基于层次化深度关联融合网络的社交媒体情感分类
2019-06-26蔡国永吕光瑞
蔡国永 吕光瑞 徐 智
(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)
随着移动互联网和智能终端的快速发展,社交媒体上的用户生成内容变得越来越多样化,社交媒体数据已不再仅限于单一的文本形式,例如越来越多的社交用户倾向于使用图像和短文本这种多模态内容的形式来表达他们的观点和在社交媒体上相互交流.这些大量社交用户分享的多模态数据为人们提供了探索众多话题的情感和观点的宝库,因此多模态情感分析已经成为一个重要的研究热点[1-9],但是大规模多模态社交媒体数据的情感分析还是一个充满挑战的任务.
早期的情感研究较多关注单一的文本或图像,且采用传统的机器学习分类算法.近年来,鉴于深度学习技术的优异表现,越来越多的研究人员倾向于使用深度神经网络来学习文本的分布式和稳健的特征表示用于情感分类[10-13].与此同时,卷积神经网络(convolutional neural network, CNN)能够自动地从大规模图像数据中学习稳健的特征且展示了优异的性能,一些研究者开始探索基于CNN的图像情感分析[14-16].最近,在多模态情感分析的研究中[1-9],利用深度神经网络的方法在性能上也更优异.多模态情感分析是融合多种模态的信息进行统一的分类预测任务,其关键的问题是多模态样本特征的融合.由于不同模态的异质性,模态之间特征的融合是较困难的.尽管基于深度网络相关的模型已经取得了不错的进展,但是基于深度网络的融合模型仍需要进一步深入研究.
为了克服已有的图像-文本的多媒体情感分析研究中存在的异构模态的特征融合方式相对简单以及单一图像处理上仅从图像自身提取特征等不足,本文的主要贡献有4个方面:
1) 在图像的处理上利用迁移学习策略和图像中层语义特征相结合的方法来构建具有一定语义的视觉情感特征表示.
2) 结合深度典型相关分析(deep canonical cor-relation analysis, DCCA)[17]和深度线性判别分析(deep linear discriminant analysis, DeepLDA)[18]的思想提出多模态深度多重判别性相关分析的联合优化目标,通过优化生成最大相关的判别性视觉特征和判别性语义特征以构建图像和文本在特征层次上的语义相关,且使特征具有判别性的能力,从而提升语义配准.
3) 提出基于多模态协同注意力网络的融合方法,能进一步序列化地交互图像的视觉特征和文本的语义特征,从而更好地匹配融合多模态特征.
4) 在多个数据集上的对比实验表明,本文提出的层次化深度关联融合的网络模型在情感分类任务中能取得更好的分类效果.
1 相关工作
多模态情感分析的研究尚且处于初期阶段,大致可以分为2类.较早的研究以特征选择模型为主,最近开始基于深度神经网络模型展开研究.
Wang等人[1]利用统一的跨媒体词袋模型来表示文本特征和图像特征,且利用机器学习的方法来预测融合后的情感,结果表明跨模态情感分类结果要略优于单模态的情感分类结果.Cao等人[2]融合来自于形容词名词对(adjective noun pairs, ANPs)[19]的图像中层视觉特征的预测结果和由情感词、情感标签和句子结构规则组成的文本特征的预测结果,其中图像和文本的融合权重是通过参数来控制,最后用于微博的公共情感分析.Poria等人[3]通过使用特征级的和决策级的融合方法合并来自于多模态的情感信息.Katsurai等人[4]首先构筑视觉特征、文本特征和情感特征,然后利用映射矩阵映射视觉、文本、情感这3个模态的数据到一个共同的潜在嵌入空间中,认为潜在空间中的映射特征是来自于不同模态的互补信息从而被用于训练情感分类器.
最近深度学习方法应用于多模态情感预测也备受关注.如Cai等人[5]利用2个单独的CNN结构分别学习文本特征表示和图像特征表示,将其合并后输入另外的CNN结构以进行多媒体的情感分析.Yu等人[6]也利用2个CNN结构分别提取文本和图像的特征表示,使用逻辑回归对文本的和图像的特征表示进行情感预测,最后使用平均策略和加权的方法融合概率结果.Baecchi等人[7]提出基于连续词袋模型和降噪自动编码的多模态特征的学习模型以进行Twitter数据情感分析,当然该模型也可应用到其他的社交媒体数据上.You等人[8]提出跨模态一致回归的方法用于结合视觉和文本的情感分析,该方法利用深度视觉的和文本的特征构建回归模型.而Xu等人[9]利用卷积网络的结构来提取图像和文本的特征表示,然后利用残差的模型来合并图像和文本的多模态特征用于情感分析.
尽管这些模型都是有效的,但是大多都独立地使用视觉和文本的信息,且在融合过程中往往忽略了图像和文本之间的内在关联.通常,组合不同模态数据的多模态融合方法可以分为早融合、后融合、混合融合[20].其中,后融合涉及为每种模态数据构建相应的分类器,然后结合这些决策进行预测;而早融合需要将不同模态的特征融合到单个分类器中.本文的研究仍属于特征层的融合,但是不同于已有的研究方法,本文工作的关注点有2个方面:1)同时处理图像和与之共现的文本信息;2)在多模态深度网络的结构中,利用层次化深度关联融合的方法来探究图像和文本之间的语义关联.首先,本文整合DCCA[17]和DeepLDA[18]到一个统一的联合多模态优化目标中,以此构建图像和与之共现的文本在特征层次上的语义关联,且使各自生成的特征具有较好的判别性.此外,最近注意力模块已经成为应用于各种任务的现代神经系统的组成部分,比如机器翻译[21]、图像问答任务[22]和图像标题生成[23]等,然而很少的研究工作已经利用注意力机制进行融合,本文提出基于协同注意力(co-attention)机制的多模态融合策略,用于训练情感分类器.
