基于fastText模型的词向量表示改进算法
2019-07-09阴爱英吴运兵郑一江余小燕
阴爱英,吴运兵,郑一江,余小燕
(1.福州大学至诚学院计算机工程系,福建福州 350002;2.福州大学数学与计算机科学学院,福建福州 350108)
0 引言
词向量表示在自然语言处理中具有十分重要的应用,如文本分类[1]、信息检索、词性标注[2]、情感分析[3]等.近年来,深度学习技术在自然语言处理领域中的应用,始终以Bengio等[4]、Mikolov等[5-6]提出神经语言模型为代表(如CBOW和skip-gram等),为词向量的分布式文本表示奠定了基础.Bengio等[4]利用神经网络构建语言模型,能巧妙解决数据稀疏性问题对建模的影响,同时克服模型维数灾难问题.Mikolov等[7]通过循环神经网络训练语言模型(RNNLM),利用隐含层循环而得到较多的上下文信息,并降低训练模型参数个数等.然而,skip-gram模型在训练时仅考虑到文本上下文语义信息,忽略了单词句法形态结构信息对词向量训练的影响,无法有效地预测句法结构相似的单词.Bojanowski等[8]提出fastText模型,该模型对于预测句法相似性的单词具有一定的提升.但fastText模型在n-gram分解单词结构时,利用“〈”和“〉”作为单词前缀和后缀边界区别于单词的其它特征序列,针对相同序列,却有不同向量表示,造成过多噪声数据.因此,其预测准确率并不理想.
基于此,本文提出基于fastText模型词向量训练模型的改进算法,不仅能预测语义相似的单词,也能较好解决句法相似单词的预测.实验结果表明,本文模型在单词关系评分、语义相似性、句法相似性均取得较好准确率.
1 模型改进及算法描述
在文本序列向量表示方面,许多学者进行深入研究.Le等[9]基于无监督学习算法提出段落向量表示,从可变长度的文本片段(如句子、段落和文档)中学习固定长度的特征表示;Pennington等[10]提出Glove模型,构建语料库中词的共现矩阵对单词进行向量化表示,使向量之间尽可能蕴含语义和语法信息;Wieting等[11]提出Charagram嵌入模型,该模型是学习基于字符组合及文本序列的简单方法,对于一个单词(或句子)可以用n-gram字符序列表示,并通过一个非线性转换到低维向量空间,在单词相似性、句子相似性和词性标注等方面具有良好效果.
1.1 fastText模型
fastText模型[8]是基于skip-gram基础上加以改进,对输入上下文的每一个单词采用基于词n-gram格式进行分解,并将分解处理后的所有单词n-gram和原单词进行相加,做为代表上下文的语义信息,其目的是根据英文单词中前后缀等语义形态上相似性,建立词与词间的相互联系,以此解决skip-gram模型在处理单词句法形态结构时预测准确率不高的情况.fastText模型n-gram分解格式如下,假设单词“where”,则3-gram 分解序列情况为“〈wh”,“whe”,“her”,“ere”,“re〉”,以及单词本身序列“〈where〉”,其中“〈”和“〉”分别表示单词前缀和后缀标记符.假设通过分解后得到n-gram的字典大小为G,对于一个单词w,记gw∈{1,…,G}为出现在单词w中所有n-gram集合.对于每个n-gram序列g使用向量Zg来进行表示,因此评分函数s改为:

fastText模型在文本分类和词向量特征表示学习方面具有较好性能,特别是针对罕见单词具有较好预测效果,然而也存在一些不足.1)对长度较短的常见单词,其句法形态变化会产生过多的噪声,预测效果不理想;2)对于拼写相近但意思不同的单词预测效果不理想;3)由于在利用n-gram分解时,引入单词前后缀标记符,会造成子序列的冗余.
