基于自商图像和随机投影的人脸识别方法*
2019-06-25朱晶晶王进花
曹 洁, 朱晶晶, 李 伟, 王进花
(1.兰州理工大学 计算机与通信学院,甘肃 兰州 730050;2.兰州理工大学 电气工程与信息工程学院,甘肃 兰州 730050)
0 引 言
近年来,人脸识别因其友好性、非接触性成为最受人们关注的生物特征识别技术之一,在军事、经济、生活等领域发挥了重要的作用。由于环境的复杂多变,人脸识别系统受到各种自然及人为因素的影响,包括光照变化、姿态、表情及遮挡等。在诸多的干扰中,光照变化对人脸识别的影响尤为显著,为了解决光照问题,研究学者提出了诸多处理方法,大致可以分为三类[1]:光照归一化法、光照建模法以及光照不变特征提取法。光照归一化利用基本图像处理和信号处理技术对光照图像预处理,如直方图均衡化(histogram equalization,HE)[2],伽马校正,同态滤波等。尽管此类方法可以消除一定程度的光照影响,但当光照较为复杂时,处理效果难以令人满意。光照建模法通过不同光照下的人脸图像建立一个低维子空间来描述人脸,由于需要完备的训练样本集以及计算复杂度较高,限制了该类方法的应用。光照不变特征提取是指从图像中提取出受光照影响较小的特征表述人脸。目前光照人脸识别中的特征主要分为两类:一类着重研究鲁棒的视觉特征描述方法,如Gabor小波变换和LBP;另一类基于Retinex模型,将人脸图像视作光照分量和反射分量的乘积,通过去除处于低频的光照成分来获取人脸的内在本质,单尺度Retinex[3](single scale retinex,SSR)、多尺度Retinex(multi-scale retinex,MSR)、LTV(logarithmic total variation)[4]等均是基于此模型的。
自商图像(self quotient image,SQI)[5]法通过将原图像与平滑后的图像作商来消除人脸图像中的光照分量,因其简单及有效性成为光照人脸识别中的热点,基于此方法的改进也很多。文献[6]提出了一种动态形态学商图像方法,采用数学形态学操作来平滑原始图像以此估计光照亮度。但商图像对训练样本集的依赖很大,当训练样本较少时,识别性能随之下降。文献[7]将反锐化掩膜滤波与自商图像结合,先将原图像经过反锐化滤波处理,然后用SQI分离反射系数和光照分量。文献[8]通过多尺度下采样方式生成SQI,在提取边缘和细节的同时,降低计算复杂度。文献[9]将离散小波变换与SQI结合,先使用小波分析将人脸图像分成4个子带,增强垂直、水平和对角线边缘,然后利用直方图截断技术去除非常亮和非常暗的区域,提取SQI特征。文献[10]利用SQI对人脸图像进行处理,提取多区域LBP特征进行融合作为光照不变特征,来提高特征的鲁棒性。文献[11]设计了边缘弱化引导滤波器,利用边缘感知系数感知图像的边缘将图像自适应平滑,保留尽可能多的面部信息。上述所提到的方法均能在一定程度上去除光照影响,然而这些基于商图像的方法,都以去除光照分量以提取光照不变特征为目的,忽略了对特征进行选择,无法提高类别之间的鉴别性。
本文用SQI对图像进行预处理,利用线性判别分析构建初始样本空间,通过随机投影将样本投影至多个不同的子空间,以此丰富样本特征的完备性和鉴别性,通过最近邻分类器对样本进行分类,从而实现在光照变化情况下更加稳定和鲁棒的人脸识别。
1 算法的研究与实现
1.1 结合SQI和LDA的初始样本空间构造
Retinex模型将一幅图像I分为光照分量L和反射分量R两个部分,三者之间的关系可以表示为:I=L×R。其中,R对应高频分量(如边缘和纹理),为图像的本质特征,取决于物体的固有反射率和表面法向量;L对应低频分量,受外界环境影响。文献[5]通过式(1)得到的自商图像

(1)

图1为不同光照下的人脸图像与其对应的自商图像,对比可以发现,经过SQI处理后,光照对人脸图像的影响显著消除,人脸图像在不同光照下呈现出一定的稳定性,但处理后的图像整体亮度更加均匀。在去除光照分量时,SQI保留了相似度较高的阴影边缘,导致处理后的图像之间的相似度较高。

