基于类中心插值的非均衡数据分类算法*
2019-05-31齐利泉
齐利泉
(杭州电子科技大学 通信工程学院,浙江 杭州 310018)
0 引 言
随机森林(Random Forests,RF)算法作为一种优秀的集成学习算法,由多棵决策树组成。每棵树享有相同的分类权重,分类结果由这些树共同投票决定。在训练随机森林模型时,使用bootstrap过程训练模型时引入了两个随机过程,使得每棵决策树的训练样本不尽相同,造成决策树模型的分类性能有所差别。同时,若样本不均衡,往往数据量大的样本分类性能优于数据量小的样本。为了降低数据量对样本分类精度的影响,在训练决策树前对数据进行预处理是一种提高算法性能的有效手段。
1 研究现状
为了获取相对均衡的训练样本,Chawla等人[1]提出了SMOTE算法。该方法主要是通过插值在数量较少的样本集内加入人造样本来实现平衡样本数据量的目的。Han等人[2]提出的Borderline-SMOTE算法是基于SMOTE的改进算法。该算法为了解决SMOTE算法插值的部分新样本无法代表少数类的问题,改进了插值方法,提高了插值样本的有效性。而随机欠采样方法和最近邻欠采样方法是最具代表性的欠采样方法。前者随机从多数类中采样样本,从而减少其数量,达到数据均衡的目的。熊冰妍等人[3]提出基于最近邻方法的欠抽样方法KAcBag,根据数据集中不同类别样本的数量来确定不同类别样本的权重,并通过迭代聚类更新权重,最后根据权重进行欠抽样。邬长安等人[4]提出一种ILKL算法来处理样本不均衡问题。该算法方法先聚类将多数类聚类成多个子簇来平衡样本数据,然后在平衡数据集上训练逻辑回归模型实现分类。为了降低样本数据量对分类性能的影响,本文提出了基于k-means和CM(Class Mean)的改进采样算法KC-RF(k-means & CM boot strapsampling,KC)。
2 KN-RF算法
本文改进了RF算法的bootstrap过程,在采样前根据数据样本点的非平衡率(Imbalance Ratio,IR)[5]来确定是否对非均衡数据进行预处理,以使数据相对均衡,然后在该数据集上训练随机森林。
2.1 非平衡系数IR
对于给定的数据集,可以用非平衡系数IR度量其不均衡程度:

其中,nmaj是数据集中大数据量样本数,nmin是数据集中小数据样本数。
在bootstrap采样过程中类别的数据量不同,样本被采样的概率也不同。通常数据量多的类别被采样的概率高,数据量少的样本被采样的概率低。
2.2 KC-RF算法流程
KC-RF算法共有4个关键步骤。第一步,根据式(1)计算数据的不均衡系数IR,然后根据该系数判断是否需要对数据进行预处理。第二步,将样本数量多的类别的数据集进行k-means聚类,聚为k个簇。在该样本集中,距簇中心根据欧式距离选择相应数量的样本进行重采样加入小样本数据集。第三步,计算样本的CM,根据类均值与样本的差值确定插值样本,并将该样本加入小样本数据集。第四步,训练随机森林。
具体的KC-RF算法流程如下。
输入:D非均衡训练集,D´均衡训练集,K簇数
输出:RF模型
具体过程:
1.计算IR,判断是否需要对数据进行均衡化处理
2.for eachDi∈D
3. k-means算法划分Di,并确定k个簇中心cj;
4. 将簇中的样本到簇中心的欧式距离dist排列;
6. 根据dist取前p个样本加入D´并赋予不同的权重。
7. end
8.for eachDi∈D
9.计算Di的类均值其中M为属性的数量。
10.for l=1:L
插值样本:Sl={arti,1,arti,2,…,arti,M,}。
arti,m-1,0,1,2},art ti,m是样本t的特征。
11.将得到的插值样本Sl加入D´中;
12. end
13.end
14.for eachDTi∈RF//DTi第i棵决策树;
15. 使用D´训练决策树DTi
16.end
其中:
其中Ni是第i个类别的样本数量。
2.3 非均衡数据分类性能的评判标准
传统的分类器使用分类精度来衡量分类器的分类性能,但是在非均衡数据集中,多数类的数据量远比小样本类别多,一般的分类算法会倾向于大数据样本。虽然把大数据类别划分为一个多类别数据集仍然可以获得不错的效果,但是对小样本数据仍然无法提高其分类精度。所以,传统分类器中的分类精度的评价方法,无法评价非均衡数据集的分类结果。针对这一问题,通常采用F-measure[6]和G-mean[7]的评价方法。它们是建立在混淆矩阵(如表1所示)上的评判方法。

