基于网格山脊点的异常点检测∗
2019-06-01卓勤政马玲玲
戴 楠 严 悍 卓勤政 马玲玲
(南京理工大学计算机科学与技术学院 南京 210094)
1 引言
随着信息技术的快速发展,各个领域内已经积累了大量的复杂数据,并且数据的规模也是成爆炸式的增长。收集和检测出有价值的信息是目前数据处理的一个重要的模块。数据集的异常点检测是数据挖掘领域内一个举足轻重的研究方向,它的目的在于消除数据内的噪音或者是挖掘出有价值的知识。Hawkins的定义[1]揭示了异常点的本质:“异常点的表现与其他点如此不同,不禁让人怀疑它是由不同机制产生的”。目前,异常点检测已经在电子商务诈骗、信用卡欺诈、网络入侵检测分析等邻域得到了广泛应用。现有的离群点检测方法大致包括:1)基于深度的方法[2];2)基于分布的方法[3];3)基于密度的方法[4];4)基于距离的方法[5]。目前数据集的异常点检测中比较常用的算法是基于密度的局部离群点检测算法LOF[4]。
2 关于GridLOF算法的研究
由于LOF算法需要计算数据集中各个点之间的距离,所以其时间复杂度非常高,耗费的时间也非常大。为了解决上述问题,提出了将网格的聚类算法和LOF算法集合起来,提出了一个GridLOF算法。GridLOF算法首先利用网格方法将数据集中部分的聚类数据点去除。仅仅考虑处于边界网格的数据点。计算它们的LOF值。这样就可以减少算法运算时间。
GridLOF算法寻找边界网格时,仅仅是粗略的对空间内数据集进行划分,采用网格内部所包含的点作为该区域的密度,并没有考虑到空间内一定邻域内点间的相互间的影响。因此GridLOF算法选取的边界网格的数据的往往包涵大量正常点并且受网格宽度的影响,增加了不必要的计算量。
本文借鉴了GridLOF算法中利用网格对数据点进行分类[6]的思想。提出一种基于网格山脊点的LOF算法。该方法能更准确、快速地找到边界网格中的数据点,并且降低了网格宽度对边界网格区域选取的影响,有效地降低了LOF算法的复杂度。
3 相关概念
定义1网格单元[7~9]:给定一个d维的数据集,其属性(A1,A2,…,Ad)都是有界的,将数据第i维划分成ni个小段,由第i维划分的小段组成的集合记为Si,那么数据空间被笛卡尔集(s1*s2*s3…*sd)划分为s1*s2*s3…*sd个网格单元。用每一小段在该维上的位置构成的d维向量来唯一标识这个网格单元。例如,网格单元u可记为(u1,u2,u3,…ud)。
