基于核空间加权稀疏表示的滚动轴承故障诊断
2019-07-05吕卫民
钱 猛,吕卫民
(海军航空大学 岸防兵学院, 山东 烟台 264001)
滚动轴承是汽车传动系统,风力发电机组,航空发动机,机床等电机和旋转机械的关键部件。这些装置通常在高速,重载,高低温和污染的恶劣的工作条件下工作,希望执行在线状态监测以提高其可用性,安全性和可靠性,降低运行和维护成本,并实现停机时间最小化和生产力最大化。 由于这些设备中的许多故障可能从滚动轴承故障开始,因此有效的故障诊断可以防止灾难性事故。
目前主要有两类故障诊断模型:基于故障物理模型和数据驱动模型。基于故障物理的故障诊断方法试图解构轴承的机制来确定故障类型。 由于复杂的故障诱因,故障模式可能是强非线性甚至混沌的。在这种情况下,很难建立基于物理的故障诊断模型。与基于物理的模型不同,数据驱动的方法仅依赖于监测数据和构建模型来反映历史数据与故障类型之间的关系。由于传感器的发展,可以实现大量的测量数据。使用这些数据,数据驱动的模型可以提取反映受监控组件运行状态的信息。与基于物理的模型相比,数据驱动的方法对故障机制或操作条件的依赖性较小,因此在没有专业知识的情况下构建它们会更简单但更普遍。
主成分分析[1]和Fisher线性判别方法作为数据驱动方法首先被引入故障诊断。然而,这两种方法都是线性方法,强烈的非线性故障增长机制使得在轴承诊断中表现不佳。人们进而提出了一些非线性方法,如人工神经网络(ANN)[2]和隐马尔可夫模型(HMM)[3]。然而,这些方法需要大量具有各种故障类型的历史数据来训练这些模型,这在航空航天等一些关键领域中并不实用。不同于传统诊断方法,稀疏表示(SR)[4]具有良好的适应性和高度的灵活性,能够在冗余和过完备的字典上基于原子分解描述任意复杂信号,因此不受正交基限制,并且提供了一种有效的特征提取方法。SR理论为我们提供了一种新的特征提取模式,并在机器学习,统计学,图像处理等许多应用领域得到了广泛的研究。稀疏表示理论具有强大的自适应提取特征能力,为解决初期轴承故障诊断问题提供了一条有效途径。
传统的SRC模型忽略了测试样本和每个字典原子之间的距离相似性。和训练样本更近或者更相似的训练样本在表示测试样本时起到更重要的作用。为了提高原始SRC模型的判别能力,卢灿义通过将样本的局部结构信息集成到一个统一的公式中,扩展了原始的SRC模型,并提出了加权稀疏表示(WSRC)模型[5]。WSRC自适应地利用测试样本和每个字典原子之间的相似性来表示测试样本。但是轴承振动信号中包含大量的非线性振动信号,这给SRC和WSRC带来了不小的挑战。相关文献表明基于核技巧的算法能够有效地解决非线性问题。 支持向量机是最著名的基于内核的方法,它结合了稀疏诱导技术和内核技巧。通过内核技巧,通过将非线性可分离特征映射到高维特征空间,基于内核稀疏表示的分类(KSRC)[6]算法被提了出来。 KSRC克服了SRC不能处理非线性信号的问题,具有更好的分类能力。
本研究在稀疏表示的基础上提出一种新的故障诊断方法,克服了上述故障诊断方法的不足,有效地提高了故障诊断的准确率。作为稀疏分类方法的延伸,基于核空间稀疏分类方法(KSRC)将非线性振动数据映射到高维空间来提高分类准确率,在基于稀疏表示理论的滚动轴承故障诊断应用中起到了显著的作用;然而该方法却忽略了振动信号局部结构所包含更多的区分性信息,本文分提出一种基于核空间的加权稀疏表示轴承故障诊断方法(LMNN-WKSRC)。首先通过核函数将非线性振动信号映射到高维空间;然后通过LMNN方法提取振动数据的局部信息并求得相似度加权矩阵;最后通过优化方法求解测试样本的稀疏系数,并通过最小化原始样本与重构样本之间的误差获得分类结果。通过轴承实验验证了所提算法的有效性。
