倒数,VIF越大,说明特征间存在多重共线性的可能性越大.一般而言,当容忍度>0.5,VIF<2时,表明特征间不存在多重共线性问题.特征间的共线性诊断如表5所示.
由表5可知,各个成分特征都满足不存在多重共线性的要求,这表明CSAFS算法在消除特征间多重共线性问题的有效性.
4.3.2 验证本文担保圈风险检测方法的有效性
本实验选用支持向量机(SVM)算法、决策树算法、随机森林(RF)算法以及朴素贝叶斯算法的四种应用较为广泛数据挖掘算法对同一组数据集进行建模.对比实验结果,验证本文担保圈风险检测方法的有效性.通过测试,各个模型的识别准确率如表6所示.

表5 多重共线性诊断表Table 5 Table of multicollinearity diagnostic

表6 算法的识别准确率对比Table 6 Comparison of algorithm recognition accuracy
由表6可知,在算法的识别准确率方面,决策树、RF、SVM和朴素贝叶斯均小于95.6%,虽然随机森林可以通过采样来减小计算量,并且能够利用并行方式进行模型训练,可以处理大规模高维数据,在担保圈风险的识别上比其他三种算法(SVM、决策树、朴素贝叶斯)识别的准确率高,但仍然低于本文方法的识别准确率.
由此可见,本文提出的担保圈风险识别方法的准确率最高.这五种算法的优缺点对比如表7所示.

表7 算法对比Table 7 Comparison of algorithm
5 总结
担保圈的存在影响面较广,究其根本是圈内存在“高危”客户,即破产风险较高、偿债能力较弱的群体,这些客户容易发生违约行为.本文提出一种CSAFS特征选择算法和Logistic回归相结合的方法,对银行信贷业务中出现的“担保圈”进行风险识别.首先采用CSAFS特征选择算法对原始数据集进行最优特征子集的选择,该算法有效避免了确定K值问题,选择出的新特征子集可以覆盖全部或者大部分(85%以上)原始数据的信息,能够有效的反映出客户的行为信息.最后将最优特征子集作为自变量进行Logistic回归,建立担保圈风险识别模型,经测试,该模型准确判别出了87组正确的样本,误判了4组样本,预测结果的准确率达到了95.6%.为了进一步验证本文方法的有效性和精准度,分别采用SVM算法、决策树算法、RF算法和朴素贝叶斯算法对同一组数据集进行建模,实验表明本文提出的方法识别率最高,具有一定的实用价值.