图1 SQI处理前后的图像
通过数据分析SQI方法处理后的不同个体图像及其相似度,可以发现,不同类样本之间的相似度较高,均大于90 %。基于SQI的方法能够很好地去除人脸图像中的光照分量,与此同时也增加了图像之间的相似性,这导致不同类别之间的鉴别性减少,在一定程度上,给图像的正确分类带来了不利影响。
作为分类前的预处理,特征选择不仅可以去除对识别作用不大的冗余信息,降低数据的维数,提高运算效率,还能够增加不同类别间的鉴别性,从而实现更好的分类。线性判别分析(linear discriminat analysis,LDA)[12]作为特征选择的一种方法,通过最大化类间散度和类内散度的比值来寻找最优的投影平面,使得样本在该空间具有更好的鉴别性和可分离性。LDA通过Fisher准则找到最优投影,Fisher准则函数为
(2)
式中Sb和Sw分别为类间散度矩阵和类内散度矩阵
(3)
(4)
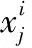
利用特征分解来求解最佳投影矩阵Wopt,当类内散度矩阵Sw为非奇异时,Wopt满足下式的解
SbWi=λiSwWi
(5)
因此,本文选择利用LDA对自商图像进行特征选择,通过寻找最优投影矩阵,最大化类间散度和类内散度之比,来构建初始样本空间。
经过上述处理之后,得到的训练样本特征用Xopt表示,Xopt=[X1,X2,…,Xc]∈Rp×l,其中,Xi=[xi,1,xi,2,…,xi,n]∈Rp×n为第ci类样本的特征,ci=1,2,…c,p为特征维数,训练样本总数为l=c×n。
1.2 迭代随机投影和最近邻结合的分类算法
为了充分挖掘样本特征的潜在信息,采用迭代随机投影的方法来生成不同的样本子空间,并用最近邻分类器进行分类。随机投影(random projection,RP)[13]在降低数据维数的同时,能够保持数据的结构特性,而且投影矩阵随机产生,独立于原始数据样本,是降维和特征提取的有效手段。随机投影的理论基础为JL(Johnson-Lindenstrauss)引理。
JL引理表示任意n的维样本集可以通过随机矩阵R∈Rd×n,映射至d维子空间。文献[14]指出如果R是标准正交化矩阵,经随机投影变换后的数据可以保留原始数据的统计特性。将训练样本特征投影到各个投影空间,由于随机投影后的样本能够保持原始样本间的关系,所以,仍然以欧氏距离作为分类的标准。本文利用文献[14]的方法构造随机投影矩阵。设置迭代次数的最大值为Tm,Tm≥2,定义第T次投影的随机矩阵为RT,训练样本Xopt经RT投影后对应的特征为XT
XT=RTXopt=[1,2,…,c]
(6)
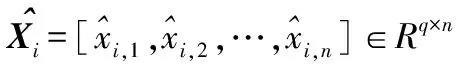
YT=RTYopt
(7)
计算测试样本和训练样本之间的欧氏距离,最小欧式距离对应的类别即为测试样本所属的类。如两次投影后,测试样本所属为同一类,即判定测试样本为此类;否则将测试样本划分为与其欧氏距离最小的样本所属的类。
1.3 算法实现
1)采用SQI对人脸图像进行光照归一化处理,得到训练样本X和测试样本Y;
2)训练样X本和测试样本Y均由LDA最优化得到Xopt和Yopt;
3)设置最大迭代次数Tm,初始迭代值T=1,类别C0=0;
4)构造随机矩阵RT,训练样本集和测试样本集分别由式(6)和式(7)得到XT和YT;
5)定义第T次迭代投影时,测试样本和训练样本之间的欧氏距离为Di(YT,i)=‖YT-i‖2,i=1,2,…,c,定义DT为欧氏距离最小的值,为最小距离DT对应的训练样本的类别;
6)如果CT=CT-1或者T=Tm,迭代结束,输出样本Y的类别为CT;否则,T=T+1,返回步骤(4),进行下一次随机投影。
2 实验结果与分析
2.1 人脸库说明
