特征概率图约束全卷积网络的目标分割
2019-07-09宋健武陈飞王美清
宋健武,陈飞,王美清
(福州大学数学与计算机科学学院,福建福州 350108)
0 引言
图像分割是计算机视觉领域中一个非常重要的问题,目的是将图像的目标与背景区分出来[1].针对此问题,许多学者提出不同的算法,如将相似性质的像素集合构成区域的区域生长法[2]、边缘检测法[3]等.基于偏微分方程的方法,比如C-V模型[4]利用图像均值信息来分割,但其不能很好地适应灰度不均匀的图像,可变区域拟合能量模型[5](RSF模型)适用于灰度不均匀的图像分割,但存在对初始曲线敏感等问题.近年来,深度学习在图像处理领域取得了很好的进展.深度学习往往根据具体数据集,构造网络模型来学习该数据集的特征,底层网络学习如边角点等特征,高层网络学习较抽象的特征.AlexNet[6]首次在大规模图像数据集分类上得到较好的分类结果,而后VGG16[7]采用了较为简洁的结构,同样达到了较好的分类效果,很多学者在此网络基础上做了改进.GoogLeNet[8]引入Inception结构,具有较复杂的网络拓扑结构,能获得丰富的图像特征.文献[9]提出了带有Reaction项可训练的扩散模型,文献[10]提出全卷积神经网络模型,移除了下采样层,在图像去噪方面取得较好效果.在基于全卷积网络的图像分割中,U-Net[11]与 SegNet[12]是常用的 Encoder-Decoder型分割网络模型.
本研究在常用的Encoder-Decoder分割网络模型基础上,借鉴文献[10]模型的方法,移除下采样层,相比具有下采层网络,该模型对输入图像大小没有限制.采用卷积层、批归一化层、激活层等作为网络的模块,构成整个模型.由于没有下采样层,减少了下采样过程的信息丢失.类比常见的L2损失函数,本研究定义了一个新的损失函数,可以减少部分错分像素点数目,改善了分割视觉效果和提高了被正确分类的像素占图像像素总和的比例.
1 U-Net
U-Net[11]是医学图像领域常用的Encoder-Decoder型的深度卷积神经网络之一,其网络结构包含收缩通道和扩张通道.收缩通道由重复的模块构成,该重复模块包含三个部分:两个卷积核大小为3×3的卷积层,一个步长为2的2×2最大化下采样层,以及ReLU激活层.每进行一次下采样层时,后续的卷积层的通道数增加一倍.构成扩张通道的重复模块同样包含三个部分:2×2大小的反卷积层,后续的卷积层的通道数减少为上一层的一半,紧接着两个卷积核大小为3×3的卷积层,以及ReLU激活层.最后一个卷积层卷积核大小为1×1,通道数与类别数对应.该网络共包含23个卷积层.针对细胞分割问题,为了处理类别不平衡问题,U-Net使用如下损失函数:

其中:pl(x)(x)为x属于第l类的概率;w(x)为权重项,赋予某些像素点更大的权重,加大对这些像素被错误分类的惩罚.w(x)的计算公式如下:
其中,wε(x)是在训练数据集中根据标签计算的权重,用来处理类别不平衡问题;w0,σ是人工设置参数;d1,d2分别是该像素离与之最近和次近的细胞边界的距离.初始化对神经网络的训练非常重要,U-Net采用如下方式初始化参数W

2 特征概率图约束全卷积网络(FPM-FCN)
将Encoder-Decoder型网络中的下采样层移除,将获得图像更多细节信息,由于没有下采样层,网络模型输出图像大小可以与输入图像大小保持一致.本研究基于Encoder-Decoder型网络提出了特征概率图约束全卷积网络(feature probability map constrained fully convolutional neural network,FPM-FCN),由27个卷积层模块组成,前面模块采用较大卷积核,可以在较大的感受范围内提取图像特征;后面模块采用较小卷积核,可以缩短训练与测试时间,提高分割精度.同时本研究定义了基于特征概率图约束的损失函数,利用该损失函数与交叉熵损失函数的线性组合来训练整个网络模型.