表1 混淆矩阵
其中TP表示正类被预测成正类,即为真正类(True Positive);FP表示负类被预测成正类,称之为假正类(False Positive);TN表示负类被预测成负类,称为真负类(True Negative);FN表示正类被预测成负类,称为假负类(False Negative)。
F-measure是一种针对非平衡数据分类问题的评价方式,定义为:

其中Recall表示查全率,Precision表示查准率,β表示Precision和Recall的重要性比值,一般取值为1。只有当Recall和Precision都较大时,F-measure才会较大。所以,F-measure方法非常适用于度量小样本类别在模型上的分类性能[3-8]。
G-mean准则可以衡量非均衡数据集的整体分类性能,定义为:

其中:

G-mean评判标准是在保证数据集正负样本分类精度平衡的情况下使得两类分类精度最大。具体地,如果负样本分类精度高,但是正样本的分类精度却很低,那么同样会使G-mean的值很小;只有当二者的分类精度都较高时,G-mean值才会较大。所以,G-mean可以评判非均衡数据集的分类性能[8]。
3 实验仿真及结果分析
本文使用Opencv3.5的RTrees类实现随机森林模型。为了排除决策树其他参数对实验结果的影响,首先实验了决策树数量对随机森林模型分类结果的影响。其他参数使用默认设置。在UCI数据中的Letter Recognition上的结果如图1所示。
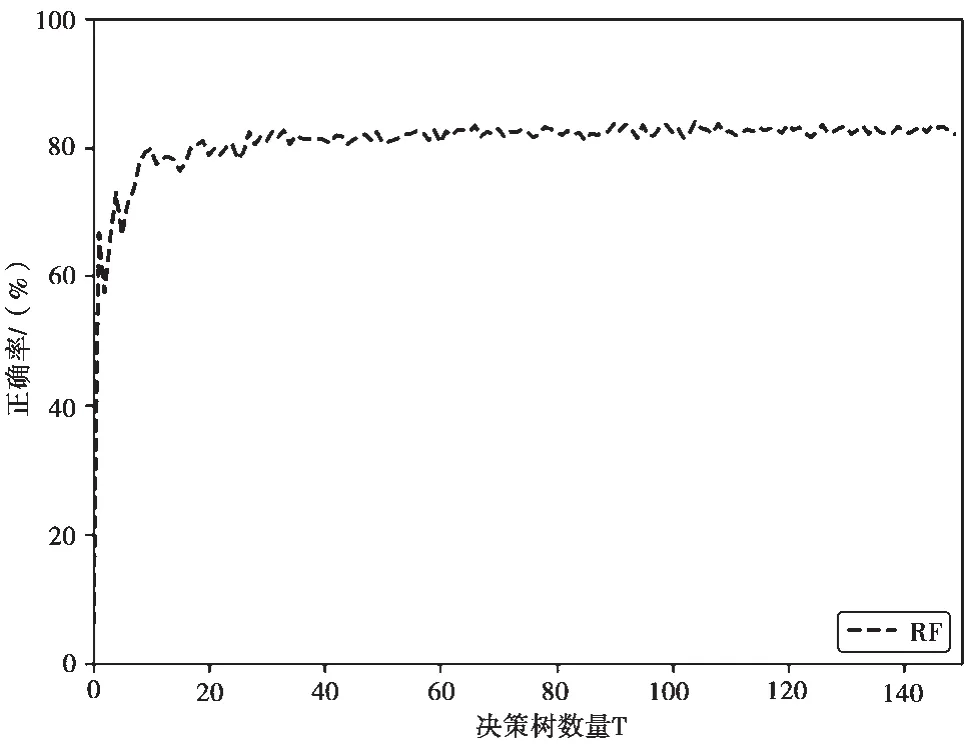