2 方法描述
本节介绍提出的用于多模态情感分析任务的层次化深度关联融合的网络模型,整体结构如图1所示,总共由5个部分构成:①视觉模态特征提取网络;②文本模态特征提取网络;③多模态深度多重判别性相关分析;④co-attention网络的多模态注意力融合模型;⑤分类网络.
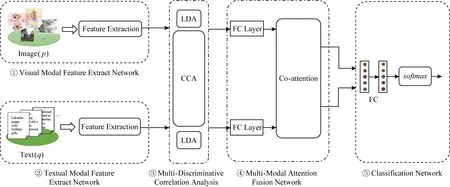
Fig. 1 Framework of hierarchical deep correlative fusion network for multi-modal sentiment classification图1 基于层次化深度关联融合网络的社交媒体多模态情感分类框架图
基于层次化深度关联融合网络的多模态情感分类模型首先利用图1中①②的多模态特征提取网络逐层提取视觉模态和文本模态的特征,得到相对应的顶层特征表示,然后通过图1中③进一步生成最大相关的判别性特征表示,最后使用图1中④的co-attention网络来交互合并这2种特征表示并传递到图1中⑤的全连接神经网络(fully connected neural network, FCNN)中进一步深层融合后再用于训练情感分类器.下面阐述模型的细节.
2.1 视觉模态特征提取网络
尽管已有学者在情感分析相关研究上探测过图像视觉特征[14-16,24]或者图像中层语义特征[19,25-26],但是仅从单一视觉特征或中层语义特征的角度来构筑视觉情感特征,并不能构筑完整的且易于理解的图像视觉特征.本文同时从图像特征提取和图像中层语义特征提取的角度来学习高层次的视觉情感表示,如图2中①所示.
图像的特征提取是基于VGG[27]展开的,其由5个卷积块和3个全连接层组成,且已经在1 000个目标分类的ImageNet数据集上表现出了极好的性能.本文利用迁移学习的策略来克服ImageNet数据集和图像情感数据集的不同差异.首先,VGG16模型在ImageNet的数据集上训练好,然后迁移已经学习好的参数到情感分析的目标中.在提出的模型中,修改最后用于目标分类的全连接层为特征映射层,然后提取该全连接层的特征输出,如图2中①(a-1)所示.
为了提取更全面的图像中层语义特征,首先划分每一个图像对应的中层语义特征(ANP)为形容词和名词,然后通过CNN来分别提取图像的形容词描述性特征和名词客观性特征.针对形容词和名词的特征提取网络,CNN采用的是二维卷积,每一个形容词或名词的样本像单通道图像一样被调整为50×50的大小,利用2个平行的子网络,即图2中①(a-2)中A-net和N-net,其分别由同样的卷积层和全连接层组成.
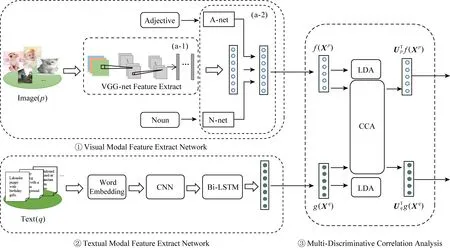
Fig. 2 Schematic sketch of deep multi-modal multi-discriminative correlation analysis to learn the visual and textual content图2 视觉和文本的多模态深度多重判别性相关分析图解
总之,在视觉模态特征提取上,本文提出联合学习图像ANP的形容词和名词以及图像特征以构筑具有一定语义的视觉情感特征表示,以此缓解图像视觉特征和文本语义特征之间的语义鸿沟.后文中将称视觉模态特征提取网络为f.
2.2 文本模态特征提取网络
文本模态特征提取网络是由词向量输入层、卷积层、双向长短时记忆网络(Bi-LSTM)层和全连接层组成,如图2中②所示.
假设xi∈Rk是句子中第i个词对应的k维词向量,则一个长度为n的句子表示为
x1:n=x1⊕x2⊕…⊕xn,
(1)
其中,⊕表示连接操作,在句子矩阵x1:n上利用一个单层的CNN[28],它的卷积层包含高度分别为h1,h2,h3的3个滤波器F1∈Rh1×k,F2∈Rh2×k,F3∈Rh3×k.每个滤波器Fi在输入的句子序列上进行滑动,当Fi应用到整个句子矩阵中每一个可能的hi窗口的词上时,就会产生一个特征映射ci∈Rn-hi+1,其中某一项窗口的词的特征映射ci,j为
ci,j=δ(Fi*x[j:j+hi-1]+bi),
(2)
这里*是卷积操作,j=1,2,…,n-hi+1,bi∈R是一个偏置项,δ(·)是一个非线性激活函数.每一个滤波器Fi能够生成M个这样的特征映射,因此总共获得了3M个特征映射.然后,在滤波器Fi的M个特征映射向量的每一个长度上应用最大池化操作,则结果输出向量为oi∈RM,具体表示为
(3)
通过⊕连接每一个oi得到o=(o1⊕o2⊕o3)∈R3M.然后将o输入Bi-LSTM网络,从正向和反向的角度来使用已提取的特征从而更好地学习输入的文本序列.最后,经过对文本的序列建模后,将Bi-LSTM的输出传递给全连接的神经网络以更好地融合时序特征以形成更容易被区分的高层特征表示.后文中称文本模态特征提取网络为g.
