新一代人工智能技术驱动下的新药研发
2019-07-04蒲小平
吴 昊,林 铭,孙 懿,赵 欣,蒲小平
(北京大学药学院分子与细胞药理学系,北京 100191)
新药研发是一项复杂的工程,具有高风险、高投入、周期长的特点。利用传统方式开发新药的费用已接近25亿美元,而且每9年会增加1倍,不仅如此,传统开发新药的方式漫长而且效率低下,近九成的药物在Ⅰ期临床阶段就会被淘汰[1]。因此,国内外药品公司都积极地将人工智能(artificial intelligence, AI)技术应用于新药研发(Tab 1),以提高研发效率,即能在早期通过计算生物学和生物信息学等手段,筛选除去无活性药物,并形成新的药物开发模式。所以,本文将围绕以“统计学习”为特征的新一代AI技术驱动下的新药研发,探究AI技术对传统新药研发模式的颠覆性改变。
1 AI技术在整合表型筛选中的应用
一般来说,传统新药研发的起点是利用分子生物学结合生物信息学相关数据,分析确定疾病治疗的有效靶点,再围绕靶点逐步寻找活性药物。在开发过程中,一般利用虚拟筛选(virtual screening,VS)、高通量筛选(high throughput screening,HTS)和高内涵筛选(high content screening,HCS)[2]等。其中,确定疾病靶点以及靶点相关基因和蛋白的过程耗时耗力,严重影响新药研发进程。与传统新药研发相比,AI技术具有明显的优势,能利用大数据样本表型筛选的方法,加快复杂疾病新药研发的速度和效率。
1.1 表型筛选及其优势表型筛选是在疾病靶点不明确,而且发病机制不清楚的条件下,基于生物体表型改变来进行药物筛选。相对于传统体内和器官/组织表型筛选,结合了AI技术的现代表型筛选适用于更复杂的病理生理过程,并且能在细胞水平利用表型改变来筛选新的化合物[3]。一般来说,先导化合物筛选过程中,常用到3种类型细胞表型筛选方法,分别是细胞活力测定、细胞信号通路分析和疾病相关表型分析。此外,细胞表型筛选还会用于细胞自噬、凋亡、细胞分泌、细胞运动、细胞核易位、骨架重排等[4]。
AI筛选平台和高敏感检测系统的发展,更推进了表型分析小型化和大型样品库的快速筛选[5]。Berg Health公司Narain等[6]通过将转移性前列腺癌PC-3细胞系暴露于模拟的肿瘤微环境中(氧气不足、低pH和营养不足),分别在培养24、48 h后,吸取15 mL条件培养基进行蛋白质组学分析,再使用AI贝叶斯神经网络推断方法分析蛋白质组数据,生成每个特定因子的独特概率模型,再根据功能变量子网的Burt约束度量得分进行排名,找到潜在的前列腺癌生物标志物Filamin-A和Filamin-B等,并在前列腺癌患者血样中得到验证。
在过去的20年里,药物靶点筛选一直是新药研发的主流,而到近十年,AI技术的崛起,使得基于表型筛选的方法回到人们的视线,又重新成为药物筛选和先导化合物发现的趋势(Fig 1)[5],像白血病治疗的溴结构域抑制剂筛选[7]、丙型肝炎病毒NS5A抑制剂开发[8]等。这一改变主要是因为AI技术在药物研发方面具有的优势,使人们进一步意识到基于靶点筛选方法的缺陷,即对于多数靶点不明确、发病机制多样的复杂疾病,其局限性较大。此外,再利用批准药物的表型筛选方法,还能明显减少潜在药物的临床前开发时间和成本[9]。新药研发的模式也因此从单一的分子靶点筛选向整合表型筛选转变[10]。不过,表型筛选并不能有效确定药物作用机制和靶点,因此不能完全覆盖靶点筛选的功能,这是目前表型筛选未能被药企普遍接受的主要原因。