1 稀疏分类模型和核稀疏分类模型
稀疏表示作为一种信号重构的方法,在人脸识别和检测等应用领域成为研究的热点。设Xi=「Xi,1,Xi,2,…Xi, j…Xi,ni⎤由第i类(共k类)训练样本组成的集合,ni为类内样本总数。其中xi, j∈Rm,m为样本维数。如果第i类训练样本充足,则任意属于第i类且不在训练集中的样本信号可由同类训练样本线性表示,即:
y=αi,1xi,1…+αi, jxi, j…+αi,nixi,ni
(1)
其中:αi, j为线性表示系数;k为训练样本总类别数。可将上述公式可重新表示为y=Xα0,其中α0=「0,…,0,αi,1,αi,2…,0,…0⎤∈Rn,α0的维数为训练样本个数总和,而且α0中只有与第i类训练样本相关的系数是非零的,即在整体训练集X上的稀疏系数是稀疏向量。
对于包含n组基(每组基作为一列)的超完备字典X∈Rm×n(n≫m),给定的信号y可以由这些基的稀疏线性组合所表示:y≈Xα,并且满足||y-Xα||2≤ε。由于X是过完备的,所以满足||y-Xα||2≤ε的解有无数个。因此,可以引入一个约束来获得唯一的解。优化模型可表示为:
(2)
在满足RIP条件下将上述优化模型转化为以下优化模型:
(3)
对于k类问题,将n列m维特征向量构成训练字典X∈Rm×n,用Xk代表字典X的k类nk个列向量。对于给定y∈Rm,可以由上述模型求解最优解α。进而通过下式求得y所属类别:
(4)
其中,αk是对应于类k的α中的分量。稀疏表示模型和判决标准在人脸识别中被称为基于稀疏表示的分类(SRC)[7]。
尽管SRC在轴承故障诊断中取得不错的效果,但SRC无法针对滚动轴承高维非线性信号做出更进一步的识别。KSRC作为SRC的非线性扩展,通过将原始数据映射到内核空间,在滚动轴承故障诊断方面取得了不错的效果。在基于内核的算法中,无需知道具体映射函数,最重要的是将数据映射到高维内核空间的内核技巧。一般情况下,Mercer核K∈Rn×n被用于计算内核矩阵K∈Rn×n和向量k(·,·)∈Rn,如式(5)、式(6)所示
Ki, j=k(xi,xj)
(5)
k(·,y)=[k(x1,y),…,k(xn,y)]T
(6)
xi和xj都代表训练集。对于大量的训练样本,核空间较高的维度会增大计算的复杂度。因此,一般用KPCA或KLDA来降低KSRC中的维数,并且获得变换矩阵B∈Rn×d,其中d是减小了的特征空间的维数。系数向量可以在低维核特征空间中计算,如式(7)所示
(7)

(8)
2 基于核空间加权稀疏表示的信号分类
在故障诊断中,一个好的分类方法应该具有鲁棒性并且能够从振动信号中获得较多的区分性信息进行分类。本节提出了稀疏分类算法(SRC)的延伸算法,加权内核稀疏表示分类(LMNN-WKSRC)。该算法利用更多的区分信息来识别测试样本。
2.1 非线性映射
与传统的线性算法相比,在模式识别和机器学习方面对它们进行非线性转换能对显著提高算法的效果。非线性变换中,基于内核的方法由于具有对非线性数据的处理能力而受到广泛的研究。对于训练样本X和任何测试样本y的集合,采用非线性映射函数φ将输入数据映射到核特征空间。由于非线性映射函数φ不容易确定,基于内核技术的方法使用Mercer内核k(·,·)来获得高维内核特征空间中的映射数据。对于任何样本z1和z2,具体可以表示如下
k(z1,z2)=φ(z1)Tφ(z2)
(9)
线性核和高斯径向基函数和是用的最多的两种Mercer内核方法。 线性核是非参数核,而高斯径向基函数(RBF)具有可以调整核矩阵的参数
(10)

(11)
