一种改进遗传算法优化SVM的入侵检测方法
2019-07-05侯春雨王戈文王崇峻
侯春雨,王戈文,王崇峻
(1.广州民航职业技术学院航空港管理学院, 广州 510403; 2.长沙市化工研究所, 长沙 410007; 3.航天工程大学, 北京 101400)
随着信息技术发展和普及,网络信息安全变得日益重要。相比传统网络防御技术,网络入侵检测系统(NIDS)可主动拦截警报数据[1],实用价值凸显。因此,如何提高入侵检测系统效率成为当前网络安全领域研究热点。现有NIDS受到未知攻击时检测率较低,且在处理警报数据时开销较大,因此相关研究人员将机器学习如支持向量机(SVM)、模糊逻辑、人工神经网络、人工免疫系统(AIM)等方法应用于NIDS中。SVM是一种基于统计学习的机器学习算法,在解决模式识别和语音识别等问题时性能较为优越[2],相比其他机器学习算法,它能够较好地解决小样本、非线性和高维问题,因此常用于识别网络中恶意流量。
大数据环境下SVM处理入侵检测数据时碰到了新问题,随着网络数据特征维度增加,NIDS训练时间增加,分类准确率随之下降,限制了SVM在NIDS中的应用。因此,特征选择、特征权重及SVM参数的合理设置对提高入侵检测效率至关重要。遗传算法利用染色体间信息交换和种群搜索策略展现的较佳全局优化能力来避免局部最优解。为了解决上述问题,本文采用遗传算子优化支持向量机方法寻优特征子集,并同时优化SVM参数和特征权重,将其用于提高NIDS分类性能。
文献[3]通过遗传算法优化SVM的核参数γ,利用启发式方法动态调整遗传算子,将分类准确率作为适应度函数,完成基于高斯核函数的SVM参数优化,但却未考虑特征权值对SVM分类准确率的影响。文献[4]提出了一种基于主成分分析(PCA)与粒子群优化SVM的入侵检测方法(PCA-SVM),利用PCA对网络入侵数据进行数据降维和特征提取,但是PCA可能会得到对分类无作用的特征,且可能丢失一些有用的数据或特征。文献[5]提出了一种基于融合FAST与自适应二进制量子引力搜索优化SVM(ABQGSA-SVM)的入侵检测方法,利用FAST算法过滤掉冗余数据特征以生成特征子集,基于组合优化的量子引力搜索算法对SVM参数和特征子集进行寻优,但该方法收敛速度较慢,不能快速高效找到优化特征子集和SVM参数。近些年,基于SVM的网络入侵检测方法存在众多问题:传统特征选择方法容易忽略许多重要特征,选出的特征子集得到的分类准确率会随之降低;传统遗传方法优化SVM用于NIDS中,无法充分搜索特征子集空间,搜到的特征子集具备较高错误率,选出的最优特征子集各项特征重要程度未充分体现,无法找到SVM模型最优参数。
