基于YOLO网络的人体跌倒检测方法
2019-08-12杨雪旗章国宝黄永明
杨雪旗, 唐 旭, 章国宝*, 黄永明
(东南大学 a. 自动化学院; b. 交通学院, 南京 210018)
跌倒是老年人受到意外伤害的重要原因之一, 特别是在无人看护的室内环境下的跌倒,如果不能被及时发现, 就更为危险, 因此发展跌倒行为检测技术有着重要的社会意义[1-2].目前对人体跌倒的检测大多使用手环、腰带报警器等穿戴式设备或环境传感器, 通过检测人体加速度或跌倒产生的异常声波等信息识别跌倒行为, 如王荣等[3]运用三轴加速度传感器检测人体跌倒; Li等[4]基于无线传感器网络实现人体跌倒检测.但这些方法在可靠性、识别精度和用户体验度等方面均存在不足.随着图像处理和神经网络技术的快速发展, 利用深度学习匹配视觉传感器的人体跌倒检测受到广泛关注[5-6].Yun等[7]利用视频中人体形状和运动学特征检测人体跌倒; Panahi等[8]利用机器视觉技术, 分析具备深度信息的图像实现人体跌倒检测; Wang等[9]基于主成分分析网络, 实现监控视频中人体的跌倒检测.但大部分人体跌倒检测算法仍然无法兼顾实时性和准确性的要求[8].室内环境下的人体活动较有限、干扰背景较简单, 为提高跌倒检测的实时性和准确性,本文通过候选框密度重组方法, 对You Only Look Once (YOLO)网络的候选框提取策略进行改进, 并根据人体形态学特征和方向梯度直方图(histogram of oriented gradient, HOG)特征[10-11], 基于两级支持向量机(support vector machine, SVM)分类器算法, 实现室内人体跌倒的快速检测.
1 基于YOLO网络的人体目标检测
1.1 基于密度重组的候选框提取
根据图像中人体的分布特征对YOLO网络候选框的提取策略进行改进, 以降低计算复杂度, 提高算法效率.YOLO网络结构由24个卷积层和2个全连接层构成, 图像被等分为S×S个网格, 图像的输出张量维度为S×S×(B×5+N), 其中B为每个网格负责的目标个数,N为识别类别数量,本文仅针对人体识别, 故N=1.图像中人体形态通常呈竖长的矩形,主要分布在水平方向上,本文利用这一特征对YOLO网络的候选框提取方案进行调整, 在网络中加入重组层以完成特征重组,增加水平方向候选框密度,降低竖直方向密度,则输出张量的维度为(2×S)×(S/2)×(B×5+1).
1.2 人体目标检测
候选框中存在人体目标的置信度C=Pp×Po×k, 式中Po为待测目标落入候选框对应网格的0/1指示变量;Pp表示候选框中待测目标为人体的条件概率;k为预测框与实际框的交集和并集的面积比,反映了当前预测框的预测精度.每个候选框的人体目标输出值为[x,y,w,h,C],其中x,y表示预测的网格中人体边界框中心位置相对于网格左上角坐标的偏移量;w,h分别表示边界框的宽度和高度.为了避免模型的不稳定性, 在实际训练过程中将x,y,w,h均进行归一化处理,其中x,y以网格的宽度和高度为参照;w,h分别以整幅图像的宽度和高度为参照.
1.3 候选框初始化
采用K-means聚类算法对训练数据集中的人体边界框进行聚类分析,得到与室内环境下人体目标边界框相近的候选框初始参数, 以提高网络的收敛速度.同时,为避免大尺寸候选框造成的误差,解除误差和边界框之间的耦合关系, 定义第m个待聚类框和样本n之间的距离函数Dmn=1-Mmn, 式中Mmn为待聚类框m与样本n的中心框交集面积和并集面积的比值,待聚类框和中心框重合面积越大,其比值越趋向于1,Dmn越小,相似度越高.
1.4 人体检测网络训练
对100名试验者分别采集4组样本图片,每组包含9种姿态,共计3 600张正样本图像.每组随机取8张共计3 200张图像,结合波兰大学的UR Fall Detection Dataset训练集共同作为本网络训练数据集.在训练过程中,对数据集进行35个迭代周期的训练,其中冲量常数取0.9,权重衰减系数设置为0.000 45.为避免初始学习率较高可能导致模型发散问题,本文在第一个迭代周期中,将学习率由0.001逐渐调整至0.01,并保持学习率不变继续训练14个迭代周期,然后将其调整为0.001训练10个迭代周期,最后10个迭代周期的训练采用0.000 1的学习率.