2.1 网络模型结构
特征概率图约束全卷积网络共有27个卷积层模块,每一个卷积层模块分为卷积层、批归一化层和激活层.为了在更大感受范围提取图像的特征,前面的2个卷积层模块采用5×5大小的卷积核,对输入图像提取其特征.出于时间与提高分割精度的考虑,后续层则采用较小的卷积核.在后续层中,首先是2个卷积核大小3×3×128的卷积层模块,其次是1个卷积核大小为1×1×64的卷积层模块.该模块一方面通过前面一层特征的不同尺度的加权组合,来得到新的特征;另一方面减少卷积核的通道数.接着是21个3×3×64大小的卷积层模块,最后采用一个卷积核大小为1×1×2的卷积层.整个网络最终得到两张特征图:前景概率图和背景概率图.用前景概率图减去背景概率图,并通过赫维赛德函数作用得到分割结果.FPM-FCN网络结构如图1所示.
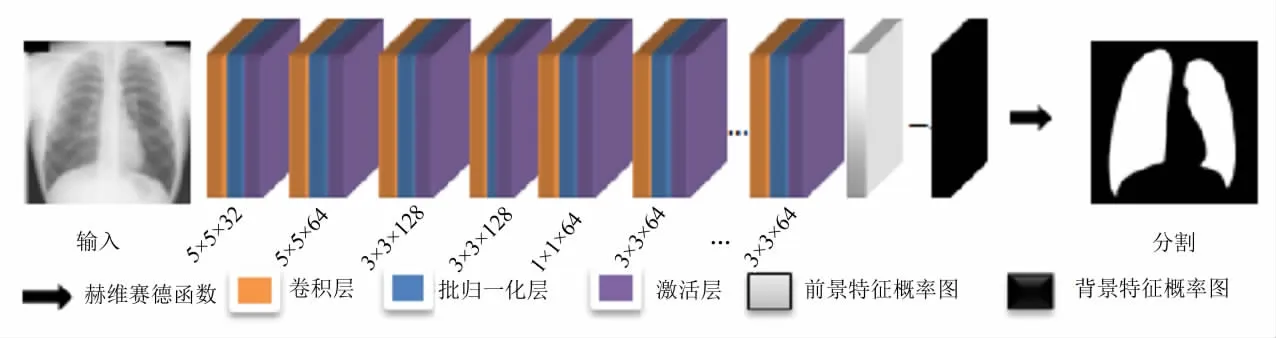
图1 FPM-FCN结构图Fig.1 The architecture of FPM-FCN model
2.2 特征概率图约束损失
卷积神经网络通过不断优化分割与真实标签的近似程度来达到训练目的.L2损失函数是卷积神经网络中常见的损失函数:

其中:X为分割结果,G为图像的真实标签.
本研究利用FPM-FCN网络最终获得的两张特征概率图来定义分割结果,并与真实标签对比,由此定义特征概率图约束损失函数:
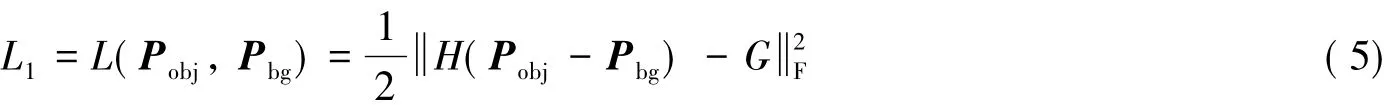
其中:Pobj属于前景的特征概率图;Pbg属于背景的特征概率图;G为图像的真实标签,标签中0表示背景,1表示前景;·F表示Frobenius范数;H表示正则化的赫维赛德函数,其公式如下:

这里,ε是赫维赛德函数的参数.
下面对特征概率图损失函数的作用进行分析.详见图2所示.图2(a)表示背景特征概率图获得的图像,其中白色表示背景,黑色表示前景.图2(b)表示前景概率图获得的图像,图2(c)表示H(Pobj-Pbg)获得的图像,图2(d)表示真实结果.在图2(b)~(d)中白色表示前景,黑色表示背景.通过图2可以发现,图像中可能错分的区域(图2(a)中红色部分)和边缘区域(图2(d)中红色部分)的分割效果得到了改善.