图1 算法分类精度和决策树数量的关系
由图1可以看出,RF算法的分类精度随着决策树的增加而不断增长,但是不会一直增长。当决策树数量达到一定值,RF的分类精度不会再增加。此外,因为决策树的数量会影响模型的大小、训练以及测试速度,所以在考虑分类精度后,下文实验的决策树数量为40棵。
在非均衡数据集KEEL数据下,实验RF算法及其改进算法KC-RF的F-measure和G-mean算法。在固定样本集中随机抽取80%的样本作为训练集,剩余20%的样本作为测试集,分别做100次实验。100次实验的均值结果如表2所示。
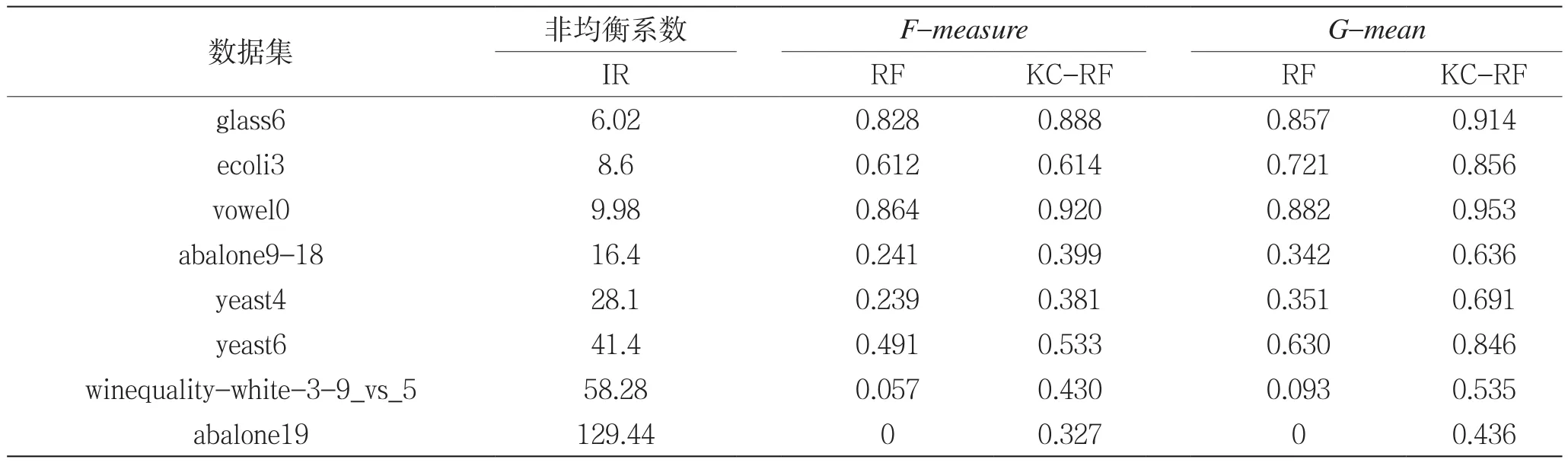
表2 KC-RF算法与RF算法的F-measure值及G-mean值比较
由表2可以看到,当类别数量相差较大时,如abalone19,OpenCV已然没有分类能力,而本文提出的算法依然能够获得不错的分类性能。可以看出,KC-RF算法在F-measure和G-mean两个指标上相比于传统RF算法均可以提高算法的分类精度,且具有很高的鲁棒性。
4 结 语
本文主要针对样本数据不均衡导致分类器向大数据样本偏重而小样本数据分类性能欠佳的问题,提出了KC-RF算法。两步的上采样过程可以有效扩增小样本数据,实现数据相对均衡。在非均衡数据集KEEL上的实验表明,KC-RF算法在F-measure和G-mean两个指标上相比于传统RF算法均可以提高算法的分类精度。实验结果表明,本文提出的方法是一种可行且高效的方法。
