应用半监督生成对抗网络预测 临床试验中严重不良事件
2019-06-06YongCai
Yong Cai
随着深度学习技术的突破,以及大数据时代到来,深层神经网络的相关应用在在各行各业中逐渐普及[1]。深度学习在模式识别,事件预测和点到点的自动化方面取得了突破性的成绩。但是和深层网络相关的模型在性能上很大程度依赖于是否存在大量有标识的学习样本。在小样本空间中,深层网络的实际应用非常困难,很难训练出相对精确的预测模型。在医疗行业中,这一现象尤为明显。如何克服 样本数量的局限,利用数据库中大量未标识数据来帮助训练和提高预测模型的精准性是医疗行业中长期以来的一个重要话题。比方说,在罕见疾病的诊断与预测上,确诊与标识的罕见病人数非常少,绝大部分患者在训练数据中都是未标识的[2]。例如在2018年国家卫生和环境卫生委员会等五部门联合制定的《第一批罕见病目录》中遗传性血管性水肿确诊率仅为1/50 000[3]。很多患者在得病初期都是没有征兆的,加上医生对罕见疾病的陌生,导致这部分病人的延迟诊断和治疗。在数据库中,存在很多这些类似的未标识样本。传统方法很难有效利用这些未标识病人的诊断和治疗历史来建模。
我们主要探讨使用最新开发的半监督生成对抗网络预测临床药物试验中产生严重不良事件(SAE)的问题。临床试验中的不良事件是指受事病人在使用药物后出现非期望的医疗事件。不良事件的发生对受试者和药物研发单位会造成灾难性的后果。如何预测和避免严重不良事件发生是一个重要的研究话题。我们主要从数据挖掘和模型角度来探讨这个问题。从我们采集到的数据,可以观测到参与临床试验的医生发生不良事件的历史记录,实验的药物化学结构,所治疗病人的诊疗历史。和以上提到的罕见疾病相类似,参预药物临床试验的医生的样本数又相对较少,其中发生严重不良事件更是罕见。小样本再加上数据极端不均衡性,给预测模型的精确性带来极大困难。另一方面,我们又观测到了大量未参与临床试验的医生和病人的数据。这些病人和相关医生含有丰富的诊疗历史信息,我们能否利用这些来帮助我们训练小样本不良事件的预测模型呢?
最近,在人工智能领域开发出的半监督生成对抗网络正是适合解决小标识样本但是存在未标识大样本的机器学习问题[4-5]。我们前面提到的预测临床药物试验中不良事件正好符合这一类问题的特性。实验结果显示,半监督生成对抗网络显著提高了不良事件预测的准确性。在以下文章中,我们首先介绍一下什么是半监督学习,以及半监督学习所需要的基本假定条件。然后我们从原生的生成对抗网络构架开始,拓展到半监督生成对抗网络模型。随后我们介绍用于实验的临床试验不良事件数据。根据数据特性,我们设计了特定的损失函数用于训练半监督生成对抗网络。我们还会讨论与之相呼应的模型训练技巧。最后,展现实验结果和与之相应的结论。