定义2网格山脊点:指在空间内各个相邻网格间的交点且网格山脊点高度大于0。如图1在二维空间内点A就是网格P,N,Q,M四个网格的交点。即空间内一个网格山脊点。
定义3网格山脊点的高度:在一个i维空间内,一个单元网格的相邻的网格山脊点有2i个,记作并且单元网格空间内一点a到该网格山脊点p的距离为dis[ap],因此点a到所有网格山脊点的最后每个点映射到网格山脊点的高度为
如图1所示在二维空间内,单元网格M的四个相 邻 的 网 格 山 脊 点 A(xa,ya),B(xb,yb) ,C(xc,yc),D(xd,yd),且网格单元内一点 a(x,y)。该点映射网格相邻点的高度为
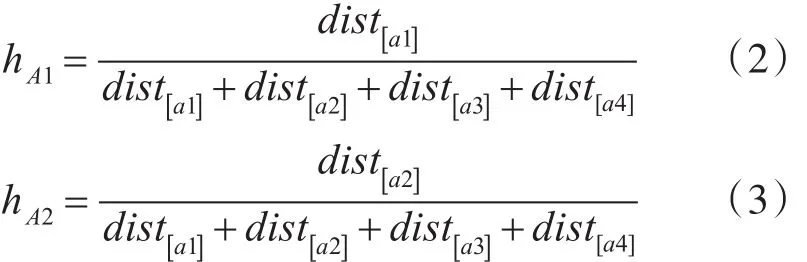

定义4网格山脊相邻点:指的是与该网格山脊点相聚只有一个网格单元长度的网格山脊点。图1中网格山脊点A的相邻点有网格山脊点B,C,E,F。
定义5山脊点邻域:指的是与网格山脊点[10~12]相接壤的网格单元所构成的区域。在图1中山脊点A的邻域为网格单元P,N,Q,M组成的区域。
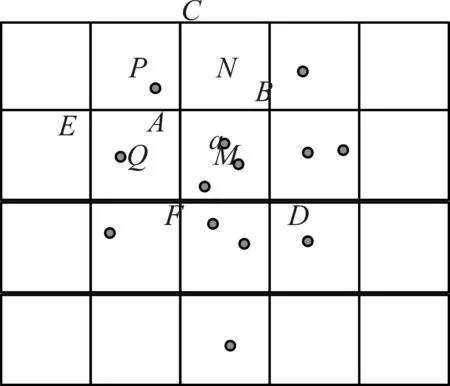
图1 某区域网格划分图
4 基于网格山脊点的异常点检测算法
4.1 算法思想
该算法的基本思想主要是:对任意空间分布的数据集[13],每一维度上取较小的且相同的网格单元长度,将空间划分为网格单元空间。遍历所有数据集中的点,将点划分到所有的网格单元中,计算出所有网格山脊点的高度,和每个网格山脊点对应的邻域。根据网格山脊点的高度对网格山脊点进行升序排序。取前某阈值的网格山脊点邻域中所包涵的所有数据集点作为LOF算法要检测数据测试点。最后采用LOF计算出数据测试点的异常程度值。
4.2 算法描述
输入:数据集D,较小的网格单元长度m,阈值p;输出:数据集D中测试点的异常程度值
基于网格山脊点的异常点检测算法描述:
步骤1:对任意空间数据集按照网格单元长度m进行划分。
步骤2:依据网格山脊点高度定义,计算出每个网格山脊点的高度和每一个网格山脊点所对应的邻域。然后基于网格山脊点高度,对网格山脊点进行升序排序,小于阈值p所对应的网格山脊点邻域所包涵的数据点为测试点。
步骤3:对选取出的测试点采用基于密度LOF算法来计算其异常程度值。
5 实验结果及分析
实验环境:Window 10,处理器:Intel(R)Core(TM)i7-6500U CPU@2.5GHz 2.59GHz
为了验证算法的可行性和精确度,笔者做了大量的实验,在此仅仅举一个具有代表性的给予具体说明。并与常用的LOF算法和GridLOF算法进行比较。