2.3 多模态深度多重判别性相关分析
本文提出的多模态深度多重判别性相关分析是基于典型相关分析(canonical correlation analysis, CCA)和线性判别分析(linear discriminant analysis, LDA)展开的.两者都来自经典的多元统计,都依赖于各自输入特征分布的协方差结构.不同之处在于,CCA是一种适用于多模态数据的分析方法,但是它既没有考虑标签信息也不能对各自模态的内部信息进行分析;而LDA是一种利用标签信息的且适用于单模态数据的分析方法,但是它不能直接地应用到多模态数据分析上,因此可将两者结合起来,以充分发掘各自模型的优势,从而形成一个在多模态学习过程中既探究不同模态之间的最大相关性又兼顾各自模态最大判别性的多模态数据处理方法.
多模态的样本数据往往来自于异构特征空间,不同模态数据的特征分布差异较大,此时如果将异构特征融合后再进行LDA,较难取得好的效果.例如,那些来自于社交网站的图像和文本,如果直接将图像和文本的特征融合后再用于LDA,这既没有考虑图像和文本的对应关联也没有考虑图像和文本各自特征分布的差异.因此本文将在考虑不同模态之间相关性的同时,也尽量考虑不同模态之间的特征分布的差异,即在寻求视觉模态和文本模态最大相关性的同时,兼顾视觉模态和文本模态各自的线性判别性.多模态深度多重判别性相关分析方法包含2部分:相关性分析部分和判别性分析部分.
J(f(Xp),g(Xq))=C(f(Xp),g(Xq))+
[D(f(Xp))+D(g(Xq))],
(4)
其中,J(f(Xp),g(Xq))表示p,q模态间的多重判别性相关分析的目标函数,C(f(Xp),g(Xq))表示两者模态间的相关性分析项,D(f(Xp))和D(g(Xq))分别表示各自模态内部的判别性分析项.
本文以式(4)为基准来设计模型,即从不同模态之间来考虑多重判别性的相关分析,下面分别对模型中的各项进行阐述.
2.3.1 多模态深度相关性分析
Andrew等人[17]提出基于CCA的端到端的深度神经网络的解释方法DCCA,其优化目标是推动多模态网络学习高度关联的特征表示.受到DCCA方法的启发,本文在自定义的多模态深度网络结构f和g下来学习视觉模态和文本模态间的相关性,称为Multi-DCCA.
在CCA中,首先通过预处理的操作,分别使f(Xp)和g(Xq)变成中心数据矩阵,表示为
(5)
(6)
其中,N表示数据的总数,1∈RN×N表示元素全为1的矩阵.
视觉模态和文本模态的顶层特征表示的正则化自协方差矩阵,分别表示为
(7)
(8)
其中,rp,rq是正则化参数,是为了确保协方差有积极的定义;I是单位矩阵.
除了领域自身的方差外,不同领域学习到的特征表示的交叉协方差矩阵为
(9)
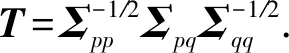
(10)
2.3.2 多模态深度判别性分析
Dorfer等人[18]提出基于LDA的端到端的深度神经网络的解释方法DeepLDA,其优化目标是推动网络在顶层表示上学习线性可分的潜在空间.受到 DeepLDA的启发,本文在视觉模态特征提取网络f的顶层和文本模态特征提取网络g的顶层同时学习可以最大化C个不同的多模态数据类别之间区分的潜在表示,称为Multi-DeepLDA.
对于LDA而言,Σpp可作为视觉模态的总体离散度矩阵,同理Σqq可作为文本模态的总体离散度矩阵.此外,由于图像-文本对的标签属于C个不同的类c∈{k1,k2,…,kC},则LDA还需要C个不同类别中每个类别的视觉模态和文本模态的协方差矩阵Σpc,Σqc,以及视觉模态和文本模态中所有不同类协方差矩阵的均值Σpw,Σqw,即类内离散度矩阵,分别表示为
(11)
(12)
(13)
(14)
其中,r是正则化参数,是为了确保协方差有积极的定义.
最后,通过总体离散度矩阵Σpp,Σqq和类内离散度矩阵Σpw,Σqw来定义视觉模态和文本模态的各自类间离散度矩阵Σpb,Σqb:
Σpb=Σpp-Σpw;Σqb=Σqq-Σqw,
(15)
则Multi-DeepLDA是通过找到视觉模态和文本模态内部的映射矩阵A1和A2,使得在相同标签下各自模态内的类间离散度矩阵和类内离散度矩阵的比值最大化,具体表述为
(16)
(17)
其中,映射矩阵A1和A2分别转化各自模态的数据到一个C-1维的空间中,在各自空间中的映射特征变得线性可区分.
总而言之,经济全球化的发展既加深了世界各国之间的依赖程度与依存程度,又缩小了各国之间的比较优势,加剧了国家之间的竞争与贸易摩擦。中国对外开放的深入与现代化进程的发展使中国逐步进入到了贸易摩擦的高发期,而中美贸易摩擦是其中最严重的贸易问题。因此,我国应该积极地采取相应的措施,不断加强自身的经济建设,提高生产技术水平,调整企业的生产方式与出口策略,以减少中美贸易摩擦所带来的负面影响,促进中美经济互利共赢的发展。
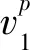
(18)
2.3.3 相关分析与判别分析的融合
综合2.3.1节和2.3.2节可看出,Multi-DCCA和Multi-DeepLDA都是基于相对应的特征值问题的特征结构优化的.其中,Multi-DCCA的优化是把最大化视觉模态特征提取网络f和文本模态特征提取网络g的隐层输出的相关性作为目标来求解矩阵T的奇异值;而Multi-DeepLDA的优化是在相同的多模态类别下最大化视觉的和文本的各自模态内类别的区分,其由相对应的广义特征值问题的特征值大小进行量化.尽管两者的优化有差异,但是这2种方法有相同之处,即它们都反向传播一个由特征值问题引起的误差来调整深度神经网络的参数.
