吊装机器人肢体动作指令识别技术研究
2019-06-27邹少元刘海强黄玲涛张红彦
倪 涛 邹少元 刘海强 黄玲涛 陈 宁 张红彦
(1.吉林大学机械与航空航天工程学院, 长春 130022; 2.集美大学机械与能源工程学院, 厦门 361021)
0 引言
随着人体行为识别技术和机器人技术的快速发展,人体行为识别在虚拟现实[1]、视频监控[2-8]和人机交互[9-11]等领域被广泛应用。在港口、码头、矿山等大型货物的远距离吊运场合,驾驶员与现场指挥员之间距离较远,难以准确把握现场操作员的指令信号。
近年来,肢体识别技术主要使用卷积神经网络(Convolutional neural network, CNN)和循环神经网络(Recurrent neural network,RNN)两种网络进行训练和识别。文献[12]构建多级CNN结构,提取图像多种时空信息特征,该方法使用图像序列以及对应的光流图像序列作为卷积神经网络输入进行训练,但网络非常复杂,训练难度大且容易过拟合。文献[13-16]基于Kinect相机提取的骨架,使用精细构造的多层RNN网络进行肢体行为识别,但是该方法网络输入只局限于骨架节点的坐标,提取的特征信息有限。文献[17-18]构建多级CNN-RNN网络,该方法综合了CNN训练简单和RNN能够获取更多的上下文信息的优势,但增大了网络复杂度,难以达到实时识别的应用需求。
为了克服上述方法存在的问题,本文提出一种CNN-BP融合网络,采用InceptionV3和BP网络融合方法对机器人吊装指挥姿势进行识别。首先基于OpenPose(卡内基梅隆大学计算机科学学院CMU AI 计划)提取图像骨架节点坐标,并由此生成RGB骨架图作为InceptionV3网络的输入层,同时将骨架节点坐标生成骨架向量作为BP神经网络输入层进行训练,再将两个网络的输出层进行融合,并使用Softmax求解器得到识别结果,最后使用双重验证控制方法实现机器人辅助吊装工作。
1 系统组成
如图1所示,系统包含人体肢体识别模块和机器人辅助吊装控制模块两部分。鉴于Kinect相机进行肢体识别监控距离有限,不适合吊运机器人的远距离操控和大作业空间的应用场合,本文采用网络大变焦摄像头作为图像采集设备,对采集图像基于OpenPose提取人体骨架节点坐标信息。该网络大变焦摄像头监控距离最大为80 m,满足远距离人机交互作业。