根据上述问题,本文提出了一种改进的遗传算法优化SVM的入侵检测方法。首先,对遗传算子的交叉和变异过程进行优化,有利于提高群落早期演化速度,然后,在寻优特征子集阶段,提出一种基于数据维度、分类准确率和误报率优化配置的适应度函数,最后,同时优化SVM的特征权值及相关参数,以增强SVM的分类性能。
1 遗传算法和梯度下降法
遗传算法是一种通过模拟自然进化过程搜索优化解的方法,主要包括3个部分:选择操作、交叉操作和变异操作[6]。其中,选择操作主要是选取较优的母代染色体进行交叉操作和变异操作,以增加群落的多样性并避免群落陷入局部最优解[7],常见的选择法方法有轮盘赌选择、精英选择和锦标赛选择。当前遗传算子中种群演化期间的交叉概率和变异概率都是常数,会影响群落后期演化的收敛性,致使SVM训练时间增加。为了使染色体在群落演化过程中加速搜索,促使遗传算法尽快找到优化解,本文根据群落演化的不同阶段确定交叉概率和变异概率,并引入梯度下降方法增加算法的搜索方式,从而加速找到全局优化解。
1.1 交叉操作
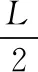

图1 遗传算法中交叉操作
根据群落的特性,刚开始群落种类更加随机和多样,到了后期群落逐渐收敛,群落相似度增加,故交叉操作在前期作用大于后期作用。所以随着迭代次数增加,每次迭代的交叉操作染色体个数和交叉概率应该随之减少,这样有利于减少计算成本。每次迭代进行交叉操作染色体的个数Pi如式(1),交叉概率更新如式(2):
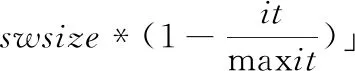
(1)
其中,swsize表示所有染色体个数,it表示迭代次数,maxit表示最大迭代次数。
(2)
其中,prmax是最大交叉概率,prmin是最小交叉概率。
1.2 变异操作
群落中母代染色体某部分基因发生改变,即变异操作,如图2所示。种群演化初期,主要通过交叉操作寻找优化解,设置较低变异概率有利于降低计算成本;种群演化后期,执行交叉操作的染色体数减少,提高变异概率有利于增加群落多样性,提高寻找到最优解的概率,因此本文变异概率公式如式(3)。染色体中第d维基因的选择概率如式(4)。
(3)
(4)
其中,gbestd表示全局最优染色体第d维基因,θ表示选择阈值。生成范围在[0,1]的随机数r,若r>CProbabilityd,执行相应的变异操作,如式(5),否则将新染色体第d维基因childd赋值为gbestd。
(5)
其中,若gbestd的值小于或等于选择阈值θ,则将childd的值映射到[θ,1]范围的实数,否则将childd的值映射到(0,θ]范围的实数,有利于改变特征的选择属性。