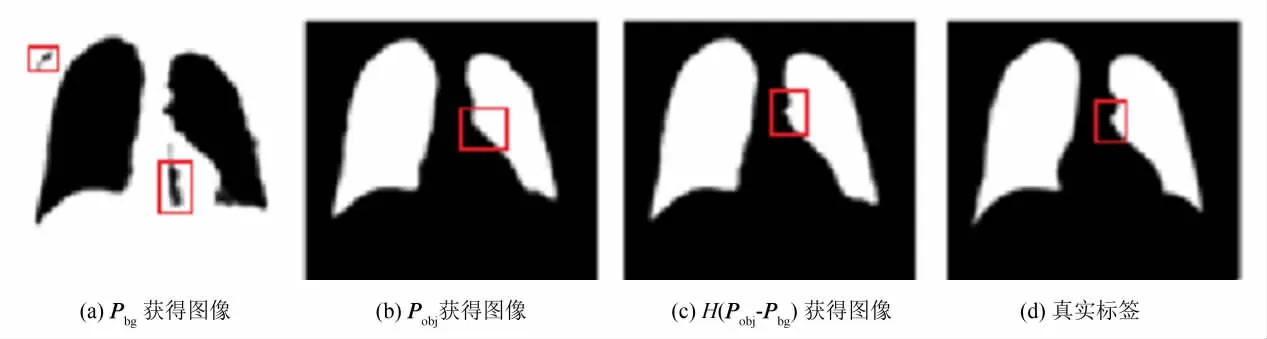
图2 FPM-FCN生成的图像Fig.2 FPM-FCN model generated images
卷积神经网络更新参数时采用反向传播算法,通过ADAM算法更新权重.更新过程中需要用到损失函数关于特征图偏导的信息.计算公式如下:
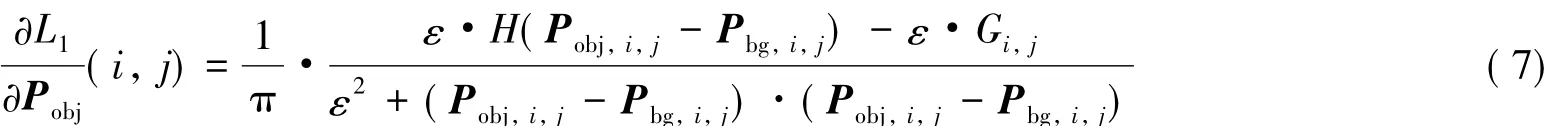
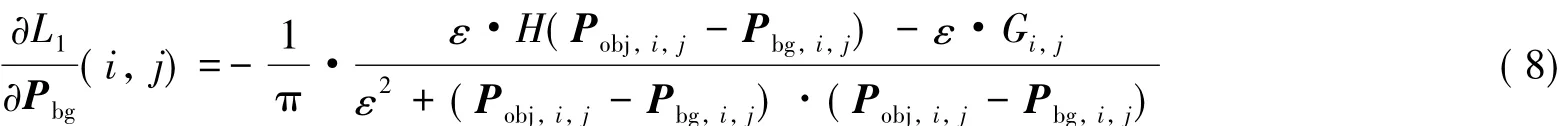
其中:Pobj,i,j表示前景概率图的第 i行,j列像素;Pbg,i,j表示背景概率图的第 i行,j列像素.
为了更精确地度量分割结果与真实标签之间的近似程度,本研究通过特征概率图约束损失函数与交叉熵损失函数的加权线性组合来训练整个模型.交叉熵损失函数可以用来衡量样本数据的真实分布与预测分布之间的距离.二分类问题的交叉熵损失函数公式如下:
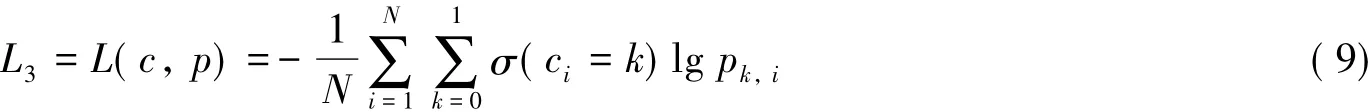
其中:N表示图像像素数目;pk,i表示第i个像素属于第k类的概率.σ(x)为指示函数,即当x取值为真时其值取1,x取值为假时取0.ci表示像素i真实的类别.