Fig 1 Development of drug screening methods Black wireframe indicates phenotypic screening
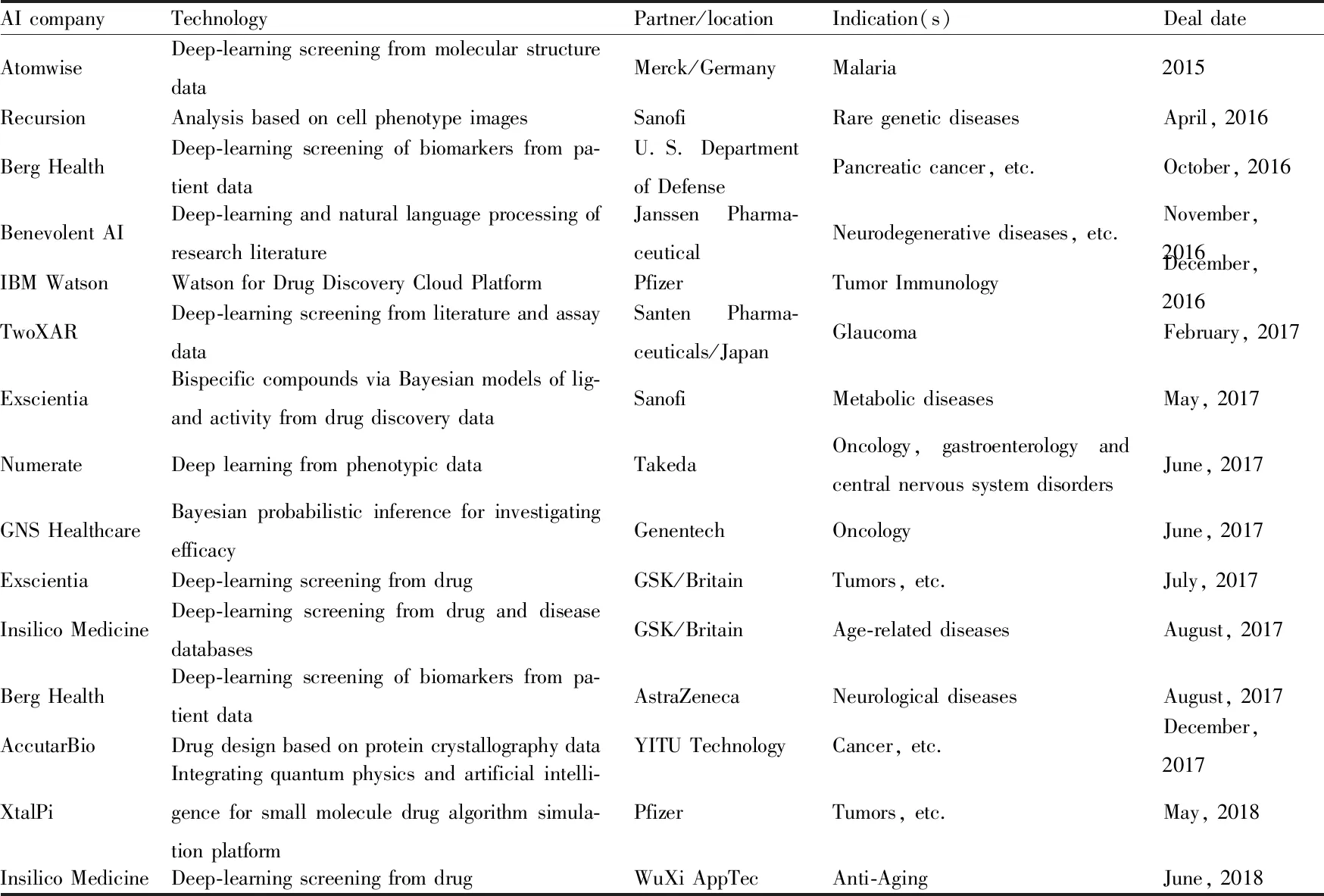
Tab 1 Selected collaborations in AI-drug discovery space
1.2 基于细胞图像组学的表型筛选细胞图像组学是指利用AI技术,将模拟疾病的细胞模型图像进行形态学分析,建立疾病的细胞表型数据库,并确定疾病的指纹特征。而基于细胞图像组学的表型筛选则是将指纹特征和大量化合物测定的生物学活性相结合,构建特征-活性网络,再根据特定化合物的细胞特征信息,来确定其生物学活性并进行筛选[11]。与基于靶点药物筛选缺乏细胞学信息相比,基于细胞表型图像药物筛选可以提供更多的生物学信息,通过相互作用蛋白所处的细胞环境和信号网络相关信息,并能保留高通量筛选能力[12]。美国犹他州Recursion Pharmaceuticals(递归医药)利用HTS经过大量的分析开发后,决定采用6种荧光染料进行染色,包括Hoechst 33342(DNA)、伴刀豆球蛋白A/Alexa Fluor 488结合物(内质网)、SYTO 14绿色荧光核酸染色(核仁,细胞质RNA)、鬼笔环肽/Alexa Fluor 568结合物(肌动蛋白)、小麦胚芽凝集素/Alexa Fluor 555结合物(高尔基体,质膜)和Mito Tracker深红(线粒体),在5个通道成像,并能在单个显微镜中区别以上8种细胞成分或区室,再借助开源软件CellProfiler提取每个细胞的1 000多个形态特征,从形态学上反映细胞的表型信息,再对上百种罕见病的几万张细胞图片进行特征分析,从而找到罕见病的指纹特征(Fig 2)[13]。之后,结合自动化生化指标检测,实现大规模并行化的高通量药物筛选。目前,该公司已经确定了几十种罕见疾病有前景的候选化合物,例如,治疗2型神经纤维瘤病(neurofibromatosis type 2,NF2)的mTOR受体抑制剂AZD2014和VEGF c-KIT激酶抑制剂PTC99等[14],还与赛诺菲(Sanofi)集团建立合作关系,以评价开发过程和临床前测试中获得成功的化合物。此外,Cell Image LibraryTM在线有各种细胞图像、视频和动画以及药物处理后的细胞形态学数据,有利于其他团队使用该技术进行采集、分析和比较细胞图像,免费提供数据库,实现资源共享。
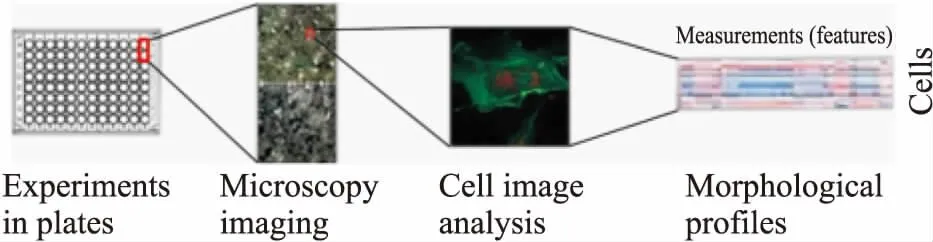
Fig 2 Morphological analysis based on cell phenotype images
基于细胞图像组学的表型筛选虽然满足了大量化合物快速筛选以及活性测定的需求,但仍未解决无法有效确定药物作用机制和靶点的问题,因此,该技术目前还只是被AI技术团队使用。
2 小样本学习在新药研发中的应用
从小样本中学习和概括的能力是人类智慧的标志[15]。道格拉斯·霍夫斯塔特(Douglas Hofstadter)曾指出,只有全面的AI技术才具备人类处理文字的灵活性,而小样本的学习能力正是其中重要的一环[16]。AI技术已经在大数据样本中获得成功(Tab 1),尤其是深度学习(deep learning),通过搭建多个神经网络,实现对大量标记样本的学习,而且样本越大,诊断精准度越高。所以,AI技术实现对小样本学习(one/few/low-shot learning),可以推动AI向小样本学习模式的发展,有利于在缺乏大样本的疾病中进行新药研发,并降低成本。