2 室内人体跌倒检测
本文提出的基于两级支持向量机分类器,结合人体形态学特征和HOG特征进行室内人体跌倒检测的方案流程如图1所示. 首先提取人体矩形宽高比和参考点位移速率等目标形态学特征,通过第一级SVM分类器判定当前行为状态,若为非常规行为状态, 则提取图像的HOG特征,然后通过第二级SVM分类器判断是否发生跌倒行为.为减少误警情况的发生,设置跌倒报警值,当累计判断人体跌倒达到阈值时发出警报.
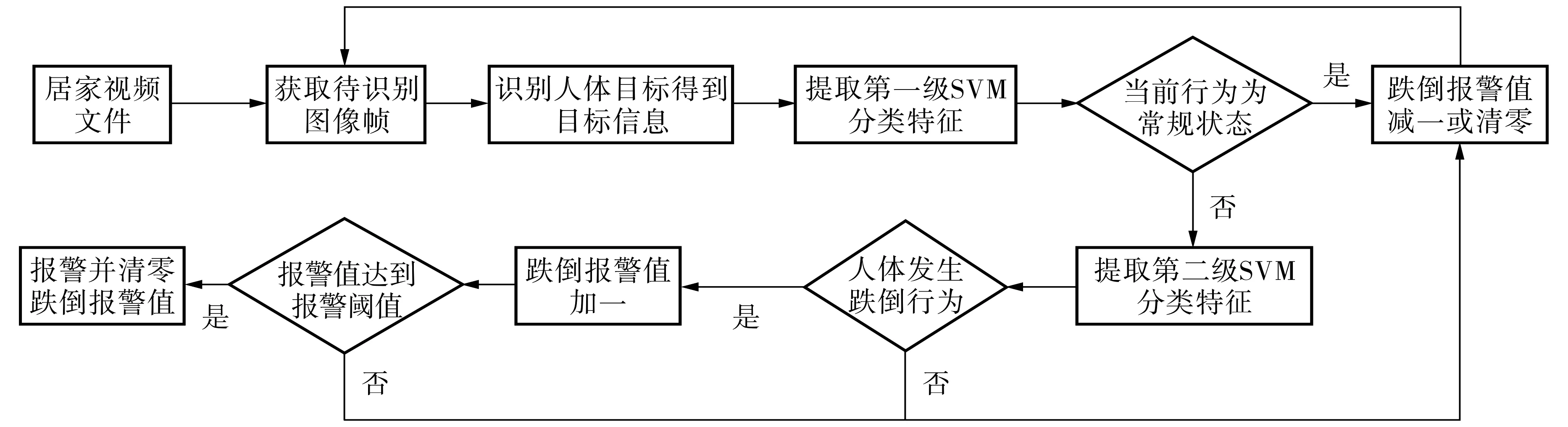
图1 室内人体跌倒检测方案流程Fig.1 Process of human fall detection in home environment
2.1 第一级SVM分类识别
将以下2个形态学特征作为第一级SVM分类器的判断特征,利用样本数据集训练分类器识别当前人体行为:
1) 人体矩形宽高比.人体近似等效为矩形,将人体目标识别得到的目标边界框作为人体最小外接矩形, 以最小外接矩形的宽高比X∶Y=(Xmax-Xmin)/(Ymax-Ymin)作为跌倒判别特征, 其中Xmax,Xmin分别为人体最小外接矩形横坐标的最大值和最小值;Ymax,Ymin分别为人体最小外接矩形纵坐标的最大值和最小值.正常活动时,人体矩形的宽高比相对较小且数值平稳;当人体发生跌倒时,宽高比的数值较大且波动明显.
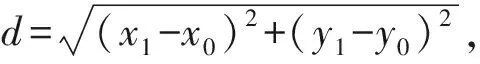
在设计分类模型时, 选取高斯径向基函数(radial basis function,RBF)K(d,dr)=exp(-‖d-dr‖2/(2σ2))作为SVM分类器的核函数, 其中dr为目标r的输入特征向量,d为训练过程中的变量,σ为自由参数.本文使用LIBSVM软件包建立分类模型, 重点调整以下参数变量: 1) 终止准则的容忍偏差σ,σ越小, 分类精度越高, 时间开销越大,由软件默认值0.001调整为0.000 1; 2) 衡量错误程度的损失函数参数q, 取默认值0.1; 3) 分类回归错误率参数u, 取值为0.5.利用交叉验证确定惩罚系数R=0.352 6, RBF的自带参数g=0.702 5.