在训练集大小为M的数据集上,特征概率图约束损失函数与交叉熵损失函数加权线性组合构成新的损失函数为:
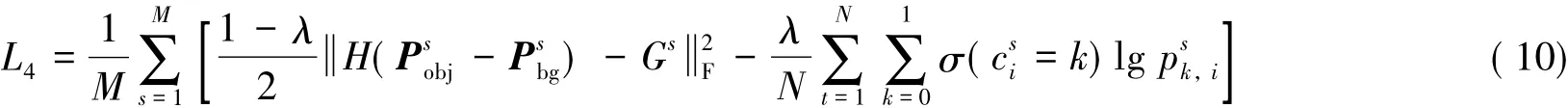
其中:λ∈[0,1].当λ=1时,即交叉熵损失函数;当λ=0时,即特征概率图约束的损失函数.像素点属于前景的概率或背景的概率越高,两张特征概率图的差距就越大,损失函数就越小.当数据集存在严重的类别不平衡时,λ需要取较大的值,比如0.9.
3 实验结果
3.1 参数设置与评估方法
本研究采用U-Net所采用的初始化方式,采用ADAM算法,epochs=70,前面20epochs学习速率取0.01,后50epochs学习速率取 0.001,ε=0.01,肺数据的 batch size为2,手势数据集的 batch size为10.对于肺图像数据集,λ取0;对于手势数据集,λ取0.9.为了使得图像更加平滑,在测试阶段加入了高斯平滑,高斯滤波的窗口为5,方差为3.实验环境如下:Windows7系统,i7处理器,8 G内存,Matlab2015b,采用matconvnet实现.对比实验在ubuntu14.04系统,于caffe和Matlab2014b上实现.
为了评价分割结果的好坏,本研究引入像素精度及Dice系数作为评价指标,与其他三种模型的评估指标对比结果如表1所示.
像素精度(pixel accuracy):被准确分类的像素点个数占所有像素点比例


表1 四种模型在肺数据集及手势数据集上的评估指标结果Tab.1 The four model’s evaluation of results on lung data sets and gesture data sets (%)
3.2 JSNR 肺分割
采用日本JSNR肺数据,该数据集共有247张X-ray肺图像,选取前173张肺图像作为训练样本,后面74张肺图像作为测试集.即70%的数据作为训练集,30%的数据作为测试集.每张图像的分辨率为256 px×256 px,本研究不采用数据集增强手段且没有采用图像块训练网络模型.为了验证特征概率图损失的有效性,公式(10)中λ取0,训练时间20 h左右,每张图像的平均测试时间1.8 s.
四种方法在肺数据集上的分割结果见图3所示.图3(a)为输入图像,对输入图像都做相同归一化处理,减均值处理.其中SegNet、U-Net使用作者提供的网络结构代码,FCN使用本研究提出的网络结构,优化目标是交叉熵损失.本研究模型实验采用特征概率图约束损失训练整个网络.图3(b)使用U-Net方法,在该数据集上容易出现将锁骨部分误判为肺,图3(c)为使用SegNet方法,在肺数据集上分割结果较好,但与采用本研究方法的图3(e)比较发现,本研究方法可以减少部分错分块,并在图像目标边界部分变现更佳.在肺数据集上用红色边框标注减少的孤立像素块的区域.本研究方法减少了部分错分像素块,提高了像素精度.