Yale B[15]人脸库包含10个人脸的图像,每个人有9种不同的姿势,每个姿势下有64种不同的光照条件。根据光照和相机之间的角度θ,这些图像可分为5个子集:子集1(0°<θ<12°),子集2(13°<θ<25°),子集3(26°<θ<50°),子集4(51°<θ<77°),子集5(78°<θ<90°)。在实验中选取正面人脸图像作为实验集,每人64张包含光照变化的图像,每张人脸图像都被裁剪为192像素×168像素大小。
AR[16]人脸库包含126个人,包含表情变化、光照变化以及遮挡等共4 000余张图像。在实验中选取部分图像作为实验集,共有100个人,每人14张包含表情及光照变化的图像,每张人脸图像都被裁剪为120像素×165像素大小。
实验中设置的最大迭代次数Tm=5。为了评估算法的性能,本文实验对比了基于Retinex理论的方法(SSR[3],LTV[4])以及基于商图像的方法(SQI[5],MQI[6])。为了更好地评估算法性能,实验对比了两种常见的光照处理方法(HE[2]和LT[17]),以下实验均选择以欧氏距离为分类标准的最近邻分类器进行分类。所有实验均在Intel Core I5,2.6 GHz CPU,4G RAM,Windows 7操作系统的计算机上进行,采用MATLAB R2014a实现仿真测试。
2.2 Yale B库上的实验结果与分析
实验中选取子集1作为训练样本集,其余的几个子集作为测试集。图2为不同光照条件下的原始图像与采用不同方法处理之后的图像,从图中可以看出,HE和LT在非极端光照下可以取得较好的效果,当光照条件较为恶劣时,处理效果不佳;SSR和LTV可以处理极端光照,但处理后的图片损失了很多细节信息;MQI,SQI对人脸细节信息保留较好,但处理后的图片包含较多的阴影,容易对识别的准确性产生不良的影响。
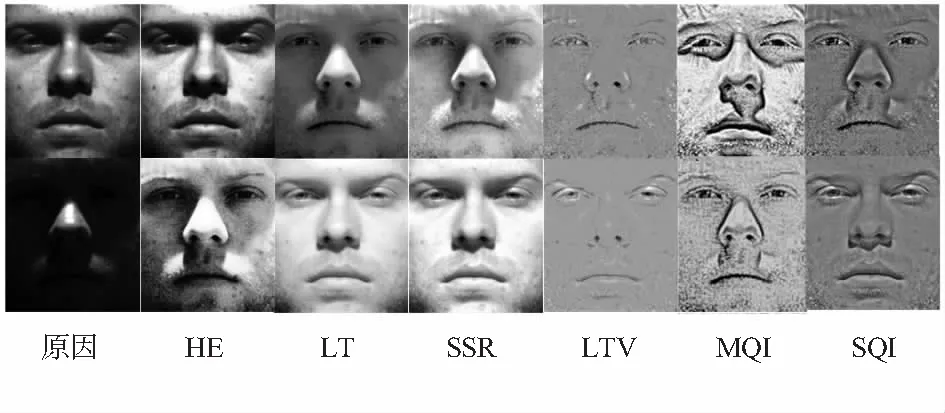
图2 原始图像及不同方法处理后结果
表1为不同算法在Yale B人脸库中不同子集的识别率。在子集2中,由于光照相对均匀的,光照变化对人脸识别的影响不是很大,各个算法的识别率均很高。随着光照恶劣程度的加剧,不同算法处理光照的能力显示出差别,其中,HE和LT的识别率下降明显高于其他几种算法。

表1 Yale B库上的识别率 %
基于商图像的方法在极端光照下,识别准确率能够保持在90 %以上。本文算法结合LDA和SQI构造初始样本空间,将类间散度和类内散度之比最大化,使样本间的鉴别性增加,具有良好的可分离性,更易分类。即使在光照最为恶劣的子集5中,本文算法的识别率高于SQI算法6.6 %,因此,在不同光照的子集下识别率均高于其他算法。
2.3 AR库上的实验结果与分析
AR库上,随机选取每人2~7张图片作为训练样本,剩余图片作为测试样本进行实验。AR人脸库中样本的类数相对较多,如果特征之间的鉴别性不够强,那么产生错误分类的概率会增大,这种情况下,选取具有鉴别性的特征对分类的准确性来说尤为重要。
图3为不同算法在AR子集上的识别率。本文方法通过LDA和随机投影,样本的鉴别性增加,从而使样本分类的准确性提高。因此,在相同训练样本数的前提下,本文算法的识别率高于其他对比算法。
在样本分类前,提取到完备的样本特征对分类的准确率有重要的作用。随着训练样本数的增加,特征的完备性增加,各个算法的识别率均有上升的趋势。在训练样本较少时,由于不能充分提取具有足够鉴别性的样本特征,对比的几种算法识别率均不高。而本文算法采用多次随机投影,挖掘出样本的潜在本质特征,因此,当训练样本较少时,本文算法依然能取得较高的识别率。
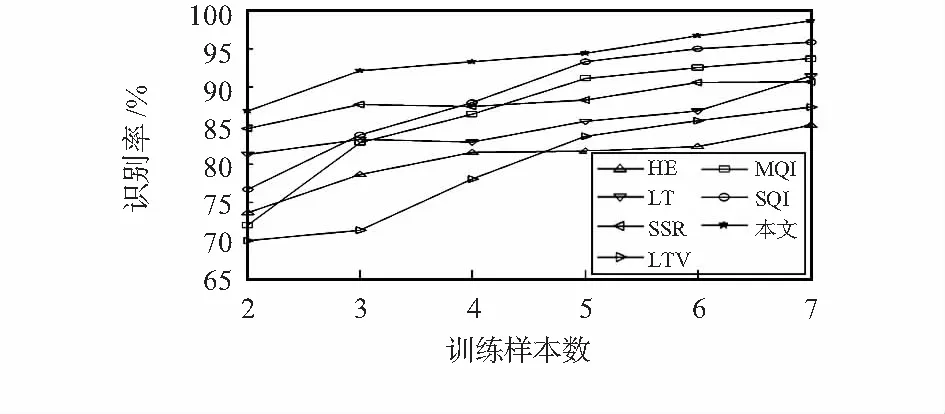
图3 AR人脸库上的识别率
3 结束语
自商图像算法能够很好地处理光照,但处理后的图像间相似性较高。本文采用自商图像和随机投影相结合的方法,利用多次随机投影将特征样本投影到各个不同的子空间,充分挖掘样本的潜在信息,在提取光照不变量的用时,增加了样本之间的鉴别性。实验结果表明:与其他经典光照处理方法相比,本文方法在不同的人脸库上均能取得不错的识别率。即使在训练样本较少的情况下,经过多次随机投影,依然能选择出具有鉴别性的特征,从而取得更高的识别率。