故多模态深度多重判别性相关分析是同时使用Multi-DCCA和Multi-DeepLDA的模型和优化理论,即同时优化2个不同模态之间隐层表示的相关性以及使各自模态学到表示具有判别性能力的联合优化目标的形式化表示为
(19)
其中,第1项是为了优化视觉模态和文本模态之间的相关性,其中用L来泛化典型相关;而第2项和第3项分别是为了优化视觉模态和文本模态的判别性.
多模态深度多重判别性的优化目标式(19)是个端到端的优化过程,首先需要计算相关性的优化目标分别对f(Xp)和g(Xq)的梯度,以及各自判别性的优化目标对f(Xp)和g(Xq)的梯度,然后沿着多模态网络的2个分支并通过标准的反向传播的方法计算针对θp和θq的梯度.
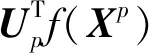
(20)
其中,式(20)中的第1项是在无监督的情况下,致力于使2个不同模态之间具有最大相关性,即两者的距离最小;而第2项是在相同标签的有监督情况下,致力于使2个模态能够各自产生具有可区分性的特征表示.
那些来自于社交网站上的图像-文本的共现数据,在人类概念理解层面上两者之间是存在语义相关性的,但是在特征层面上两者之间并没有关系,且属于异构模态特征,存在较大的语义鸿沟.经过上述系列操作,将存在语义相关的成对的图像-文本数据转化成在具体特征形式上的最大相关,即在特征层次上将图像数据和对应的文本数据建立起关联,从而使两者之间差异更小,如式(20)所示,这一定程度上缓解了异构模态特征之间的鸿沟,且使各个模态具有优异的判别能力.
2.4 多模态注意力融合网络的情感分类
受人类视觉注意力启发的注意力模块提供了一种机制来推断局部特征对于整体特征的相对重要性.鉴于它能够提供完整的可微性和可解释性来发掘网络关注的重点,目前已经在许多神经网络的应用中作为默认的组成部分.注意力模块可以是只关注整体特征中某一特定部分的硬性注意力机制,也可以是通过重要性的概率分布来分配给所有特征的软性注意力机制.本文主要选择软性注意力机制来展开后续的研究.
hI=tanh(WvIfI(vI)⊙WvSfS(vS)),
(21)
α=softmax(WhIhI+bhI),
(22)
其中,WvI,WvS,WhI,bhI是参数,使用⊙表示视觉特征表示和语义特征表示的结合,其中视觉特征fI(vI)∈Rd和语义特征fS(vS)∈Rd具有相同的特征维度d,通过对应交互视觉特征fI(vI)和语义特征fS(vS)从而形成视觉语义特征fIS(v),为了更加频繁地深入交互特征元素,继续学习fIS(v)使其特征元素全部关联到d维特征空间中,从而形成具有特征之间内部关联的新的视觉语义特征hI,因此可得对应于hI中特征的注意力概率α∈Rd,是一个d维向量.
基于每一个特征i的视觉注意力概率αi,新的判别性视觉特征表示通过视觉特征的权重和来构造,即:
(23)
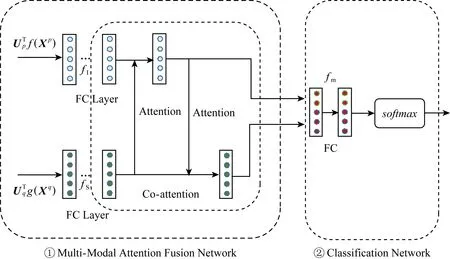
Fig. 3 Schematic sketch of multi-modal attention fusion network for sentiment classification图3 多模态注意力融合网络的情感分类图解
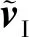
(24)
β=softmax(WhShS+bhS),
(25)
(26)
同理,式(24)~(26)中的参数设置与基于语义的视觉注意力的等式设置相同.
总之,基于语义的视觉注意力和基于视觉的语义注意力是一个交互影响的过程,通过交互来形成更好的有利于图像和文本进行深层融合的特征表示.为了探索图像和文本之间更深层次的内部关联,可以尝试多次序列化地迭代交互视觉特征和语义特征,即形成嵌套的co-attention网络.
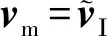
(27)
其中,⊕是连接操作.在网络学习的过程中,隐藏层可以自动地结合视觉的和文本的情感表示.
在获得了融合特征vm之后,通过2层全连接神经网络fm进一步捕获更深层次的内部关联,将最后一个全连接层的输出通过softmax层产生分类标签的分布,如图3中②所示,该过程简要描述为
(28)
其中,Wfm∈RC×d和bfm∈RC是参数,C是标签的数量,在多模态注意力融合网络模型的设置中,vI和vS的输入到最后的分类是一个端到端的过程,该模型使用分类交叉熵计算基于反向传播的训练的批量损失.