图1 系统总体方案Fig.1 System overall plan
人体肢体识别模块中,构建CNN-BP融合网络进行训练和识别。依据OpenPose提取的骨架节点的坐标生成RGB骨架图作为InceptionV3网络输入,采用迁移学习方法提取RGB骨架图深层抽象特征。同时将18个骨架坐标生成一个骨架向量输入BP神经网络提取其骨架坐标间点、线以及面等浅层特征。最后将两个网络输出层进行融合并用Softmax求解器得到识别结果。本文选取9组机器人吊装指令(参考机器人吊装指挥信号GB 5082—1985),使用CNN-BP网络对采集训练数据进行训练和识别,将识别结果输入机器人辅助吊装控制模块,采用双重验证控制方法完成机器人辅助吊装操作。
2 数据处理
图像采集设备为由安迅士网络摄像机(AXIS-Q1635型)和海康威视大变焦镜头(HV1140D-8MPIR型)组成的网络大变焦摄像头,如图2所示。为保证在摄像机振动情况下成像稳定,AXIS-Q1635型摄像机配备一个1/2英寸传感器。HV1140D-8MPIR型镜头是一款自动光圈手动变焦800万像素大变焦镜头,提供焦距变化范围为11~40 mm,最大监控距离为80 m。

图2 网络大变焦摄像头示意图Fig.2 Large-zoom webcam schematic1.HV1140D-8MPIR型镜头 2.AXIS-Q1635型摄像机
数据预处理的关键是获得RGB骨架图和骨架向量,RGB骨架图和骨架向量获取操作流程如图3所示,其操作步骤为:①首先通过网络大变焦摄像头采集一帧图像,经OpenPose提取人体18个骨架节点坐标。②将18个骨架坐标展成一列,生成骨架向量。③对骨架节点间使用不同颜色的椭圆进行连接,并使用不同颜色进行着色。为强化肢体特征信息,剔除背景信息获得RGB骨架图。
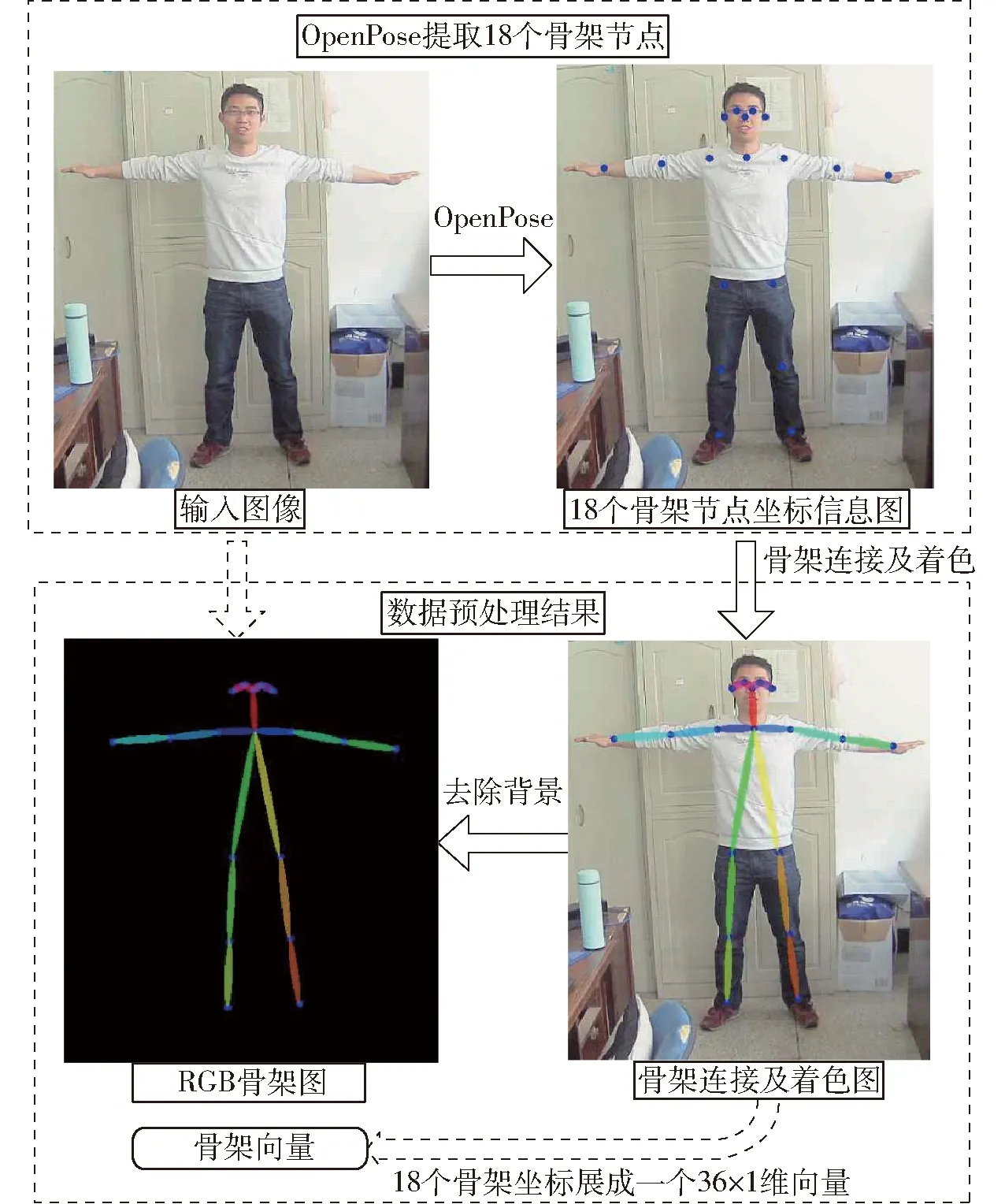
图3 RGB骨架图和骨架向量获取示意图Fig.3 Schematic of RGB skeleton diagram and skeleton vector acquisition