2.2 第二级SVM分类识别
第一级SVM分类器判断发生异常行为时, 对检测出的人体目标区域提取HOG特征[12]输入训练好的第二级SVM分类器,判定是否发生人体跌倒行为.
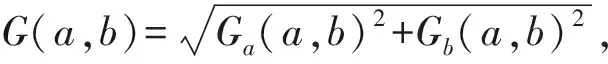
SVM分类模型中调整偏差容忍度参数σ为0.001, 确定惩罚系数R=0.458 3,自带参数g=0.971 5,其余参数保持不变.对用于支持向量机训练的正负样本数据进行HOG特征描述向量的提取,将特征向量导入SVM分类器完成训练,即可得到用于识别跌倒行为的分类模型.采用波兰大学跌倒检测数据库以及本课题组录制的部分跌倒样本作为分类训练的正样本.
3 试验结果和分析
10名样本成员分别完成行走、坐起、蹲起、弯腰、卧起、跌倒等6种行为各30次,拍摄每组行为共300次,总计1 800次试验行为.
根据传统的人体跌倒识别算法,设置人体行为几何特征阈值,通过分析待识别目标特征与跌倒阈值的关系进行判断.对试验视频每20帧图像采样1次,分别通过本文的识别器和传统算法进行跌倒行为判别,试验结果如表1所示.由表1可知,本文算法可以有效区分人体的跌倒行为和行走、坐卧等正常行为,正检率达96.33%,与传统算法相比提高约8.16%.但同时也发现,各行为识别效果受算法的一级判断以人体形态学特征为识别特征的影响,行走状态与人体跌倒的区别最为明显, 故正检率最高.而卧起行为与跌倒行为的姿态特征较相似,因此识别率最低,仅为94.33%.后续研究可根据当前方案的识别特点,针对识别率较低的行为进行优化处理,提高整体识别率.
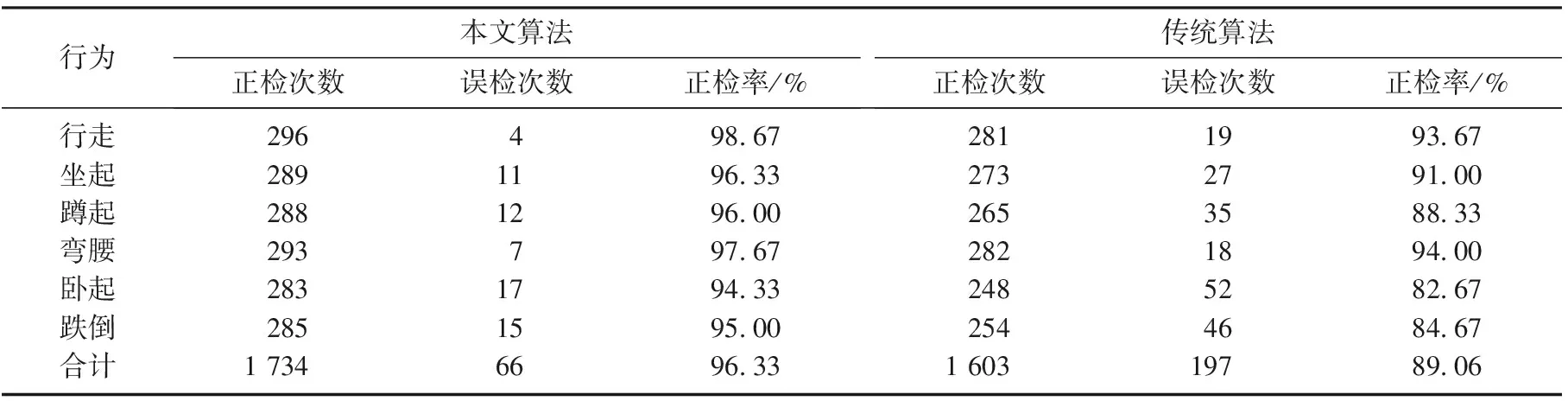
表1 人体行为识别结果
4 结论
本文利用YOLO网络识别人体目标的方案替代传统的前后景差分方案,提高了目标检测精度.同时利用形态学特征和HOG特征, 配合两级SVM分类器进行训练识别,降低运算成本,提高实时性.后续研究的改进方向包括: 精简目标检测网络,降低人体目标检测过程中的计算成本;引入人体局部特征作为跌倒识别的辅助方式,如头部高度、头部运动特征、头肩位置关系等,进行多特征融合识别,提高人体被部分遮挡情况下跌倒行为的识别精度和鲁棒性.