1 半监督学习
处理小样本标识数据主要有两种方法,一种是转移学习[6],另一种就是半监督学习[7]。本文主要讨论半监督学习方向的模型。在训练用的数据中,有标识的样本是指目标变量在数据集中时观测得到的。所谓标识可以是指病人是否有某种疾病,不良事件是否发生等等。如果只用有标识的数据来建模,这种模型称之为监督学习模型。如果在数据中有一部分样本是没有标识的,我们用有标识的样本再加上这些未标识的来建模就是半监督学习了。在现实世界中,很多收集来的数据都只是部分有标识。那些未标识的样本对半监督学习预测模型会不会有帮助呢?这取决于以下三个基本假设条件其中之一是否成立:连续性假设,丛生性假设和多样性假设。简单来说,这些假设条件规定了标识和未标识样本之间的决定边界是连续的,相似样本是丛生和聚类的。多样性假设保证了标识的产生是可以通过一个相对小的数据空间来实现的。用临床药物试验的例子来说,产生严重不良事件的病人之间是有相似性的,同时参与实验和未参与实验的医生之间也有相似性。而且我们可以认为严重不良事件事件是由数据库中一个相对较小的特征空间决定和产生的。基于这些条件,用未标识样本学习会对预测临床药物试验中模型有所帮助。
2 半监督生成对抗网络模型
2.1 生成对抗网络
生成对抗网络(GAN)是当下热门的研究重点[8]。Goodfellow 在1994年NIPS 会议上提出最初的生成对抗网络构架,随后几年内,学术界不断提出和开发了各种形式的相关网络拓展和应用。基本的生成对抗网络主要由两部分组成:生成模型和判别模型(图1)。生成模型从随机数开始产生虚拟的样本,比方说虚拟图像。判别模型判断输入的样本是虚拟的还是真实的。这两个模型的优化目标是截然相对的,生成模型要生成判别模型无法辨别真伪的样本,判别模型要能成功识别样本的真伪。在训练过程中这两个模型不断地通过对抗达到优化。训练完成后,原生的生成对抗网络会丢弃判别模型,而只保留生成模型。因为最初提出的生成对抗网络主要是为了产生一个好的生成器。而对于我们预测模型来说,目标恰恰相反,我们要保留和使用优化好的判别模型。下面我们谈一谈半监督生成对抗网络的构架。
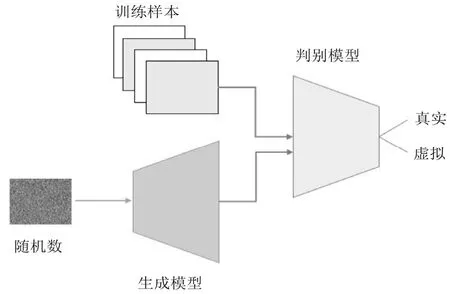
图1 生成对抗网络构架
2.2 半监督生成对抗网络构架
半监督生成对抗网络是从生成对抗网络演化而来。半监督生成对抗网会读取三种数据:有标识的样本数据L,无标识的样本数据U,和从生成模型生成的虚拟数据G(图2)。和原始的生成对抗网络不同的是,在半监督生成对抗网中的判别模型不但要识别数据真伪,而且要判别数据类别。在图2的示意图中,判别模型要区分k 类和虚拟样本。在我们的具体实验中,判别模型要判断读取的样本数据是否真实,以及是否有严重不良事件发生。