(29)
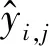
3 实验分析
本节首先介绍实验中要用到的5个数据集,其中3个是根据ANP[19,25 ]从不同的社交网络上爬取的,另外2个是来自于公开的数据集[4];然后介绍了本文实验中的一些设置;最后通过实验来评估本文提出方法的性能,大致包括2部分内容:1)从整体情感分类性能的角度来比较本文提出方法和其他对比方法的实验结果的差异;2)从局部模型设置合理性的角度来确定整体模型中的2个关键部分对情感分类结果的影响.
3.1 数据集
在目前的多模态情感分析中,由于存在一些可以构建的具有英文描述的图像-文本对的多模态情感数据集,而缺乏公开的具有中文描述的多模态情感数据集,故在本文后续的实验中主要讨论英文描述的图文多媒体情感数据集.但是本文提出的模型同样也适用于具有中文描述的多模态情感数据集,这是因为本文提出的模型主要关注的是构建视觉语义和文本语义之间的深层关联交互,与文本语言的表现形式关系不大.语言形式对模型的影响将在今后进一步的工作中验证.
由此,首先利用不同的情感关键词查询视觉中国官网的搜索引擎来构筑数据集.具体而言,利用视觉情感本体库(VSO)中3 244个ANP[19]作为情感关键词从视觉中国网站上的Getty专区爬取38 363条图像-文本对,称其为VCGI数据集;此外,从3 244个ANP[19]中随机选出300个ANP作为情感关键词,又从相同的网站上爬取37 158条图像-文本对,称其为VCGII数据集.
此外,多语言视觉情感本体库MVSO是由来自于12种语言(例如中文、英文等)的15 600个概念构成,这些概念和图像中表达的情感和情绪密切相关.类似于VSO数据集,这些概念也以ANP的形式定义.与VCG数据获取的方式相同,利用MVSO[25]中提供的英文语言ANP,选取其中情感分数绝对值大于1的ANP作为关键词从社交网站Flickr上爬取75 516条图像与其相对应的标题、标签、描述,称其为MVSO-EN数据集.
文献[4]中公开了带有3个标注(积极、中性、消极)的Flickr图像ID,幸运的是Flickr提供了API,其能通过提供的唯一ID获得1张图像的元数据(描述、上传日期、标签(tags)等),因此利用公开的所有ID从Flickr网站上爬取了6万余张图像以及相对应的标题、标签、描述,称其为Flickr数据集.
对于来自于Getty图像的2个数据集,由于存在极少量中文描述的数据集,则删除那些描述是中文的图像-文本对,同时为了获得更丰富的文本语义信息,则删除那些英文描述少于20个字符的图像-文本对;对于MVSO-EN数据集和Flickr数据集,选择那些标签和描述至少有1个存在的数据,将筛选过后的数据集中存在的标签、描述、标题组合成文本信息(这里并不是所有的数据都是三者都有,但至少有1个).由于文本中存在一些不是词汇的内容,而是以链接、符号等明显不含语义信息的内容形式展示,则利用wordnet删除文本信息中不在wordnet中的词汇以生成最终的文本.
VCG数据集和MVSO-EN数据集中图像的情感极性标签来自于ANP的情感分数值,而Flickr数据集中图像的情感标签来自于人工标注,将至少2个人标注为积极的图像的极性标签认为是积极,至少2个人标注为中性的图像的极性标签认为是中性,至少2个人标注为消极的图像的极性标签认为是消极.此外,处理后的Flickr数据集有3万多张积极标签的图像,明显高于消极的和中性的数量.为了人工构造一个较平衡的数据集,从积极的图像中随机取样一些与消极或中性大致数量相等的数据.因此得到了本文在实验中使用的5个数据集,分别为VCGI,VCGII,MVSO-EN,Flickr-2,Flickr-3,其具体信息统计如表1所示:
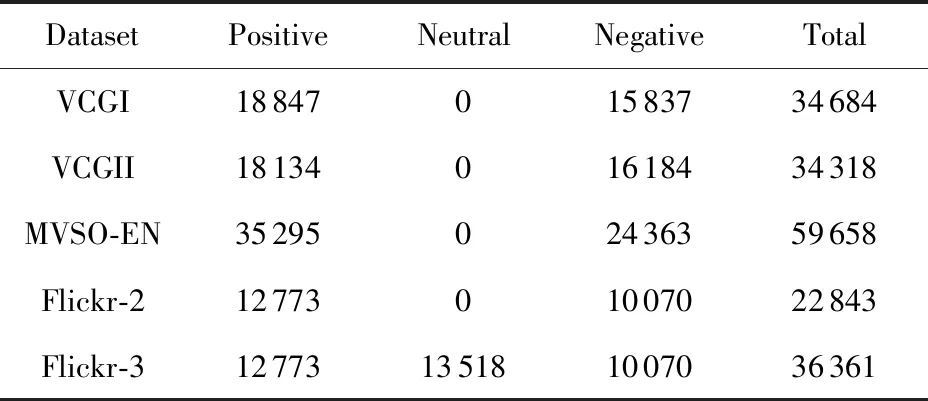
Table 1 Statistic of The Datasets表1 实验使用数据集统计
3.2 实验设置
VCG数据来自于视觉中国网站的Getty专区,其图像的文本描述相对正式和简洁.由于其文本长度普遍较短且长短不一,则选取所用训练集中最长的文本长度为最大长度,不足最大长度的文本用零向量填充.MVSO-EN数据集和Flickr数据集均来自社交网站Flickr,不同的是获取数据的方式以及图像标签(label)的方法不同.由于不是所有的图像共现的文本信息中都含有标签(tags)、描述和标题,则文本长度长短不一且差别较大,故截取最大文本长度为300,不足最大长度的文本以零向量填充.