1.2 模型改进与算法描述
首先,由于fastText模型在选取n-gram大小是从3-gram到6-gram,这样做对于一些长度较长的罕见单词起到较好预测作用,然而对于常见单词,由于单词本身不长,如果选择3-gram到6-gram分解时,会造成更多噪声数据.如单词“act”和“action”,3-gram 仅有“〈ac”和“act”是相同,而对于5-gram,单词“act”就没有,因此,在共同部分较短情况下,产生出来噪声数量和共同部分序列数量比往往偏大,使得在初始化时两者间的距离偏离较远.其次,使用前后缀标记符“〈”和“〉”会产生效果相同序列却有不同向量表示,如单词“act”3-gram序列“act”,而4-gram中“〈act”,这两者含义一样,但却被赋予不同向量.再次,fastText模型在处理词组时,采用预先设定阈值来判断是否满足词组情况,且在n-gram分解中包含词组中空格等无关字符,显然不能很好解决词组问题预测等情况.
鉴于fastText模型缺陷,本文提出模型改进思想.首先,针对词组对模型预测准确率造成影响,本文结合stopwords数据集预处理方式对训练数据进行处理[12],剔除那些使用频率过高且没有实际意义的介词,从而将词组转变为单独单词进行训练.具体剔除词规则如:将I,a,about,an,is,on,to,in,the,and等词剔除,通过剔除后将动词+介词的词组结构化解为单独单词.其次,考虑到英文单词词性前后缀特性,如过去式采用ed,比较级采用er、最高级采用est等,以及名词、副词、复数等词的前后缀绝大部分在2-gram到4-gram之间,因此,本文在选取n-gram方面,主要选择2-gram、3-gram和4-gram进行训练,以此解决常见单词中由于过多n-gram而造成较多噪声数据.同时,在模型中去除fastText中单词前缀“〈”和后缀“〉”标记符,解决相同含义序列而被赋予不同初始向量问题.
算法流程为:首先对文本数据进行预处理,去掉标点符号和stopwords数据集中无关的介词等;其次通过统计形成单词词典,在单词词典基础上构造n-gram词典(其中n的取值为2到4),并将词典中每个单词表示为n-gram子序列集;接着初始化各个子序列向量,通过计算损失函数并结合随机梯度下降法对其进行优化,可以对子序列向量进行更改.具体算法流程图1所示.

图1 改进算法流程图Fig.1 Improved algorithm flow chart
2 实验及结果分析
2.1 实验数据集
本文实验数据来自于4个英文数据集,具体如下:
1)IMDB上的影评数据集[13].在文献[8]中对fastText模型训练数据集采用Wikipedia上数据,由于该数据集过于庞大,训练时间过久,因此,本文采用了IMDB提供数据集进行模型训练.该数据集上约83万个单词数,大小约1.2 MB.
2)WS353数据集[14].该数据集包含由13位专家对353个常见单词对进行人工标注.WS353数据集也是文献[8]用于测试模型词向量相关性评价.
3)RW数据集(rare word dataset).该数据集是由Luong等[15]提供较为罕见单词对数据集,其单词数量共有2 034对.RW数据集主要是为验证词向量模型是否适应于较为罕见或复杂的单词而设置数据集.
4)由文献[5]提供的语义相似性(semantic similarity)和句法相似性(syntactic similarity)关系单词对.数据集中包含5个类型的语义问题和9个类型的句法问题,具体情况可详见文献[5].
2.2 实验设置及结果分析
为验证所提方法有效性,将本文模型与 skip-gram[5-6]、CBOW[5-6]、fastText[8]等模型进行对比,设置相关实验.实验参数为:词向量维数大小均为200(如无另外说明),CBOW滑动窗口为2,skip-gram、fast-Text和本文模型滑动窗口均为1,迭代次数为10 000次,每次迭代大小为50,初始学习率为0.5.
实验1 基于人工评分标准的单词相关性
为检验模型对于人工标注数据集(常见单词对和罕见单词对)的预测能力是否达到人工评分的期望值.本次实验数据集为WS353和RW,依据文献[8]的评价标准,计算斯皮尔曼等级相关系数和余弦相似性.由于实验测试集出现在训练集中的单词数量较少,因此,斯皮尔曼等级相关系数值选取范围在[-1,1]之间,而余弦相似性值选取为前3名.实验结果如表1所示.