2.1 迁移学习和半监督学习对于某些情况,比如确定个体沙门氏菌血清型[17]等,研究者只能够获取单个或几个样本,有时还是未知样本。为了实现小样本学习,AI技术常会用到迁移学习(transfer learning)以及半监督学习(semi-supervised learning)等。迁移学习指先在样本源领域(source domain)训练,再把整合的知识迁移到目标领域(target domain),从而将已知的样本信息与小样本目标信息进行联系。研究者往往将迁移学习和深度学习结合,形成深度迁移学习(deep transfer learning)。美国芝加哥大学Huynh等[18]先从小样本乳腺癌图像数据库中找到每个图像中病灶的感兴趣区域(region of interest,ROI),并进行截图标记(良性或恶性)作为目标集,再通过非医学任务预训练的卷积神经网络,从该小样本医学图像集中提取肿瘤信息,再借助支持向量机分类器进行特征分类,之后利用接收器操作特征分析和交叉验证进行模型评估,最终很好地完成了对乳腺癌的准确诊断,并发现潜在的药物作用靶点。此外,迁移学习还可用于阿尔茨海默病、前列腺癌等的准确诊断。所以,迁移学习有利于小样本信息分析,能够推动精准医学中AI技术的发展。
而半监督学习通过标记的小样本信息和未标记的大样本信息进行训练和分类,从而完成小样本学习。Chen等[19]通过基于网络的拉普拉斯正则化最小二乘协同药物组合预测(network-based Laplacian regularized least square synergistic drug combination prediction,NLLSS)算法,整合少量已知的协同抗真菌药物组合和大量未知的抗真菌药物组合,并根据发挥协同作用的药物具有相似的性质,同时借助药物-靶点相互作用和药物化学结构来检测药物相似性,从而预测潜在的协同药物组合,结果证明,NLLSS可以有效识别潜在的协同药物组合,探索药物的新适应症,并有助于协同药物组合的潜在分子机制研究。加拿大Hao等[20]则通过间接阐明阳性无标记学习(positive unlabeled learning for splicing elucidation,PULSE)算法,利用剪接、进化、调节性、蛋白质组学、结构功能等5个维度,共计48个预测特征的小样本蛋白质异形体(protein isoforms)数据集和大量未标记的蛋白质异形体数据集,进行半监督学习,首次成功预测约32%的“外显子跳跃”选择性剪接事件会产生稳定的蛋白质,并获得了大量推测的和未表征的蛋白质,再对预测的活性蛋白质异形体进行结构分析,包括剪接掉PK酶结构域261~271片段的BRSK2蛋白质异形体、剪接掉WD40结构域431~496片段的多聚体调节因子1蛋白质异形体等,找到疾病特异的蛋白质异形体(disease-specific protein isoforms),有助于疾病预测和靶点研究。
2.2 基于高维小样本数据的靶点筛选高维数据是多变量数据,使用更多变量来描述样本,而不增加要分析的样本数量,而且变量的数量往往超过了样本的数量。例如,同时测量所有已知基因的表达(大于20 000),但研究中受试者血样可能只有几百个[21]。如何方便有效地实现高维数据可视化,一直都是国内外科研机构关注的问题。而AI技术通过深度自动编码器的反向传播,实现了高维数据的非线性降维,并能保留全局特征[22],因此,可以帮助人们分析并整合疾病高维数据和遗传信息,以便更好地找到对药物筛选有价值的作用靶点。