每一个词向量的维度设置为300,在训练过程中微调词向量来适应本文使用的情感数据集.文本模态特征提取网络的卷积核在实验中使用了3个不同的卷积核尺寸,分别为3,4,5,且针对每一个卷积核尺寸采用了20个滤波器.此外,针对所有的图像都调整其为相同的大小224×224.在实验中总共有2个端到端的优化过程:1)多模态深度多重判别性相关分析的优化,除了在最后关联层上采用线性(linear)激活函数,其他网络层的输出均连接到ReLU激活函数;2)多模态注意力融合网络的分类交叉熵的优化,每一个全连接层(除最后一个)的输出均连接到ReLU激活函数,最后一个全连接层的输出采用softmax进行分类.但是这2个优化的过程均使用小批量的RMSprop方法[29]来优化网络.为了防止过拟合,实验中整体模型上均采用Dropout策略,具体设定Dropout的值为0.5.
本文实验主要评估提出的方法在二分类(积极、消极)目标和三分类(积极、消极、中性)目标上的效果.针对情感分类准确性评估和局部模型效用评估的所有实验中,每个实验均从各自对应数据集中随机选取80%用于训练,20%用于测试.
3.3 实验1:情感分类准确性评估
3.3.1 对比方法
为了证明提出方法的有效性,首先比较其与仅用图像和仅用文本进行情感分析的方法,然后进一步比较其与其他相关的图文融合情感分类方法的性能.对比方法说明有4种:
1) S -Visual. 利用文献[30]中提出的基于迁移学习的视觉情感分析方法,不同的是本文实验利用VGG-16net网络模型.
2) S -Text. 利用本文提出的文本模态特征提取网络,并通过softmax层对文本进行情感分类.
3) CNN-Multi. 由3个CNN组成.预训练的文本CNN和图像CNN分别抽取文本和图像的特征表示,然后拼接2个特征向量输入到另一个仅有4个全连接层的multi-CNN结构.文本CNN中的卷积层用的是二维卷积,每一个文本样本的维度像单通道图像一样被调整为50×50的大小[5].
4) DNN-Multi. 方法同CNN-Multi,不同的是利用本文提出的视觉模态特征提取网络和文本模态特征提取网络分别抽取图像和文本的特征表示,然后拼接2个特征向量输入到另一个有4个全连接层的结构中.
3.3.2 结果与讨论
表2展示了本文方法和对比方法在2个VCG数据集上的比较结果.如表2所示,本文提出的层次化深度关联融合网络的方法DDC+co-attention和DANDC+co-attention的分类效果明显优于单模态图像S -Visual和单模态文本S -Text的分类效果,说明学习图文多媒体内容的特征能更好地理解用户的情感.此外,尽管CNN-Multi在多模态情感分析的任务上取得了一定的效果,然而其特征提取的网络模型比较简单,故修改CNN-Multi网络结构的DNN-Multi方法取得了更优异的效果,这一定程度上说明设计合适的网络结构有益于学习好的特征表示以更好地服务于情感分类.
Table 2Accuracy of Different Methods on VCGI andVCGII Dataset
表2 在VCGI和VCGII数据集上不同方法的准确率%
Notes: The bold values are the accuracy obtained by our method.
然而CNN-Multi和DNN-Multi都是首先分别提取图像和文本的特征然后再进行融合,不是共同地学习成对的图像-文本数据,而社交媒体上共现的图像-文本数据往往是存在语义概念相关的,若分别提取图像特征和文本特征后再进行特征融合,这会割裂图像与文本之间对应的语义关联.本文提出的方法是同时共同地学习图像-文本的共现数据,且效果也优于CNN-Multi和DNN-Multi,这表明在多模态情感分析任务上同时处理成对的图像-文本的共现数据是必要的.如表2所示,提出的方法在VCGI和VCGII数据集上相较对比方法均展示出更好的性能,说明提出的方法在相同领域不同背景的数据集下具有领域适应能力.
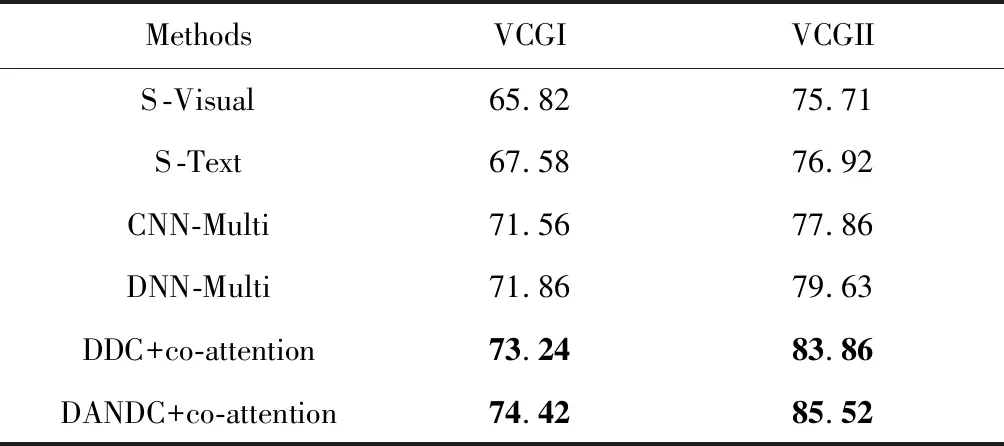
表3分别展示了本文方法和对比方法在MVSO-EN数据集和Flickr数据集上的实验结果.尽管MVSO-EN数据集和Flickr数据集都是来自于Flickr社交网站,但是它们数据集的构造方式略有不同,其中MVSO-EN数据集和VCG数据集的构造方式相同,则针对MVSO-EN数据集的实验评估,采取了与表2中VCG数据集同样的对比方式,且本文的方法DDC+co-attention和DANDC+co-attention都展示了优异的性能.