核特征空间较高的维度使得计算稀疏系数变得困难,因此通过降维方法来提高计算效率。在WKSRC中,可以使用KPCA来降低核心特征空间的维度。在KPCA中,如果设定降维后的特征空间维数为d,则变换矩阵B可以表示为B=[β1,…βj…βd]∈Rn×d;对于j=1,…,d,每个向量βj是对应于非零特征值的标准特征向量,通常选择前d个最大特征值。通过变换矩阵B,上述问题可以表示如下
s.t.BTk(·,y)=BTKα
(12)
因此在原始特征空间中线性不可分的问题得以解决,样本在高维特征空间中变得线性可分。在核特征空间中,使用降维方法来减小维度。与映射函数一样,在线性降维方法中也可以用核技巧来获得非线性数据。 核特征空间的非线性特征得以保留并用于解决分类问题。
2.2 局部结构信息
传统的加权稀疏分类方法已经应用于人脸识别和在轴承故障诊断中,相比传统的稀疏分类算法拥有更高的分类准确率。对于某些非线性信号,基于欧几里得距离的加权稀疏分类方法往往不能获得较好的分类效果
(16)
(17)
使用欧几里得度量计算距离时,组间的距离会小于组内距离。利用最大间隔最小邻居(LMNN)可以克服上述不足。
大间隔最近邻[7](Large margin nearest neighbor)分类算法是统计学的一种机器学习算法。该距离度量方法充分利用先验知识来从标记的样本中学习马哈拉诺比斯距离度量。通过训练使得k最近邻归属于同一类,而来自不同类的样本以较大的余量分开。输入空间的这种全局线性变换确保了同一类中的较小距离和不同类之间的较大距离。LMNN最初旨在提高K最近邻(KNN)分类性能。从字面上理解,同一种类的输入训练集应该足够接近;其次,不同种类的输入训练样本应该足够地分开。
基于上述理解,LMNN的损失函数由两个项组成,一个用于将目标邻居拉近,另一个用于将不同类别的样本距离更远。惩罚每个输入与其最近邻之间较大距离的项定义如下
(13)
惩罚不同类别样本之间的距离的项被定义为
(14)
这里的yil=1,当且仅当yi=yl,yil=0;否则,xl表示来自xi的不同类别样本。最后,结合上述两项并定义一个损失函数如下,其中μ∈[0,1]是平衡上述两项的权重参数
ε(L)=(1-μ)εpull(L)+ηεpush(L)
(15)
该种距离度量充分利用先验知识使得k近邻总是归属于同一类,而来自不同类别的样本被大间隔分隔。输入空间的这种全局线性变换确保了同一类中的较小距离以及不同类之间的较大距离。在本文中块对角矩阵可以定义如下:
diag(W)=[dist(y,x1),…,dist(y,xn)]T
(18)
用马氏距离来计算两个向量之间的距离
(19)
其中M=LTL由LMNN得到。如果测试样本y与训练样本xi之间的大距离Wi表明它们不太可能属于同一类别,并且相应的αi往往很小,这也表明xi不能较好地表示y。在使用欧几里得度量时,由于表示全局距离并且对噪声敏感,所以如果y和xi实际上属于不同的类别时y和xi之间的距离很小,则相应的αi往往很大,这会导致稀疏表示不准确。通过学习方法来测量距离。具体而言,训练集包括相同类别样本中的噪声变化。在训练词组中,线性变换矩阵L可以学习这些模式。通过这种投影,输出空间对不相关的噪音不敏感。因此,LMNN距离度量更可能呈现两个信号之间的正确距离。
2.3 基于核空间稀疏表示的信号分类模型
本节提出的LMNN-WKSRC将局部适配矩阵应用于核函数空间中的L1最小化问题,得到了核函数空间中的加权L1最小化问题。求解系数向量的问题可以被表述为以下加权L1最小化问题:
(20)
(21)

(22)
其中k(X,y)=[k(x1,y),…k(xn,y)]T∈Rn×1表示核空间内的核向量;K∈Rn×n表示相对应的核度量矩阵,其中Ki, j=k(xi,xj)。||Wα||1代指加权L1正则化项;dist(y,xi)表示每个原子与测试样本之间的距离或相似度;λ控制表示误差项||φ(y)-φ(X)α||2和加权正则化项间的权重。通过式(22)得到系数向量之后。将计算c类训练样本的重建误差来确定测试样本的标签。与SRC和KSRC类似,除了与测试样本所属类别相关的部分外,系数向量将是稀疏的,大多数α的项为零