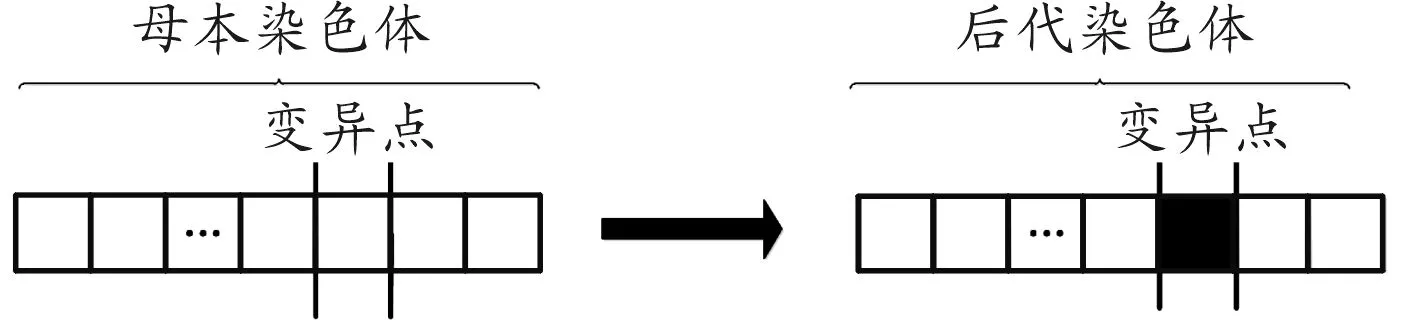
图2 遗传算法中变异操作
1.3 梯度下降法
梯度下降算法是目前较为流行的优化算法,收敛速度较快,经常与各种算法联合使用。梯度下降法分为批量梯度下降法、随机梯度下降法、小批量梯度下降法,其关键思想是某质点沿适应度函数梯度下降尽快滑落到函数极值点,主要包含两个内容:搜索方向,如式(6)计算出最优搜索方向[8];搜索步长,如式(7)计算搜索步长。
gtm=负梯度=
(6)
(7)
其中,sec代表梯度下降法最多探索次数。基于梯度下降法有利于增加遗传算法群落多样性,其算法如下:

算法:本文梯度下降算法输入:设置误差ε>0,迭代次数变量m,最多探索次数sec;输出:全局优化解gbest;Step1:如式(6)计算最优搜索方向,判断搜索是否满足迭代次数m≤sec或gtmmaxxi≤ε,若是则跳到Step2,否则跳到Step3;Step2:如式(7)计算最优步长,并如式(8)更新群落全局最优值,并跳到Step1;gbestm+1=gbestm+λmgtm(8)Step3:输出全局优化解gbest。
2 改进的遗传算法优化支持向量机的入侵检测方法
本文将改进的遗传算法优化SVM用于NIDS中,需要解决两个主要问题:如何对特征的重要程度进行排序;如何选择最优SVM内核参数。这两个问题必须同时解决,因为权重特征会影响SVM的内核参数,反之亦然。本文提出改进的遗传算法优化SVM体系结构如图3所示,主要分为3部分:特征选择、入侵检测和停止准则,目的是寻找最优特征子集,优化SVM参数和各项特征权重。

图3 改进的遗传算法优化SVM体系结构
1) 特征选择[9]:将KDD CUP99作为初始数据集,利用基于改进遗传算法的特征选择算法寻找候选特征子集。其中,特征子集包括特征的权重W1~Wn(特征W=0表示未选特征)以及SVM参数C和γ,如图4所示。

图4 特征子集结构
2) 基于SVM的入侵检测[10]:在初始数据集中,将特征子集中的特征权重对应相乘每条数据的特征值得到入侵检测输入数据,并将特征子集中SVM参数C和γ用于构建SVM模型,经过入侵检测识别后,求解出相应适应度值。其中,各项特征权重是通过随机方式生成的范围[0,1]的实数。
3) 停止准则:将适应度值最大的特征子集作为最优特征子集,并利用最优特征子集得到特征权重和SVM参数。
本文中改进的遗传算法优化SVM具体算法如下:

算法:改进遗传算法优化SVM在入侵检测中应用算法输入:KDD CUP99 样本训练集和测试集,随机初始化的母本群体swarm,群落最优gbest,SVM参数C和γ,交叉概率pcrprobability,变异概率pmuprobability,最大迭代次数maxit,其中,swarm包含10对母本染色体,每条染色体包含一组入侵检测中特征权重和支持向量机参数C和γ的编码,染色体中每个基因取值均在实数范围[0,1]中。输出:最优特征子集,各项特征权重,SVM参数C和γ;Step1:求解swarm的适应度fswarm,初始化gbest为swarm中最优适应度染色体,并求其适应度fgbest;Step2:判断是否满足最大迭代次数maxit或最大适应度值,满足则跳到Step7,否则跳Step3;Step3:评估每条染色体适应度值,并如式(2)、(3)更新交叉概率pcrprobability、变异概率pmuprobability;Step4:根据3.1节对群体进行交叉操作,更新群体最优值gbest及其适应度;Step5:根据3.2节对群体进行变异操作,更新群体最优值gbest及其适应度;Step6:若全局最优值gbest连续3次迭代不发生变化,根据3.2节梯度下降法产生新染色体,然后跳到Step2;Step7:将全局优化染色体gbest当作最优特征子集,并得到相关权重和参数。
算法中适应度函数是本文算法的一个基本组成部分,用来评估染色体的优劣程度,本文适应度函数设计如式(9):
(9)
其中,Acc表示分类准确率;fsn表示特征子集的特征维数;Afs表示总特征数量;far表示误报率;(1-a-b)表示准确率的权重参数,其权重应该大于其他权重;a表示特征维数占总维数比例的权重参数,其权重应该仅次于准确率的权重;b表示误报率的权重参数。
3 NIDS实验结果与分析
3.1 实验环境与数据集
本文实验环境基于Windows 8系统,Matlab2014b软件。改进的遗传算法优化SVM方法参数设置如表1所示。实验样本数据集取自KDD CUP 99 数据集[11],如表2所示,实验样本数据集的41维特征[12]如表3所示。

表1 改进遗传算法优化SVM方法参数设置
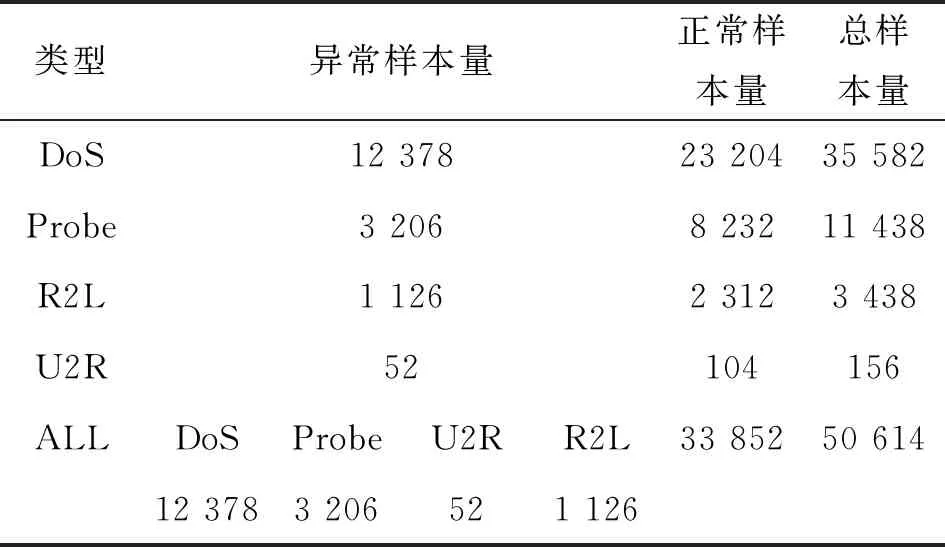
表2 KDD CUP 99样本数据集组成

表3 KDD CUP 99连接记录41维特征
3.2 实验结果与分析
本文实验数据集主要是检测样本数据集和特征选择数据集。检测样本数据集组成如表2所示。为了缩短寻优特征子集的时间,从表2的DOS、Probe、R2L和U2R数据集中分别随机抽取50%、80%、100%和100%的数据作为各自特征选择数据集,并将上述特征选择数据集合并作为ALL的特征选择数据集。