从表1可以看出:
1)在常见单词对数据集(WS353)中,其skip-gram和CBOW预测结果相比于fastText和本文模型较好.其原因由于skip-gram和CBOW是根据上下文来训练词向量,在训练过程中,仅从单词的意思层面考虑,并未考虑到单词的词根、词缀等结构,而在WS353数据集中,绝大多数单词并没有词根和词缀等复杂信息,因此,skip-gram和CBOW预测单词相关性的性能要更好些.

表1 人工评分标准的结果Tab.1 The result of artificial scoring criteria
2)在罕见单词对数据集(RW)中,fastText和本文模型的性能要高于skip-gram和CBOW.其原因是在RW数据集中,有更多词根、词缀等词的结构信息,fastText和本文模型利用n-gram格式对词的结构进行分析和考虑,因此,其性能要高于skip-gram和CBOW.
3)本文模型在WS353和RW数据集中,其性能均比fastText要好.其原因为本文模型在n-gram格式上限制n的值(为2到4),并去除fastText中词缀标记符,降低了模型分解所产生的噪声数据,因此,其模型性能优于fastText.
实验2 基于语义相似性和句法相似性
语义相似性是指通过模型能找到其语义相近的单词,如:X=vector("France")-vector("Paris")+vector("Germany"),则X得到为单词“Berlin”;而句法相似性是指通过模型能找到其句法相似的单词,如反义词、复数形式、比较词等,例:X=vector("possibly")-vector("impossibly")+vector("ethical"),则X得到为单词“unethical”.本次实验数据集为文献[5]提供,评价标准是计算单词词向量的余弦相似性,由于测试用例较少,选取余弦相似性排名前3的单词数.实验结果如表2所示.

表2 semantic和syntactic关系准确率Tab.2 Accuracy of semantic and syntactic (%)
从表2可以看出:
1)从语义相似性(semantic similarity)上看,skip-gram预测准确率最高,分别比fastText和本文模型高出11.1%和10.1%.其原因skip-gram是基于单词语义来更改词向量的值,而fastText和本文模型是基于单词结构信息上融入语义作用,所以预测结果相对于skip-gram较差.
2)从句法相似性(syntactic similarity)上看,本文模型预测准确率最好,分别比skip-gram和fastText高出30.7%和6.1%.因为syntactic similarity测试集中,绝大多数单词具有相应前后缀等结构,而本文模型主要是考虑单词本身结构信息,因此,预测准确率高于skip-gram.同时,由于本文模型在分解单词结构是较于fastText更加精炼,减少冗余序列和噪声的比例,并结合stopwords数据处理,降低介词等带来的影响,因此,模型预测准确率高于fastText.
实验3词向量维数对模型准确率的影响
为了解词向量维数大小对本文模型预测准确率影响情况,选取实验2中的句法相似性(syntactic similarity)数据集进行验证(由于语义相关性测试集数据量较少),分别选取词向量维数为100~600进行实验,结果如图2所示.
从图2(a)可以看出,随着词向量维数大小的递增,模型预测准确率也呈现出递增趋势.然而,当词向量维数增加到300时,预测准确率达到最高,继续加大词向量维数,预测准确率有所下降,并趋向于平稳状态.其原因是:当维数较小时,模型词向量变化方向过大,产生较多误差,影响模型预测准确率;而当词向量维数过大时,向量改变方向并不明显,因此,模型预测准确率并未有过多变化.同时,随着词向量维数的增大,运行时间也逐步加大,具体情况如图2(b)所示.