ri=||〗BTk(X,y)-BTKα||2
(23)
(24)
算法流程如表1所示。

表1 算法流程
3 验证
本研究在轴承振动信号数据库和航空发动机振动信号上对所提出的算法进行实验验证,实验结果证明了该分类算法的有效性。为了充分验证所提出的算法的分类效果,将WKSRC与3个现有的算法SRC,WSRC和KSRC在数据库上进行比较。在KSRC和WKSRC中,需要将原始样本映射进入高维内核空间。使用线性核作为非参数内核来获取内核特征空间。然后,使用KPCA来减小特征维度降低系数向量的计算复杂度。在所有实验中,使用SPAMS(SPAMS是用于解决涉及稀疏的机器学习和信号处理问题正则化的开源工具箱)软件包来解决内核特征空间中的加权L1最小化问题。稀疏求解的系数λ的值取5,以保证非零系数不超过20个(共100组数据)。
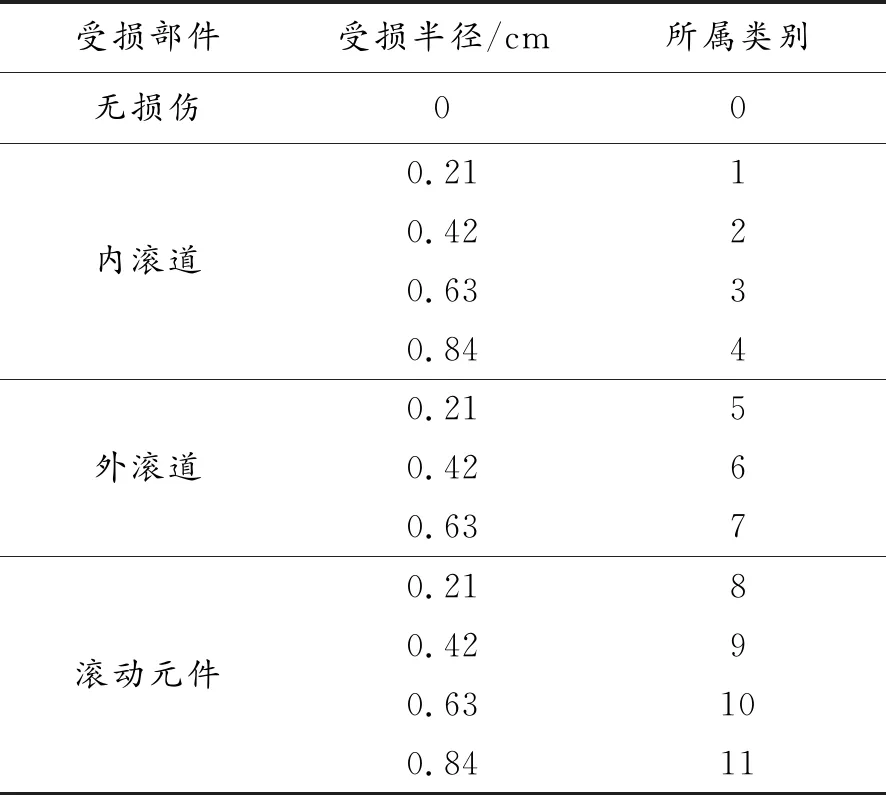
采用西储大学公开的轴承数据进行实验验证。表2所示为轴承故障类别。从图1所示的振动幅值图可以看出:即便注入损伤大小各异,但振动信号的振动模态却相差无几,比如0.84 cm的内滚道损伤与0.42 cm的外滚道损伤的振动模态极为相近,这给准确区分出故障类型增加了难度。对于上述每一种故障类型,从原始振动信号中采集并构造100组数据,每一组数据的维数均为2 048。将全部的1 200个样本构造成一个2 048行1 200列的矩阵D,矩阵中的每一列都代一种故障
D=[D0,D1,…,D11] (25)
由于信号中不可避免存在噪声干扰,因此第一步对数据进行中值滤波。提出矩阵每一列的多尺度熵和傅里叶系数作为特征来进行分类。接下来则对特征归一化以防止某几维数值过大或过小而影响分类准确率;本文采用通常的归一化方法:
(26)
其中fij是第j个样本特征向量的第i个特征值,归一化之后的特征值区间为[ymin,ymax]。在特征归一化过程中,采用与特征选择相同的反馈机制确定归一化的区间。相关实验表明当归一化区间为[-1,1]时,后续的故障诊断准确率最高。
每一组实验均从100组样本中随机选出P组样本作为训练样本,剩余样本作为测试样本。降维后的信号维数d分别取1 000和1 100。为了验证本文算法的有效性。本文将所提出的算法与常见的稀疏分类算法进行识别率的对比;加权稀疏分类算法和核稀疏分类算法是本文算法在分类精度相对较高的两种算法,本文同样进行实验对照;SVM是常用的分类算法,多数用于小子样的分类。将上述实验数据输入到相应的算法中得到识别率折线图2。

图2 不同分类方法的故障识别率对比
4 结论
1) 本研究所提出的模型具有较高的故障识别率;当d=1 000时,平均识别率比单独的稀疏分类算法高出将近9个百分点,比常用的支持向量机高出3个百分点;当d=1 100时,平均识别率比单独的稀疏分类算法高出将近9.8个百分点,比常用的支持向量机高出3.8个百分点。
2) 振动信号的局部结构信号对振动信号故障分类有着重要的意义。由于WSRC将振动数据的局部结构信息与SRC结合起来,取得了比SRC更好地分类效果。
3) 核技巧根据轴承振动信号强烈非线性的特点将数据映射到高维核空间,提高了故障识别率。
4) 当对振动信号进行编码时,在一个过完备字典上,对于相似振动信号SRC或KSRC会选择相当一部分相同的基;而选择LMNN方法作为信号之间的度量能够更加准确地计算两列信号信号之间的距离,从而获得更高的故障识别率。
