利用Plackett-Luce模型的在线服务评价方法
2019-08-13张继康付晓东刘利军昆明理工大学信息工程与自动化学院云南省计算机技术应用重点实验室昆明650500
张继康,付晓东,2,岳 昆,刘 骊,刘利军(昆明理工大学信息工程与自动化学院云南省计算机技术应用重点实验室,昆明650500)
2(昆明理工大学航空学院,昆明650500)
3(云南大学信息学院,昆明650091)
E-mail:xiaodong_fu@hotmail.com
1 引言
在线服务是指利用互联网技术,向用户提供线上服务的方式.现如今互联网上存在大量功能相似或者相同的在线服务[1].用户在挑选服务时如何在大量的在线服务中快速准确选择到需要的服务是一个越来越严重的问题.另外,不法商家为了提高自己服务被选择的几率,会恶意修改用户给与的在线服务的评价,导致评价结果无法正确反应在线服务的性能,诱导用户做出错误选择[2].以上行为导致用户对互联网中的在线服务无法进行有效的筛选.因此,通过给服务排名的方式向用户提供在线服务成为了如今在线服务评价的主要手段[3].服务排名是把在线服务各项性能量化,最后整体得到在线服务评价结果的方法.用户在面对众多在线服务时,会根据排序名次挑选满足需求的服务.所以使用在线服务评价方法可以帮助用户在互联网中快速准确的找到满足需求的在线服务.
累加法、平均值法、构图法等方法是目前工业界和学术界常用的在线服务评价方法[4].这些方法为了方便计算,通常对在线服务进行评价时都假设用户具有相同的评价准则[5].然而受用户主观心理因素和消费偏好的影响,用户群体很难具有相似的评价准则,所以用户服务评分无法客观的的反应服务质量[6,7].这种情况下,即使性能相同的服务也可能会得到不同的评分.因此现有方法得到的评价结果会对用户选择起到诱导作用,做出不正确的选择.此外,互联网中还存在恶意修改或大批量增加在线服务的评分数据,来提高在线服务排序名次的行为,导致用户根据排序名次进行服务选择时会产生有利于自己的结果[8].
为解决上述问题,本文提出了一种利用Plackett-Luce模型[9,1https://www.amazon.cn/0]的在线服务评价方法,方法基于用户评价准则不一致的情况,根据用户对不同的在线服务的评分获取用户对服务可比较的偏好关系[11],根据在线服务间可比较的偏好关系进而得到在线服务评价结果.
2 相关工作
近年来,根据用户评价信息判断服务之间优劣关系的研究工作已经成为热点.文献[12]的研究提出基于服务属性的在线服务评价方法,例如价格、销量、信誉、评分等等.文献[13https://www.ebay.cn/-15]指出可以基于在线服务特征对在线服务进行评价,从大量评论信息中使用自然语言处理技术抽取服务描述信息对服务进行评价,得到最终评价结果.文献[16]指出目前工业界大部分是通过累加法与平均值法计算获取最终的评价值.平均值法是将所有用户对某个在线服务的评分进行累加得到一个总的服务评分,然后除以用户数量,将所得到的结果作为该服务的评价结果,目前Amazon1https://www.amazon.cn/和天猫2https://www.tmall.com/是使用平均值法作为网站内部的评价方法.累加法将用户对服务的评分进行分类并统计:当用户评分为4、5时,表示好评,即总分+1分;当用户评分为3时,表示中评,即得0分;当用户评分为1、2,表示为差评,即总分-1分.然后对总分进行累加,将所得到的结果作为该服务的评价结果,目前eBay3https://www.ebay.cn/和淘宝4https://www.taobao.com/是使用累加法作为网站内部的评价方法.但是每位用户对在线服务的评价准则和偏好只需要满足自己的需求,很难在用户群体中出现一致的偏好.因此,以上研究提出的在线服务评价方法涉及到用户反馈信息实质是不可比较的,通过这些方法得到的在线服务评价结果很难反应在线服务的真是性能.
文献[17]的研究是根据用户的多维度属性评价对服务的信任进行综合评价,进而得到个性化的评价结果.文献[18]提出了一种改进熵权的在线服务评价方法,对于多维度属性以主客观权重相结合的方法得到最终的评价结果.上述研究虽然都考虑到用户对在线服务评价准则不同的问题,但是还是根据用户服务评分直接计算得到最终评价结果,没有解决评分不可比较问题.文献[19]考虑从用户服务偏好入手解决该问题,构建加权有向图并计算最强路径得到最终的评价结果.文献[20]的研究基于偏好不一致的思路,以社会选择函数[21]为基础提出基于Copeland社会选择理论的在线服务评价方法,构建有向无环偏好图获取在线服务评价结果.上述研究虽然考虑到了用户偏好不一致的问题,但是提出的解决办法运行时间较长,整体效率较低.
考虑到以上研究中存在的不足,在用户评价准则不一致情况下,本文在不假设用户偏好一致的情况下,首先以用户对服务的评分为基础,将用户对不同在线服务的评分转换成用户服务可比较的偏好关系,通过可比较的偏好关系获取每个服务的占优次数;其次利用Plackett-Luce模型,将占优次数转换为概率;最后通过概率求解得出在线服务评价结果.
3 存在问题
3.1 问题定义
定义1.定义 U={u1,u2,…,um}为用户集合,定义 S={s1,s2,…,sn}为在线服务集合.其中,m 表示用户人数,n表示在线服务数量.
定义 2.定义 R=[rij]m×n(i=1,2,…,m;j=1,2,3,…,n)为用户-服务评分矩阵;其中,rij表示第i位用户ui对第j个在线服务sj的评分,若存在rij=0,则表示用户ui未对在线服务sj进行评分.
定义3.在线服务评价结果 P={p1,p2,…,pn},其中 pn表示第n个服务的评价值.若px>py,则表示服务sx优于服务sy.
显然,一种有效的在线服务评价方法应当满足以下准则:
1)反转对称性:对不同在线服务 sx、sy(1≤x,y≤n且 x≠y),若所有用户都认为服务sx比服务sy好,则最终结果为 sxsy.若每位用户改变想法,即每位用户都认为服务sy比服务sx好,则最终结果为 sxsy.
2)单调性:若有服务排序sxsy,则提高用户对服务sx的评分,则结果仍是sxsy;
3)非独裁性:若用户群体中只有一个用户认为sx比服务sy好,而其他所有用户认为sy比服务sx好,则最终结果结果不可能是sxsy;
4)抗操纵性:若存在服务排序sxsy,那么增加给予服务sy高评分的用户,则结果仍是sxsy;
3.2 举例说明
例1.假设有3个用户共同对4个在线服务进行评分,评分矩阵如表1所示.