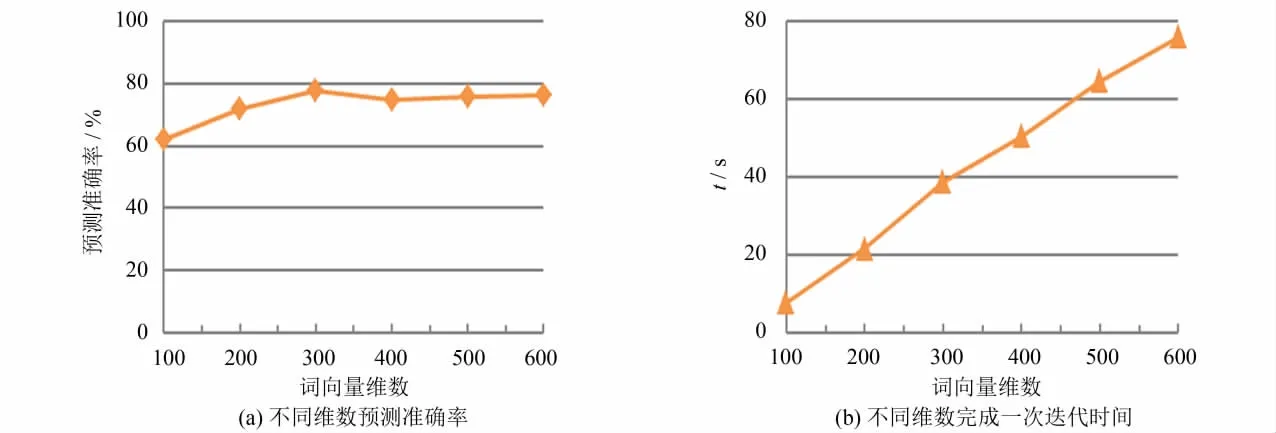
图2 词向量维数大小对模型预测准确率影响及所需时间Fig.2 Influence of word vector dimensions on the model prediction accuracy and the required time
实验4词向量二维空间分布情况
为更加直观了解词向量表示模型在二维空间分布情况,选取skip-gram和本文模型结合PCA(principal component analysis)[6]降维方式进行可视化处理,通过降维后的词向量在二维空间分布情况如图3所示.
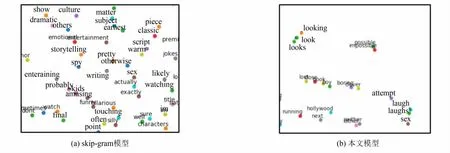
图3 skip-gram模型及本文模型词向量空间分布Fig.3 Distribution word vectors of skip-gram model and our model
从图3(a)可以看出,skip-gram是基于单词语义的词向量模型,对于语义相近的单词,其降维后二维空间向量距离也相对靠近,如图中单词“amusing”和“funny”两个单词.而对于拼写结构相近的单词,其词向量并未靠近,如图中“others”和“otherwise”两个单词.图3(b)是本文模型的词向量分布情况,从图中可以看出,本文模型考虑单词结构,其语义相近且拼写结构相似的单词,词向量相对接近,而对于那些拼写结构相似却语义不同的单词,词向量的距离相对偏远,如图中“look”和“book”两个单词.
实验5词向量模型用于情感分类任务
为进一步了解词向量模型在一些应用任务中情况,本次实验以情感分类任务为例,目的是验证词向量模型在情感分类任务中有效性.实验数据集为IMDB电影正负向评论,其中标注正、负向情感文本分别有25 000个,本文实验选取正、负向情感各12 500条.利用机器学习SVM进行情感分类,实验评价标准为准确率、召回率和F1值,对比实验为skip-gram、fastText及本文模型,实验结果如表3所示.

表3 情感分类的准确率、召回率和F1值Tab.3 Precision,recall and F1-score of sentiment classification (%)
从表3可以看出,三种词向量模型在情感分类任务中的性能差别不大,但本文模型效果稍微优于skip-gram和fastText.其原因是本文模型在进行n-gram选择时减少n的数量,并剔除一些无用词的干扰,减少噪声数据,分类性能相对高一些,说明本文模型可以适用于情感分类的词向量任务.
3 结语
针对fastText中存在一些问题,本文提出基于fastText模型的词向量表示改进算法.首先,利用stopwords处理技术对模型训练数据集进行预处理,剔除空格和一些无意义介词对词组的干扰,降低词组引起噪声数据;其次,结合英文单词句法形态结构特点,缩短n-gram分解格式,并去除fastText中前后缀分隔标记符.实验表明,文章提出改进模型算法在单词关系评分、语义相似性、句法相似性均取得较好的准确率.在下一步研究中,将考虑利用英文单词的音节等进行分解,以及进一步考虑词组结构对模型预测影响问题,以便提高模型预测准确率.