为验证CNN-BP分类性能,参考GB 5082—1985《起重吊运指挥信号》选取的9组待分类指挥信号分别为:预备、要主钩、要副钩、吊钩上升、吊钩下降、水平向左移动、水平向右移动、吊钩停止、紧急结束。考虑到现实环境下人的姿态多变,为了提升CNN-BP网络模型的分类性能和泛化能力,对提取的RGB骨架图采用-15°~15°随机旋转、水平垂直两个方向-20~20像素点随机平移、0.8~1.2倍随机缩放和随机初始化仿射变换矩阵进行仿射变换多种数据增强方式,数据增强效果如图4所示。分别对9组机器人吊装指令各采集1 000幅图像,共计9 000幅初始图像,每幅图像每种数据增强方式随机产生1幅图像共生成45 000幅训练数据。使用数据增强方式大大扩充了训练数据的数量,可以有效防止模型过拟合。
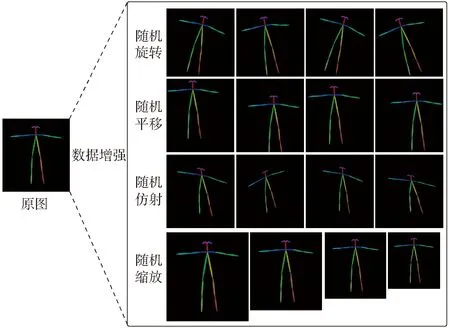
图4 4种数据增强方式示意图Fig.4 Sketch of four data enhancement methods
3 肢体动作识别分类器构建
3.1 CNN-BP网络架构
卷积神经网络是一种深度前馈神经网络,可以很好地提取图像的局部和更深层次的抽象特征。BP神经网络是一种前向传播,误差逆向传播训练的多层感知神经网络,能够很好地提取数据浅层特征。参照文献[19-20]构建CNN-BP融合网络架构如图5所示,分类过程主要包括网络输入预处理模块和CNN-BP网络模块两部分。其中网络输入预处理模块用于提取RGB骨架图和骨架向量;CNN-BP网络模块包含CNN网络迁移学习模块、BP神经网络模块和网络融合模块。
3.2 基于InceptionV3网络特征提取
经典CNN网络在ImageNet数据集效果如表1所示。由表1可知,InceptionV3和IncetionResNetV2在ImageNet数据集效果较优,但考虑模型复杂度,选择InceptionV3网络提取RGB骨架图特征。由于训练数据有限,文献[21-23]对深度CNN网络ImageNet数据集上使用迁移学习方法进行分类任务,得到了较优的性能。迁移学习是利用源域解决任务获得一些知识来提升目标分类性能的一种算法,文献[21-23]先将InceptionV3网络在大型图像数据集ImageNet上进行预训练,训练后保留卷积层训练参数用来初始化应用于本文RGB骨架图分类任务InceptionV3网络卷积层参数,具体实现过程如图6所示。