在我们构建的半监督生成对抗网络中,用于训练判别模型的损失函数由三部分组成:LD=LL+LU+LG,其中
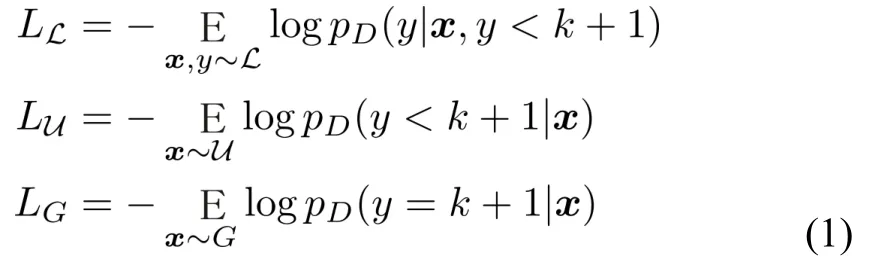
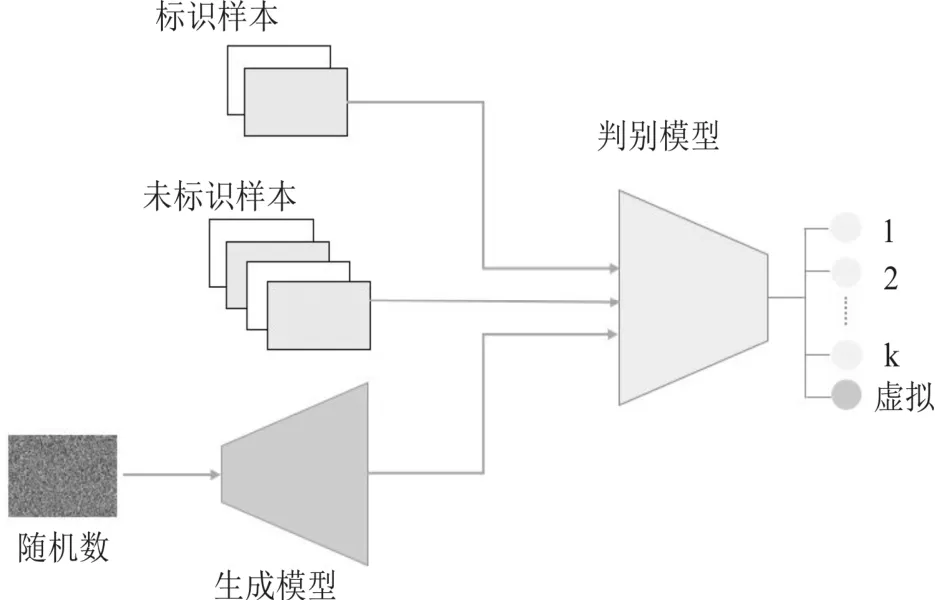
图2 半监督生成对抗网络构架
LL 代表交叉熵值损失项,这项用来使标识数据分类错误最小化。LU代表未标识样本的损失项,这项用来最大程度分辨数据是否是未标识样本。LG用来最大程度区分数据是否虚拟样本。
我们发现如果仅用以上的损失项来训练半监督生成对抗网络模型,性能并不理想。原因就是半监督生成对抗网络本身难以训练。主要的困难包括:模式扁平(mode collapsing),难收敛性和训练缓慢。为提高模型性能和精确性,我们需要使用一些额外的训练技巧[9]。在生成模型中,我们加入了以下生成损失项LG=Lfm+Lpt。Lfm和Lpt分别代表特征值匹配(feature mapping)和脱离项(pull away term)。其中,特征值匹配(2)迫使生成模型生成样本和未标识样本有相类似的特征空间[9]。(3)式的第一部分用余弦相似函数确保生成不同的虚拟样本,第二部分确保生成样本和真实样本之间不完全一样(这就是3 式称为“脱离项”的原因)。性能好的半监督生成对抗网络需要有一个“不好”的生成器[10],即生成一些和有标识样本互补的虚拟样本。这项主要帮助生成一些标识空间分布之外的样本。
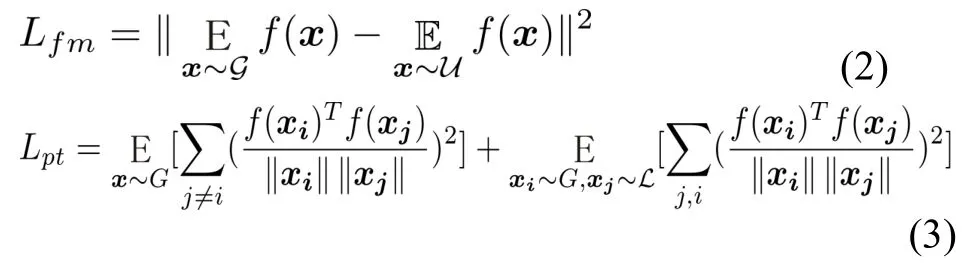
生成模型和判别模型都由深层网络构成,在训练中我们使用了常用的的深层网络技巧:权重正态化(weight normalization)和退出(dropout)。
3 数据介绍
我们提取了2008—2016年IQVIA 临床药物实验数据,其中包括药物严重不良事件的报告。同时我们提取IQVIA 美国的医生KPI 数据和病人KPI数据。从IQVIA 数据我们得到了医生专业、治疗处方特性、病人数、治疗病人的病情复杂度等数据变量;病人方面得到了病人的基本生理、并发症、治疗历史、医嘱遵从程度等特征数据。此外,我们还下载了美国政府公开的临床数据,药物结构数据(Tox21 和PubChem)。和IQVIA 数据融合后,我们得到了药物分子、结构特性、毒性等特征数据。最终的数据含有217 个可以用于预测的变量,和241 070 个训练样本。训练样本中包括72 997 个有标识的样本和168 073 个未标识样本。在标识样本中,1779 个样本观测到严重不良反应。正负标识比率约为2.4%。