Table 3Accuracy of Different Methods on MVSO-EN andFlickr Dataset
表3 在MVSO-EN和Flickr数据集上不同方法的准确率%
Notes: The bold values are the accuracy obtained by our method.
此外,由于Flickr数据集的标签来自于人工标注,故没有图像的ANP信息,则在Flickr数据集上不能评估DANDC+co-attention的性能,表3中空白表示无实验数据.但是由于本文使用的Flickr数据集来自于人工标注,其标签相比更准确,同时为了证明本文提出的DDC+co-attention同样适用于三分类的目标,故针对Flickr数据集,在二分类目标和三分类目标上都进行了分类性能评估,其中在Flickr-2数据集上是为了评估二分类目标,而在Flickr-3数据集上是为了评估三分类目标,且在Flickr-2和Flickr-3这2个数据集上DDC+co-attention均较对比方法展示了更好的性能.
3.4 实验2: 局部模型效用评估
尽管表2和表3的实验已经展示了本文提出的方法可以达到更好的情感分类效果,但是在本文提出的层次化深度关联融合网络的模型中,不仅考虑了经过多模态深度多重判别性相关分析的优化而生成的最大相关的判别性视觉特征表示和判别性语义特征表示,还在多模态注意力的融合网络中序列化地研究了图像视觉特征和文本语义特征之间的协同关注(co-attention).为了探讨这2部分模型的设置对图像和文本融合的情感分类结果的贡献度以及合理性,则分别做实验来评估这2个部分的性能.
3.4.1 对比方法
首先,通过设定实验来评估多模态深度多重判别性相关分析的合理性.对比方法设置为:
1) DNN-S.利用DNN-Multi方法中的DNN网络结构分别提取图像和文本的特征,然后拼接特征向量输入softmax层进行情感分类.
2) DC-S.利用文献[17]中提出的深度相关性分析的方法,不同于文献[17]中的网络结构,而是利用本文提出的视觉模态特征提取网络和文本模态特征提取网络来共同提取图像和文本的最大相关的视觉和语义的映射特征,将图文映射特征融合后通过softmax层进行情感分类.
3) DDC-S.利用本文DDC的方法共同地提取图像和文本的最大相关的判别性视觉和语义的映射特征,将视觉和语义映射特征融合后通过softmax层进行情感分类.
4) DANDC-S.利用本文DANDC的方法共同地提取图像和文本的最大相关的判别性视觉和语义的映射特征,将视觉和语义映射特征融合后通过softmax层进行情感分类.
总之,前3组实验设置是为了评估简单的特征融合(DNN-S)、具有深度相关分析的特征映射(DC-S)、具有深度多重判别性相关分析的特征映射(DDC-S)这三者在情感分类上的性能差异,而DANDC-S是为了评估在深度多重判别性相关分析阶段,融入图像中层语义特征对分类结果的影响.
其次,通过设定实验来评估多模态协同注意力(co-attention)设置的合理性,对比方法设置为:
3.4.2 结果与讨论
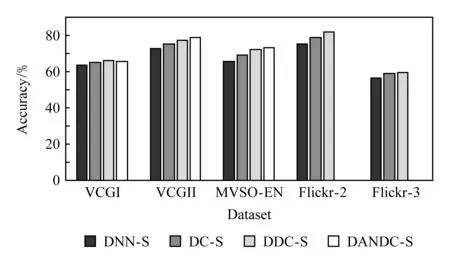
Fig. 4 Evaluate the performance of deep and discriminative correlation analysis on five datasets图4 在5个数据集上评估深度判别性相关分析的性能
图4的实验结果展示了在5个数据集上利用多模态深度多重判别性相关分析(DDC-S和DANDC-S)的分类性能均优于DNN-S和DC-S,这说明利用多重深度判别性相关分析来学习最大相关的判别性特征表示是可行且必要的.此外,在视觉模态上共同学习图像视觉特征和图像中层语义特征的DANDC-S在除了VCGI数据集外的所有数据集上的分类结果上均优于仅利用视觉特征的DDC-S.然而,在VCGI数据集上DANDC+co-attention的情感分类性能要优于DDC+co-attention,如表2所示.此外,在表3中的MVSO-EN数据集上,DANDC+co-attention的性能次优于DDC+co-attention,但是在多重深度判别性相关分析阶段DANDC-S的分类性能要优于DDC-S,如图4所示.这表明融入图像的中层语义特征(ANP)在一定程度上对多模态情感分类的性能是起积极作用的.
然后,进一步评估co-attention方法设置的合理性,本实验仅利用提出的DDC模型生成的最大相关的判别性视觉特征和判别性语义特征做基准,比较其与same-co-attention和co-attention-2的性能差异.如图5所示,在5个数据集上的对比实验均显示序列化的co-attention相比于非序列化的same-co-attention都取得了略好的情感分类效果,这说明先后序列化生成视觉的注意力和语义的注意力的设置有益于探测图像视觉和文本语义之间的深层内部关联.另外,为了探讨嵌套co-attention网络的性能,在5个数据集上也相应做了实验评估.如图5所示,在Flickr-2和Flickr-3数据集上的分类结果co-attention-2略优于co-attention,但在其他数据集上效果反而不如co-attention的性能.由于增加co-attention网络的迭代交互的次数,不仅会使模型变得更复杂,而且在实验中需要更多的训练时间.很显然,嵌套序列交互后的效果没有明显的提升甚至在几个数据集上反而下降,因此,实验设置中没有必要去设置更多嵌套co-attention层的模型.