采用迁移学习方法,使用随机梯度下降算法(Stochastic gradient descent optimizer,SGD),设置批大小为32、低学习率0.001、动量为0.9进行训练,网络终止迭代轮数为1 000。对底层和顶层卷积层激活后的特征图可视化如图7所示(限于篇幅仅可视化每个特征图的前32个通道)。由图7可知,靠近输入层的卷积层(conv2d_1、conv2d_3、conv2d_5)激活保留图像的大量边缘、颜色和形状等信息,随着层数的加深靠近输出层的卷积层(mixed8、 mixed9和mixed10)激活后变得越来越抽象并且难以直观理解,其表示图像更高层次的特征信息。随着深度网络的加深,可以将无关信息过滤并放大和细化用于分类的特征信息。其中InceptionV3卷积层命名参考Keras深度学习框架。
3.3 BP神经网络特征提取
OpenPose提取的18个骨架节点坐标记为(P1,
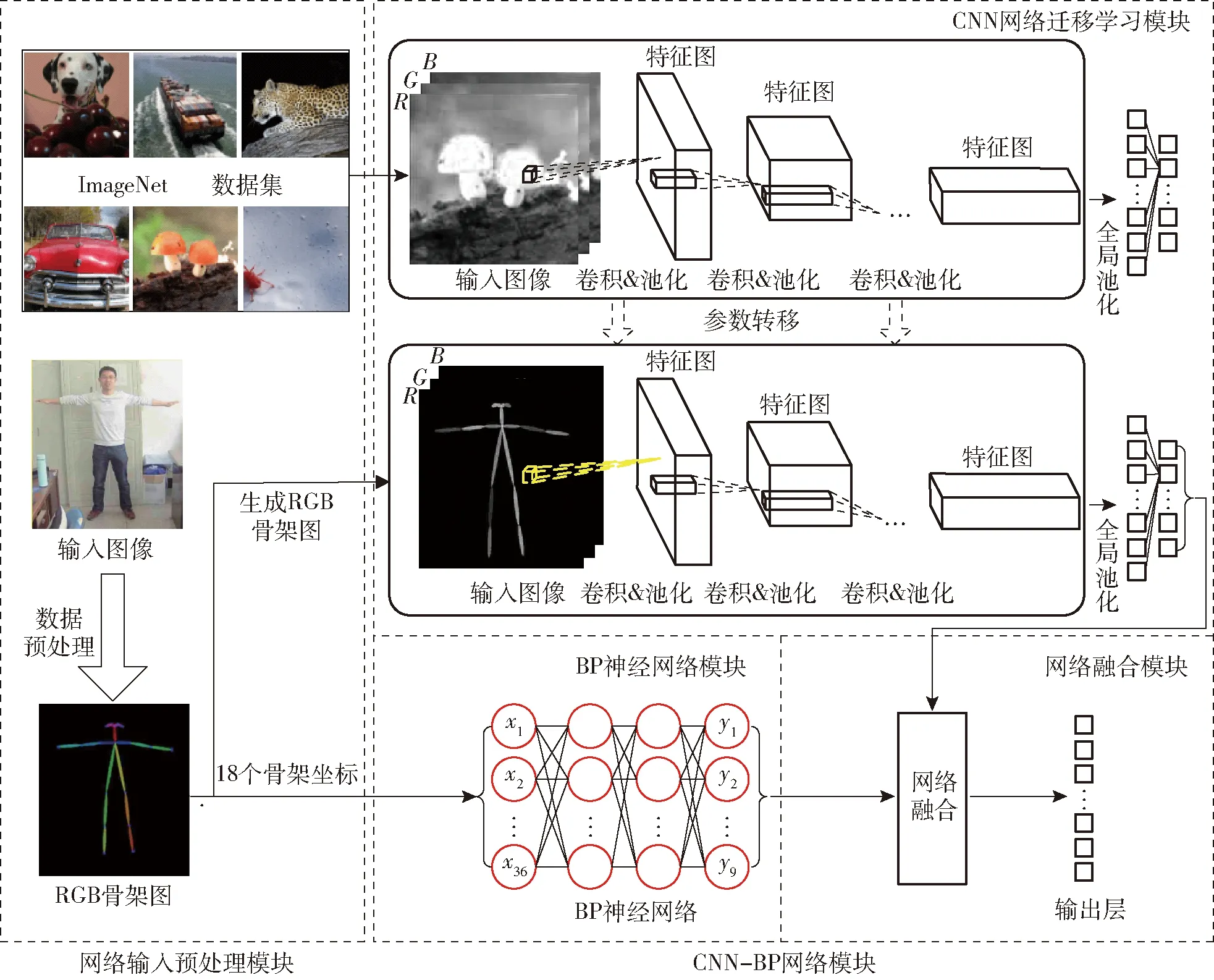
图5 CNN-BP网络架构Fig.5 CNN-BP network architecture
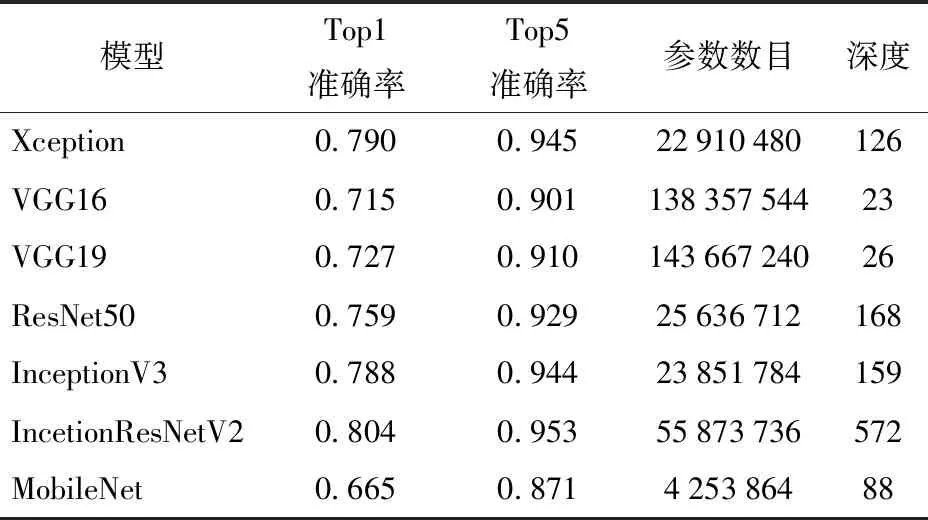
表1 经典CNN网络在ImageNet上效果Tab.1 Effect of classic CNN network on ImageNet

图6 迁移学习示意图Fig.6 Migration learning schematic
P2,…,P18),将其展成一个骨架向量(Px1,Py1,Px2,Py2,…,Px18,Py18)作为BP神经网络输入层。点与点特征之间构成线特征,线与线特征之间构成面特征,本文BP神经网络设置2个隐含层,网络结构示意图如图8所示。网络训练参数为:学习率为0.005,第1隐含层节点个数为100,第2隐含层节点个数为50,dropout概率为0.5,正则化系数1.1,终止迭代次数为1 000。