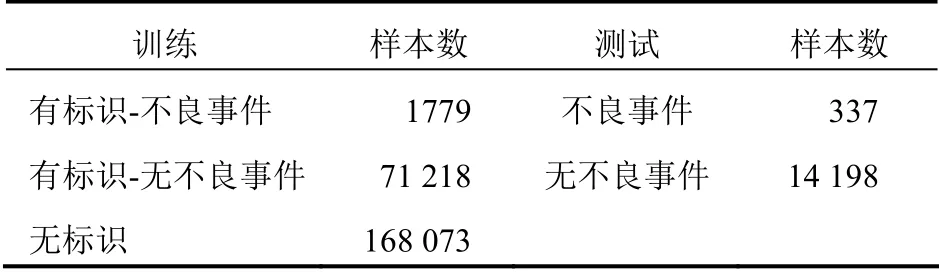
表1 训练和测试样本分布
由于正负标识的严重不均衡性,通常使用的ROC 曲线不能公平测量试验结果。所以我们采用PR(Precision-Recall)曲线中的PR-AUC 来作为模型衡量指标。
4 实验结果
使用以上的生成的实验数据,我们用章节3.2 中提出的半监督生成对抗网络模型来训练和预测临床中的严重不良事件。同时在基准模型中我们使用了逻辑回归,随机森林算法(Random Forest)和深层神经网络(Deep NeuralNets)模型作为结果比较。基准模型中只能使用有标识的数据。其中深层神经网络使用了和半监督生成对抗网络中的判别模型相同的网络构架。
最终,半监督生成对抗网络(图3中标识为SGAN)得到34.4%的PR-AUC。基准模型中,逻辑回归得到20.4%的PR-AUC随机森林算法得到22.7%的PR-AUC,深层神经网络有27.8%。我们提出的半监督生成对抗网络相对于基准模型中表现最好的深层神经网络提高了24%的准确率。尤其是在PR 曲线中召回(recall)小的区间,半监督生成对抗网络的预测性能明显优于基准模型。
5 讨论
在大数据时代,总体数据特征呈现多样性和丰富性。但是在医疗领域,一旦细化到特定专业,比方说癌症,罕见病等等,目标数据就变得相对稀疏。这就给建模、分析、预测带来很多困难。从另一方面来看,整个专业总体上产生了前所未有的大数据。如何链接、融合和使用这些看似相关但又并不直接相关的数据是一个非常有价值研究话题。

图3 半监督生成对抗网络和其他常用基准模型的PR-AUC 衡量比较
我们提出了半监督生成对抗网络模型来使用用未标识数据达到帮助训练和提高预测准确性的方法。在临床实验中预测不良事件的具体案例中,新 方法达到提高预测精准度的预期效果。从这个案例的结果来看,未标识数据确实给模型训练带来了额外信息,并且产生了和真实样本互补的虚拟样本,从而提高了模型的可训练性和预测的准确性。当然,半监督生成对抗网络有其局限性,其中之一就是比较难以训练。一个良好的预测模型,必须通过调试不同的损失函数来实现。我们在网络构架中使用了特征值匹配和脱离项,达到了预期的效果。在将来的研究中,应该会有更好的模型构架和训练技巧来进一步体高性能。另外,我们希望看到半监督生成对抗网络能够更多应用在其他领域。我们期待有更多更新的方法来有效利用大数据时代丰富数据。
