长三角供应链金融的发展现状和风险控制研究
2019-06-06
(重庆大学 重庆 400000)
一、长三角供应链金融信用风险现状分析
在国内金融发展仍不完善的大背景下,长三角商业银行在内的大多国内银行对供应链金融的引入多少存在着盲目性。为了抢占客户,对不管何种信用水平的新老客户都趋之若鹜。这种盈利模式势必容易出现拉高授信额度,降低门槛限制,减弱审查力度的现象,致使银行客户资源鱼龙混杂,随时处于被骗贷的风险之中。
在供应链金融风险的监管方面,长三角大部分银行尚处于传统信用风险评估阶段向现代化风险管理阶段转变的过渡期,这无疑限制着供应链金融市场的发展空间。
二、长三角供应链金融信用风险logistic模型测度
(一)供应链金融信用风险评价体系设计
基于前人研究和数据获得的便利准确性构建指标体系,选择指标如下:X1每股收益;X2净资产收益率;X3净利率;X4毛利率;X5营业利润率;X6应收账款周转率;X7存货周转率;X8流动比率;X9总资产周转率;X10资产负债率;X11现金流动负债比;X12应收款项增长率;X13每股经营性现金流;X14现金比率;X15净利润现金含量。
(二)数据选取与来源
本文选取三年前的财务指标数据作为模型回归和验证的测试数据。模型所用样本采用沪深两市2012~2015年间经营正常的非“ST”公司10家和失败的“*ST”公司10家。涉及制造、零售等行业,基本都为长三角地区供应链中小企业,并被平均分为估计样本和测试样本。估计样本由其中来自长三角地区的5家“*ST”和5家非“ST”企业组成,其财务比率用来估计logistic方程的回归系数。
本文选用各个上市公司2012年的财务比率值作为原始数据,来源于“证劵之星”网站和“个股宝典”资料中提供的年度财务报表及业绩预告。
(三)主成分logistic模型的求解
1.主成分分析。运行SPSS19.0,输入估计样本公司的相应数据结果如表1所示。
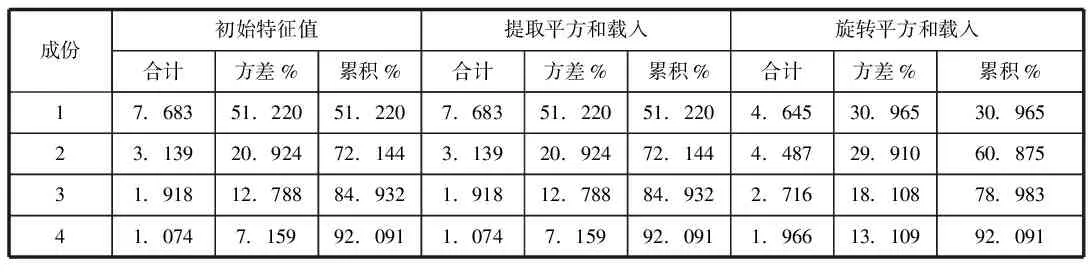
表1 主成分分析解释的总方差统计表
表1中,各成分中初始特征根大于等于1的值分别为7.683、3.139、1.918、1.074,且四者对应成分的累积贡献率达到了92.091%,符合主成分的指标要求。同时可知4个主成分变量分别解释了原指标变量的51.22%、20.924%、12.788%、7.159%的信息,较完整地保留了原有数据的信息。
2.主成分得分计算。按照主成分分析和因子数据正交旋转的结果,得到各因子与各原始财务指标函数关系如下:
Y1=0.2828SX1+0.2196SX2+…+0.3392SX14-0.0525SX15
(1)
Y2=0.3283SX1+0.4032SX2+…+0.1185SX14+0.0633SX15
(2)