特征选择前需要预处理检测样本数据集和特征选择数据集,预处理主要分为字符特征数值化和数据归一化过程。本文从适应度、特征维数、分类准确率及检测时间四个方面,对比了PCA-SVM[4]和ABQGSA-SVM[5]方法,得到相关实验结果如图5,表4~表6。
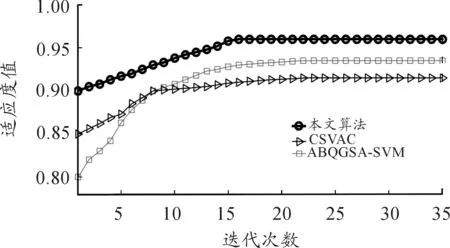
图5 3种特征选择算法得到的适应度对比
从图5可知,通过比较3种特征选择算法得到的适应度曲线可以发现:本文算法收敛速度快于其他算法,且本文算法在第17次迭代时适应度趋于稳定,CSVAC和ABQGSA-SVM在第23次迭代时适应度才稳定,说明本文算法稳定后得到的适应度高于其他特征选择算法。因此,本文算法寻优到的SVM模型优于其他算法。
在特征选择数据集上比较3种特征算法得到特征子集的特征选择维数,如表4。其中,特征维数序号和表3相对应。

表4 3种算法得到的特征维数
从表4可知:通过比较3种算法得到平均特征选择维数发现:本文方法比其他算法少至少20%的特征,3种方法得到的平均特征选择维数从少到多排序为本文算法、ABQGSA-SVM、CSVAC。
在表2样本数据集上比较所有特征情况下和上述3种特征选择算法后得到最优特征子集的分类准确率和检测时间,得到实验结果如表5和表6。
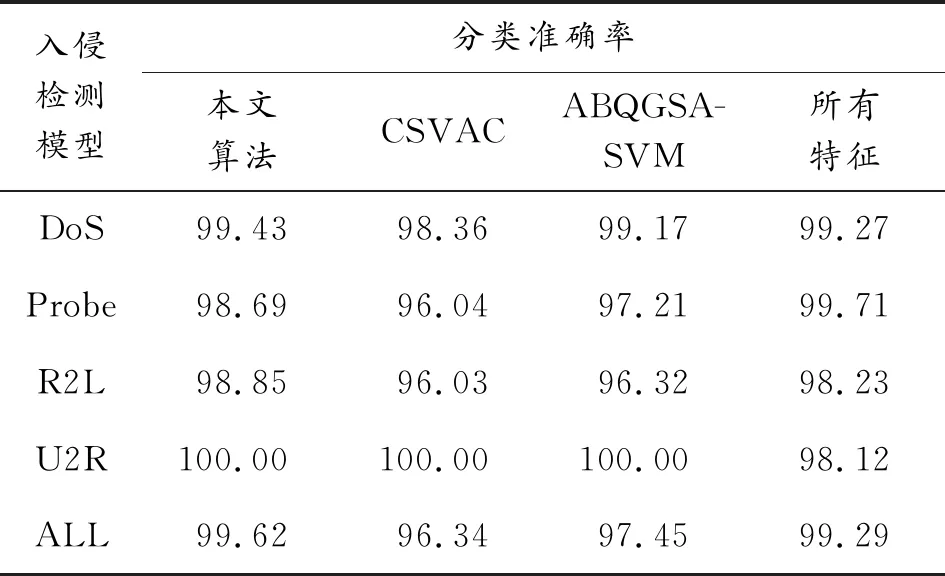
表5 3种算法得到的分类准确率
从表5可以得到,通过比较3种算法得到最优特征子集的平均分类准确率发现:本文方法比其他方法提高了至少2%的分类准确率;比所有特征情况提高了约0.5%的分类准确率。
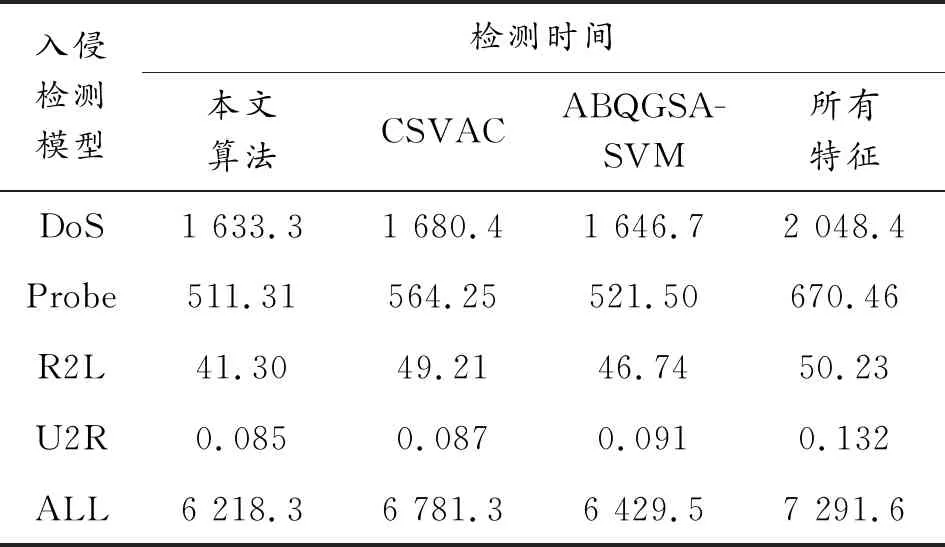
表6 3种算法得到的检测时间
从表6可以得到,通过比较3种算法得到最优特征子集的检测时间发现:本文方法比其他方法缩短了至少10%的检测时间;比所有特征情况缩短了约20%的检测时间。
综上所述,本文算法寻优到的特征子集所构建入侵检测模型相比ABQGSA-SVM和CSVAC算法,有效降低了入侵检测中恶意流量的特征维度,提高了入侵检测的分类准确率,缩短了检测时间,因此本文算法所构建的入侵检测模型具备更优的性能。
4 结论
针对入侵检测中高维特征问题,本文提出了一种改进遗传算法优化SVM方法。首先,利用梯度下降算法对遗传算法进行改进,并设计了自适应变化的交叉和变异概率;设计了基于分类准确率、数据特征维度和误报率优化配置的适应度函数;输出网络流量特征权重、支持向量机核参数γ和惩罚因子C。由于遗传算法的初始值对后期寻优效果有较大影响,下一步将研究如何产生合适的遗传算法初始值,寻找到更优的特征子集,提高SVM的分类性能。