在现实数据集中,大部分数据是满足正态分布,如图2显示的是在二维空间满足某两种不同正态分布的数据集且相互间存在关联,数据集的规模是8000。
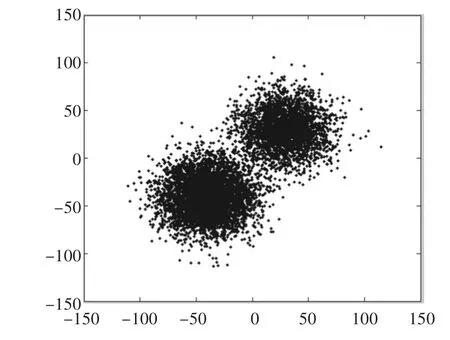
图2 二维空间正态分布数据
采用常用的LOF算法[14]对图2中二维正态分布的数据集进行检测。现实数据集中异常点的数量占非常小的一部分,所以本实验中取异常程度排在前150的数据集点作为异常点处理。如图3为异常点的分布图。图4所示异常点和正常点显示,其中星型代表异常点,圆形为正常点。
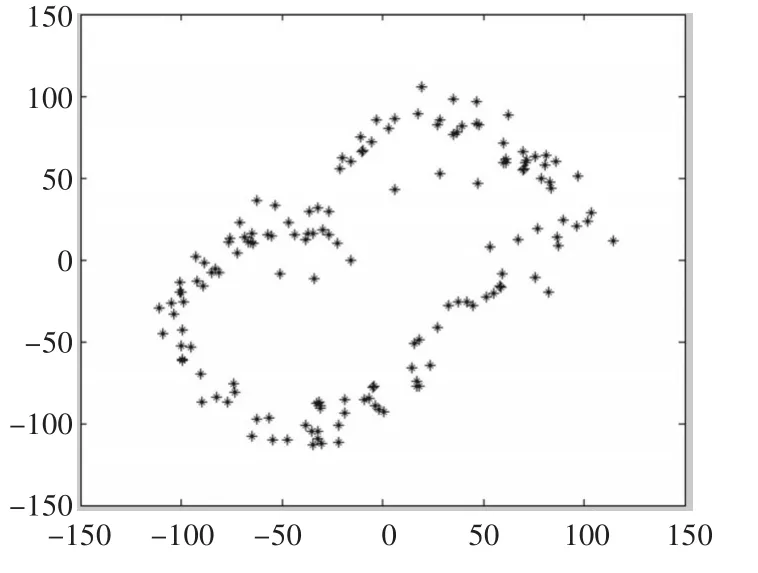
图3 LOF算法检测出异常点
采用GridLOF和基于网格山脊点的异常值检测算法对图2二维正态分布数据集进行检测。为了保证GridLOF算法和基于网格山脊点的异常点检测算法的有效性,要求该两种算法计算出的数据集的异常点与LOF算法计算的数据集异常点相同的数量要在140(总数150个异常点)以上才能算该算法有效。
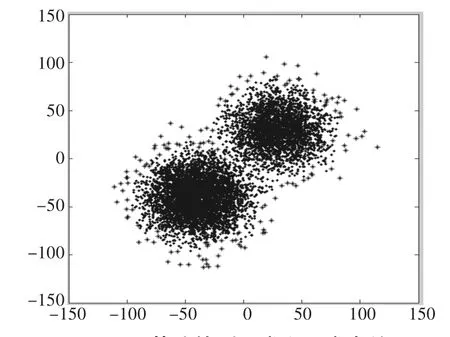
图4 LOF算法检测异常和正常点结果
采用GridLoF算法和基于网格山脊点的异常点检测算法对图2所示数据集进行异常点检测,在保证算法的有效。如图5所示其在不同网格宽度情况下,所需取最少的数据测试点。图6对应是下不同网格宽度情况下检测相关数据点所需要的时间。在上方框型点构成的折线图为GridLOF算法检测结果。星型点构成的折线图为采用基于网格山脊点异常点检测算法检测的结果。

图5 不同网格情况下两种算法取得测试点数

图6 不同网格情况下,最优解情况下的运行时间
根据实验的情况可以了解到,在同等数据规模的情况下,采用基于网格山脊点的异常点检测算法的效率明显高于采用GridLOF算法,时间上的缩减也非常明显。并且采用基于网格山脊点的异常点检测算法对网格宽度变化的抗干扰性明显强于GridLOF算法。所以在实际使用时,基于网格山脊点算法异常点检测算法要优于GridLOF算法。
6 结语
采用基于网格的异常点检测方法[15]是数据检测主要方法之一,具有效率高,检测结果与输入数据顺序无关,可拓展性好的优点。本文提出的基于网格山脊点的异常点检测算法极大的降低了检测算法的时间。能快速高效地定位数据集的边缘区域,给LOF算法提供较精确的检测区域来检测异常点,从而极大减少了算法检测的时间。基于网格的异常点检测方法是一种对GridLOF算法有效改进的方法。