表1 用户-服务评分表Table 1 User-service score sheet
根据表1的数据,利用eBay网站使用的累加法(Sum)和Amazon网站使用的平均值法(Avg)的得到评价值如表2所示.
由表1可见,每位用户给出的评价值是个人效用,无法和其他用户的评价比较.无法说明服务s1给用户u3的表现比服务s3给用户u1的表现更好.所以用户服务评分无法去直接计算,且运用服务评分直接计算得到的在线服务评价结果无法反映在线服务的真是性能.
此外,如果将用户u1对服务s2的评分提高至5分,这个操作会提升服务s2的评价值.但对其他服务的评价结果没有影响,这将导致服务s2的评价结果大大提升,所以上述方法抗操纵性较弱.因此,本文提出一种利用Plackett-Luce模型的在线服务评价方法,从服务偏好和服务占优次数的角度解决了在线服务评分不可比较的问题,同时提高了评价方法的抗操纵性.

表2 评价值表Table 2 Evaluation value table
4 利用Plackett-Luce模型的在线服务评价
Plackett-Luce模型是一个排序概率模型,描述模型内部参数排序的概率[22,23].对内部参数进行排序时,Plackett-Luce模型把排序过程分成许多个阶段且每个阶段互不影响,并在每个阶段选出一个最优服务.在当前阶段中,计算所有服务排序名次为第一的概率,把排序概率值最高的服务作为当前阶段的最优服务,重复这个过程直到所有阶段结束,得到服务的排序结果.
基于以上分析,本文将每位用户对不同服务的评分计算获取该用户对所有服务的偏好关系,然后通过偏好关系,得到每个服务的占优次数.通过占优次数解决了用户评分准则不一致导致的不同用户对同一服务的评分不可比较的问题.最后根据Plackett-Luce模型对数似然函数的迭代函数从概率的角度推断得到每个服务在整体服务中排序的概率,把排序权重转化的概率后作为评价结果向用户展示.
4.1 服务偏好获取
定义 4.用户-服务偏好关系矩阵 Pre=[preij]m×n(i=1,2,3,…,m;j=1,2,3,…,n).其中,preij表示第 i位用户 ui对第j个在线服务sj的偏好值.其中preij的计算公式如下所示:

对于同一用户,服务评分是可以比较的.所以计算用户-服务评分得到每位用户关于每个服务的偏好值pre,填入偏好矩阵Pre.在相同的情况下pre值大的服务被用户选择的概率更大.
算法1.根据用户服务评分矩阵R得到用户服务偏好矩阵Pre.
输入:用户服务评分矩阵R
输出:用户服务偏好矩阵Pre

算法1根据用户服务评分矩阵R得到用户服务偏好矩阵Pre,根据矩阵Pre中每位用户对每个服务的偏好关系确定服务的占优次数.
定义5.ui是一个用户,其评价的在线服务之间的偏好关系:若 preix>preiy,则偏好关系为 sxsy;若 preix=preiy,则偏好关系为 sx~sy;若 preix<preiy,则偏好关系为 sxsy.其中sxsy表示用户ui认为服务sx优于服务sy;sx~sy表示用户ui认为服务sx和服务sy无差别;sxsy表示用户ui认为服务sy优于服务sx.
定义 6.服务占优次数矩阵 T=[tij]m×n(i=1,2,3,…,m;j=1,2,3,…,n),其中 tij表示服务 sj在用户 ui偏好下的占优次数.
根据定义6,若在用户ui偏好下将服务sx和服务sy进行比较,那么服务sx的占优次数tix计算方式如下所示:
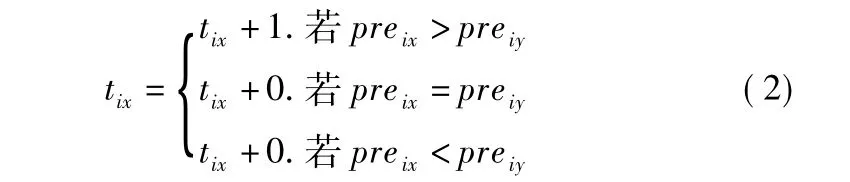
服务占优次数矩阵T是将m个用户评价的n个在线服务根据偏好值pre进行统计,若pre值大则记为占优1次.在每位用户的偏好下,每个服务都要和其他所有服务进行偏好值比较,统计每个服务的占优次数.
算法2.根据用户服务偏好矩阵Pre得到服务占优次数矩阵T.
输入:用户服务偏好矩阵Pre
输出:服务占优次数矩阵T

算法2根据用户偏好矩阵Pre构建服务占优次数矩阵T.在得到矩阵T后根据矩阵中每位用户偏好下每个服务的占优次数tij得到每个服务在所有用户偏好下总的占优次数.
定义7.用W表示服务在所有用户偏好下总的占优次数,W={W1,W2,W3,…,Wn}.其中 W 计算公式如下所示:

累加每个服务在所有用户偏好下的占优次数t,得到每个服务在所有用户偏好下总的占优次数W.根据得到的服务总的占优次数W,从概率的角度推断求解每个在线服务的评价结果.
4.2 服务排序获取
通过Plackett-Luce模型的对数似然函数(γ)构建关于权重值的迭代函数Q(γ),找到使对数似然函数(γ)取得最大值时的权重值γ的值.把权重值转化的概率,通过服务概率值大小对在线服务进行排序.
由于对数似然函数(γ)无法直接求解得到最大值,所以需要通过迭代的方式求解使得对数似然函数(γ)取得最大值的γ的值.
定义8.迭代函数Q(γx)如下所示:

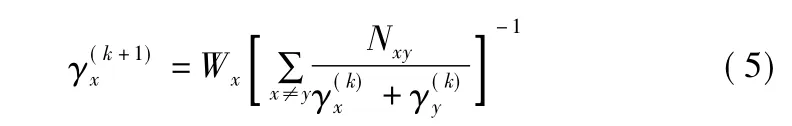
Nxy表示服务sx和服务sy的总占优次数之和.
|≤ε,则认为当前得到的结果 接近最优的权重
x
定义10.服务的排序权重值 γ ={γ1,γ2,γ3,…,γn},在Plackett-Luce模型中,服务sx的排序概率求解如下所示:
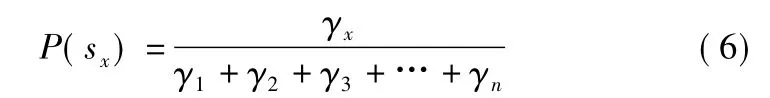
5 理论分析
5.1 孔多塞性[24]
在用户群体中,若服务sx与服务sy比较时有超过一半的用户认为服务sx比服务sy好,则sx称为孔多塞候选服务.
证明:有超过一半的用户认为sx优于sy,则Wx大于Wy,即服务sx的初始权重值比服务sy的初始权重值大,所以服务sx的评价结果不会比sy差.因此本方法满足孔多塞性.
孔多塞性表明最终排序结果满足用户群体中多数人的偏好.评价结果中孔多塞候选服务越多,那么评价结果就越满足多数人的偏好.
5.2 非独裁性[24]
将两个在线服务sxsy进行比较,若用户群体中仅有一位用户认为服务sx优于sy,其余所有用户都认为服务sy比服务sx好,那么最终排序结果服务sx的排序名次不会比服务sy高.
证明:仅有一位用户ui认为服务sx比服务sy好,即仅有一次preixpreiy,所以在线服务sy的占优次数只有1次,在有n个用户的情况下,服务sx的初始权重值是1/2n.而服务sy的初始权重值是2n-1/2n,所以在排序结果中服务sx的排序结果应该比服务sy低.
非独裁性表明有效的在线服务评价方法不会因为特定用户评价偏好影响最终的评价结果.
5.3 单调性[24]
存在任意的在线服务sx、sy并且排序结果为sxsy.若部分用户将给予服务sx较服务评分提高,对服务sy评分保持不变,那么服务sx的排序结果不应该变得比服务sy低,并且排序结果仍是sxsy.
证明:若果用户持续给予服务sx高评分而保持服务sy评分不变,那么服务sx的占优次数Wx只会增加而不会降低,所以服务sx的初始权重值会增加,迭代的结果就不会比增加前的结果差.若用户持续给予服务sy低评分,那么服务sy的占优次数Wy只会降低不会增加,所以服务sy的初始迭代权重只会降低不会增加,那么迭代结果就不会比之间的结果好,并且排序结果应该是sxsy.
单调性表明在线服务的评分发生变化时,该服务的排序结果也应该发生变化.若评分变高,那么排序结果应该提升;若评分降低,那么排序结果应该降低.
5.4 反转对称性[24]
对两个在线服务sx、sy,若所有用户都认为服务sx比服务sy好,那么排序结果应该为sxsy.若每位用户都改变想法,即每位用户都认为服务sx比服务sy差,那么最后的结果应该为 sxsy.
证明:若所有用户对在线服务sx、sy偏好由 sxsy变为sxsy,那么服务sx,sy之间的占优次数也就会发生反转,从而导致服务总的占优次数也会发生反转,即通过占优次数计算的排序结果由sxsy变为sxsy.
反转对称性表示在线服务评价方法不会偏袒任何一个在线服务,是公平性的体现.
6 实验结果及分析
根据文中提到的利用Plackett-Luce模型的在线服务评价方法,设计了在以下实验环境中进行验证该方法的合理性和有效性:PC机,Windows 10系统、Core i3处理器、8GB内存.我们采用了由GroupLens研究组发布的公共数据集MovieLens[25],其中该数据集包含1682部电影,943个用户,以及100,000条左右的评分(1-5).
因为Avg和Sum方法是目前工业界和学术界应用十分广泛的在线服务评价方法,所以本文选择这两种方法进行对比.而Copeland方法是基于用户服务评分矩阵,通过评分获取用户服务偏好关系,通过偏好关系获取最终的评价结果.因为本文方法也是从偏好角度入手,所以选择社会选择函数Copeland方法作为本文中的对比方法.
6.1 反转对称性实验
本实验中随机选取20个服务,将800为用户对所有在线服务评价全都取反(即1分变为5分,2分变为4分,3分不变),然后分别计算取反前在线服务权重值与取反后的在线服务权重值,权重值数据如图1所示.
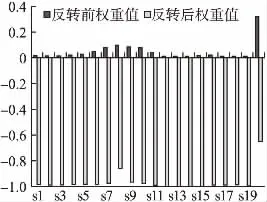
图1 反转对称性验证Fig.1 Reverse symmetry verification
由图1可见,本文方法在取反前排序权重值大的,取反后排序权重值变小,取反前排序权重值小的,取反后排序权重值变大,最终结果排序结果也反转了.所以在取反后本文方法得到的评价名次会变成相反的,因此本文方法满足反转对称性.
6.2 多数准则冲突实验
实验比较记录了本方法、Sum方法、Avg方法和Copeland方法得到的多数准则冲突的数量,实验结果如图2所示.
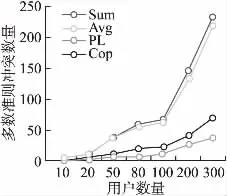
图2 多数准则冲突Fig.2 Most criteria conflict
由图2可见,由于孔多塞悖论[26]的存在,结果不可能达到100%.但是本文方法在不同数量在线服务中多数准则冲突的数量是最少的,远低于Sum方法、Avg方法与Copeland方法中的多数准则冲突数量.
6.3 单调性实验
为模拟单调性实验,分别选择50个~500个用户针对一个在线服务的评分进行修改,观察修改后评价值变化情况.实验结果图3(a)、图3(b)所示.