3.4 CNN-BP网络融合
(1)
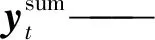

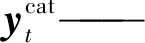
n——分类类别数目

图7 卷积层激活后的特征图可视化图Fig.7 Feature map visualization after convolutional layer activation
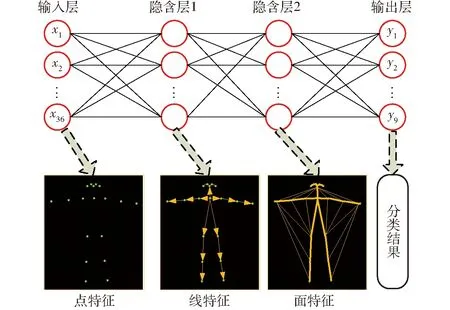
图8 BP神经网络结构示意图Fig.8 Schematic of BP neural network structure
(2)
式中N——训练样本数
K——样本类别数
y(i)——第i个样本预测类别
θ——权重
x(i)——第i个样本的特征
exp(θ(k)Tx(i))——样本i被分类成类别k的概率
l{y(i)=k}——正样本
4 实验及结果分析
4.1 实验环境
实验控制设备为计算机,配置为Intel i7处理器,内存8 GB,显卡GTX980,Win10环境使用PyQt编写软件控制界面。鉴于OpenPose与InceptionV3复杂度过高,为了确保实时性采用双GTX980显卡(显存8 GB),模型在GPU进行运算。为了降低计算量,设置OpenPose的scale_search参数为“0.5,1”,并将输入图像压缩至320像素×240像素,得到单帧图像识别时间为386 ms,为了实时识别采用多线程编程将视频预览与算法运算分离。其中吊装机器人实物如图9所示。

图9 吊装机器人实物图Fig.9 Physical diagram of lifting robot
4.2 网络训练结果
为验证提出的CNN-BP网络模型的准确性,分别使用InceptionV3网络、BP神经网络和CNN-BP网络,对吊装机器人9种吊装指挥姿势进行训练,分类精度如表2所示。从表2可以看出,CNN-BP采用Sum融合方式识别精度最高,其分类结果的混淆矩阵和ROC曲线如图10、11所示,可以看出该方法对9组机器人吊装姿势都能够准确分类,平均识别精度达到0.953。同时9组动作识别的ROC曲线AUC值不低于0.92,平均AUC达到0.96。其中RUC为ROC曲线和横轴围成的面积,取值范围为0~1,越接近1表示分类器分类性能越好。