Y3=-0.0878SX1-0.0668SX2+…+0.1336SX14-0.1013SX15
(3)
Y4=-0.0961SX1-0.1376SX2+…-0.1058SX14+0.9165SX15
(4)
上式中,标准化指标数据SXi的系数由因子载荷矩阵中的权值与对应特征根的平方根相除所得。
主成分Y1承载着代表公司短期债务偿还能力的X1、X8、X11和X14较多的信息,可称其为偿债因子;主成分Y2承载着代表企业获利能力的X2、X3、X4和X5较多的信息,由于企业的盈利能力强弱跟它的运营水平高低息息相关,故可称Y2为运营因子;主成分Y3承载着表征公司成长潜能和进步空间的X6、X7和X12较多的信息,可称其为成长因子;主成分Y4承载着表征公司现金流活力的X13、X15较多的信息,可称其为现金流因子。
3.二元logistic回归分析。本文以三年前的财务指标数据作为判断或预测公司贷款违约或非违约的指标,即自变量。因变量以三年来经营正常的公司为贷款非违约状态,以三年来经营失败的公司为贷款违约的状态。也就是Y1~Y4为自变量,违约概率P为因变量代入二元logistic模型进行回归。设分类临界值为0.5,通过SPSS 19.0获得的迭代结果如表2所示。
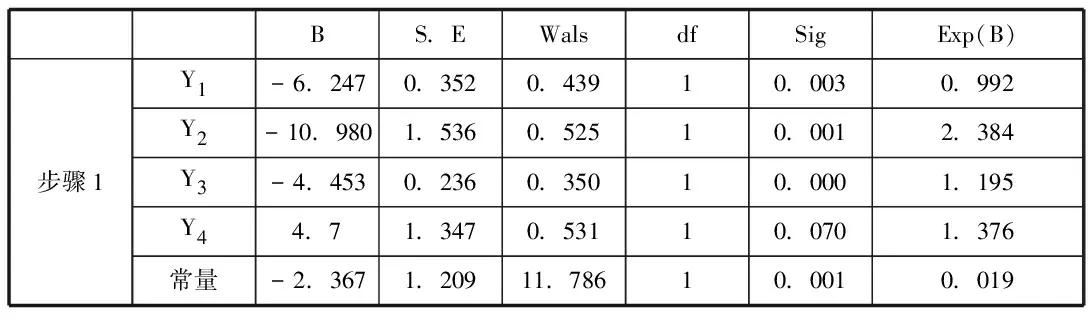
表2 回归分析结果
3.模型系数综合检验。同时得到模型系数的综合检验结果,见表3。
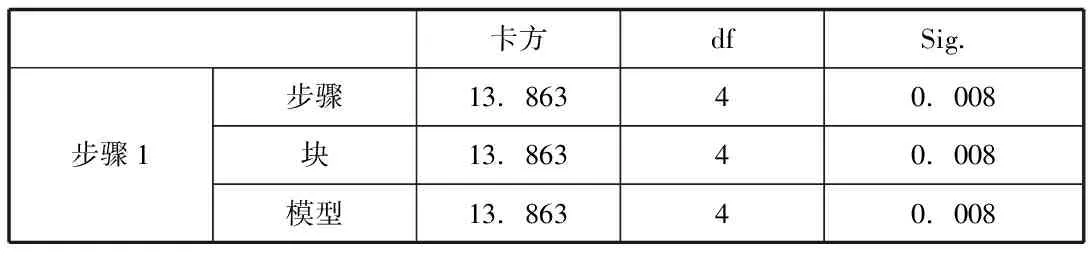
表3 模型系数的综合检验
p值为0.008,小于0.05,故该检验通过。
综上,估计的logistic回归模型如下:
Z=-2.367-6.247Y1-10.98Y2-4.453Y3+4.7Y4
(5)
(6)
式(6)中的P表征着供应链中融资企业的信用风险。
(四)模型验证
本文以其他5家“*ST”和5家非“ST”公司为测试样本验证模型预测的准确性。将每个上市公司的各项财务指标代入最终的logistic模型,对每个公司的违约情况进行预测。
预测结果显示,观测值P=0有5个(经营正常),相应的预判值全部是P=0,预判准确率为100%;观测值P=1有5个(经营失败),相应的预判值有4个P=1,1个P=0,预判失败一例,预判准确率为80%。总体来看,全部10个样本有9个预判准确,1个预判失败,总的预判准确率为90%,表明该模型是可行并且有效的。
三、结论和建议
(1)依据企业的财务数据构建风险预测模型是可行的,基于主成分和Logistic回归的预测模型具有良好的准确率。
(2)商业银行必须认清供应链金融的行业特殊性,在选择供应链时就有做到选好供应链、强化准入标准、完善评价体系和评估模型。
(3)建立恰当的信用风险评价模型和风险预测模型,及时对风险进行预测减少坏账损失。