图3 单调性验证Fig.3 Monotonic verification
由图3可知,改变在线服务的评分时,在线服务评价值也会相应的发生变化.本文方法在评分降低时,最终排序结果也呈现降低趋势;在评分变高时,排序结果也是呈现上升趋势.因此本文方法满足单调性.
6.4 抗操纵性实验
随机选取某在线服务,通过增加高评分或低评分的数量来模拟操纵该服务评分,若果评价结果中,增加高或低评分数量对排序名次影响较小,则该方法得到的评价结果具有较好的抗操纵性.因此选择用户数量为300,对在线服务sx增加高评分或降低评分.分别对 10,20,30,40,50,60,70 位用户的评分进行修改.改变这些用户对在线服务的评分后排序名次如图4(a)、图4(b)所示.

图4 抗操纵性验证Fig.4 Anti-manipulation verification
根据图4(a)所示,随着高评分数量的增加,四种方法得到的评价结果都是呈现上升趋势,但是本文方法得到的排序名次改变幅度比其他三种方法得到的结果小;反之从图4(b)可知其他三种方法对于降低评分的影响也比本方法高.因此本方法更具抗操纵性.
6.5 性能实验
为验证本方法的效率,实验选择100~900个用户和20~100个在线服务的环境进行模拟,记录了系统在不同用户数量和服务数量下的运行时间(单位:s),运行结果如图5所示.

图5 不同样本规模下的运行时间Fig.5 Run time at different sample sizes
如图5所示,在固定用户数量下,运行时间虽然随服务数量的增加而增加,但是时间增长并不是呈指数级;在固定服务数量下,随着用户数量的增加,运行时间增长也不是呈指数级增长,因此本方法具有较高的效率.
7 结语
本文提出一种利用Plackett-Luce模型的在线服务评价方法,解决由于用户评价准则不一致导致的在线服务评分不可比较的问题.方法通过Plackett-Luce模型把不可比较的评分转化为可比较的用户偏好,然后再把用户偏好转化为在线服务排序概率,通过概率对在线服务进行总体评价.理论分析及实验验证表明了该方法的有效性以及抗操纵性.但是本方法对在线服务评价时仅从单一的评分角度衡量在线服务的性能,不能充分合理地表现在线服务的真是性能.因此下一步的工作将从多属性综合考虑在线服务性能,力求让在线服务评价结果更加准确.