由于研究样本的复杂性,小样本数据往往以高维数据形式被获取。目前,基于高维小样本数据的疾病靶点筛选方法还在逐步完善当中。中国科学院陈洛南团队将高维小样本动态网络生物标志物应用于流感病毒感染和癌症转移的数据集,来准确识别疾病的临界状态,以进行个体化疾病诊断,并能分析疾病进展的分子机制。此外,还能识别许多非线性生物过程的临界状态,如细胞分化和细胞增殖等,这有助于找到潜在的药物靶点[23-24]。加拿大Chao等[25]则通过动态基因组信息,借助于微阵列杂交(microarray hybridization,MH)和MAS5算法,找到选定血样集中稳定的探针组,再对挑选出的探针组进行评估和优化,从而利用单个外周血液样品找到多种疾病的生物标志物,包括精神疾病、骨关节炎、心血管疾病、胃肠道疾病、肿瘤等,从而获得每个患者的多种疾病患病风险,为组织活检提供了替代方案,也便于不同疾病的诊断和预后,以及药物潜在靶点的筛选。
总之,随着小样本学习的发展,基于高维小样本数据的新药研发会使AI技术变得更加全面、成熟。
3 AlphaGo Zero在新药研发中的应用
2018年,AI技术出现重大突破,英国杂志Nature发表重磅文章,指出AlphaGo Zero只使用单一的深度强化学习(deep reinforcement learning)算法和蒙特卡罗树搜索(Monte Carlo tree search, MCTS)[26],从空白状态学起,无人工监督,利用自我对弈模型来不断迭代,进而找到全局最优解。其中,自我对弈模式可以类似地理解为近似策略迭代方案,由MCTS来进行策略评估和策略优化。AlphaGo Zero已经击败了AlphaGo及其升级版AlphaGo Fan、AlphaGo Lee等,而且只使用1台机器和4个张量处理单元(tensor processing unit,TPU),非常节省资源[27]。AlphaGo Zero的成功,表明深度强化学习算法在没有大量先验知识的情况下,能很好地完成复杂任务,突破了现有AI技术需要样本训练集的局限性。
最近,德国Segler等[28]通过深度学习神经网络和MCTS,利用Reaxys化学数据库学习已知的大约1 240万个单步化学反应,再反复训练进行算法优化,使其可以预测单步可用的化学反应。再结合指导搜索的扩展策略网络和过滤网络,预先选择目标化合物的最优合成路线,大幅提高了化合物合成效率。该算法被称作“化学界的AlphaGo”,具有划时代意义。而AlphaGo Zero比AlphaGo学习能力更强,所以,AlphaGo Zero理论上具备更强的处理复杂问题的能力,将会进一步推动新药研发的快速发展。
4 展望
AI技术通过高维数据分析结果来生成假设,改变了新药研发“先假设再验证”的传统模式,此外,AI技术可以利用小样本学习,进一步推动精准医学和个体化医疗的发展。而AlphaGo Zero的成功表明机器无需帮助就可能超越人类,为AI技术带来重大突破,但AlphaGo Zero的成功经验能否拓展到新药研发,还需要进一步探索和研究。目前,世界上还没有AI技术研发的新药被批准上市,然而,Berg Health公司的候选药物BPM 31510和BPM 31543均进入临床研究阶段,而BPM 31510预计会在2020年获得FDA批准[29]。最近,美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)开展的“AI Next”项目,使机器具备理解和推理能力,为人类开启第3次AI浪潮[30],预计会为新药研发策略带来又一次革命性转变。