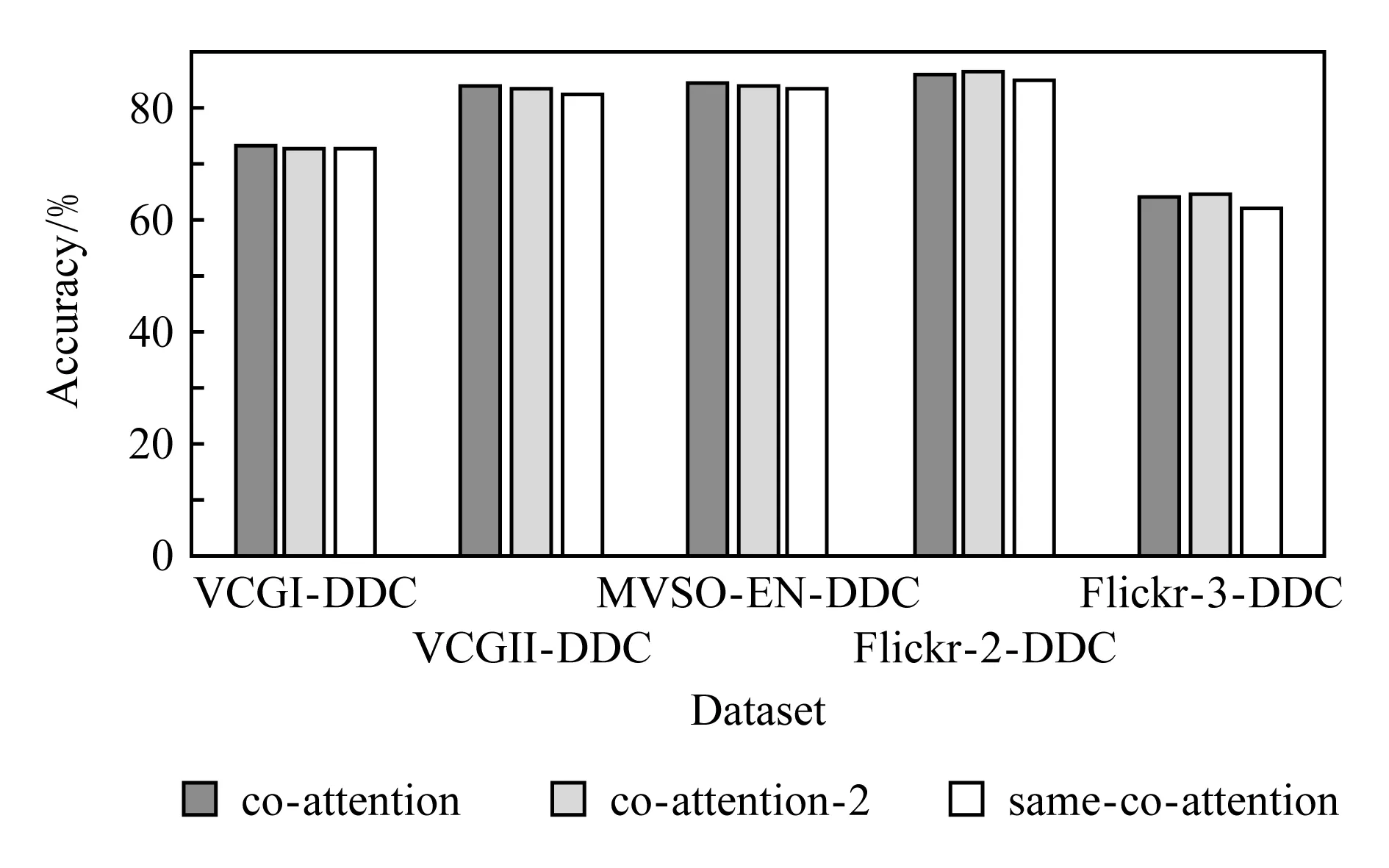
Fig. 5 Evaluate the performance of co-attention settings on five datasets图5 在5个数据集上评估co-attention设置的性能
4 总 结
近年来,多模态情感分析已经成为一个日益重要的研究热点,尤其在社交媒体大数据的环境下.本文提出一个新颖的层次化深度关联融合网络结构用于多模态情感分析.在提出的方法中,首先依赖提出的多模态深度多重判别性相关分析的模型共同学习最大相关的判别性视觉特征表示和判别性语义特征表示.基于这2种特征表示,进一步提出多模态注意力融合网络的情感分类模型,首先,序列化地生成语义的视觉注意力和视觉的语义注意力来交互视觉和语义,从而获得图像的和文本的更深层和更判别性的特征表示;然后,合并最新的图像视觉特征和文本语义特征后并通过全连接神经网络学习后再用于训练情感分类器.在5个真实数据集上已经评估了提出方法的有效性,且实验结果表明本文提出的层次化深度关联融合网络的图文媒体情感分析方法要优于其他相关的方法.
在未来的工作中将考虑不同的文本语言类型、图像的区域化语义,设计更好的多模态网络提取结构以及更合理的注意力网络模型用于情感分析,此外,还将研究更好的特征融合策略以进一步提高异构多模态特征融合的性能.