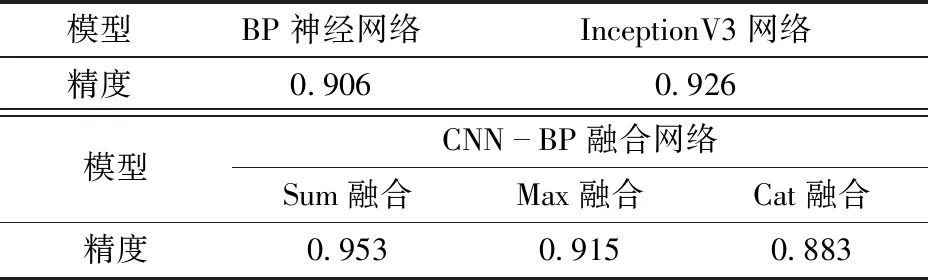
表2 不同网络分类结果Tab.2 Different network classification results

图11 9组辅助吊装命令识别ROC曲线Fig.11 Nine groups of auxiliary lifting commands identified ROC curves

图10 辅助吊装命令分类结果Fig.10 Auxiliary lifting command classification result
4.3 机器人辅助吊装系统控制方法
基于双重验证控制方法的机器人辅助吊装控制过程和9组控制信号如图12所示,机器人辅助控制系统初始状态处于待命状态,在CNN-BP网络识别出“预备命令”控制系统才会进入工作状态。而肢体识别过程采取间隔50 ms采集两帧图像先后输入CNN-BP网络分类模块,对两次识别结果进行判断,如果相等且识别结果为“预备指令”则开启机器人吊装控制,在开启机器人辅助吊装系统后将识别的控制信号发送给机器人吊装控制器完成吊装操作,如果两次识别结果不相等则丢弃本次识别结果,该方法实时识别精度达0.99以上。

图12 机器人辅助吊装系统Fig.12 Robotic assisted lifting system
5 结束语
鉴于Kinect进行肢体识别监控距离有限,搭建了使用网络大变焦摄像头并基于OpenPose的CNN-BP融合网络,使用迁移学习方法在ImageNet数据集上对InceptionV3网络预训练。采用旋转、平移、缩放和仿射方法对采集的训练数据集进行数据增强,有效防止了过拟合。采用3种方式对InceptionV3网络和BP神经网络两种网络输出进行融合,结果表明,Sum融合方式可以得到更高的模型分类精度。对机器人辅助吊装系统建立了双重验证控制方法。实验结果表明,采用CNN-BP融合网络和双重验证方法保证了模型运行的精度和时效性,识别精度达0.99以上,大大提升了远距离人机交互能力。