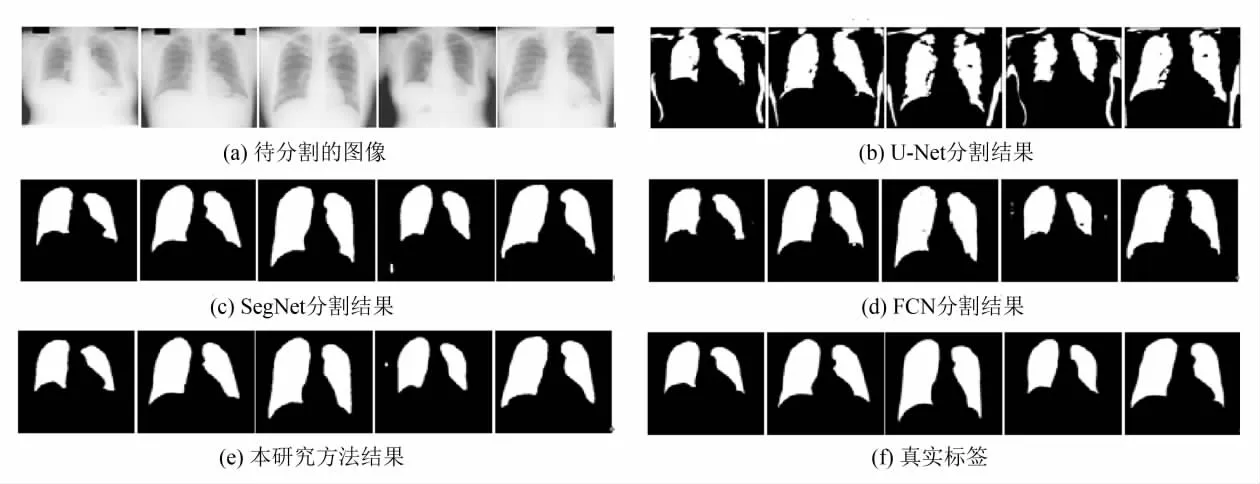
图3 四种方法在肺数据集上的分割结果Fig.3 Results of the four methods on lung data
3.3 手势分割
手势数据集:训练集包含810张71 px×71 px大小的手势图像,测试集包含90张手势图像.使用公式(10)定义的损失函数作为优化目标,由于手势数据集存在较大的类别不平衡问题,λ需要取较大的值,本研究λ取0.9.对比实验中的U-Net、SegNet方法,需要对手势数据集中每一张图像扩充一行一列,扩充图像的第一行与原始图像的第一行一致,扩充后的图像的第一列和原始图像第一列一致,图像大小将变成72 px×72 px.将扩充的一列一行去除.手势数据训练的时间为18 h左右,在每张手势图像的平均测试时间0.15 s.
四种方法在手势数据集上的分割结果见图4所示.图4(a)为输入图像,对输入图像都做相同归一化处理,减均值处理.其中SegNet,U-Net使用作者提供的网络结构代码,FCN使用本研究提出的网络结构,优化目标是交叉熵损失.对比图4(a)~(b)可以发现,U-Net方法容易将部分区域错误分割;由SegNet分割结果可知,图4(c)的第四个图片中手边界部分分割效果较差;由图4(e)的第四个图片反映出,本研究方法在某些边界也有分割不够好的地方,但总体比其它三种方法好.
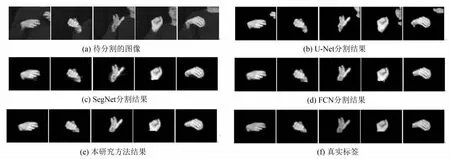
图4 四种方法在手势数据集上的分割结果Fig.4 Results of the four methodson hand dataset.
4 总结
本研究提出特征概率图约束的全卷积神经网络,引入特征概率约束损失,将常用的L2损失函数的网络模型末端的一张特征图扩张到具有两张特征图的网络模型上.其中一张特征图代表前景概率图,另一张特征图代表背景概率图.在此基础上定义基于特征概率图约束的损失函数,并与交叉熵损失联合训练整个模型.以日本JSNR肺数据集和一个手势数据集验证了该模型的有效性,实验表明,本研究模型可以缓解全卷积网络容易出现的部分错误分类的像素点与错误分类的像素块问题,提高分割精度.
